 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGALAR-TemporalNet v2: Anatomy-Guided Dual-Branch Temporal Classification with Bidirectional Mamba and Dual-Graph GCN for Video Capsule Endoscopy -- after competition results
May 21, 2026Video Capsule Endoscopy (VCE) poses a challenging multi-label temporal classification problem, requiring simultaneous localization of 8 anatomical regions and detection of 9 pathological findings across tens of thousands of frames. We present GALAR-TemporalNet v2, a hierarchical temporal model that addresses three core challenges: extreme class imbalance, long-range temporal dependencies, and pathology--anatomy entanglement. Our architecture combines windowed self-attention for local modeling, a Dual-Graph GCN for global frame relationships, and Bidirectional Mamba for selective boundary context encoding. A novel anatomy prototype residual pathway decouples pathological deviation signals from normal organ appearance, and a frame-level GCN skip connection stabilizes training of visually confusable rare classes. The competition version, GALAR-TemporalNet, achieved an overall mAP@0.5 of 0.2644 and mAP@0.95 of 0.2353 on the RARE-VISION test set. Following the competition, the redesigned GALAR-TemporalNet v2 -- incorporating a restructured pathology branch, refined loss functions, and extended post-processing -- improved these results to mAP@0.5 of 0.3409 and mAP@0.95 of 0.3333.
MambaLiteUNet: Cross-Gated Adaptive Feature Fusion for Robust Skin Lesion Segmentation
Apr 22, 2026Recent segmentation models have demonstrated promising efficiency by aggressively reducing parameter counts and computational complexity. However, these models often struggle to accurately delineate fine lesion boundaries and texture patterns essential for early skin cancer diagnosis and treatment planning. In this paper, we propose MambaLiteUNet, a compact yet robust segmentation framework that integrates Mamba state space modeling into a U-Net architecture, along with three key modules: Adaptive Multi-Branch Mamba Feature Fusion (AMF), Local-Global Feature Mixing (LGFM), and Cross-Gated Attention (CGA). These modules are designed to enhance local-global feature interaction, preserve spatial details, and improve the quality of skip connections. MambaLiteUNet achieves an average IoU of 87.12% and average Dice score of 93.09% across ISIC2017, ISIC2018, HAM10000, and PH2 benchmarks, outperforming state-of-the-art models. Compared to U-Net, our model improves average IoU and Dice by 7.72 and 4.61 points, respectively, while reducing parameters by 93.6% and GFLOPs by 97.6%. Additionally, in domain generalization with six unseen lesion categories, MambaLiteUNet achieves 77.61% IoU and 87.23% Dice, performing best among all evaluated models. Our extensive experiments demonstrate that MambaLiteUNet achieves a strong balance between accuracy and efficiency, making it a competitive and practical solution for dermatological image segmentation. Our code is publicly available at: https://github.com/maklachur/MambaLiteUNet.
Mamba in Vision: A Comprehensive Survey of Techniques and Applications
Oct 04, 2024



Mamba is emerging as a novel approach to overcome the challenges faced by Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) in computer vision. While CNNs excel at extracting local features, they often struggle to capture long-range dependencies without complex architectural modifications. In contrast, ViTs effectively model global relationships but suffer from high computational costs due to the quadratic complexity of their self-attention mechanisms. Mamba addresses these limitations by leveraging Selective Structured State Space Models to effectively capture long-range dependencies with linear computational complexity. This survey analyzes the unique contributions, computational benefits, and applications of Mamba models while also identifying challenges and potential future research directions. We provide a foundational resource for advancing the understanding and growth of Mamba models in computer vision. An overview of this work is available at https://github.com/maklachur/Mamba-in-Computer-Vision.
