 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Shearlets as Feature Extractor for Semantic Edge Detection: The Model-Based and Data-Driven Realm
Nov 27, 2019
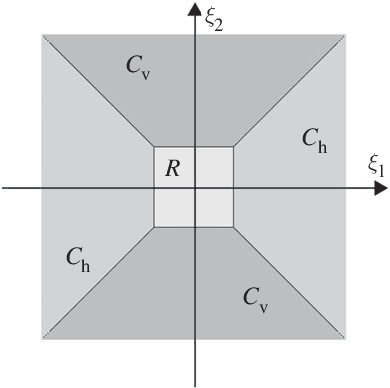

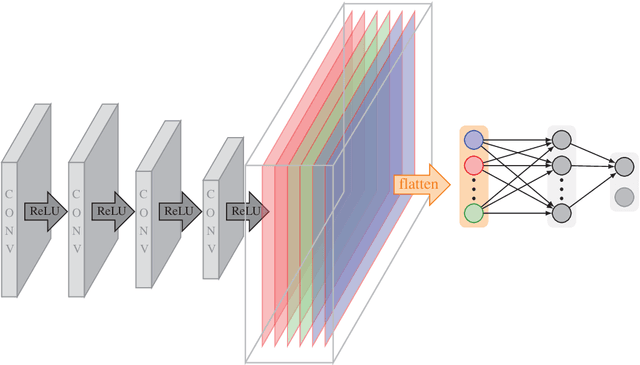
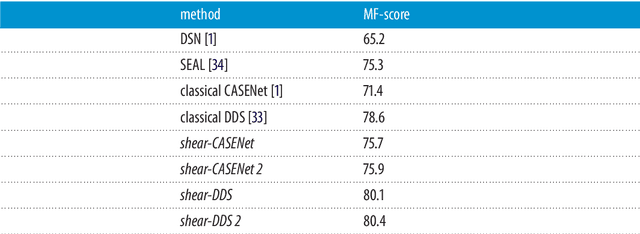
Semantic edge detection has recently gained a lot of attention as an image processing task, mainly due to its wide range of real-world applications. This is based on the fact that edges in images contain most of the semantic information. Semantic edge detection involves two tasks, namely pure edge detecion and edge classification. Those are in fact fundamentally distinct in terms of the level of abstraction that each task requires, which is known as the distracted supervision paradox that limits the possible performance of a supervised model in semantic edge detection. In this work, we will present a novel hybrid method to avoid the distracted supervision paradox and achieve high-performance in semantic edge detection. Our approach is based on a combination of the model-based concept of shearlets, which provides probably optimally sparse approximations of a model-class of images, and the data-driven method of a suitably designed convolutional neural netwok. Finally, we present several applications such as tomographic reconstruction and show that our approach signifiantly outperforms former methods, thereby indicating the value of such hybrid methods for the area in biomedical imaging.
Fine-grained lesion annotation in CT images with knowledge mined from radiology reports
Mar 26, 2019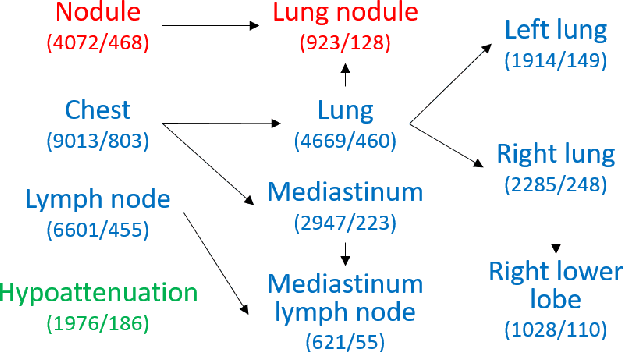
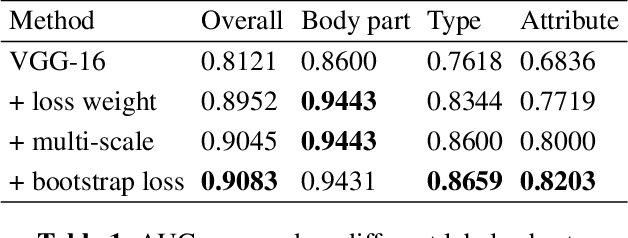

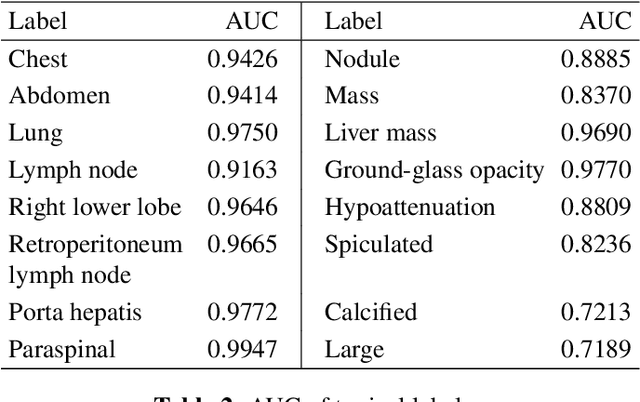
