 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Grokking Tickets: Lottery Tickets Accelerate Grokking
Oct 30, 2023
Grokking is one of the most surprising puzzles in neural network generalization: a network first reaches a memorization solution with perfect training accuracy and poor generalization, but with further training, it reaches a perfectly generalized solution. We aim to analyze the mechanism of grokking from the lottery ticket hypothesis, identifying the process to find the lottery tickets (good sparse subnetworks) as the key to describing the transitional phase between memorization and generalization. We refer to these subnetworks as ''Grokking tickets'', which is identified via magnitude pruning after perfect generalization. First, using ''Grokking tickets'', we show that the lottery tickets drastically accelerate grokking compared to the dense networks on various configurations (MLP and Transformer, and an arithmetic and image classification tasks). Additionally, to verify that ''Grokking ticket'' are a more critical factor than weight norms, we compared the ''good'' subnetworks with a dense network having the same L1 and L2 norms. Results show that the subnetworks generalize faster than the controlled dense model. In further investigations, we discovered that at an appropriate pruning rate, grokking can be achieved even without weight decay. We also show that speedup does not happen when using tickets identified at the memorization solution or transition between memorization and generalization or when pruning networks at the initialization (Random pruning, Grasp, SNIP, and Synflow). The results indicate that the weight norm of network parameters is not enough to explain the process of grokking, but the importance of finding good subnetworks to describe the transition from memorization to generalization. The implementation code can be accessed via this link: \url{https://github.com/gouki510/Grokking-Tickets}.
Multi-scale Diffusion Denoised Smoothing
Oct 27, 2023Along with recent diffusion models, randomized smoothing has become one of a few tangible approaches that offers adversarial robustness to models at scale, e.g., those of large pre-trained models. Specifically, one can perform randomized smoothing on any classifier via a simple "denoise-and-classify" pipeline, so-called denoised smoothing, given that an accurate denoiser is available - such as diffusion model. In this paper, we present scalable methods to address the current trade-off between certified robustness and accuracy in denoised smoothing. Our key idea is to "selectively" apply smoothing among multiple noise scales, coined multi-scale smoothing, which can be efficiently implemented with a single diffusion model. This approach also suggests a new objective to compare the collective robustness of multi-scale smoothed classifiers, and questions which representation of diffusion model would maximize the objective. To address this, we propose to further fine-tune diffusion model (a) to perform consistent denoising whenever the original image is recoverable, but (b) to generate rather diverse outputs otherwise. Our experiments show that the proposed multi-scale smoothing scheme combined with diffusion fine-tuning enables strong certified robustness available with high noise level while maintaining its accuracy close to non-smoothed classifiers.
LipSim: A Provably Robust Perceptual Similarity Metric
Oct 27, 2023Recent years have seen growing interest in developing and applying perceptual similarity metrics. Research has shown the superiority of perceptual metrics over pixel-wise metrics in aligning with human perception and serving as a proxy for the human visual system. On the other hand, as perceptual metrics rely on neural networks, there is a growing concern regarding their resilience, given the established vulnerability of neural networks to adversarial attacks. It is indeed logical to infer that perceptual metrics may inherit both the strengths and shortcomings of neural networks. In this work, we demonstrate the vulnerability of state-of-the-art perceptual similarity metrics based on an ensemble of ViT-based feature extractors to adversarial attacks. We then propose a framework to train a robust perceptual similarity metric called LipSim (Lipschitz Similarity Metric) with provable guarantees. By leveraging 1-Lipschitz neural networks as the backbone, LipSim provides guarded areas around each data point and certificates for all perturbations within an $\ell_2$ ball. Finally, a comprehensive set of experiments shows the performance of LipSim in terms of natural and certified scores and on the image retrieval application. The code is available at https://github.com/SaraGhazanfari/LipSim.
SmooSeg: Smoothness Prior for Unsupervised Semantic Segmentation
Oct 27, 2023Unsupervised semantic segmentation is a challenging task that segments images into semantic groups without manual annotation. Prior works have primarily focused on leveraging prior knowledge of semantic consistency or priori concepts from self-supervised learning methods, which often overlook the coherence property of image segments. In this paper, we demonstrate that the smoothness prior, asserting that close features in a metric space share the same semantics, can significantly simplify segmentation by casting unsupervised semantic segmentation as an energy minimization problem. Under this paradigm, we propose a novel approach called SmooSeg that harnesses self-supervised learning methods to model the closeness relationships among observations as smoothness signals. To effectively discover coherent semantic segments, we introduce a novel smoothness loss that promotes piecewise smoothness within segments while preserving discontinuities across different segments. Additionally, to further enhance segmentation quality, we design an asymmetric teacher-student style predictor that generates smoothly updated pseudo labels, facilitating an optimal fit between observations and labeling outputs. Thanks to the rich supervision cues of the smoothness prior, our SmooSeg significantly outperforms STEGO in terms of pixel accuracy on three datasets: COCOStuff (+14.9%), Cityscapes (+13.0%), and Potsdam-3 (+5.7%).
