 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Biometric Fish Classification of Temperate Species Using Convolutional Neural Network with Squeeze-and-Excitation
Apr 04, 2019

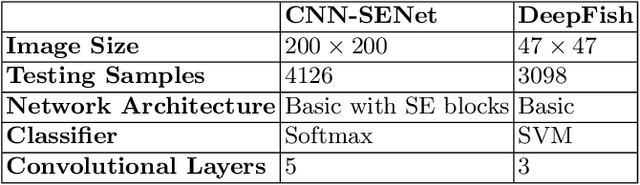
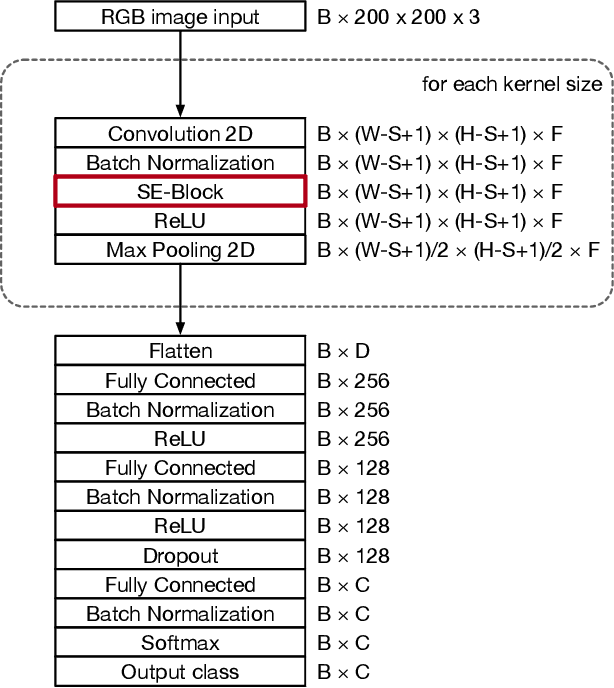
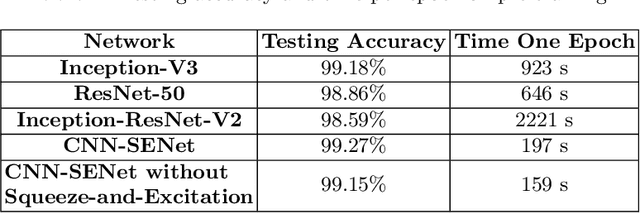
Our understanding and ability to effectively monitor and manage coastal ecosystems are severely limited by observation methods. Automatic recognition of species in natural environment is a promising tool which would revolutionize video and image analysis for a wide range of applications in marine ecology. However, classifying fish from images captured by underwater cameras is in general very challenging due to noise and illumination variations in water. Previous classification methods in the literature relies on filtering the images to separate the fish from the background or sharpening the images by removing background noise. This pre-filtering process may negatively impact the classification accuracy. In this work, we propose a Convolutional Neural Network (CNN) using the Squeeze-and-Excitation (SE) architecture for classifying images of fish without pre-filtering. Different from conventional schemes, this scheme is divided into two steps. The first step is to train the fish classifier via a public data set, i.e., Fish4Knowledge, without using image augmentation, named as pre-training. The second step is to train the classifier based on a new data set consisting of species that we are interested in for classification, named as post-training. The weights obtained from pre-training are applied to post-training as a priori. This is also known as transfer learning. Our solution achieves the state-of-the-art accuracy of 99.27% accuracy on the pre-training. The accuracy on the post-training is 83.68%. Experiments on the post-training with image augmentation yields an accuracy of 87.74%, indicating that the solution is viable with a larger data set.