In radiologists' routine work, one major task is to read a medical image, e.g., a CT scan, find significant lesions, and write sentences in the radiology report to describe them. In this paper, we study the lesion description or annotation problem as an important step of computer-aided diagnosis (CAD). Given a lesion image, our aim is to predict multiple relevant labels, such as the lesion's body part, type, and attributes. To address this problem, we define a set of 145 labels based on RadLex to describe a large variety of lesions in the DeepLesion dataset. We directly mine training labels from the lesion's corresponding sentence in the radiology report, which requires minimal manual effort and is easily generalizable to large data and label sets. A multi-label convolutional neural network is then proposed for images with multi-scale structure and a noise-robust loss. Quantitative and qualitative experiments demonstrate the effectiveness of the framework. The average area under ROC curve on 1,872 test lesions is 0.9083.
Fast and Efficient Model for Real-Time Tiger Detection In The Wild
Sep 03, 2019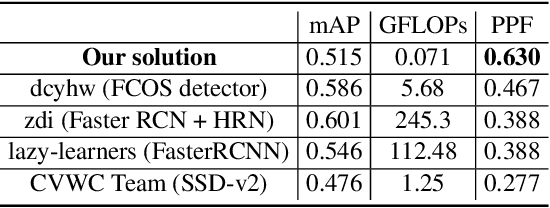
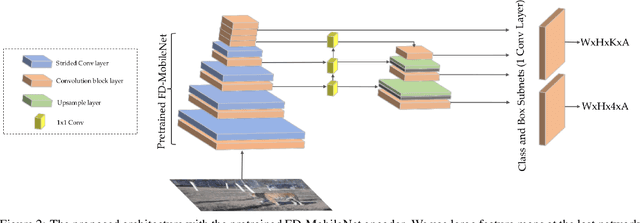


The highest accuracy object detectors to date are based either on a two-stage approach such as Fast R-CNN or one-stage detectors such as Retina-Net or SSD with deep and complex backbones. In this paper we present TigerNet - simple yet efficient FPN based network architecture for Amur Tiger Detection in the wild. The model has 600k parameters, requires 0.071 GFLOPs per image and can run on the edge devices (smart cameras) in near real time. In addition, we introduce a two-stage semi-supervised learning via pseudo-labelling learning approach to distill the knowledge from the larger networks. For ATRW-ICCV 2019 tiger detection sub-challenge, based on public leaderboard score, our approach shows superior performance in comparison to other methods.