C-RITNet: Set Infrared and Visible Image Fusion Free from Complementary Information Mining
Sep 13, 2023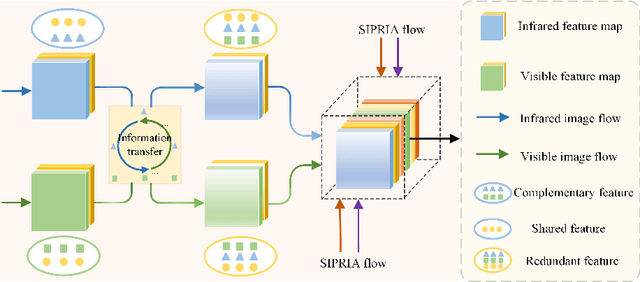

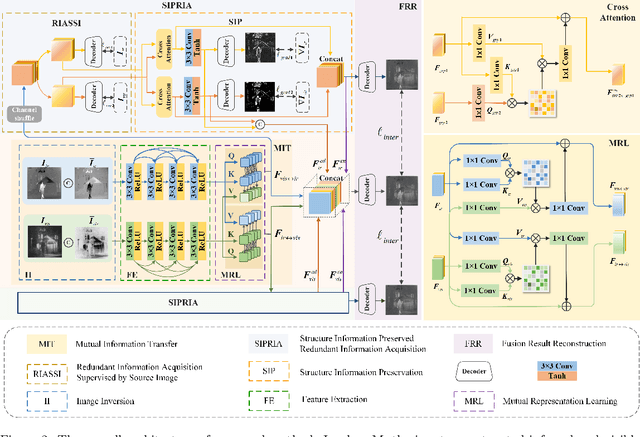
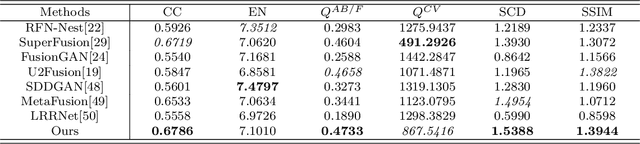
Infrared and visible image fusion (IVIF) aims to extract and integrate the complementary information in two different modalities to generate high-quality fused images with salient targets and abundant texture details. However, current image fusion methods go to great lengths to excavate complementary features, which is generally achieved through two efforts. On the one hand, the feature extraction network is expected to have excellent performance in extracting complementary information. On the other hand, complex fusion strategies are often designed to aggregate the complementary information. In other words, enabling the network to perceive and extract complementary information is extremely challenging. Complicated fusion strategies, while effective, still run the risk of losing weak edge details. To this end, this paper rethinks the IVIF outside the box, proposing a complementary-redundant information transfer network (C-RITNet). It reasonably transfers complementary information into redundant one, which integrates both the shared and complementary features from two modalities. Hence, the proposed method is able to alleviate the challenges posed by the complementary information extraction and reduce the reliance on sophisticated fusion strategies. Specifically, to skillfully sidestep aggregating complementary information in IVIF, we first design the mutual information transfer (MIT) module to mutually represent features from two modalities, roughly transferring complementary information into redundant one. Then, a redundant information acquisition supervised by source image (RIASSI) module is devised to further ensure the complementary-redundant information transfer after MIT. Meanwhile, we also propose a structure information preservation (SIP) module to guarantee that the edge structure information of the source images can be transferred to the fusion results.
Achieving Constraints in Neural Networks: A Stochastic Augmented Lagrangian Approach
Oct 25, 2023Regularizing Deep Neural Networks (DNNs) is essential for improving generalizability and preventing overfitting. Fixed penalty methods, though common, lack adaptability and suffer from hyperparameter sensitivity. In this paper, we propose a novel approach to DNN regularization by framing the training process as a constrained optimization problem. Where the data fidelity term is the minimization objective and the regularization terms serve as constraints. Then, we employ the Stochastic Augmented Lagrangian (SAL) method to achieve a more flexible and efficient regularization mechanism. Our approach extends beyond black-box regularization, demonstrating significant improvements in white-box models, where weights are often subject to hard constraints to ensure interpretability. Experimental results on image-based classification on MNIST, CIFAR10, and CIFAR100 datasets validate the effectiveness of our approach. SAL consistently achieves higher Accuracy while also achieving better constraint satisfaction, thus showcasing its potential for optimizing DNNs under constrained settings.
