 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Stage Multi-Modal Pre-Training for Automatic Speech Recognition
Mar 28, 2024



Recent advances in machine learning have demonstrated that multi-modal pre-training can improve automatic speech recognition (ASR) performance compared to randomly initialized models, even when models are fine-tuned on uni-modal tasks. Existing multi-modal pre-training methods for the ASR task have primarily focused on single-stage pre-training where a single unsupervised task is used for pre-training followed by fine-tuning on the downstream task. In this work, we introduce a novel method combining multi-modal and multi-task unsupervised pre-training with a translation-based supervised mid-training approach. We empirically demonstrate that such a multi-stage approach leads to relative word error rate (WER) improvements of up to 38.45% over baselines on both Librispeech and SUPERB. Additionally, we share several important findings for choosing pre-training methods and datasets.
conv_einsum: A Framework for Representation and Fast Evaluation of Multilinear Operations in Convolutional Tensorial Neural Networks
Jan 07, 2024



Modern ConvNets continue to achieve state-of-the-art results over a vast array of vision and image classification tasks, but at the cost of increasing parameters. One strategy for compactifying a network without sacrificing much expressive power is to reshape it into a tensorial neural network (TNN), which is a higher-order tensorization of its layers, followed by a factorization, such as a CP-decomposition, which strips a weight down to its critical basis components. Passes through TNNs can be represented as sequences of multilinear operations (MLOs), where the evaluation path can greatly affect the number of floating point operations (FLOPs) incurred. While functions such as the popular einsum can evaluate simple MLOs such as contractions, existing implementations cannot process multi-way convolutions, resulting in scant assessments of how optimal evaluation paths through tensorized convolutional layers can improve training speed. In this paper, we develop a unifying framework for representing tensorial convolution layers as einsum-like strings and a meta-algorithm conv_einsum which is able to evaluate these strings in a FLOPs-minimizing manner. Comprehensive experiments, using our open-source implementation, over a wide range of models, tensor decompositions, and diverse tasks, demonstrate that conv_einsum significantly increases both computational and memory-efficiency of convolutional TNNs.
See, Say, and Segment: Teaching LMMs to Overcome False Premises
Dec 13, 2023



Current open-source Large Multimodal Models (LMMs) excel at tasks such as open-vocabulary language grounding and segmentation but can suffer under false premises when queries imply the existence of something that is not actually present in the image. We observe that existing methods that fine-tune an LMM to segment images significantly degrade their ability to reliably determine ("see") if an object is present and to interact naturally with humans ("say"), a form of catastrophic forgetting. In this work, we propose a cascading and joint training approach for LMMs to solve this task, avoiding catastrophic forgetting of previous skills. Our resulting model can "see" by detecting whether objects are present in an image, "say" by telling the user if they are not, proposing alternative queries or correcting semantic errors in the query, and finally "segment" by outputting the mask of the desired objects if they exist. Additionally, we introduce a novel False Premise Correction benchmark dataset, an extension of existing RefCOCO(+/g) referring segmentation datasets (which we call FP-RefCOCO(+/g)). The results show that our method not only detects false premises up to 55% better than existing approaches, but under false premise conditions produces relative cIOU improvements of more than 31% over baselines, and produces natural language feedback judged helpful up to 67% of the time.
CLAIR: Evaluating Image Captions with Large Language Models
Oct 19, 2023



The evaluation of machine-generated image captions poses an interesting yet persistent challenge. Effective evaluation measures must consider numerous dimensions of similarity, including semantic relevance, visual structure, object interactions, caption diversity, and specificity. Existing highly-engineered measures attempt to capture specific aspects, but fall short in providing a holistic score that aligns closely with human judgments. Here, we propose CLAIR, a novel method that leverages the zero-shot language modeling capabilities of large language models (LLMs) to evaluate candidate captions. In our evaluations, CLAIR demonstrates a stronger correlation with human judgments of caption quality compared to existing measures. Notably, on Flickr8K-Expert, CLAIR achieves relative correlation improvements over SPICE of 39.6% and over image-augmented methods such as RefCLIP-S of 18.3%. Moreover, CLAIR provides noisily interpretable results by allowing the language model to identify the underlying reasoning behind its assigned score. Code is available at https://davidmchan.github.io/clair/
Scalable and Accurate Self-supervised Multimodal Representation Learning without Aligned Video and Text Data
Apr 04, 2023