Neuro-SERKET: Development of Integrative Cognitive System through the Composition of Deep Probabilistic Generative Models
Oct 20, 2019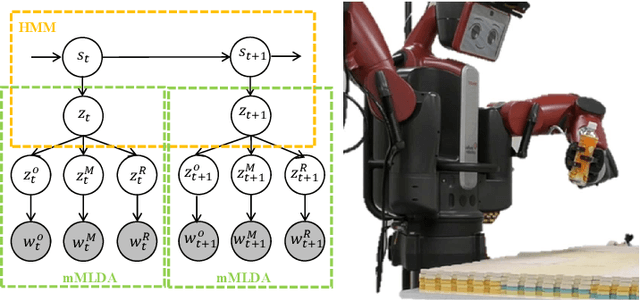

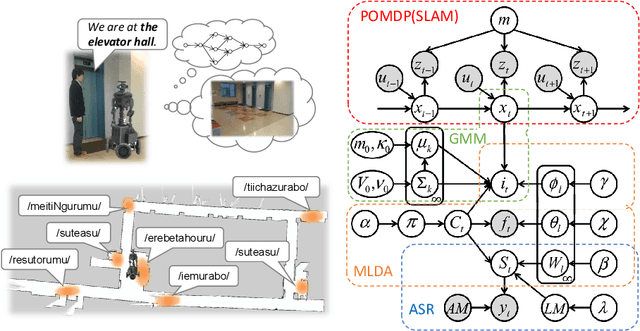
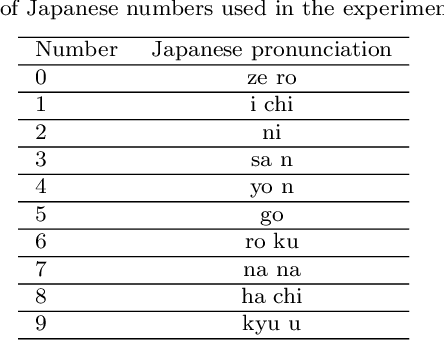
This paper describes a framework for the development of an integrative cognitive system based on probabilistic generative models (PGMs) called Neuro-SERKET. Neuro-SERKET is an extension of SERKET, which can compose elemental PGMs developed in a distributed manner and provide a scheme that allows the composed PGMs to learn throughout the system in an unsupervised way. In addition to the head-to-tail connection supported by SERKET, Neuro-SERKET supports tail-to-tail and head-to-head connections, as well as neural network-based modules, i.e., deep generative models. As an example of a Neuro-SERKET application, an integrative model was developed by composing a variational autoencoder (VAE), a Gaussian mixture model (GMM), latent Dirichlet allocation (LDA), and automatic speech recognition (ASR). The model is called VAE+GMM+LDA+ASR. The performance of VAE+GMM+LDA+ASR and the validity of Neuro-SERKET were demonstrated through a multimodal categorization task using image data and a speech signal of numerical digits.
Procrustes registration of two-dimensional statistical shape models without correspondences
Nov 27, 2019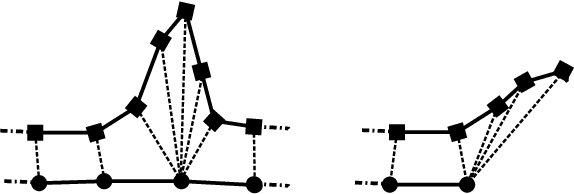
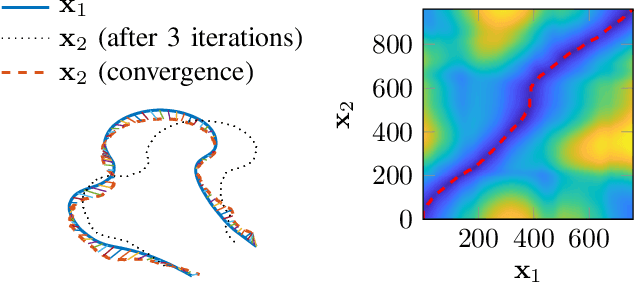

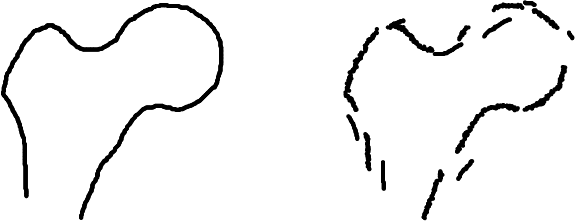
Statistical shape models are a useful tool in image processing and computer vision. A Procrustres registration of the contours of the same shape is typically perform to align the training samples to learn the statistical shape model. A Procrustes registration between two contours with known correspondences is straightforward. However, these correspondences are not generally available. Manually placed landmarks are often used for correspondence in the design of statistical shape models. However, determining manual landmarks on the contours is time-consuming and often error-prone. One solution to simultaneously find correspondence and registration is the Iterative Closest Point (ICP) algorithm. However, ICP requires an initial position of the contours that is close to registration, and it is not robust against outliers. We propose a new strategy, based on Dynamic Time Warping, that efficiently solves the Procrustes registration problem without correspondences. We study the registration performance in a collection of different shape data sets and show that our technique outperforms competing techniques based on the ICP approach. Our strategy is applied to an ensemble of contours of the same shape as an extension of the generalized Procrustes analysis accounting for a lack of correspondence.
