 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreative Agents: Simulating the Systems Model of Creativity with Generative Agents
Nov 26, 2024



With the growing popularity of generative AI for images, video, and music, we witnessed models rapidly improve in quality and performance. However, not much attention is paid towards enabling AI's ability to "be creative". In this study, we implemented and simulated the systems model of creativity (proposed by Csikszentmihalyi) using virtual agents utilizing large language models (LLMs) and text prompts. For comparison, the simulations were conducted with the "virtual artists" being: 1)isolated and 2)placed in a multi-agent system. Both scenarios were compared by analyzing the variations and overall "creativity" in the generated artifacts (measured via a user study and LLM). Our results suggest that the generative agents may perform better in the framework of the systems model of creativity.
LiP-LLM: Integrating Linear Programming and dependency graph with Large Language Models for multi-robot task planning
Oct 28, 2024



This study proposes LiP-LLM: integrating linear programming and dependency graph with large language models (LLMs) for multi-robot task planning. In order for multiple robots to perform tasks more efficiently, it is necessary to manage the precedence dependencies between tasks. Although multi-robot decentralized and centralized task planners using LLMs have been proposed, none of these studies focus on precedence dependencies from the perspective of task efficiency or leverage traditional optimization methods. It addresses key challenges in managing dependencies between skills and optimizing task allocation. LiP-LLM consists of three steps: skill list generation and dependency graph generation by LLMs, and task allocation using linear programming. The LLMs are utilized to generate a comprehensive list of skills and to construct a dependency graph that maps the relationships and sequential constraints among these skills. To ensure the feasibility and efficiency of skill execution, the skill list is generated by calculated likelihood, and linear programming is used to optimally allocate tasks to each robot. Experimental evaluations in simulated environments demonstrate that this method outperforms existing task planners, achieving higher success rates and efficiency in executing complex, multi-robot tasks. The results indicate the potential of combining LLMs with optimization techniques to enhance the capabilities of multi-robot systems in executing coordinated tasks accurately and efficiently. In an environment with two robots, a maximum success rate difference of 0.82 is observed in the language instruction group with a change in the object name.
Predictive Reachability for Embodiment Selection in Mobile Manipulation Behaviors
Oct 28, 2024



Mobile manipulators require coordinated control between navigation and manipulation to accomplish tasks. Typically, coordinated mobile manipulation behaviors have base navigation to approach the goal followed by arm manipulation to reach the desired pose. Selecting the embodiment between the base and arm can be determined based on reachability. Previous methods evaluate reachability by computing inverse kinematics and activate arm motions once solutions are identified. In this study, we introduce a new approach called predictive reachability that decides reachability based on predicted arm motions. Our model utilizes a hierarchical policy framework built upon a world model. The world model allows the prediction of future trajectories and the evaluation of reachability. The hierarchical policy selects the embodiment based on the predicted reachability and plans accordingly. Unlike methods that require prior knowledge about robots and environments for inverse kinematics, our method only relies on image-based observations. We evaluate our approach through basic reaching tasks across various environments. The results demonstrate that our method outperforms previous model-based approaches in both sample efficiency and performance, while enabling more reasonable embodiment selection based on predictive reachability.
Goal Estimation-based Adaptive Shared Control for Brain-Machine Interfaces Remote Robot Navigation
Jul 25, 2024



In this study, we propose a shared control method for teleoperated mobile robots using brain-machine interfaces (BMI). The control commands generated through BMI for robot operation face issues of low input frequency, discreteness, and uncertainty due to noise. To address these challenges, our method estimates the user's intended goal from their commands and uses this goal to generate auxiliary commands through the autonomous system that are both at a higher input frequency and more continuous. Furthermore, by defining the confidence level of the estimation, we adaptively calculated the weights for combining user and autonomous commands, thus achieving shared control.
Data-Efficient Approach to Humanoid Control via Fine-Tuning a Pre-Trained GPT on Action Data
May 29, 2024