Siamese Encoding and Alignment by Multiscale Learning with Self-Supervision
Apr 04, 2019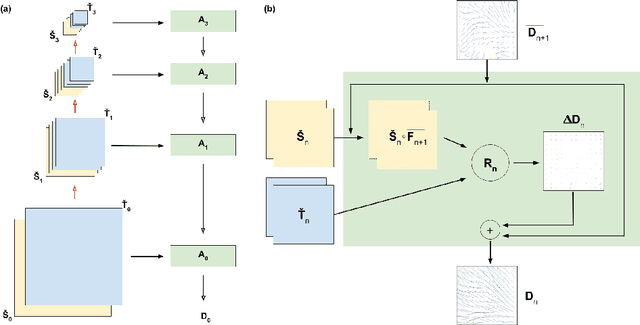
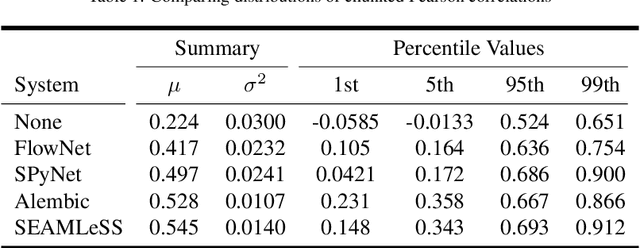
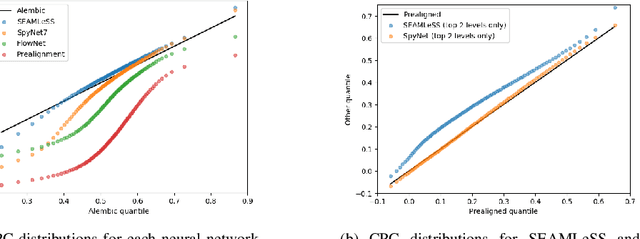

We propose a method of aligning a source image to a target image, where the transform is specified by a dense vector field. The two images are encoded as feature hierarchies by siamese convolutional nets. Then a hierarchy of aligner modules computes the transform in a coarse-to-fine recursion. Each module receives as input the transform that was computed by the module at the level above, aligns the source and target encodings at the same level of the hierarchy, and then computes an improved approximation to the transform using a convolutional net. The entire architecture of encoder and aligner nets is trained in a self-supervised manner to minimize the squared error between source and target remaining after alignment. We show that siamese encoding enables more accurate alignment than the image pyramids of SPyNet, a previous deep learning approach to coarse-to-fine alignment. Furthermore, self-supervision applies even without target values for the transform, unlike the strongly supervised SPyNet. We also show that our approach outperforms one-shot approaches to alignment, because the fine pathways in the latter approach may fail to contribute to alignment accuracy when displacements are large. As shown by previous one-shot approaches, good results from self-supervised learning require that the loss function additionally penalize non-smooth transforms. We demonstrate that "masking out" the penalty function near discontinuities leads to correct recovery of non-smooth transforms. Our claims are supported by empirical comparisons using images from serial section electron microscopy of brain tissue.
Signal-to-Noise Ratio: A Robust Distance Metric for Deep Metric Learning
Apr 04, 2019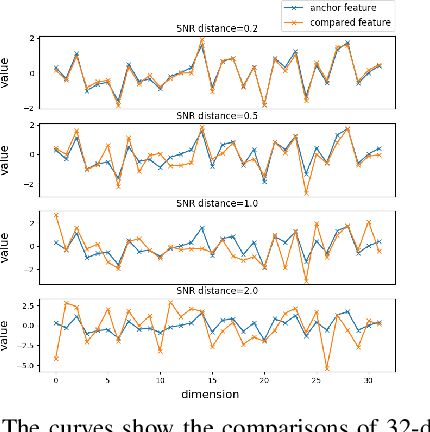
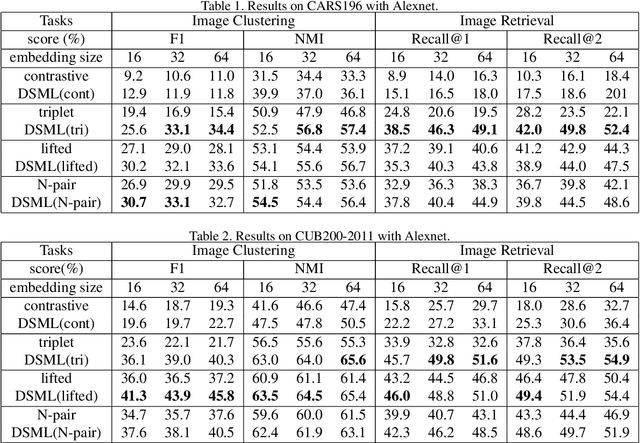
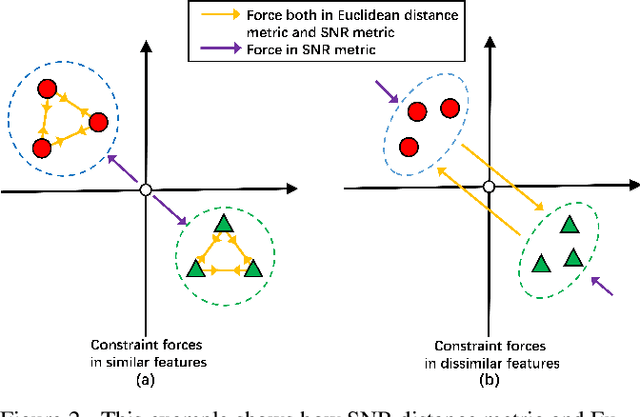
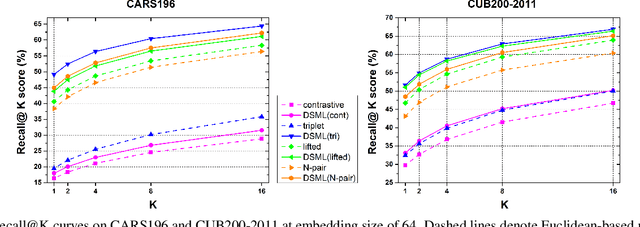