Towards Control-Centric Representations in Reinforcement Learning from Images
Oct 25, 2023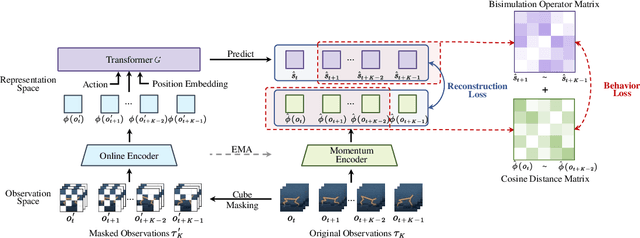
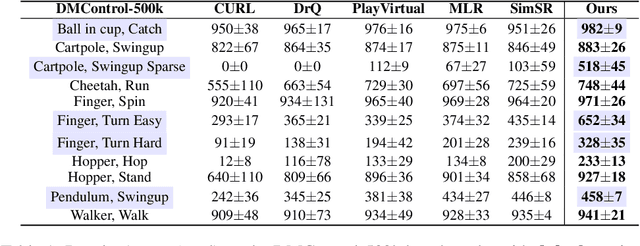

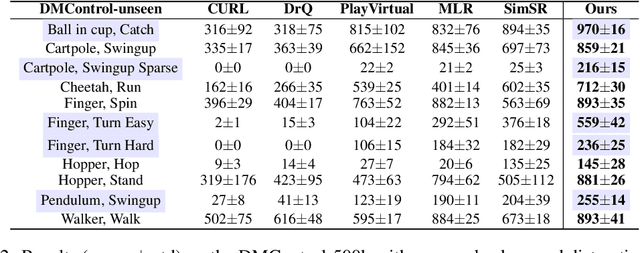
Image-based Reinforcement Learning is a practical yet challenging task. A major hurdle lies in extracting control-centric representations while disregarding irrelevant information. While approaches that follow the bisimulation principle exhibit the potential in learning state representations to address this issue, they still grapple with the limited expressive capacity of latent dynamics and the inadaptability to sparse reward environments. To address these limitations, we introduce ReBis, which aims to capture control-centric information by integrating reward-free control information alongside reward-specific knowledge. ReBis utilizes a transformer architecture to implicitly model the dynamics and incorporates block-wise masking to eliminate spatiotemporal redundancy. Moreover, ReBis combines bisimulation-based loss with asymmetric reconstruction loss to prevent feature collapse in environments with sparse rewards. Empirical studies on two large benchmarks, including Atari games and DeepMind Control Suit, demonstrate that ReBis has superior performance compared to existing methods, proving its effectiveness.
JM3D & JM3D-LLM: Elevating 3D Representation with Joint Multi-modal Cues
Oct 20, 2023The rising importance of 3D representation learning, pivotal in computer vision, autonomous driving, and robotics, is evident. However, a prevailing trend, which straightforwardly resorted to transferring 2D alignment strategies to the 3D domain, encounters three distinct challenges: (1) Information Degradation: This arises from the alignment of 3D data with mere single-view 2D images and generic texts, neglecting the need for multi-view images and detailed subcategory texts. (2) Insufficient Synergy: These strategies align 3D representations to image and text features individually, hampering the overall optimization for 3D models. (3) Underutilization: The fine-grained information inherent in the learned representations is often not fully exploited, indicating a potential loss in detail. To address these issues, we introduce JM3D, a comprehensive approach integrating point cloud, text, and image. Key contributions include the Structured Multimodal Organizer (SMO), enriching vision-language representation with multiple views and hierarchical text, and the Joint Multi-modal Alignment (JMA), combining language understanding with visual representation. Our advanced model, JM3D-LLM, marries 3D representation with large language models via efficient fine-tuning. Evaluations on ModelNet40 and ScanObjectNN establish JM3D's superiority. The superior performance of JM3D-LLM further underscores the effectiveness of our representation transfer approach. Our code and models are available at https://github.com/Mr-Neko/JM3D.
S3Aug: Segmentation, Sampling, and Shift for Action Recognition
Oct 23, 2023Action recognition is a well-established area of research in computer vision. In this paper, we propose S3Aug, a video data augmenatation for action recognition. Unlike conventional video data augmentation methods that involve cutting and pasting regions from two videos, the proposed method generates new videos from a single training video through segmentation and label-to-image transformation. Furthermore, the proposed method modifies certain categories of label images by sampling to generate a variety of videos, and shifts intermediate features to enhance the temporal coherency between frames of the generate videos. Experimental results on the UCF101, HMDB51, and Mimetics datasets demonstrate the effectiveness of the proposed method, paricularlly for out-of-context videos of the Mimetics dataset.
LXMERT Model Compression for Visual Question Answering
Oct 23, 2023Large-scale pretrained models such as LXMERT are becoming popular for learning cross-modal representations on text-image pairs for vision-language tasks. According to the lottery ticket hypothesis, NLP and computer vision models contain smaller subnetworks capable of being trained in isolation to full performance. In this paper, we combine these observations to evaluate whether such trainable subnetworks exist in LXMERT when fine-tuned on the VQA task. In addition, we perform a model size cost-benefit analysis by investigating how much pruning can be done without significant loss in accuracy. Our experiment results demonstrate that LXMERT can be effectively pruned by 40%-60% in size with 3% loss in accuracy.