There are several challenges in developing a model for multi-tasking humanoid control. Reinforcement learning and imitation learning approaches are quite popular in this domain. However, there is a trade-off between the two. Reinforcement learning is not the best option for training a humanoid to perform multiple behaviors due to training time and model size, and imitation learning using kinematics data alone is not appropriate to realize the actual physics of the motion. Training models to perform multiple complex tasks take long training time due to high DoF and complexities of the movements. Although training models offline would be beneficial, another issue is the size of the dataset, usually being quite large to encapsulate multiple movements. Many papers have implemented state of the art deep learning models such as transformers to control humanoid characters and predict their motion based on a large dataset of recorded/reference motion. In this paper, we train a GPT on a large dataset of noisy expert policy rollout observations from a humanoid motion dataset as a pre-trained model and fine tune that model on a smaller dataset of noisy expert policy rollout observations and actions to autoregressively generate physically plausible motion trajectories. We show that it is possible to train a GPT-based foundation model on a smaller dataset in shorter training time to control a humanoid in a realistic physics environment to perform human-like movements.
Proceedings of the Dialogue Robot Competition 2023
Jan 15, 2024The Dialogic Robot Competition 2023 (DRC2023) is a competition for humanoid robots (android robots that closely resemble humans) to compete in interactive capabilities. This is the third year of the competition. The top four teams from the preliminary competition held in November 2023 will compete in the final competition on Saturday, December 23. The task for the interactive robots is to recommend a tourism plan for a specific region. The robots can employ multimodal behaviors, such as language and gestures, to engage the user in the sightseeing plan they recommend. In the preliminary round, the interactive robots were stationed in a travel agency office, where visitors conversed with them and rated their performance via a questionnaire. In the final round, dialogue researchers and tourism industry professionals interacted with the robots and evaluated their performance. This event allows visitors to gain insights into the types of dialogue services that future dialogue robots should offer. The proceedings include papers on dialogue systems developed by the 12 teams participating in DRC2023, as well as an overview of the papers provided by all the teams.
Estimation of User's World Model Using Graph2vec
Jan 10, 2023



To obtain advanced interaction between autonomous robots and users, robots should be able to distinguish their state space representations (i.e., world models). Herein, a novel method was proposed for estimating the user's world model based on queries. In this method, the agent learns the distributed representation of world models using graph2vec and generates concept activation vectors that represent the meaning of queries in the latent space. Experimental results revealed that the proposed method can estimate the user's world model more efficiently than the simple method of using the ``AND'' search of queries.
Overview of Dialogue Robot Competition 2022
Oct 23, 2022



Although many competitions have been held on dialogue systems in the past, no competition has been organized specifically for dialogue with humanoid robots. As the first such attempt in the world, we held a dialogue robot competition in 2020 to compare the performances of interactive robots using an android that closely resembles a human. Dialogue Robot Competition 2022 (DRC2022) was the second competition, held in August 2022. The task and regulations followed those of the first competition, while the evaluation method was improved and the event was internationalized. The competition has two rounds, a preliminary round and the final round. In the preliminary round, twelve participating teams competed in performance of a dialogue robot in the manner of a field experiment, and then three of those teams were selected as finalists. The final round will be held on October 25, 2022, in the Robot Competition session of IROS2022. This paper provides an overview of the task settings and evaluation method of DRC2022 and the results of the preliminary round.
Survey and Perspective on Social Emotions in Robotics
May 20, 2021
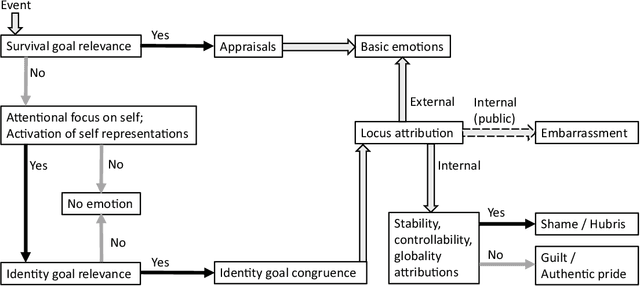
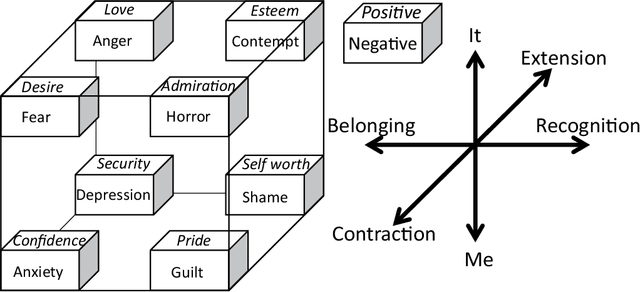

