 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CLIP-QDA: An Explainable Concept Bottleneck Model
Nov 30, 2023
In this paper, we introduce an explainable algorithm designed from a multi-modal foundation model, that performs fast and explainable image classification. Drawing inspiration from CLIP-based Concept Bottleneck Models (CBMs), our method creates a latent space where each neuron is linked to a specific word. Observing that this latent space can be modeled with simple distributions, we use a Mixture of Gaussians (MoG) formalism to enhance the interpretability of this latent space. Then, we introduce CLIP-QDA, a classifier that only uses statistical values to infer labels from the concepts. In addition, this formalism allows for both local and global explanations. These explanations come from the inner design of our architecture, our work is part of a new family of greybox models, combining performances of opaque foundation models and the interpretability of transparent models. Our empirical findings show that in instances where the MoG assumption holds, CLIP-QDA achieves similar accuracy with state-of-the-art methods CBMs. Our explanations compete with existing XAI methods while being faster to compute.
CLAIR: Evaluating Image Captions with Large Language Models
Oct 19, 2023The evaluation of machine-generated image captions poses an interesting yet persistent challenge. Effective evaluation measures must consider numerous dimensions of similarity, including semantic relevance, visual structure, object interactions, caption diversity, and specificity. Existing highly-engineered measures attempt to capture specific aspects, but fall short in providing a holistic score that aligns closely with human judgments. Here, we propose CLAIR, a novel method that leverages the zero-shot language modeling capabilities of large language models (LLMs) to evaluate candidate captions. In our evaluations, CLAIR demonstrates a stronger correlation with human judgments of caption quality compared to existing measures. Notably, on Flickr8K-Expert, CLAIR achieves relative correlation improvements over SPICE of 39.6% and over image-augmented methods such as RefCLIP-S of 18.3%. Moreover, CLAIR provides noisily interpretable results by allowing the language model to identify the underlying reasoning behind its assigned score. Code is available at https://davidmchan.github.io/clair/
Towards image compression with perfect realism at ultra-low bitrates
Oct 16, 2023Image codecs are typically optimized to trade-off bitrate vs, distortion metrics. At low bitrates, this leads to compression artefacts which are easily perceptible, even when training with perceptual or adversarial losses. To improve image quality, and to make it less dependent on the bitrate, we propose to decode with iterative diffusion models, instead of feed-forward decoders trained using MSE or LPIPS distortions used in most neural codecs. In addition to conditioning the model on a vector-quantized image representation, we also condition on a global textual image description to provide additional context. We dub our model PerCo for 'perceptual compression', and compare it to state-of-the-art codecs at rates from 0.1 down to 0.003 bits per pixel. The latter rate is an order of magnitude smaller than those considered in most prior work. At this bitrate a 512x768 Kodak image is encoded in less than 153 bytes. Despite this ultra-low bitrate, our approach maintains the ability to reconstruct realistic images. We find that our model leads to reconstructions with state-of-the-art visual quality as measured by FID and KID, and that the visual quality is less dependent on the bitrate than previous methods.
Retrieval-Augmented Layout Transformer for Content-Aware Layout Generation
Nov 22, 2023Content-aware graphic layout generation aims to automatically arrange visual elements along with a given content, such as an e-commerce product image. In this paper, we argue that the current layout generation approaches suffer from the limited training data for the high-dimensional layout structure. We show that a simple retrieval augmentation can significantly improve the generation quality. Our model, which is named Retrieval-Augmented Layout Transformer (RALF), retrieves nearest neighbor layout examples based on an input image and feeds these results into an autoregressive generator. Our model can apply retrieval augmentation to various controllable generation tasks and yield high-quality layouts within a unified architecture. Our extensive experiments show that RALF successfully generates content-aware layouts in both constrained and unconstrained settings and significantly outperforms the baselines.