Deep metric learning, which learns discriminative features to process image clustering and retrieval tasks, has attracted extensive attention in recent years. A number of deep metric learning methods, which ensure that similar examples are mapped close to each other and dissimilar examples are mapped farther apart, have been proposed to construct effective structures for loss functions and have shown promising results. In this paper, different from the approaches on learning the loss structures, we propose a robust SNR distance metric based on Signal-to-Noise Ratio (SNR) for measuring the similarity of image pairs for deep metric learning. By exploring the properties of our SNR distance metric from the view of geometry space and statistical theory, we analyze the properties of our metric and show that it can preserve the semantic similarity between image pairs, which well justify its suitability for deep metric learning. Compared with Euclidean distance metric, our SNR distance metric can further jointly reduce the intra-class distances and enlarge the inter-class distances for learned features. Leveraging our SNR distance metric, we propose Deep SNR-based Metric Learning (DSML) to generate discriminative feature embeddings. By extensive experiments on three widely adopted benchmarks, including CARS196, CUB200-2011 and CIFAR10, our DSML has shown its superiority over other state-of-the-art methods. Additionally, we extend our SNR distance metric to deep hashing learning, and conduct experiments on two benchmarks, including CIFAR10 and NUS-WIDE, to demonstrate the effectiveness and generality of our SNR distance metric.
SparseNet: A Sparse DenseNet for Image Classification
Apr 15, 2018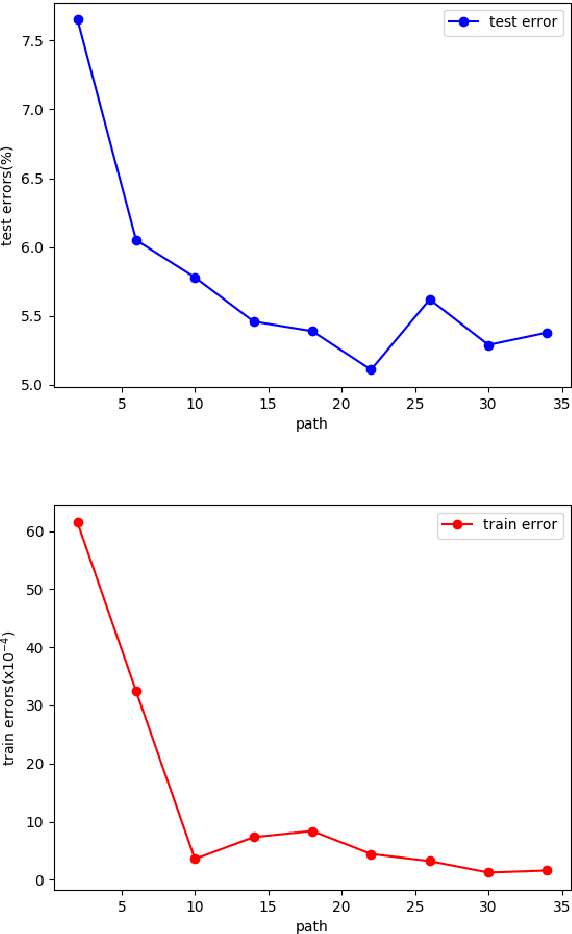
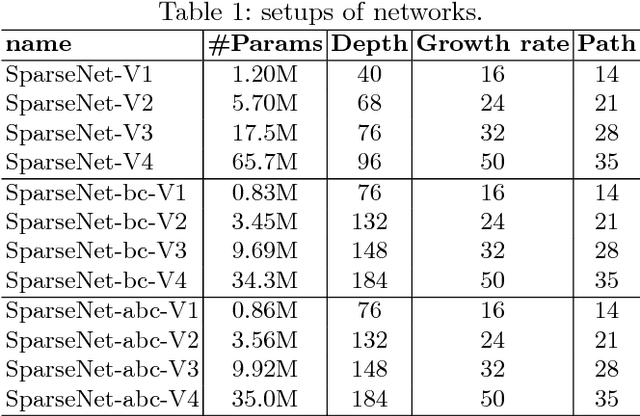
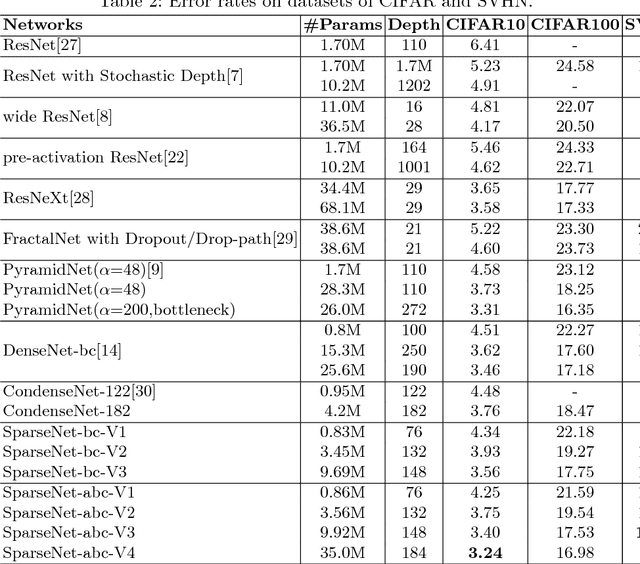
Deep neural networks have made remarkable progresses on various computer vision tasks. Recent works have shown that depth, width and shortcut connections of networks are all vital to their performances. In this paper, we introduce a method to sparsify DenseNet which can reduce connections of a L-layer DenseNet from O(L^2) to