 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIPoint3D: Language-Grounded Few-Shot Unsupervised 3D Point Cloud Domain Adaptation
Feb 23, 2026Recent vision-language models (VLMs) such as CLIP demonstrate impressive cross-modal reasoning, extending beyond images to 3D perception. Yet, these models remain fragile under domain shifts, especially when adapting from synthetic to real-world point clouds. Conventional 3D domain adaptation approaches rely on heavy trainable encoders, yielding strong accuracy but at the cost of efficiency. We introduce CLIPoint3D, the first framework for few-shot unsupervised 3D point cloud domain adaptation built upon CLIP. Our approach projects 3D samples into multiple depth maps and exploits the frozen CLIP backbone, refined through a knowledge-driven prompt tuning scheme that integrates high-level language priors with geometric cues from a lightweight 3D encoder. To adapt task-specific features effectively, we apply parameter-efficient fine-tuning to CLIP's encoders and design an entropy-guided view sampling strategy for selecting confident projections. Furthermore, an optimal transport-based alignment loss and an uncertainty-aware prototype alignment loss collaboratively bridge source-target distribution gaps while maintaining class separability. Extensive experiments on PointDA-10 and GraspNetPC-10 benchmarks show that CLIPoint3D achieves consistent 3-16% accuracy gains over both CLIP-based and conventional encoder-based baselines. Codes are available at https://github.com/SarthakM320/CLIPoint3D.
iSHIFT: Lightweight Slow-Fast GUI Agent with Adaptive Perception
Dec 26, 2025



Multimodal Large Language Models (MLLMs) show strong potential for interpreting and interacting with complex, pixel-rich Graphical User Interface (GUI) environments. However, building agents that are both efficient for high-level tasks and precise for fine-grained interactions remains challenging. GUI agents must perform routine actions efficiently while also handling tasks that demand exact visual grounding, yet existing approaches struggle when accuracy depends on identifying specific interface elements. These MLLMs also remain large and cannot adapt their reasoning depth to the task at hand. In this work, we introduce iSHIFT: Implicit Slow-fast Hybrid Inference with Flexible Tokens, a lightweight agent that integrates latent thinking (implicit chain-of-thought) with a perception control module. iSHIFT enables an MLLM to switch between a slow mode, which leverages detailed visual grounding for high precision and a fast mode that uses global cues for efficiency. Special perception tokens guide attention to relevant screen regions, allowing the model to decide both how to reason and where to focus. Despite its compact 2.5B size, iSHIFT matches state-of-the-art performance on multiple benchmark datasets.
EOPose : Exemplar-based object reposing using Generalized Pose Correspondences
May 06, 2025



Reposing objects in images has a myriad of applications, especially for e-commerce where several variants of product images need to be produced quickly. In this work, we leverage the recent advances in unsupervised keypoint correspondence detection between different object images of the same class to propose an end-to-end framework for generic object reposing. Our method, EOPose, takes a target pose-guidance image as input and uses its keypoint correspondence with the source object image to warp and re-render the latter into the target pose using a novel three-step approach. Unlike generative approaches, our method also preserves the fine-grained details of the object such as its exact colors, textures, and brand marks. We also prepare a new dataset of paired objects based on the Objaverse dataset to train and test our network. EOPose produces high-quality reposing output as evidenced by different image quality metrics (PSNR, SSIM and FID). Besides a description of the method and the dataset, the paper also includes detailed ablation and user studies to indicate the efficacy of the proposed method
FedMVP: Federated Multi-modal Visual Prompt Tuning for Vision-Language Models
Apr 29, 2025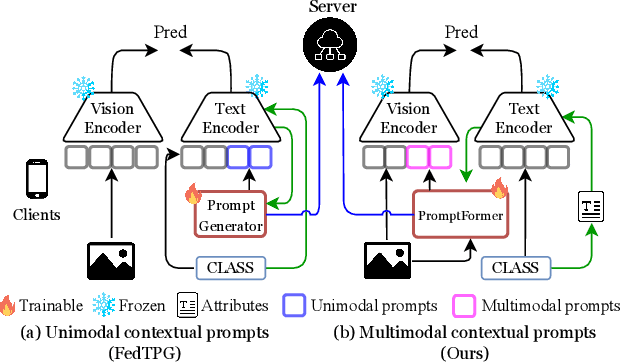
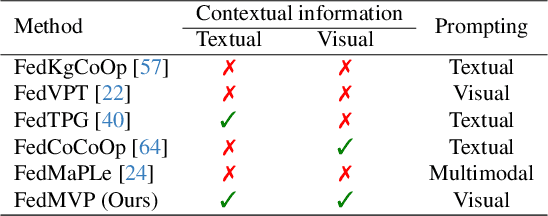
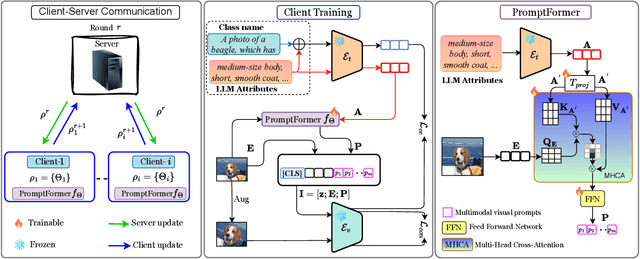
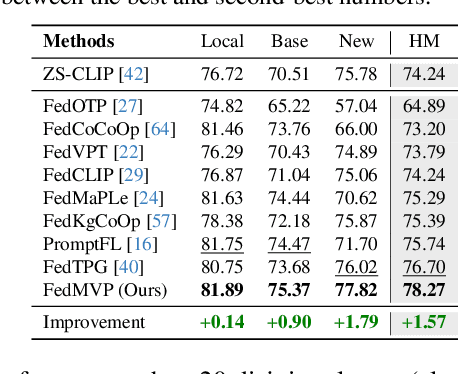
Textual prompt tuning adapts Vision-Language Models (e.g., CLIP) in federated learning by tuning lightweight input tokens (or prompts) on local client data, while keeping network weights frozen. Post training, only the prompts are shared by the clients with the central server for aggregation. However, textual prompt tuning often struggles with overfitting to known concepts and may be overly reliant on memorized text features, limiting its adaptability to unseen concepts. To address this limitation, we propose Federated Multimodal Visual Prompt Tuning (FedMVP) that conditions the prompts on comprehensive contextual information -- image-conditioned features and textual attribute features of a class -- that is multimodal in nature. At the core of FedMVP is a PromptFormer module that synergistically aligns textual and visual features through cross-attention, enabling richer contexual integration. The dynamically generated multimodal visual prompts are then input to the frozen vision encoder of CLIP, and trained with a combination of CLIP similarity loss and a consistency loss. Extensive evaluation on 20 datasets spanning three generalization settings demonstrates that FedMVP not only preserves performance on in-distribution classes and domains, but also displays higher generalizability to unseen classes and domains when compared to state-of-the-art methods. Codes will be released upon acceptance.
REJEPA: A Novel Joint-Embedding Predictive Architecture for Efficient Remote Sensing Image Retrieval
Apr 04, 2025