Learning Site-specific Styles for Multi-institutional Unsupervised Cross-modality Domain Adaptation
Nov 22, 2023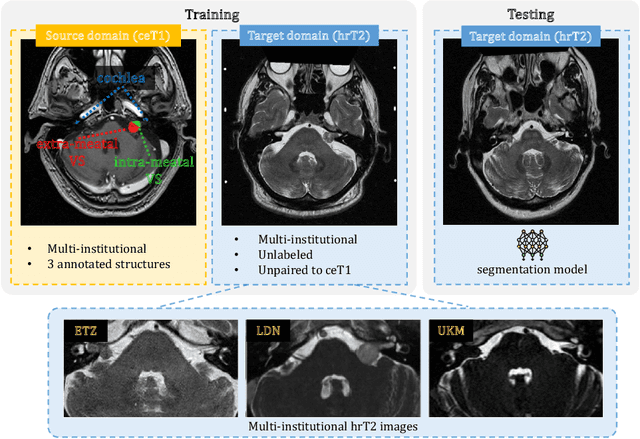
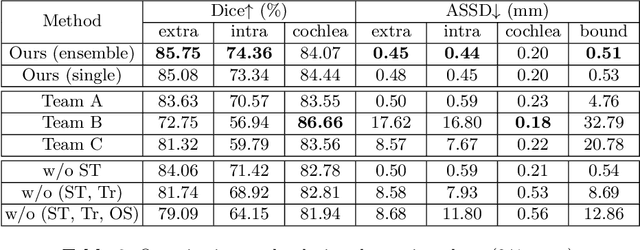
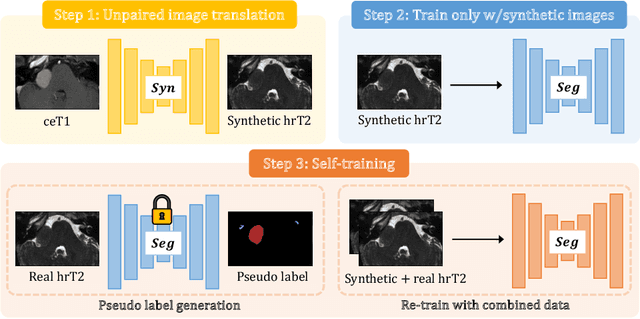
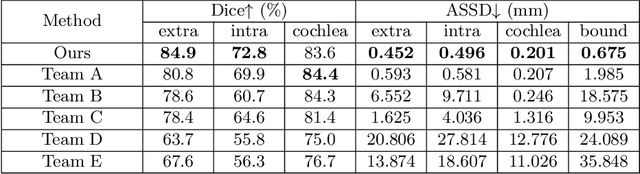
Unsupervised cross-modality domain adaptation is a challenging task in medical image analysis, and it becomes more challenging when source and target domain data are collected from multiple institutions. In this paper, we present our solution to tackle the multi-institutional unsupervised domain adaptation for the crossMoDA 2023 challenge. First, we perform unpaired image translation to translate the source domain images to the target domain, where we design a dynamic network to generate synthetic target domain images with controllable, site-specific styles. Afterwards, we train a segmentation model using the synthetic images and further reduce the domain gap by self-training. Our solution achieved the 1st place during both the validation and testing phases of the challenge. The code repository is publicly available at https://github.com/MedICL-VU/crossmoda2023.
OASIS: Offsetting Active Reconstruction Attacks in Federated Learning
Nov 23, 2023Federated Learning (FL) has garnered significant attention for its potential to protect user privacy while enhancing model training efficiency. However, recent research has demonstrated that FL protocols can be easily compromised by active reconstruction attacks executed by dishonest servers. These attacks involve the malicious modification of global model parameters, allowing the server to obtain a verbatim copy of users' private data by inverting their gradient updates. Tackling this class of attack remains a crucial challenge due to the strong threat model. In this paper, we propose OASIS, a defense mechanism based on image augmentation that effectively counteracts active reconstruction attacks while preserving model performance. We first uncover the core principle of gradient inversion that enables these attacks and theoretically identify the main conditions by which the defense can be robust regardless of the attack strategies. We then construct OASIS with image augmentation showing that it can undermine the attack principle. Comprehensive evaluations demonstrate the efficacy of OASIS highlighting its feasibility as a solution.