O(L), and thus we can simultaneously increase depth, width and connections of neural networks in a more parameter-efficient and computation-efficient way. Moreover, an attention module is introduced to further boost our network's performance. We denote our network as SparseNet. We evaluate SparseNet on datasets of CIFAR(including CIFAR10 and CIFAR100) and SVHN. Experiments show that SparseNet can obtain improvements over the state-of-the-art on CIFAR10 and SVHN. Furthermore, while achieving comparable performances as DenseNet on these datasets, SparseNet is x2.6 smaller and x3.7 faster than the original DenseNet.
An Improving Framework of regularization for Network Compression
Dec 11, 2019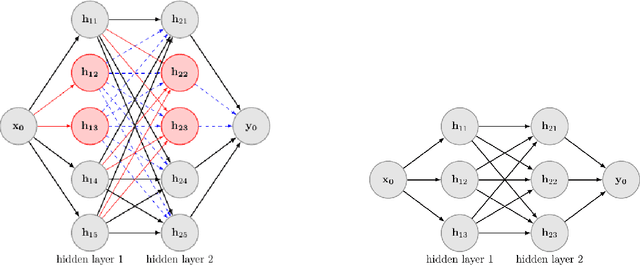
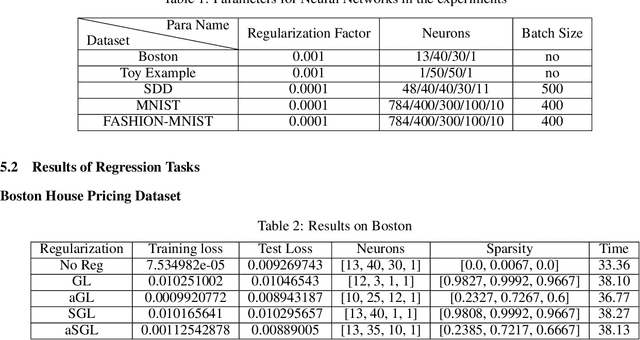
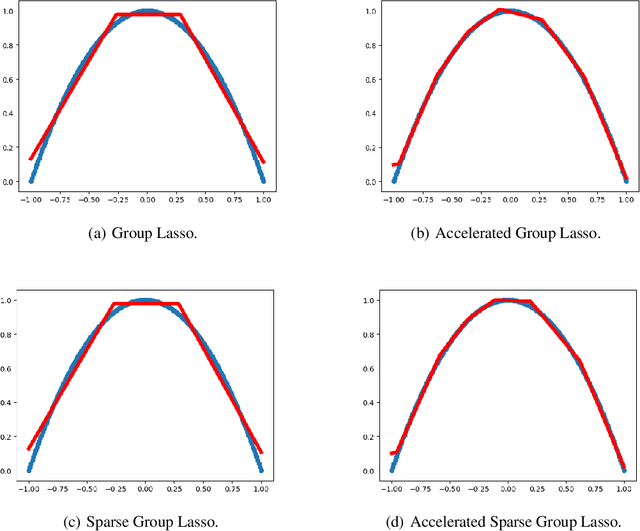

Deep Neural Networks have achieved remarkable success relying on the developing high computation capability of GPUs and large-scale datasets with increasing network depth and width in image recognition, object detection and many other applications. However, due to the expensive computation and intensive memory, researchers have concentrated on designing compression methods in recent years. In this paper, we briefly summarize the existing advanced techniques that are useful in model compression at first. After that, we give a detailed description on group lasso regularization and its variants. More importantly, we propose an improving framework of partial regularization based on the relationship between neurons and connections of adjacent layers. It is reasonable and feasible with the help of permutation property of neural network . Experiment results show that partial regularization methods brings improvements such as higher classification accuracy in both training and testing stages on multiple datasets. Since our regularizers contain the computation of less parameters, it shows competitive performances in terms of the total running time of experiments. Finally, we analysed the results and draw a conclusion that the optimal network structure must exist and depend on the input data.