Scaling up weakly-supervised datasets has shown to be highly effective in the image-text domain and has contributed to most of the recent state-of-the-art computer vision and multimodal neural networks. However, existing large-scale video-text datasets and mining techniques suffer from several limitations, such as the scarcity of aligned data, the lack of diversity in the data, and the difficulty of collecting aligned data. Currently popular video-text data mining approach via automatic speech recognition (ASR) used in HowTo100M provides low-quality captions that often do not refer to the video content. Other mining approaches do not provide proper language descriptions (video tags) and are biased toward short clips (alt text). In this work, we show how recent advances in image captioning allow us to pre-train high-quality video models without any parallel video-text data. We pre-train several video captioning models that are based on an OPT language model and a TimeSformer visual backbone. We fine-tune these networks on several video captioning datasets. First, we demonstrate that image captioning pseudolabels work better for pre-training than the existing HowTo100M ASR captions. Second, we show that pre-training on both images and videos produces a significantly better network (+4 CIDER on MSR-VTT) than pre-training on a single modality. Our methods are complementary to the existing pre-training or data mining approaches and can be used in a variety of settings. Given the efficacy of the pseudolabeling method, we are planning to publicly release the generated captions.
LAVA: Language Audio Vision Alignment for Contrastive Video Pre-Training
Jul 16, 2022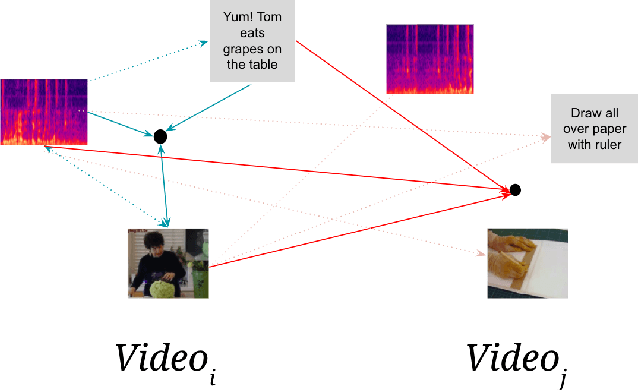
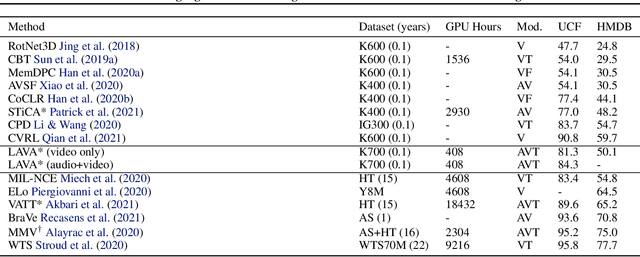
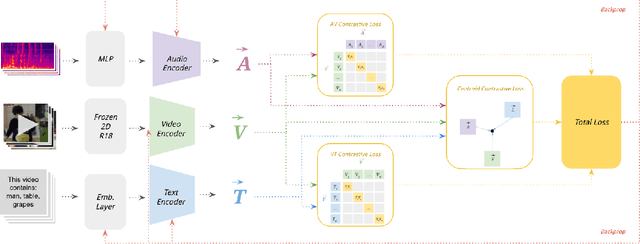
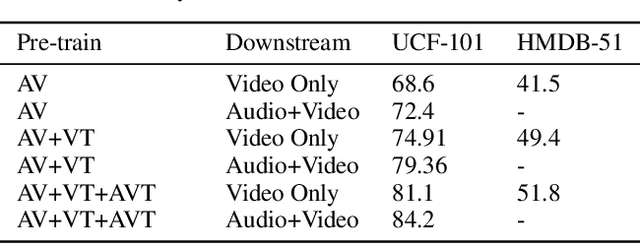
