 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
General Image-to-Image Translation with One-Shot Image Guidance
Aug 05, 2023
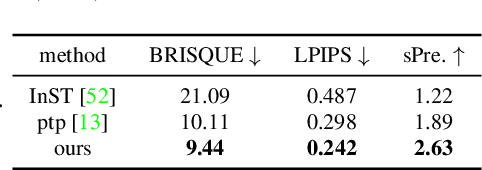
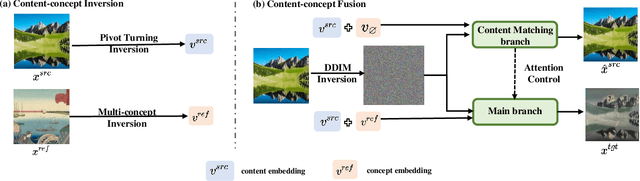
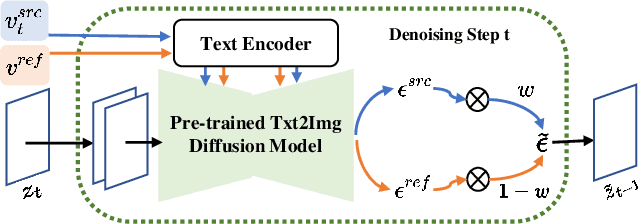
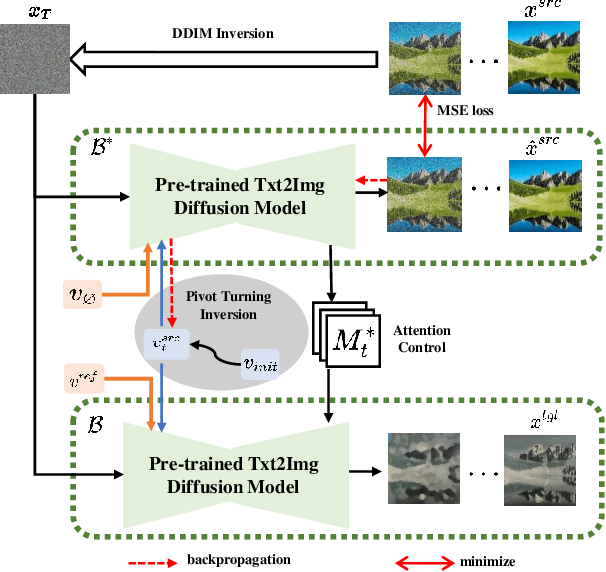
Large-scale text-to-image models pre-trained on massive text-image pairs show excellent performance in image synthesis recently. However, image can provide more intuitive visual concepts than plain text. People may ask: how can we integrate the desired visual concept into an existing image, such as our portrait? Current methods are inadequate in meeting this demand as they lack the ability to preserve content or translate visual concepts effectively. Inspired by this, we propose a novel framework named visual concept translator (VCT) with the ability to preserve content in the source image and translate the visual concepts guided by a single reference image. The proposed VCT contains a content-concept inversion (CCI) process to extract contents and concepts, and a content-concept fusion (CCF) process to gather the extracted information to obtain the target image. Given only one reference image, the proposed VCT can complete a wide range of general image-to-image translation tasks with excellent results. Extensive experiments are conducted to prove the superiority and effectiveness of the proposed methods. Codes are available at https://github.com/CrystalNeuro/visual-concept-translator.
GNeSF: Generalizable Neural Semantic Fields
Oct 26, 20233D scene segmentation based on neural implicit representation has emerged recently with the advantage of training only on 2D supervision. However, existing approaches still requires expensive per-scene optimization that prohibits generalization to novel scenes during inference. To circumvent this problem, we introduce a generalizable 3D segmentation framework based on implicit representation. Specifically, our framework takes in multi-view image features and semantic maps as the inputs instead of only spatial information to avoid overfitting to scene-specific geometric and semantic information. We propose a novel soft voting mechanism to aggregate the 2D semantic information from different views for each 3D point. In addition to the image features, view difference information is also encoded in our framework to predict the voting scores. Intuitively, this allows the semantic information from nearby views to contribute more compared to distant ones. Furthermore, a visibility module is also designed to detect and filter out detrimental information from occluded views. Due to the generalizability of our proposed method, we can synthesize semantic maps or conduct 3D semantic segmentation for novel scenes with solely 2D semantic supervision. Experimental results show that our approach achieves comparable performance with scene-specific approaches. More importantly, our approach can even outperform existing strong supervision-based approaches with only 2D annotations. Our source code is available at: https://github.com/HLinChen/GNeSF.