PF-LRM: Pose-Free Large Reconstruction Model for Joint Pose and Shape Prediction
Nov 23, 2023
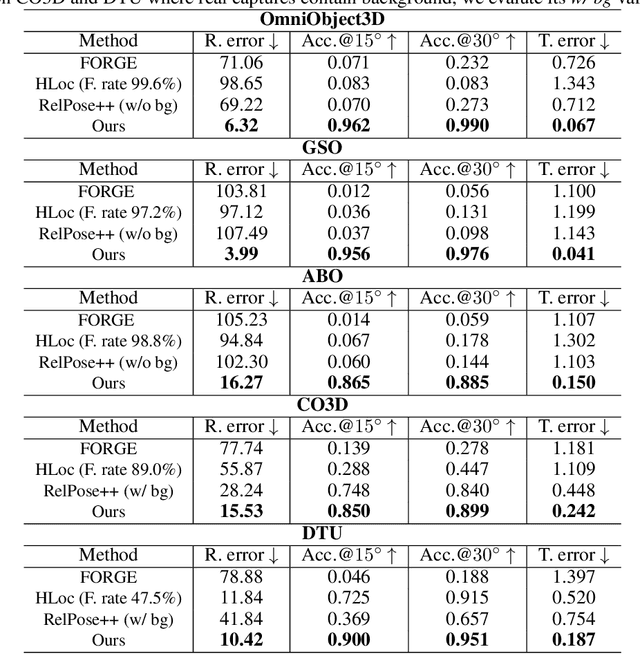
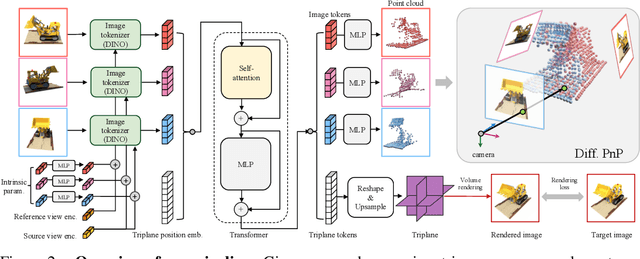
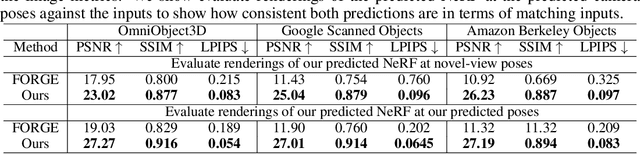
We propose a Pose-Free Large Reconstruction Model (PF-LRM) for reconstructing a 3D object from a few unposed images even with little visual overlap, while simultaneously estimating the relative camera poses in ~1.3 seconds on a single A100 GPU. PF-LRM is a highly scalable method utilizing the self-attention blocks to exchange information between 3D object tokens and 2D image tokens; we predict a coarse point cloud for each view, and then use a differentiable Perspective-n-Point (PnP) solver to obtain camera poses. When trained on a huge amount of multi-view posed data of ~1M objects, PF-LRM shows strong cross-dataset generalization ability, and outperforms baseline methods by a large margin in terms of pose prediction accuracy and 3D reconstruction quality on various unseen evaluation datasets. We also demonstrate our model's applicability in downstream text/image-to-3D task with fast feed-forward inference. Our project website is at: https://totoro97.github.io/pf-lrm .