Generating representations of video data is of key importance in advancing the field of machine perception. Most current techniques rely on hand-annotated data, which can be difficult to work with, expensive to generate, and hard to scale. In this work, we propose a novel learning approach based on contrastive learning, LAVA, which is capable of learning joint language, audio, and video representations in a self-supervised manner. We pre-train LAVA on the Kinetics 700 dataset using transformer encoders to learn representations for each modality. We then demonstrate that LAVA performs competitively with the current state-of-the-art self-supervised and weakly-supervised pretraining techniques on UCF-101 and HMDB-51 video action recognition while using a fraction of the unlabeled data.
Misinformation Detection in Social Media Video Posts
Feb 15, 2022
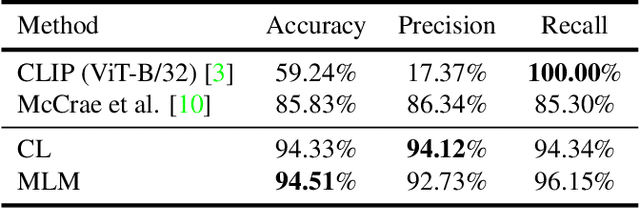
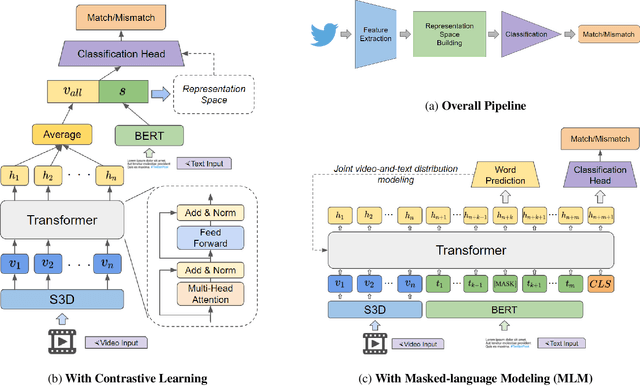
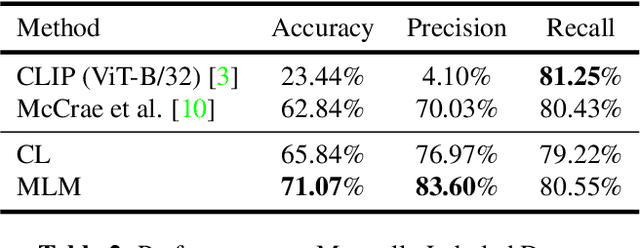
With the growing adoption of short-form video by social media platforms, reducing the spread of misinformation through video posts has become a critical challenge for social media providers. In this paper, we develop methods to detect misinformation in social media posts, exploiting modalities such as video and text. Due to the lack of large-scale public data for misinformation detection in multi-modal datasets, we collect 160,000 video posts from Twitter, and leverage self-supervised learning to learn expressive representations of joint visual and textual data. In this work, we propose two new methods for detecting semantic inconsistencies within short-form social media video posts, based on contrastive learning and masked language modeling. We demonstrate that our new approaches outperform current state-of-the-art methods on both artificial data generated by random-swapping of positive samples and in the wild on a new manually-labeled test set for semantic misinformation.
Decision Tree-Based Predictive Models for Academic Achievement Using College Students' Support Networks
Aug 31, 2021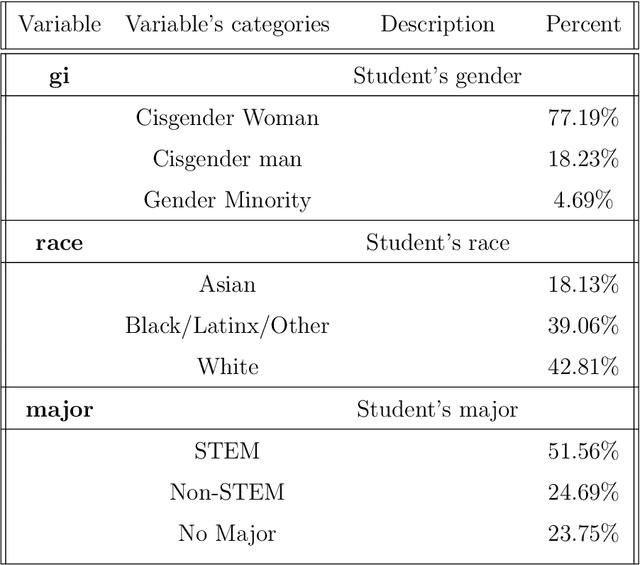

