 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Global Feature Pyramid Network
Dec 18, 2023
The visual feature pyramid has proven its effectiveness and efficiency in target detection tasks. Yet, current methodologies tend to overly emphasize inter-layer feature interaction, neglecting the crucial aspect of intra-layer feature adjustment. Experience underscores the significant advantages of intra-layer feature interaction in enhancing target detection tasks. While some approaches endeavor to learn condensed intra-layer feature representations using attention mechanisms or visual transformers, they overlook the incorporation of global information interaction. This oversight results in increased false detections and missed targets.To address this critical issue, this paper introduces the Global Feature Pyramid Network (GFPNet), an augmented version of PAFPN that integrates global information for enhanced target detection. Specifically, we leverage a lightweight MLP to capture global feature information, utilize the VNC encoder to process these features, and employ a parallel learnable mechanism to extract intra-layer features from the input image. Building on this foundation, we retain the PAFPN method to facilitate inter-layer feature interaction, extracting rich feature details across various levels.Compared to conventional feature pyramids, GFPN not only effectively focuses on inter-layer feature information but also captures global feature details, fostering intra-layer feature interaction and generating a more comprehensive and impactful feature representation. GFPN consistently demonstrates performance improvements over object detection baselines.
Diffusion Handles: Enabling 3D Edits for Diffusion Models by Lifting Activations to 3D
Dec 06, 2023


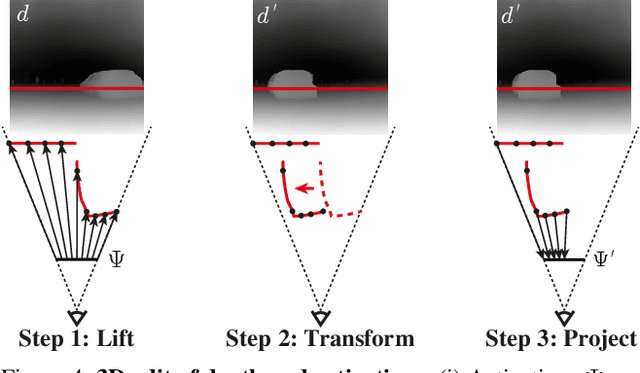
Diffusion Handles is a novel approach to enabling 3D object edits on diffusion images. We accomplish these edits using existing pre-trained diffusion models, and 2D image depth estimation, without any fine-tuning or 3D object retrieval. The edited results remain plausible, photo-real, and preserve object identity. Diffusion Handles address a critically missing facet of generative image based creative design, and significantly advance the state-of-the-art in generative image editing. Our key insight is to lift diffusion activations for an object to 3D using a proxy depth, 3D-transform the depth and associated activations, and project them back to image space. The diffusion process applied to the manipulated activations with identity control, produces plausible edited images showing complex 3D occlusion and lighting effects. We evaluate Diffusion Handles: quantitatively, on a large synthetic data benchmark; and qualitatively by a user study, showing our output to be more plausible, and better than prior art at both, 3D editing and identity control. Project Webpage: https://diffusionhandles.github.io/
MedISure: Towards Assuring Machine Learning-based Medical Image Classifiers using Mixup Boundary Analysis
Nov 23, 2023Machine learning (ML) models are becoming integral in healthcare technologies, presenting a critical need for formal assurance to validate their safety, fairness, robustness, and trustworthiness. These models are inherently prone to errors, potentially posing serious risks to patient health and could even cause irreparable harm. Traditional software assurance techniques rely on fixed code and do not directly apply to ML models since these algorithms are adaptable and learn from curated datasets through a training process. However, adapting established principles, such as boundary testing using synthetic test data can effectively bridge this gap. To this end, we present a novel technique called Mix-Up Boundary Analysis (MUBA) that facilitates evaluating image classifiers in terms of prediction fairness. We evaluated MUBA for two important medical imaging tasks -- brain tumour classification and breast cancer classification -- and achieved promising results. This research aims to showcase the importance of adapting traditional assurance principles for assessing ML models to enhance the safety and reliability of healthcare technologies. To facilitate future research, we plan to publicly release our code for MUBA.
VDIP-TGV: Blind Image Deconvolution via Variational Deep Image Prior Empowered by Total Generalized Variation
Oct 30, 2023Recovering clear images from blurry ones with an unknown blur kernel is a challenging problem. Deep image prior (DIP) proposes to use the deep network as a regularizer for a single image rather than as a supervised model, which achieves encouraging results in the nonblind deblurring problem. However, since the relationship between images and the network architectures is unclear, it is hard to find a suitable architecture to provide sufficient constraints on the estimated blur kernels and clean images. Also, DIP uses the sparse maximum a posteriori (MAP), which is insufficient to enforce the selection of the recovery image. Recently, variational deep image prior (VDIP) was proposed to impose constraints on both blur kernels and recovery images and take the standard deviation of the image into account during the optimization process by the variational principle. However, we empirically find that VDIP struggles with processing image details and tends to generate suboptimal results when the blur kernel is large. Therefore, we combine total generalized variational (TGV) regularization with VDIP in this paper to overcome these shortcomings of VDIP. TGV is a flexible regularization that utilizes the characteristics of partial derivatives of varying orders to regularize images at different scales, reducing oil painting artifacts while maintaining sharp edges. The proposed VDIP-TGV effectively recovers image edges and details by supplementing extra gradient information through TGV. Additionally, this model is solved by the alternating direction method of multipliers (ADMM), which effectively combines traditional algorithms and deep learning methods. Experiments show that our proposed VDIP-TGV surpasses various state-of-the-art models quantitatively and qualitatively.
