 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioVLM: Routing Prompts, Not Parameters, for Cross-Modality Generalization in Biomedical VLMs
Apr 19, 2026Pretrained biomedical vision-language models (VLMs) such as BioMedCLIP perform well on average but often degrade on challenging modalities where inter-class margins are small and acquisition-specific variations are pronounced, especially under few-shot supervision and when modality priors differ from pretraining corpora substantially. We propose BioVLM, a prompt-learning framework that improves cross-domain generalization without extensive backbone fine-tuning. BioVLM learns a diverse prompt bank and introduces dynamic prompt selection: for each input, it selects the most discriminative prompts via a low-entropy criterion on the predictive distribution, effectively coupling sparse few-shot evidence with rich LLM semantic priors. To strengthen this coupling, we distill high-confidence LLM-derived attributes and enforce robust knowledge transfer through strong/weak augmentation consistency. At test time, BioVLM adapts by choosing modality-appropriate prompts, enabling transfer to unseen categories and domains, while keeping training lightweight and inference efficient. On 11 MedMNIST+ 2D datasets, BioVLM achieves new state of the art across three distinct generalization settings. Codes are available at https://github.com/mainaksingha01/BioVLM.
MMLGNet: Cross-Modal Alignment of Remote Sensing Data using CLIP
Jan 13, 2026In this paper, we propose a novel multimodal framework, Multimodal Language-Guided Network (MMLGNet), to align heterogeneous remote sensing modalities like Hyperspectral Imaging (HSI) and LiDAR with natural language semantics using vision-language models such as CLIP. With the increasing availability of multimodal Earth observation data, there is a growing need for methods that effectively fuse spectral, spatial, and geometric information while enabling semantic-level understanding. MMLGNet employs modality-specific encoders and aligns visual features with handcrafted textual embeddings in a shared latent space via bi-directional contrastive learning. Inspired by CLIP's training paradigm, our approach bridges the gap between high-dimensional remote sensing data and language-guided interpretation. Notably, MMLGNet achieves strong performance with simple CNN-based encoders, outperforming several established multimodal visual-only methods on two benchmark datasets, demonstrating the significant benefit of language supervision. Codes are available at https://github.com/AdityaChaudhary2913/CLIP_HSI.
SDHSI-Net: Learning Better Representations for Hyperspectral Images via Self-Distillation
Jan 12, 2026Hyperspectral image (HSI) classification presents unique challenges due to its high spectral dimensionality and limited labeled data. Traditional deep learning models often suffer from overfitting and high computational costs. Self-distillation (SD), a variant of knowledge distillation where a network learns from its own predictions, has recently emerged as a promising strategy to enhance model performance without requiring external teacher networks. In this work, we explore the application of SD to HSI by treating earlier outputs as soft targets, thereby enforcing consistency between intermediate and final predictions. This process improves intra-class compactness and inter-class separability in the learned feature space. Our approach is validated on two benchmark HSI datasets and demonstrates significant improvements in classification accuracy and robustness, highlighting the effectiveness of SD for spectral-spatial learning. Codes are available at https://github.com/Prachet-Dev-Singh/SDHSI.
Reconstruction Guided Few-shot Network For Remote Sensing Image Classification
Jan 12, 2026Few-shot remote sensing image classification is challenging due to limited labeled samples and high variability in land-cover types. We propose a reconstruction-guided few-shot network (RGFS-Net) that enhances generalization to unseen classes while preserving consistency for seen categories. Our method incorporates a masked image reconstruction task, where parts of the input are occluded and reconstructed to encourage semantically rich feature learning. This auxiliary task strengthens spatial understanding and improves class discrimination under low-data settings. We evaluated the efficacy of EuroSAT and PatternNet datasets under 1-shot and 5-shot protocols, our approach consistently outperforms existing baselines. The proposed method is simple, effective, and compatible with standard backbones, offering a robust solution for few-shot remote sensing classification. Codes are available at https://github.com/stark0908/RGFS.