DetNAS: Neural Architecture Search on Object Detection
Mar 26, 2019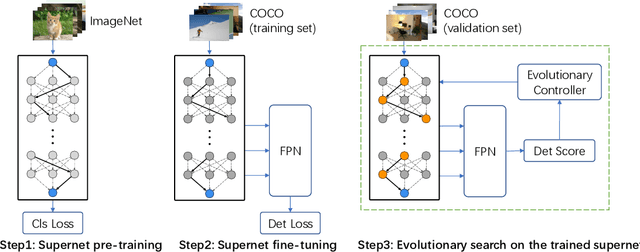
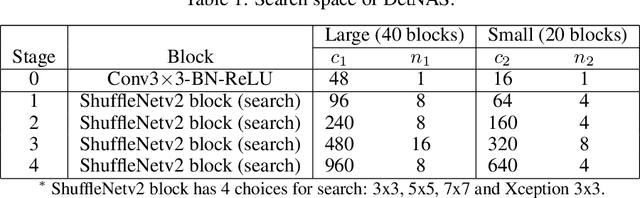
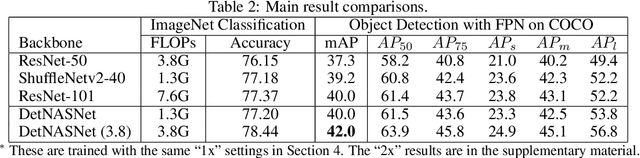
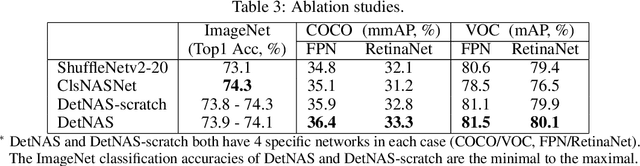
Object detectors are usually equipped with networks designed for image classification as backbones, e.g., ResNet. Although it is publicly known that there is a gap between the task of image classification and object detection, designing a suitable detector backbone is still manually exhaustive. In this paper, we propose DetNAS to automatically search neural architectures for the backbones of object detectors. In DetNAS, the search space is formulated into a supernet and the search method relies on evolution algorithm (EA). In experiments, we show the effectiveness of DetNAS on various detectors, the one-stage detector, RetinaNet, and the two-stage detector, FPN. For each case, we search in both training from scratch scheme and ImageNet pre-training scheme. There is a consistent superiority compared to the architectures searched on ImageNet classification. Our main result architecture achieves better performance than ResNet-101 on COCO with the FPN detector. In addition, we illustrate the architectures searched by DetNAS and find some meaningful patterns.
Believe It or Not, We Know What You Are Looking at!
Jul 04, 2019
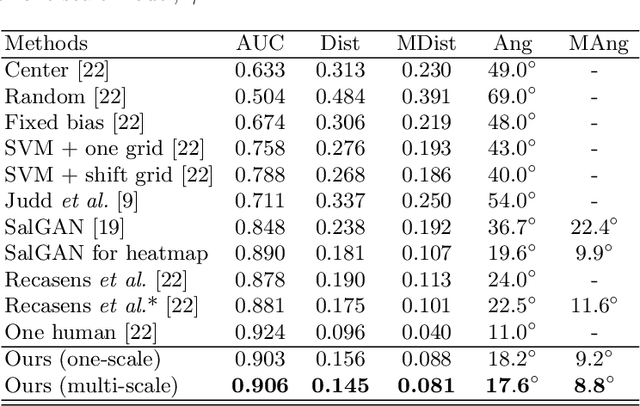
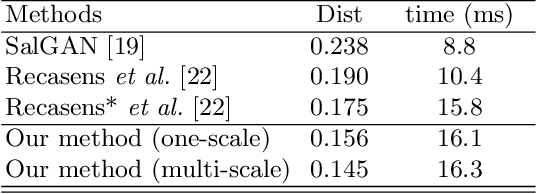
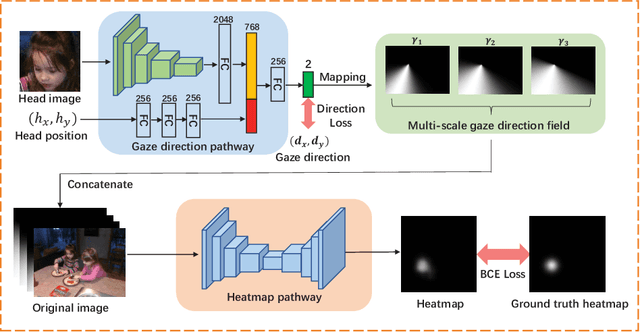
By borrowing the wisdom of human in gaze following, we propose a two-stage solution for gaze point prediction of the target persons in a scene. Specifically, in the first stage, both head image and its position are fed into a gaze direction pathway to predict the gaze direction, and then multi-scale gaze direction fields are generated to characterize the distribution of gaze points without considering the scene contents. In the second stage, the multi-scale gaze direction fields are concatenated with the image contents and fed into a heatmap pathway for heatmap regression. There are two merits for our two-stage solution based gaze following: i) our solution mimics the behavior of human in gaze following, therefore it is more psychological plausible; ii) besides