Towards Efficient and Accurate CT Segmentation via Edge-Preserving Probabilistic Downsampling
Apr 05, 2024



Downsampling images and labels, often necessitated by limited resources or to expedite network training, leads to the loss of small objects and thin boundaries. This undermines the segmentation network's capacity to interpret images accurately and predict detailed labels, resulting in diminished performance compared to processing at original resolutions. This situation exemplifies the trade-off between efficiency and accuracy, with higher downsampling factors further impairing segmentation outcomes. Preserving information during downsampling is especially critical for medical image segmentation tasks. To tackle this challenge, we introduce a novel method named Edge-preserving Probabilistic Downsampling (EPD). It utilizes class uncertainty within a local window to produce soft labels, with the window size dictating the downsampling factor. This enables a network to produce quality predictions at low resolutions. Beyond preserving edge details more effectively than conventional nearest-neighbor downsampling, employing a similar algorithm for images, it surpasses bilinear interpolation in image downsampling, enhancing overall performance. Our method significantly improved Intersection over Union (IoU) to 2.85%, 8.65%, and 11.89% when downsampling data to 1/2, 1/4, and 1/8, respectively, compared to conventional interpolation methods.
High-Quality Face Caricature via Style Translation
Nov 22, 2023



Caricature is an exaggerated form of artistic portraiture that accentuates unique yet subtle characteristics of human faces. Recently, advancements in deep end-to-end techniques have yielded encouraging outcomes in capturing both style and elevated exaggerations in creating face caricatures. Most of these approaches tend to produce cartoon-like results that could be more practical for real-world applications. In this study, we proposed a high-quality, unpaired face caricature method that is appropriate for use in the real world and uses computer vision techniques and GAN models. We attain the exaggeration of facial features and the stylization of appearance through a two-step process: Face caricature generation and face caricature projection. The face caricature generation step creates new caricature face datasets from real images and trains a generative model using the real and newly created caricature datasets. The Face caricature projection employs an encoder trained with real and caricature faces with the pretrained generator to project real and caricature faces. We perform an incremental facial exaggeration from the real image to the caricature faces using the encoder and generator's latent space. Our projection preserves the facial identity, attributes, and expressions from the input image. Also, it accounts for facial occlusions, such as reading glasses or sunglasses, to enhance the robustness of our model. Furthermore, we conducted a comprehensive comparison of our approach with various state-of-the-art face caricature methods, highlighting our process's distinctiveness and exceptional realism.
Lightweight Encoder-Decoder Architecture for Foot Ulcer Segmentation
Jul 06, 2022Continuous monitoring of foot ulcer healing is needed to ensure the efficacy of a given treatment and to avoid any possibility of deterioration. Foot ulcer segmentation is an essential step in wound diagnosis. We developed a model that is similar in spirit to the well-established encoder-decoder and residual convolution neural networks. Our model includes a residual connection along with a channel and spatial attention integrated within each convolution block. A simple patch-based approach for model training, test time augmentations, and majority voting on the obtained predictions resulted in superior performance. Our model did not leverage any readily available backbone architecture, pre-training on a similar external dataset, or any of the transfer learning techniques. The total number of network parameters being around 5 million made it a significantly lightweight model as compared with the available state-of-the-art models used for the foot ulcer segmentation task. Our experiments presented results at the patch-level and image-level. Applied on publicly available Foot Ulcer Segmentation (FUSeg) Challenge dataset from MICCAI 2021, our model achieved state-of-the-art image-level performance of 88.22% in terms of Dice similarity score and ranked second in the official challenge leaderboard. We also showed an extremely simple solution that could be compared against the more advanced architectures.
* Published version of this article is available at https://link.springer.com/chapter/10.1007/978-3-031-06381-7_17
Illumination Invariant Foreground Object Segmentation using ForeGANs
Apr 05, 2019
The foreground segmentation algorithms suffer performance degradation in the presence of various challenges such as dynamic backgrounds, and various illumination conditions. To handle these challenges, we present a foreground segmentation method, based on generative adversarial network (GAN). We aim to segment foreground objects in the presence of two aforementioned major challenges in background scenes in real environments. To address this problem, our presented GAN model is trained on background image samples with dynamic changes, after that for testing the GAN model has to generate the same background sample as test sample with similar conditions via back-propagation technique. The generated background sample is then subtracted from the given test sample to segment foreground objects. The comparison of our proposed method with five state-of-the-art methods highlights the strength of our algorithm for foreground segmentation in the presence of challenging dynamic background scenario.