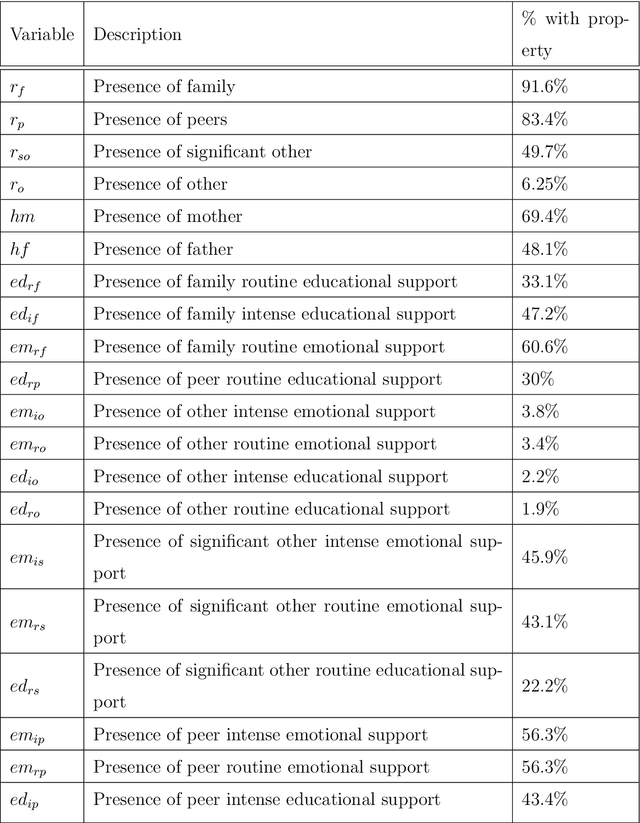

In this study, we examine a set of primary data collected from 484 students enrolled in a large public university in the Mid-Atlantic United States region during the early stages of the COVID-19 pandemic. The data, called Ties data, included students' demographic and support network information. The support network data comprised of information that highlighted the type of support, (i.e. emotional or educational; routine or intense). Using this data set, models for predicting students' academic achievement, quantified by their self-reported GPA, were created using Chi-Square Automatic Interaction Detection (CHAID), a decision tree algorithm, and cforest, a random forest algorithm that uses conditional inference trees. We compare the methods' accuracy and variation in the set of important variables suggested by each algorithm. Each algorithm found different variables important for different student demographics with some overlap. For White students, different types of educational support were important in predicting academic achievement, while for non-White students, different types of emotional support were important in predicting academic achievement. The presence of differing types of routine support were important in predicting academic achievement for cisgender women, while differing types of intense support were important in predicting academic achievement for cisgender men.
A Dataset and Benchmarks for Multimedia Social Analysis
Jun 05, 2020
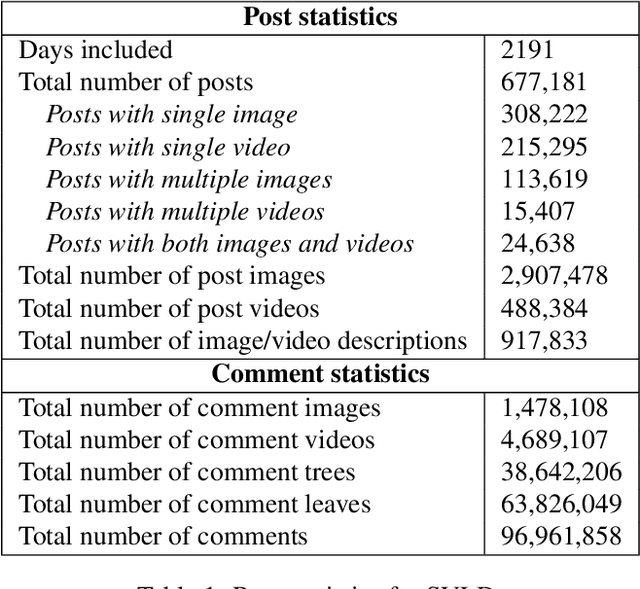
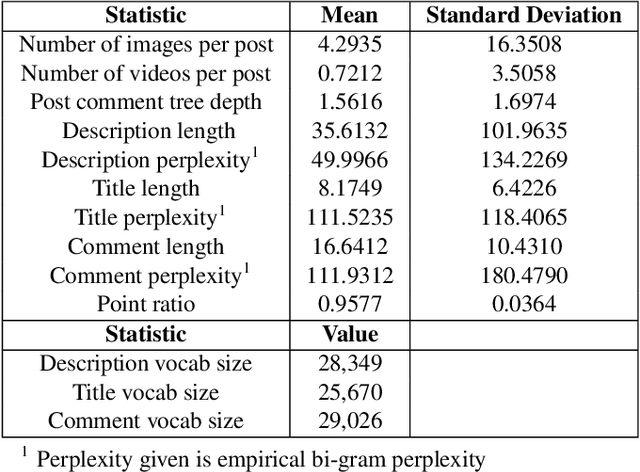
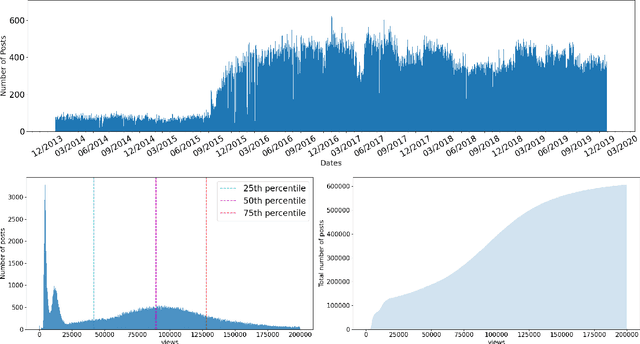
We present a new publicly available dataset with the goal of advancing multi-modality learning by offering vision and language data within the same context. This is achieved by obtaining data from a social media website with posts containing multiple paired images/videos and text, along with comment trees containing images/videos and/or text. With a total of 677k posts, 2.9 million post images, 488k post videos, 1.4 million comment images, 4.6 million comment videos, and 96.9 million comments, data from different modalities can be jointly used to improve performances for a variety of tasks such as image captioning, image classification, next frame prediction, sentiment analysis, and language modeling. We present a wide range of statistics for our dataset. Finally, we provide baseline performance analysis for one of the regression tasks using pre-trained models and several fully connected networks.
ZPD Teaching Strategies for Deep Reinforcement Learning from Demonstrations
Oct 26, 2019