Interpreting CLIP's Image Representation via Text-Based Decomposition
Oct 10, 2023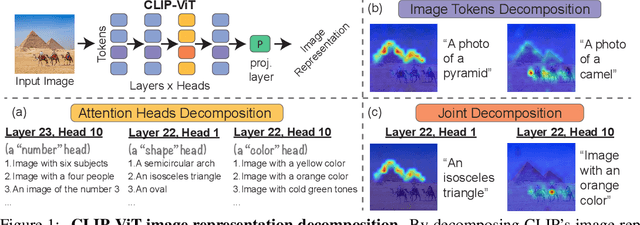
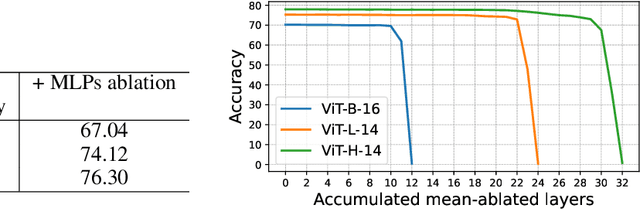

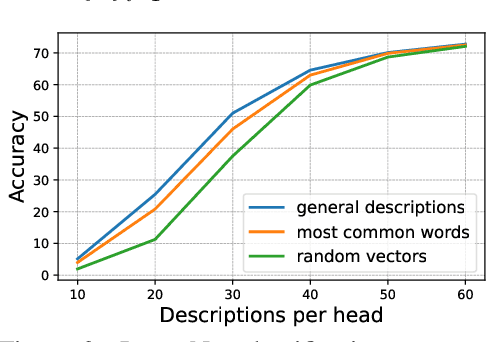
We investigate the CLIP image encoder by analyzing how individual model components affect the final representation. We decompose the image representation as a sum across individual image patches, model layers, and attention heads, and use CLIP's text representation to interpret the summands. Interpreting the attention heads, we characterize each head's role by automatically finding text representations that span its output space, which reveals property-specific roles for many heads (e.g. location or shape). Next, interpreting the image patches, we uncover an emergent spatial localization within CLIP. Finally, we use this understanding to remove spurious features from CLIP and to create a strong zero-shot image segmenter. Our results indicate that a scalable understanding of transformer models is attainable and can be used to repair and improve models.
Rethinking Skip Connections in Spiking Neural Networks with Time-To-First-Spike Coding
Dec 01, 2023Time-To-First-Spike (TTFS) coding in Spiking Neural Networks (SNNs) offers significant advantages in terms of energy efficiency, closely mimicking the behavior of biological neurons. In this work, we delve into the role of skip connections, a widely used concept in Artificial Neural Networks (ANNs), within the domain of SNNs with TTFS coding. Our focus is on two distinct types of skip connection architectures: (1) addition-based skip connections, and (2) concatenation-based skip connections. We find that addition-based skip connections introduce an additional delay in terms of spike timing. On the other hand, concatenation-based skip connections circumvent this delay but produce time gaps between after-convolution and skip connection paths, thereby restricting the effective mixing of information from these two paths. To mitigate these issues, we propose a novel approach involving a learnable delay for skip connections in the concatenation-based skip connection architecture. This approach successfully bridges the time gap between the convolutional and skip branches, facilitating improved information mixing. We conduct experiments on public datasets including MNIST and Fashion-MNIST, illustrating the advantage of the skip connection in TTFS coding architectures. Additionally, we demonstrate the applicability of TTFS coding on beyond image recognition tasks and extend it to scientific machine-learning tasks, broadening the potential uses of SNNs.
Motion-Guided Latent Diffusion for Temporally Consistent Real-world Video Super-resolution
Dec 01, 2023Real-world low-resolution (LR) videos have diverse and complex degradations, imposing great challenges on video super-resolution (VSR) algorithms to reproduce their high-resolution (HR) counterparts with high quality. Recently, the diffusion models have shown compelling performance in generating realistic details for image restoration tasks. However, the diffusion process has randomness, making it hard to control the contents of restored images. This issue becomes more serious when applying diffusion models to VSR tasks because temporal consistency is crucial to the perceptual quality of videos. In this paper, we propose an effective real-world VSR algorithm by leveraging the strength of pre-trained latent diffusion models. To ensure the content consistency among adjacent frames, we exploit the temporal dynamics in LR videos to guide the diffusion process by optimizing the latent sampling path with a motion-guided loss, ensuring that the generated HR video maintains a coherent and continuous visual flow. To further mitigate the discontinuity of generated details, we insert temporal module to the decoder and fine-tune it with an innovative sequence-oriented loss. The proposed motion-guided latent diffusion (MGLD) based VSR algorithm achieves significantly better perceptual quality than state-of-the-arts on real-world VSR benchmark datasets, validating the effectiveness of the proposed model design and training strategies.