Brain MRI Segmentation using Rule-Based Hybrid Approach
Feb 12, 2019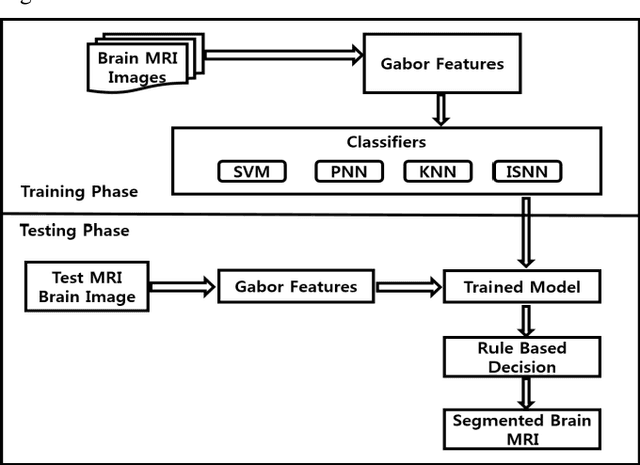
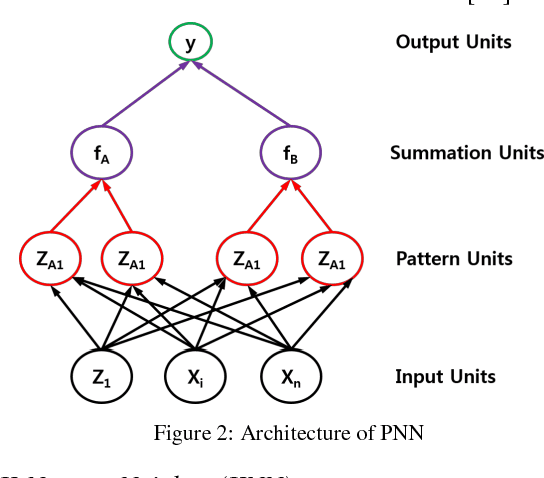
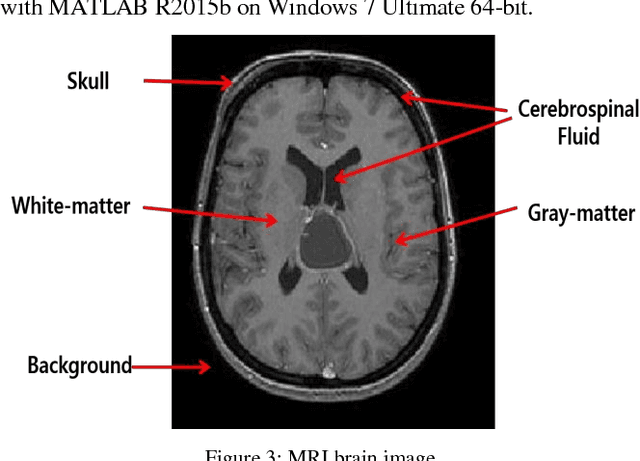
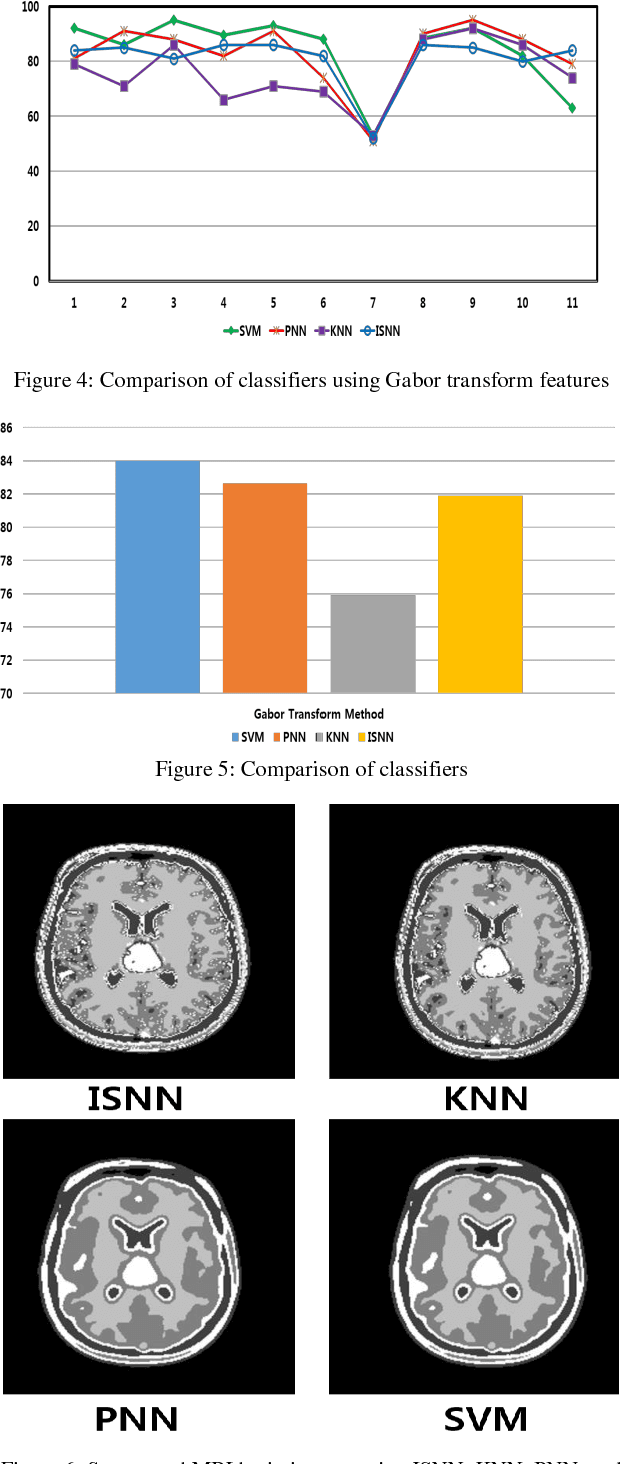
Medical image segmentation being a substantial component of image processing plays a significant role to analyze gross anatomy, to locate an infirmity and to plan the surgical procedures. Segmentation of brain Magnetic Resonance Imaging (MRI) is of considerable importance for the accurate diagnosis. However, precise and accurate segmentation of brain MRI is a challenging task. Here, we present an efficient framework for segmentation of brain MR images. For this purpose, Gabor transform method is used to compute features of brain MRI. Then, these features are classified by using four different classifiers i.e., Incremental Supervised Neural Network (ISNN), K-Nearest Neighbor (KNN), Probabilistic Neural Network (PNN), and Support Vector Machine (SVM). Performance of these classifiers is investigated over different images of brain MRI and the variation in the performance of these classifiers is observed for different brain tissues. Thus, we proposed a rule-based hybrid approach to segment brain MRI. Experimental results show that the performance of these classifiers varies over each tissue MRI and the proposed rule-based hybrid approach exhibits better segmentation of brain MRI tissues.