Frequency Domain Decomposition Translation for Enhanced Medical Image Translation Using GANs
Nov 06, 2023Medical Image-to-image translation is a key task in computer vision and generative artificial intelligence, and it is highly applicable to medical image analysis. GAN-based methods are the mainstream image translation methods, but they often ignore the variation and distribution of images in the frequency domain, or only take simple measures to align high-frequency information, which can lead to distortion and low quality of the generated images. To solve these problems, we propose a novel method called frequency domain decomposition translation (FDDT). This method decomposes the original image into a high-frequency component and a low-frequency component, with the high-frequency component containing the details and identity information, and the low-frequency component containing the style information. Next, the high-frequency and low-frequency components of the transformed image are aligned with the transformed results of the high-frequency and low-frequency components of the original image in the same frequency band in the spatial domain, thus preserving the identity information of the image while destroying as little stylistic information of the image as possible. We conduct extensive experiments on MRI images and natural images with FDDT and several mainstream baseline models, and we use four evaluation metrics to assess the quality of the generated images. Compared with the baseline models, optimally, FDDT can reduce Fr\'echet inception distance by up to 24.4%, structural similarity by up to 4.4%, peak signal-to-noise ratio by up to 5.8%, and mean squared error by up to 31%. Compared with the previous method, optimally, FDDT can reduce Fr\'echet inception distance by up to 23.7%, structural similarity by up to 1.8%, peak signal-to-noise ratio by up to 6.8%, and mean squared error by up to 31.6%.
GeNIe: Generative Hard Negative Images Through Diffusion
Dec 05, 2023Data augmentation is crucial in training deep models, preventing them from overfitting to limited data. Common data augmentation methods are effective, but recent advancements in generative AI, such as diffusion models for image generation, enable more sophisticated augmentation techniques that produce data resembling natural images. We recognize that augmented samples closer to the ideal decision boundary of a classifier are particularly effective and efficient in guiding the learning process. We introduce GeNIe which leverages a diffusion model conditioned on a text prompt to merge contrasting data points (an image from the source category and a text prompt from the target category) to generate challenging samples for the target category. Inspired by recent image editing methods, we limit the number of diffusion iterations and the amount of noise. This ensures that the generated image retains low-level and contextual features from the source image, potentially conflicting with the target category. Our extensive experiments, in few-shot and also long-tail distribution settings, demonstrate the effectiveness of our novel augmentation method, especially benefiting categories with a limited number of examples.
COVIDx CXR-4: An Expanded Multi-Institutional Open-Source Benchmark Dataset for Chest X-ray Image-Based Computer-Aided COVID-19 Diagnostics
Nov 29, 2023The global ramifications of the COVID-19 pandemic remain significant, exerting persistent pressure on nations even three years after its initial outbreak. Deep learning models have shown promise in improving COVID-19 diagnostics but require diverse and larger-scale datasets to improve performance. In this paper, we introduce COVIDx CXR-4, an expanded multi-institutional open-source benchmark dataset for chest X-ray image-based computer-aided COVID-19 diagnostics. COVIDx CXR-4 expands significantly on the previous COVIDx CXR-3 dataset by increasing the total patient cohort size by greater than 2.66 times, resulting in 84,818 images from 45,342 patients across multiple institutions. We provide extensive analysis on the diversity of the patient demographic, imaging metadata, and disease distributions to highlight potential dataset biases. To the best of the authors' knowledge, COVIDx CXR-4 is the largest and most diverse open-source COVID-19 CXR dataset and is made publicly available as part of an open initiative to advance research to aid clinicians against the COVID-19 disease.