The rapid expansion of remote sensing image archives demands the development of strong and efficient techniques for content-based image retrieval (RS-CBIR). This paper presents REJEPA (Retrieval with Joint-Embedding Predictive Architecture), an innovative self-supervised framework designed for unimodal RS-CBIR. REJEPA utilises spatially distributed context token encoding to forecast abstract representations of target tokens, effectively capturing high-level semantic features and eliminating unnecessary pixel-level details. In contrast to generative methods that focus on pixel reconstruction or contrastive techniques that depend on negative pairs, REJEPA functions within feature space, achieving a reduction in computational complexity of 40-60% when compared to pixel-reconstruction baselines like Masked Autoencoders (MAE). To guarantee strong and varied representations, REJEPA incorporates Variance-Invariance-Covariance Regularisation (VICReg), which prevents encoder collapse by promoting feature diversity and reducing redundancy. The method demonstrates an estimated enhancement in retrieval accuracy of 5.1% on BEN-14K (S1), 7.4% on BEN-14K (S2), 6.0% on FMoW-RGB, and 10.1% on FMoW-Sentinel compared to prominent SSL techniques, including CSMAE-SESD, Mask-VLM, SatMAE, ScaleMAE, and SatMAE++, on extensive RS benchmarks BEN-14K (multispectral and SAR data), FMoW-RGB and FMoW-Sentinel. Through effective generalisation across sensor modalities, REJEPA establishes itself as a sensor-agnostic benchmark for efficient, scalable, and precise RS-CBIR, addressing challenges like varying resolutions, high object density, and complex backgrounds with computational efficiency.
When Domain Generalization meets Generalized Category Discovery: An Adaptive Task-Arithmetic Driven Approach
Mar 21, 2025Generalized Class Discovery (GCD) clusters base and novel classes in a target domain using supervision from a source domain with only base classes. Current methods often falter with distribution shifts and typically require access to target data during training, which can sometimes be impractical. To address this issue, we introduce the novel paradigm of Domain Generalization in GCD (DG-GCD), where only source data is available for training, while the target domain, with a distinct data distribution, remains unseen until inference. To this end, our solution, DG2CD-Net, aims to construct a domain-independent, discriminative embedding space for GCD. The core innovation is an episodic training strategy that enhances cross-domain generalization by adapting a base model on tasks derived from source and synthetic domains generated by a foundation model. Each episode focuses on a cross-domain GCD task, diversifying task setups over episodes and combining open-set domain adaptation with a novel margin loss and representation learning for optimizing the feature space progressively. To capture the effects of fine-tuning on the base model, we extend task arithmetic by adaptively weighting the local task vectors concerning the fine-tuned models based on their GCD performance on a validation distribution. This episodic update mechanism boosts the adaptability of the base model to unseen targets. Experiments across three datasets confirm that DG2CD-Net outperforms existing GCD methods customized for DG-GCD.
CDAD-Net: Bridging Domain Gaps in Generalized Category Discovery
Apr 08, 2024In Generalized Category Discovery (GCD), we cluster unlabeled samples of known and novel classes, leveraging a training dataset of known classes. A salient challenge arises due to domain shifts between these datasets. To address this, we present a novel setting: Across Domain Generalized Category Discovery (AD-GCD) and bring forth CDAD-NET (Class Discoverer Across Domains) as a remedy. CDAD-NET is architected to synchronize potential known class samples across both the labeled (source) and unlabeled (target) datasets, while emphasizing the distinct categorization of the target data. To facilitate this, we propose an entropy-driven adversarial learning strategy that accounts for the distance distributions of target samples relative to source-domain class prototypes. Parallelly, the discriminative nature of the shared space is upheld through a fusion of three metric learning objectives. In the source domain, our focus is on refining the proximity between samples and their affiliated class prototypes, while in the target domain, we integrate a neighborhood-centric contrastive learning mechanism, enriched with an adept neighborsmining approach. To further accentuate the nuanced feature interrelation among semantically aligned images, we champion the concept of conditional image inpainting, underscoring the premise that semantically analogous images prove more efficacious to the task than their disjointed counterparts. Experimentally, CDAD-NET eclipses existing literature with a performance increment of 8-15% on three AD-GCD benchmarks we present.