This study reviews research on social emotions in robotics. In robotics, emotions are pursued for a long duration, such as recognition, expression, and computational modeling of the basic mechanism behind them. Research has been promoted according to well-known psychological findings, such as category and dimension theories. Many studies have been based on these basic theories, addressing only basic emotions. However, social emotions, also called higher-level emotions, have been studied in psychology. We believe that these higher-level emotions are worth pursuing in robotics for next-generation social-aware robots. In this review paper, while summarizing the findings of social emotions in psychology and neuroscience, studies on social emotions in robotics at present are surveyed. Thereafter, research directions towards implementation of social emotions in robots are discussed.
A Framework of Explanation Generation toward Reliable Autonomous Robots
May 06, 2021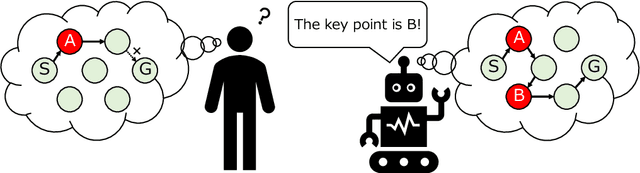

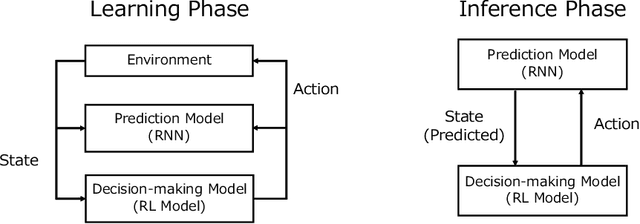
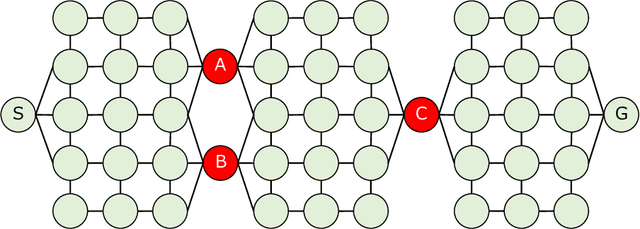
To realize autonomous collaborative robots, it is important to increase the trust that users have in them. Toward this goal, this paper proposes an algorithm which endows an autonomous agent with the ability to explain the transition from the current state to the target state in a Markov decision process (MDP). According to cognitive science, to generate an explanation that is acceptable to humans, it is important to present the minimum information necessary to sufficiently understand an event. To meet this requirement, this study proposes a framework for identifying important elements in the decision-making process using a prediction model for the world and generating explanations based on these elements. To verify the ability of the proposed method to generate explanations, we conducted an experiment using a grid environment. It was inferred from the result of a simulation experiment that the explanation generated using the proposed method was composed of the minimum elements important for understanding the transition from the current state to the target state. Furthermore, subject experiments showed that the generated explanation was a good summary of the process of state transition, and that a high evaluation was obtained for the explanation of the reason for an action.