Cache Me if You Can: Accelerating Diffusion Models through Block Caching
Dec 06, 2023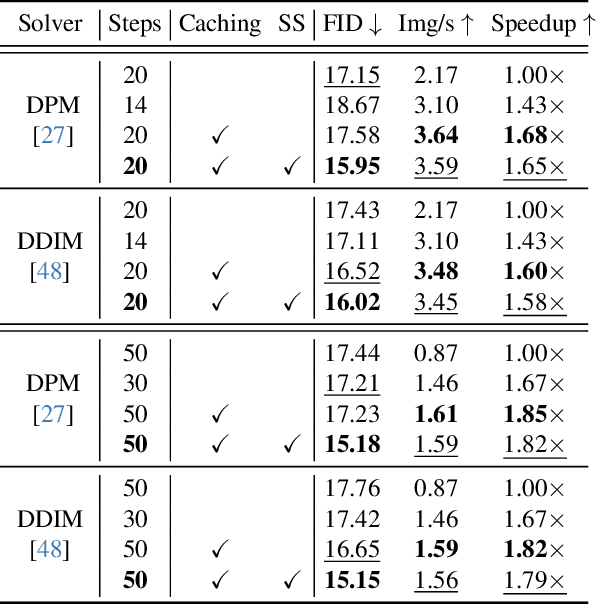

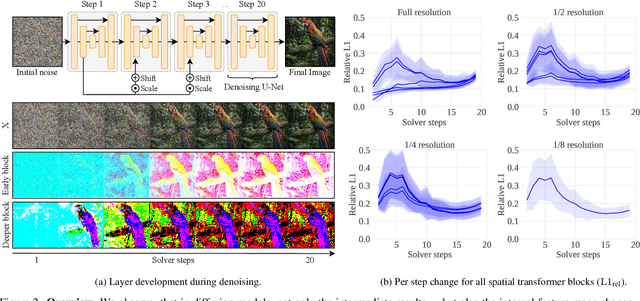
Diffusion models have recently revolutionized the field of image synthesis due to their ability to generate photorealistic images. However, one of the major drawbacks of diffusion models is that the image generation process is costly. A large image-to-image network has to be applied many times to iteratively refine an image from random noise. While many recent works propose techniques to reduce the number of required steps, they generally treat the underlying denoising network as a black box. In this work, we investigate the behavior of the layers within the network and find that 1) the layers' output changes smoothly over time, 2) the layers show distinct patterns of change, and 3) the change from step to step is often very small. We hypothesize that many layer computations in the denoising network are redundant. Leveraging this, we introduce block caching, in which we reuse outputs from layer blocks of previous steps to speed up inference. Furthermore, we propose a technique to automatically determine caching schedules based on each block's changes over timesteps. In our experiments, we show through FID, human evaluation and qualitative analysis that Block Caching allows to generate images with higher visual quality at the same computational cost. We demonstrate this for different state-of-the-art models (LDM and EMU) and solvers (DDIM and DPM).
Foundation Model Assisted Weakly Supervised Semantic Segmentation
Dec 06, 2023This work aims to leverage pre-trained foundation models, such as contrastive language-image pre-training (CLIP) and segment anything model (SAM), to address weakly supervised semantic segmentation (WSSS) using image-level labels. To this end, we propose a coarse-to-fine framework based on CLIP and SAM for generating high-quality segmentation seeds. Specifically, we construct an image classification task and a seed segmentation task, which are jointly performed by CLIP with frozen weights and two sets of learnable task-specific prompts. A SAM-based seeding (SAMS) module is designed and applied to each task to produce either coarse or fine seed maps. Moreover, we design a multi-label contrastive loss supervised by image-level labels and a CAM activation loss supervised by the generated coarse seed map. These losses are used to learn the prompts, which are the only parts need to be learned in our framework. Once the prompts are learned, we input each image along with the learned segmentation-specific prompts into CLIP and the SAMS module to produce high-quality segmentation seeds. These seeds serve as pseudo labels to train an off-the-shelf segmentation network like other two-stage WSSS methods. Experiments show that our method achieves the state-of-the-art performance on PASCAL VOC 2012 and competitive results on MS COCO 2014.
GPT4SGG: Synthesizing Scene Graphs from Holistic and Region-specific Narratives
Dec 07, 2023Learning scene graphs from natural language descriptions has proven to be a cheap and promising scheme for Scene Graph Generation (SGG). However, such unstructured caption data and its processing are troubling the learning an acurrate and complete scene graph. This dilema can be summarized as three points. First, traditional language parsers often fail to extract meaningful relationship triplets from caption data. Second, grounding unlocalized objects in parsed triplets will meet ambiguity in visual-language alignment. Last, caption data typically are sparse and exhibit bias to partial observations of image content. These three issues make it hard for the model to generate comprehensive and accurate scene graphs. To fill this gap, we propose a simple yet effective framework, GPT4SGG, to synthesize scene graphs from holistic and region-specific narratives. The framework discards traditional language parser, and localize objects before obtaining relationship triplets. To obtain relationship triplets, holistic and dense region-specific narratives are generated from the image. With such textual representation of image data and a task-specific prompt, an LLM, particularly GPT-4, directly synthesizes a scene graph as "pseudo labels". Experimental results showcase GPT4SGG significantly improves the performance of SGG models trained on image-caption data. We believe this pioneering work can motivate further research into mining the visual reasoning capabilities of LLMs.