Feature Extraction and Classification from Planetary Science Datasets enabled by Machine Learning
Oct 26, 2023In this paper we present two examples of recent investigations that we have undertaken, applying Machine Learning (ML) neural networks (NN) to image datasets from outer planet missions to achieve feature recognition. Our first investigation was to recognize ice blocks (also known as rafts, plates, polygons) in the chaos regions of fractured ice on Europa. We used a transfer learning approach, adding and training new layers to an industry-standard Mask R-CNN (Region-based Convolutional Neural Network) to recognize labeled blocks in a training dataset. Subsequently, the updated model was tested against a new dataset, achieving 68% precision. In a different application, we applied the Mask R-CNN to recognize clouds on Titan, again through updated training followed by testing against new data, with a precision of 95% over 369 images. We evaluate the relative successes of our techniques and suggest how training and recognition could be further improved. The new approaches we have used for planetary datasets can further be applied to similar recognition tasks on other planets, including Earth. For imagery of outer planets in particular, the technique holds the possibility of greatly reducing the volume of returned data, via onboard identification of the most interesting image subsets, or by returning only differential data (images where changes have occurred) greatly enhancing the information content of the final data stream.
SAM-Deblur: Let Segment Anything Boost Image Deblurring
Sep 05, 2023
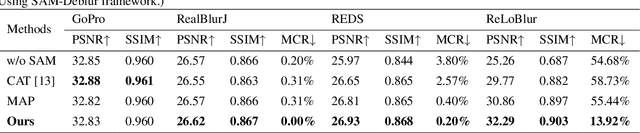

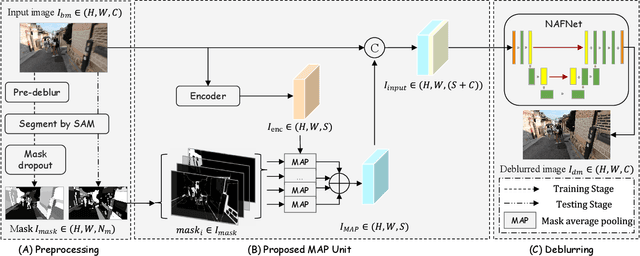
Image deblurring is a critical task in the field of image restoration, aiming to eliminate blurring artifacts. However, the challenge of addressing non-uniform blurring leads to an ill-posed problem, which limits the generalization performance of existing deblurring models. To solve the problem, we propose a framework SAM-Deblur, integrating prior knowledge from the Segment Anything Model (SAM) into the deblurring task for the first time. In particular, SAM-Deblur is divided into three stages. First, We preprocess the blurred images, obtain image masks via SAM, and propose a mask dropout method for training to enhance model robustness. Then, to fully leverage the structural priors generated by SAM, we propose a Mask Average Pooling (MAP) unit specifically designed to average SAM-generated segmented areas, serving as a plug-and-play component which can be seamlessly integrated into existing deblurring networks. Finally, we feed the fused features generated by the MAP Unit into the deblurring model to obtain a sharp image. Experimental results on the RealBlurJ, ReloBlur, and REDS datasets reveal that incorporating our methods improves NAFNet's PSNR by 0.05, 0.96, and 7.03, respectively. Code will be available at \href{https://github.com/HPLQAQ/SAM-Deblur}{SAM-Deblur}.