using heatmap to supervise the output of our network, we can also leverage gaze direction to facilitate the training of gaze direction pathway, therefore our network can be more robustly trained. Considering that existing gaze following dataset is annotated by the third-view persons, we build a video gaze following dataset, where the ground truth is annotated by the observers in the videos. Therefore it is more reliable. The evaluation with such a dataset reflects the capacity of different methods in real scenarios better. Extensive experiments on both datasets show that our method significantly outperforms existing methods, which validates the effectiveness of our solution for gaze following. Our dataset and codes are released in https://github.com/svip-lab/GazeFollowing.
Hierarchical Cross-Modal Talking Face Generationwith Dynamic Pixel-Wise Loss
May 09, 2019

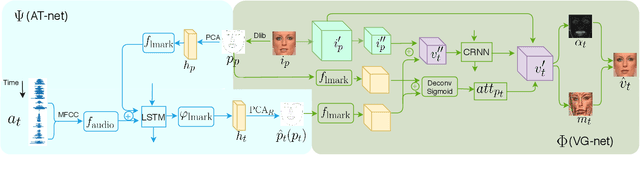
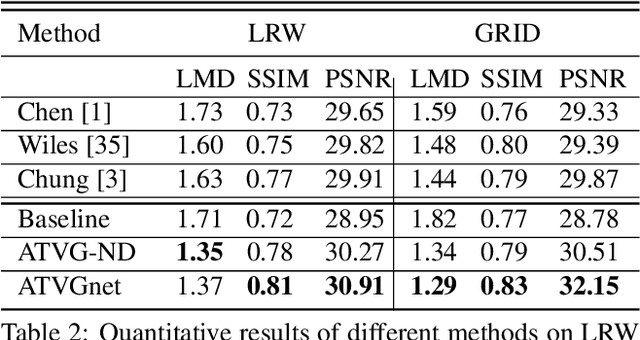
We devise a cascade GAN approach to generate talking face video, which is robust to different face shapes, view angles, facial characteristics, and noisy audio conditions. Instead of learning a direct mapping from audio to video frames, we propose first to transfer audio to high-level structure, i.e., the facial landmarks, and then to generate video frames conditioned on the landmarks. Compared to a direct audio-to-image approach, our cascade approach avoids fitting spurious correlations between audiovisual signals that are irrelevant to the speech content. We, humans, are sensitive to temporal discontinuities and subtle artifacts in video. To avoid those pixel jittering problems and to enforce the network to focus on audiovisual-correlated regions, we propose a novel dynamically adjustable pixel-wise loss with an attention mechanism. Furthermore, to generate a sharper image with well-synchronized facial movements, we propose a novel regression-based discriminator structure, which considers sequence-level information along with frame-level information. Thoughtful experiments on several datasets and real-world samples demonstrate significantly better results obtained by our method than the state-of-the-art methods in both quantitative and qualitative comparisons.