FedMVP: Federated Multi-modal Visual Prompt Tuning for Vision-Language Models
Apr 29, 2025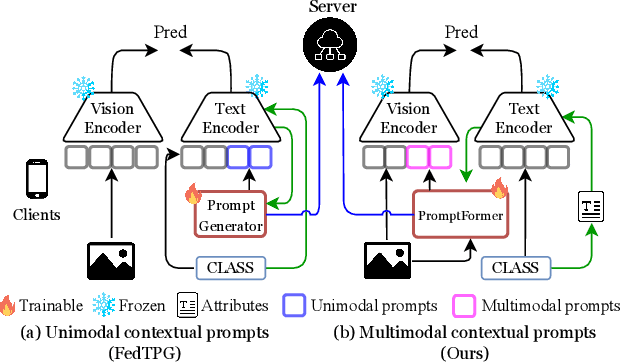
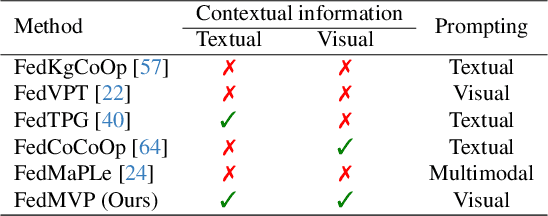
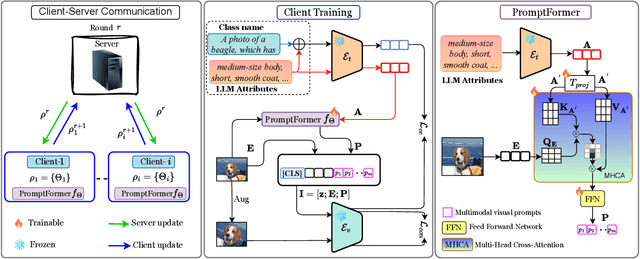
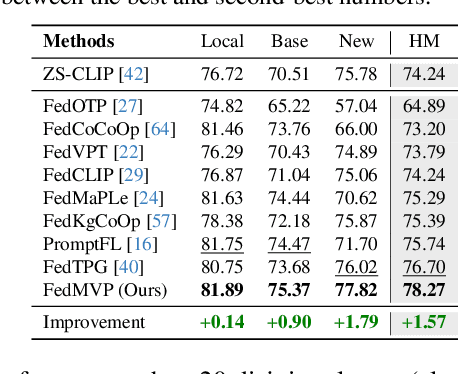
Textual prompt tuning adapts Vision-Language Models (e.g., CLIP) in federated learning by tuning lightweight input tokens (or prompts) on local client data, while keeping network weights frozen. Post training, only the prompts are shared by the clients with the central server for aggregation. However, textual prompt tuning often struggles with overfitting to known concepts and may be overly reliant on memorized text features, limiting its adaptability to unseen concepts. To address this limitation, we propose Federated Multimodal Visual Prompt Tuning (FedMVP) that conditions the prompts on comprehensive contextual information -- image-conditioned features and textual attribute features of a class -- that is multimodal in nature. At the core of FedMVP is a PromptFormer module that synergistically aligns textual and visual features through cross-attention, enabling richer contexual integration. The dynamically generated multimodal visual prompts are then input to the frozen vision encoder of CLIP, and trained with a combination of CLIP similarity loss and a consistency loss. Extensive evaluation on 20 datasets spanning three generalization settings demonstrates that FedMVP not only preserves performance on in-distribution classes and domains, but also displays higher generalizability to unseen classes and domains when compared to state-of-the-art methods. Codes will be released upon acceptance.
OSLoPrompt: Bridging Low-Supervision Challenges and Open-Set Domain Generalization in CLIP
Mar 20, 2025We introduce Low-Shot Open-Set Domain Generalization (LSOSDG), a novel paradigm unifying low-shot learning with open-set domain generalization (ODG). While prompt-based methods using models like CLIP have advanced DG, they falter in low-data regimes (e.g., 1-shot) and lack precision in detecting open-set samples with fine-grained semantics related to training classes. To address these challenges, we propose OSLOPROMPT, an advanced prompt-learning framework for CLIP with two core innovations. First, to manage limited supervision across source domains and improve DG, we introduce a domain-agnostic prompt-learning mechanism that integrates adaptable domain-specific cues and visually guided semantic attributes through a novel cross-attention module, besides being supported by learnable domain- and class-generic visual prompts to enhance cross-modal adaptability. Second, to improve outlier rejection during inference, we classify unfamiliar samples as "unknown" and train specialized prompts with systematically synthesized pseudo-open samples that maintain fine-grained relationships to known classes, generated through a targeted query strategy with off-the-shelf foundation models. This strategy enhances feature learning, enabling our model to detect open samples with varied granularity more effectively. Extensive evaluations across five benchmarks demonstrate that OSLOPROMPT establishes a new state-of-the-art in LSOSDG, significantly outperforming existing methods.