Transparent Anomaly Detection via Concept-based Explanations
Nov 01, 2023Advancements in deep learning techniques have given a boost to the performance of anomaly detection. However, real-world and safety-critical applications demand a level of transparency and reasoning beyond accuracy. The task of anomaly detection (AD) focuses on finding whether a given sample follows the learned distribution. Existing methods lack the ability to reason with clear explanations for their outcomes. Hence to overcome this challenge, we propose Transparent {A}nomaly Detection {C}oncept {E}xplanations (ACE). ACE is able to provide human interpretable explanations in the form of concepts along with anomaly prediction. To the best of our knowledge, this is the first paper that proposes interpretable by-design anomaly detection. In addition to promoting transparency in AD, it allows for effective human-model interaction. Our proposed model shows either higher or comparable results to black-box uninterpretable models. We validate the performance of ACE across three realistic datasets - bird classification on CUB-200-2011, challenging histopathology slide image classification on TIL-WSI-TCGA, and gender classification on CelebA. We further demonstrate that our concept learning paradigm can be seamlessly integrated with other classification-based AD methods.
fMRI-PTE: A Large-scale fMRI Pretrained Transformer Encoder for Multi-Subject Brain Activity Decoding
Nov 01, 2023The exploration of brain activity and its decoding from fMRI data has been a longstanding pursuit, driven by its potential applications in brain-computer interfaces, medical diagnostics, and virtual reality. Previous approaches have primarily focused on individual subject analysis, highlighting the need for a more universal and adaptable framework, which is the core motivation behind our work. In this work, we propose fMRI-PTE, an innovative auto-encoder approach for fMRI pre-training, with a focus on addressing the challenges of varying fMRI data dimensions due to individual brain differences. Our approach involves transforming fMRI signals into unified 2D representations, ensuring consistency in dimensions and preserving distinct brain activity patterns. We introduce a novel learning strategy tailored for pre-training 2D fMRI images, enhancing the quality of reconstruction. fMRI-PTE's adaptability with image generators enables the generation of well-represented fMRI features, facilitating various downstream tasks, including within-subject and cross-subject brain activity decoding. Our contributions encompass introducing fMRI-PTE, innovative data transformation, efficient training, a novel learning strategy, and the universal applicability of our approach. Extensive experiments validate and support our claims, offering a promising foundation for further research in this domain.
Dual Conditioned Diffusion Models for Out-Of-Distribution Detection: Application to Fetal Ultrasound Videos
Nov 01, 2023Out-of-distribution (OOD) detection is essential to improve the reliability of machine learning models by detecting samples that do not belong to the training distribution. Detecting OOD samples effectively in certain tasks can pose a challenge because of the substantial heterogeneity within the in-distribution (ID), and the high structural similarity between ID and OOD classes. For instance, when detecting heart views in fetal ultrasound videos there is a high structural similarity between the heart and other anatomies such as the abdomen, and large in-distribution variance as a heart has 5 distinct views and structural variations within each view. To detect OOD samples in this context, the resulting model should generalise to the intra-anatomy variations while rejecting similar OOD samples. In this paper, we introduce dual-conditioned diffusion models (DCDM) where we condition the model on in-distribution class information and latent features of the input image for reconstruction-based OOD detection. This constrains the generative manifold of the model to generate images structurally and semantically similar to those within the in-distribution. The proposed model outperforms reference methods with a 12% improvement in accuracy, 22% higher precision, and an 8% better F1 score.
Efficient Large Scale Medical Image Dataset Preparation for Machine Learning Applications
Sep 29, 2023In the rapidly evolving field of medical imaging, machine learning algorithms have become indispensable for enhancing diagnostic accuracy. However, the effectiveness of these algorithms is contingent upon the availability and organization of high-quality medical imaging datasets. Traditional Digital Imaging and Communications in Medicine (DICOM) data management systems are inadequate for handling the scale and complexity of data required to be facilitated in machine learning algorithms. This paper introduces an innovative data curation tool, developed as part of the Kaapana open-source toolkit, aimed at streamlining the organization, management, and processing of large-scale medical imaging datasets. The tool is specifically tailored to meet the needs of radiologists and machine learning researchers. It incorporates advanced search, auto-annotation and efficient tagging functionalities for improved data curation. Additionally, the tool facilitates quality control and review, enabling researchers to validate image and segmentation quality in large datasets. It also plays a critical role in uncovering potential biases in datasets by aggregating and visualizing metadata, which is essential for developing robust machine learning models. Furthermore, Kaapana is integrated within the Radiological Cooperative Network (RACOON), a pioneering initiative aimed at creating a comprehensive national infrastructure for the aggregation, transmission, and consolidation of radiological data across all university clinics throughout Germany. A supplementary video showcasing the tool's functionalities can be accessed at https://bit.ly/MICCAI-DEMI2023.