Visual Explanation for Deep Metric Learning
Sep 27, 2019
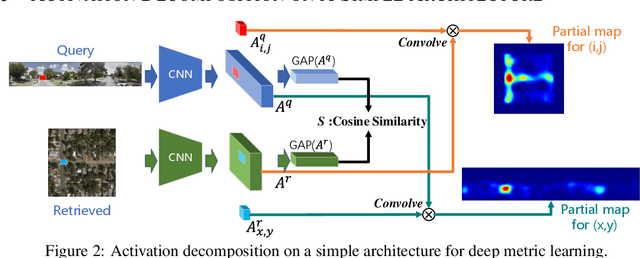
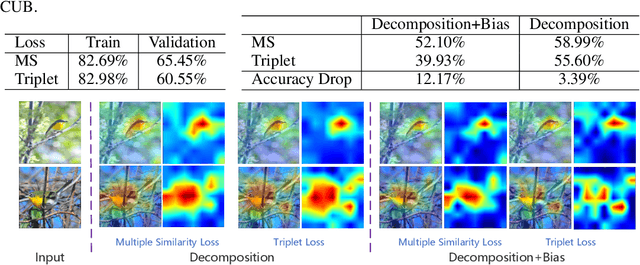
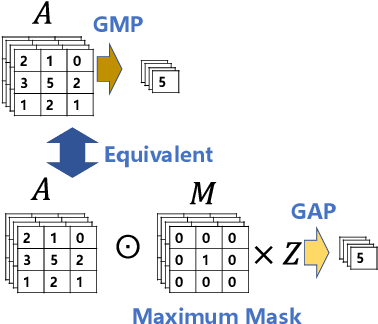
This work explores the visual explanation for deep metric learning and its applications. As an important problem for learning representation, metric learning has attracted much attention recently, while the interpretation of such model is not as well studied as classification. To this end, we propose an intuitive idea to show where contributes the most to the overall similarity of two input images by decomposing the final activation. Instead of only providing the overall activation map of each image, we propose to generate point-to-point activation intensity between two images so that the relationship between different regions is uncovered. We show that the proposed framework can be directly deployed to a large range of metric learning applications and provides valuable information for understanding the model. Furthermore, our experiments show its effectiveness on two potential applications, i.e. cross-view pattern discovery and interactive retrieval.
Graph Representation Learning: A Survey
Sep 03, 2019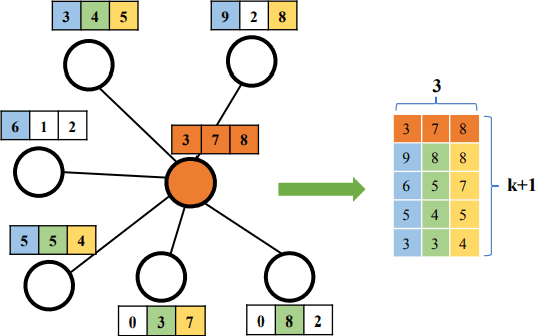
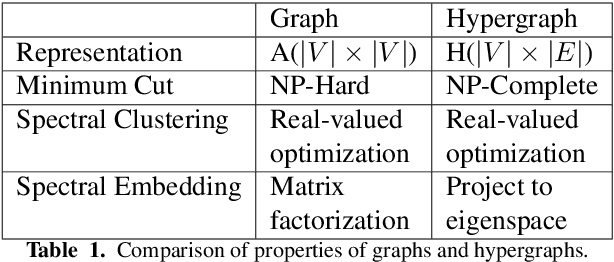
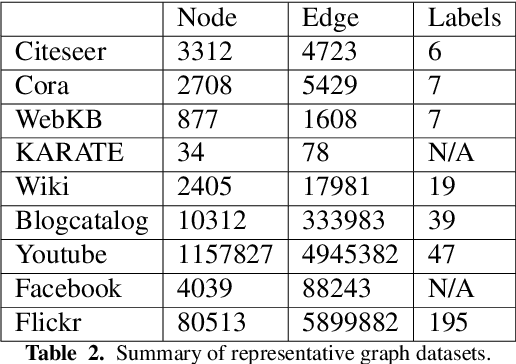
Research on graph representation learning has received a lot of attention in recent years since many data in real-world applications come in form of graphs. High-dimensional graph data are often in irregular form, which makes them more difficult to analyze than image/video/audio data defined on regular lattices. Various graph embedding techniques have been developed to convert the raw graph data into a low-dimensional vector representation while preserving the intrinsic graph properties. In this review, we first explain the graph embedding task and its challenges. Next, we review a wide range of graph embedding techniques with insights. Then, we evaluate several state-of-the-art methods against small and large datasets and compare their performance. Finally, potential applications and future directions are presented.