Foundation Models and Adaptive Feature Selection: A Synergistic Approach to Video Question Answering
Dec 12, 2024
This paper tackles the intricate challenge of video question-answering (VideoQA). Despite notable progress, current methods fall short of effectively integrating questions with video frames and semantic object-level abstractions to create question-aware video representations. We introduce Local-Global Question Aware Video Embedding (LGQAVE), which incorporates three major innovations to integrate multi-modal knowledge better and emphasize semantic visual concepts relevant to specific questions. LGQAVE moves beyond traditional ad-hoc frame sampling by utilizing a cross-attention mechanism that precisely identifies the most relevant frames concerning the questions. It captures the dynamics of objects within these frames using distinct graphs, grounding them in question semantics with the miniGPT model. These graphs are processed by a question-aware dynamic graph transformer (Q-DGT), which refines the outputs to develop nuanced global and local video representations. An additional cross-attention module integrates these local and global embeddings to generate the final video embeddings, which a language model uses to generate answers. Extensive evaluations across multiple benchmarks demonstrate that LGQAVE significantly outperforms existing models in delivering accurate multi-choice and open-ended answers.
In the Era of Prompt Learning with Vision-Language Models
Nov 07, 2024

Large-scale foundation models like CLIP have shown strong zero-shot generalization but struggle with domain shifts, limiting their adaptability. In our work, we introduce \textsc{StyLIP}, a novel domain-agnostic prompt learning strategy for Domain Generalization (DG). StyLIP disentangles visual style and content in CLIP`s vision encoder by using style projectors to learn domain-specific prompt tokens and combining them with content features. Trained contrastively, this approach enables seamless adaptation across domains, outperforming state-of-the-art methods on multiple DG benchmarks. Additionally, we propose AD-CLIP for unsupervised domain adaptation (DA), leveraging CLIP`s frozen vision backbone to learn domain-invariant prompts through image style and content features. By aligning domains in embedding space with entropy minimization, AD-CLIP effectively handles domain shifts, even when only target domain samples are available. Lastly, we outline future work on class discovery using prompt learning for semantic segmentation in remote sensing, focusing on identifying novel or rare classes in unstructured environments. This paves the way for more adaptive and generalizable models in complex, real-world scenarios.
GraphVL: Graph-Enhanced Semantic Modeling via Vision-Language Models for Generalized Class Discovery
Nov 04, 2024



Generalized Category Discovery (GCD) aims to cluster unlabeled images into known and novel categories using labeled images from known classes. To address the challenge of transferring features from known to unknown classes while mitigating model bias, we introduce GraphVL, a novel approach for vision-language modeling in GCD, leveraging CLIP. Our method integrates a graph convolutional network (GCN) with CLIP's text encoder to preserve class neighborhood structure. We also employ a lightweight visual projector for image data, ensuring discriminative features through margin-based contrastive losses for image-text mapping. This neighborhood preservation criterion effectively regulates the semantic space, making it less sensitive to known classes. Additionally, we learn textual prompts from known classes and align them to create a more contextually meaningful semantic feature space for the GCN layer using a contextual similarity loss. Finally, we represent unlabeled samples based on their semantic distance to class prompts from the GCN, enabling semi-supervised clustering for class discovery and minimizing errors. Our experiments on seven benchmark datasets consistently demonstrate the superiority of GraphVL when integrated with the CLIP backbone.
COSMo: CLIP Talks on Open-Set Multi-Target Domain Adaptation
Aug 31, 2024



Multi-Target Domain Adaptation (MTDA) entails learning domain-invariant information from a single source domain and applying it to multiple unlabeled target domains. Yet, existing MTDA methods predominantly focus on addressing domain shifts within visual features, often overlooking semantic features and struggling to handle unknown classes, resulting in what is known as Open-Set (OS) MTDA. While large-scale vision-language foundation models like CLIP show promise, their potential for MTDA remains largely unexplored. This paper introduces COSMo, a novel method that learns domain-agnostic prompts through source domain-guided prompt learning to tackle the MTDA problem in the prompt space. By leveraging a domain-specific bias network and separate prompts for known and unknown classes, COSMo effectively adapts across domain and class shifts. To the best of our knowledge, COSMo is the first method to address Open-Set Multi-Target DA (OSMTDA), offering a more realistic representation of real-world scenarios and addressing the challenges of both open-set and multi-target DA. COSMo demonstrates an average improvement of $5.1\%$ across three challenging datasets: Mini-DomainNet, Office-31, and Office-Home, compared to other related DA methods adapted to operate within the OSMTDA setting. Code is available at: https://github.com/munish30monga/COSMo