A plug-and-play synthetic data deep learning for undersampled magnetic resonance image reconstruction
Sep 13, 2023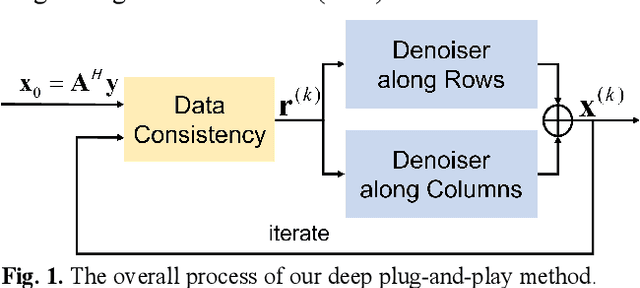
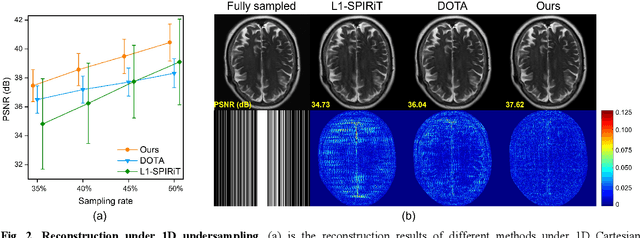
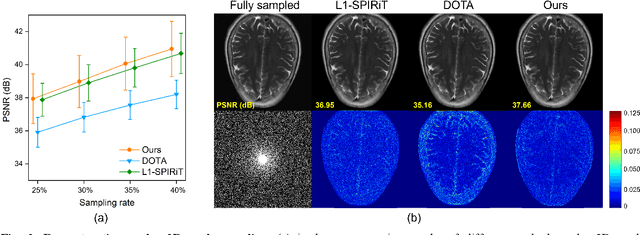
Magnetic resonance imaging (MRI) plays an important role in modern medical diagnostic but suffers from prolonged scan time. Current deep learning methods for undersampled MRI reconstruction exhibit good performance in image de-aliasing which can be tailored to the specific kspace undersampling scenario. But it is very troublesome to configure different deep networks when the sampling setting changes. In this work, we propose a deep plug-and-play method for undersampled MRI reconstruction, which effectively adapts to different sampling settings. Specifically, the image de-aliasing prior is first learned by a deep denoiser trained to remove general white Gaussian noise from synthetic data. Then the learned deep denoiser is plugged into an iterative algorithm for image reconstruction. Results on in vivo data demonstrate that the proposed method provides nice and robust accelerated image reconstruction performance under different undersampling patterns and sampling rates, both visually and quantitatively.
LinFlo-Net: A two-stage deep learning method to generate simulation ready meshes of the heart
Oct 30, 2023We present a deep learning model to automatically generate computer models of the human heart from patient imaging data with an emphasis on its capability to generate thin-walled cardiac structures. Our method works by deforming a template mesh to fit the cardiac structures to the given image. Compared with prior deep learning methods that adopted this approach, our framework is designed to minimize mesh self-penetration, which typically arises when deforming surface meshes separated by small distances. We achieve this by using a two-stage diffeomorphic deformation process along with a novel loss function derived from the kinematics of motion that penalizes surface contact and interpenetration. Our model demonstrates comparable accuracy with state-of-the-art methods while additionally producing meshes free of self-intersections. The resultant meshes are readily usable in physics based simulation, minimizing the need for post-processing and cleanup.