Handcrafted and Deep Trackers: A Review of Recent Object Tracking Approaches
Dec 06, 2018



In recent years visual object tracking has become a very active research area. An increasing number of tracking algorithms are being proposed each year. It is because tracking has wide applications in various real world problems such as human-computer interaction, autonomous vehicles, robotics, surveillance and security just to name a few. In the current study, we review latest trends and advances in the tracking area and evaluate the robustness of different trackers based on the feature extraction methods. The first part of this work comprises a comprehensive survey of the recently proposed trackers. We broadly categorize trackers into Correlation Filter based Trackers (CFTs) and Non-CFTs. Each category is further classified into various types based on the architecture and the tracking mechanism. In the second part, we experimentally evaluated 24 recent trackers for robustness, and compared handcrafted and deep feature based trackers. We observe that trackers using deep features performed better, though in some cases a fusion of both increased performance significantly. In order to overcome the drawbacks of the existing benchmarks, a new benchmark Object Tracking and Temple Color (OTTC) has also been proposed and used in the evaluation of different algorithms. We analyze the performance of trackers over eleven different challenges in OTTC, and three other benchmarks. Our study concludes that Discriminative Correlation Filter (DCF) based trackers perform better than the others. Our study also reveals that inclusion of different types of regularizations over DCF often results in boosted tracking performance. Finally, we sum up our study by pointing out some insights and indicating future trends in visual object tracking field.
Deep Neural Network Concepts for Background Subtraction: A Systematic Review and Comparative Evaluation
Nov 13, 2018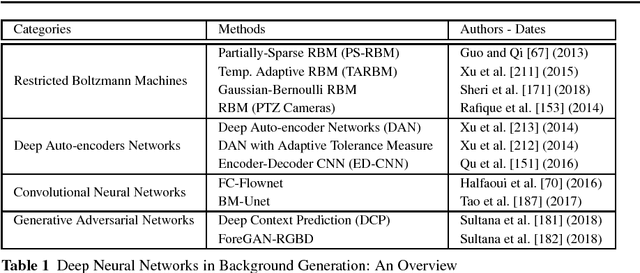

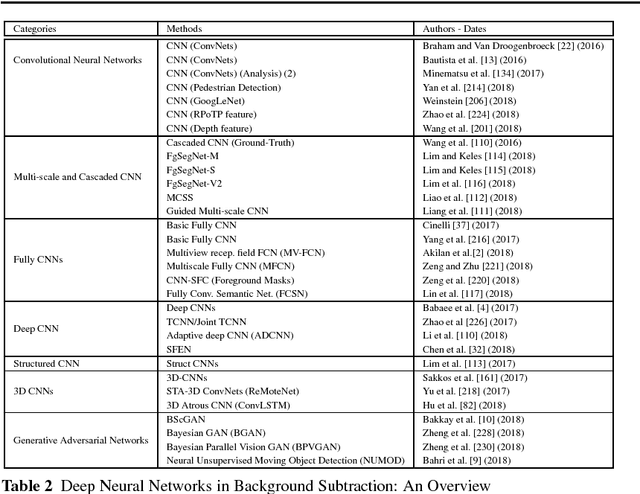

Conventional neural networks show a powerful framework for background subtraction in video acquired by static cameras. Indeed, the well-known SOBS method and its variants based on neural networks were the leader methods on the largescale CDnet 2012 dataset during a long time. Recently, convolutional neural networks which belong to deep learning methods were employed with success for background initialization, foreground detection and deep learned features. Currently, the top current background subtraction methods in CDnet 2014 are based on deep neural networks with a large gap of performance in comparison on the conventional unsupervised approaches based on multi-features or multi-cues strategies. Furthermore, a huge amount of papers was published since 2016 when Braham and Van Droogenbroeck published their first work on CNN applied to background subtraction providing a regular gain of performance. In this context, we provide the first review of deep neural network concepts in background subtraction for novices and experts in order to analyze this success and to provide further directions. For this, we first surveyed the methods used background initialization, background subtraction and deep learned features. Then, we discuss the adequacy of deep neural networks for background subtraction. Finally, experimental results are presented on the CDnet 2014 dataset.