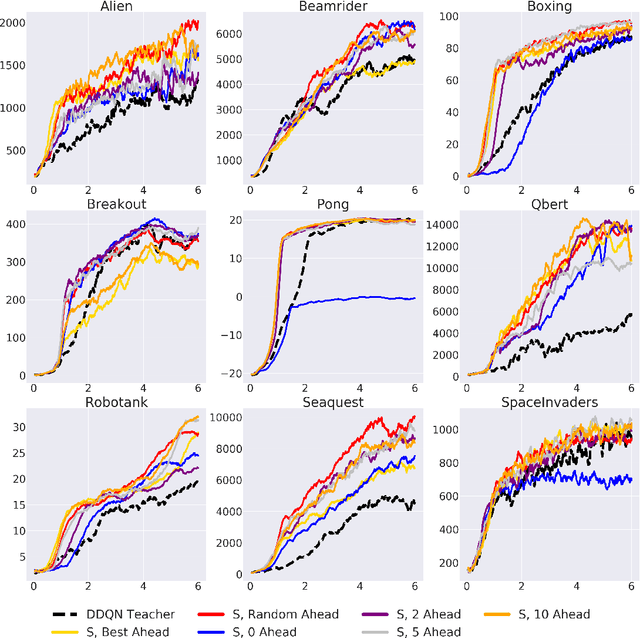

Learning from demonstrations is a popular tool for accelerating and reducing the exploration requirements of reinforcement learning. When providing expert demonstrations to human students, we know that the demonstrations must fall within a particular range of difficulties called the "Zone of Proximal Development (ZPD)". If they are too easy the student learns nothing, but if they are too difficult the student is unable to follow along. This raises the question: Given a set of potential demonstrators, which among them is best suited for teaching any particular learner? Prior work, such as the popular Deep Q-learning from Demonstrations (DQfD) algorithm has generally focused on single demonstrators. In this work we consider the problem of choosing among multiple demonstrators of varying skill levels. Our results align with intuition from human learners: it is not always the best policy to draw demonstrations from the best performing demonstrator (in terms of reward). We show that careful selection of teaching strategies can result in sample efficiency gains in the learner's environment across nine Atari games