Sample-specific repetitive learning for photo aesthetic assessment and highlight region extraction
Sep 18, 2019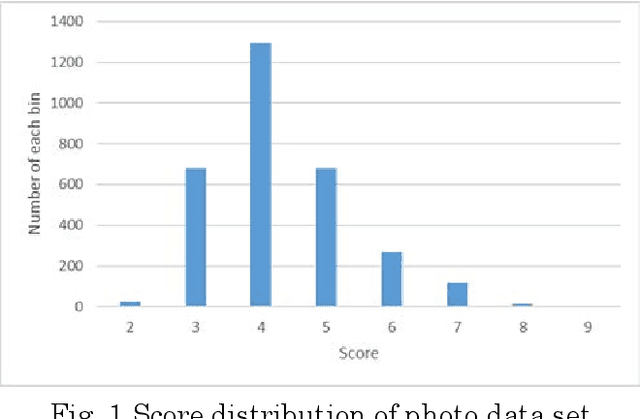
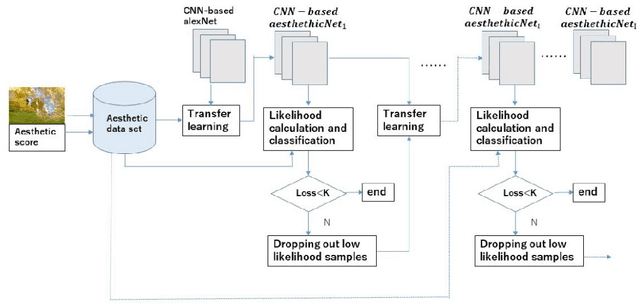

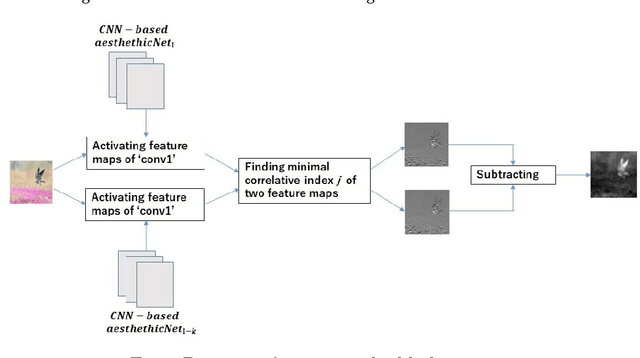
Aesthetic assessment is subjective, and the distribution of the aesthetic levels is imbalanced. In order to realize the auto-assessment of photo aesthetics, we focus on retraining the CNN-based aesthetic assessment model by dropping out the unavailable samples in the middle levels from the training data set repetitively to overcome the effect of imbalanced aesthetic data on classification. Further, the method of extracting aesthetics highlight region of the photo image by using the two repetitively trained models is presented. Therefore, the correlation of the extracted region with the aesthetic levels is analyzed to illustrate what aesthetics features influence the aesthetic quality of the photo. Moreover, the testing data set is from the different data source called 500px. Experimental results show that the proposed method is effective.
Enhancing Cross-task Black-Box Transferability of Adversarial Examples with Dispersion Reduction
Nov 22, 2019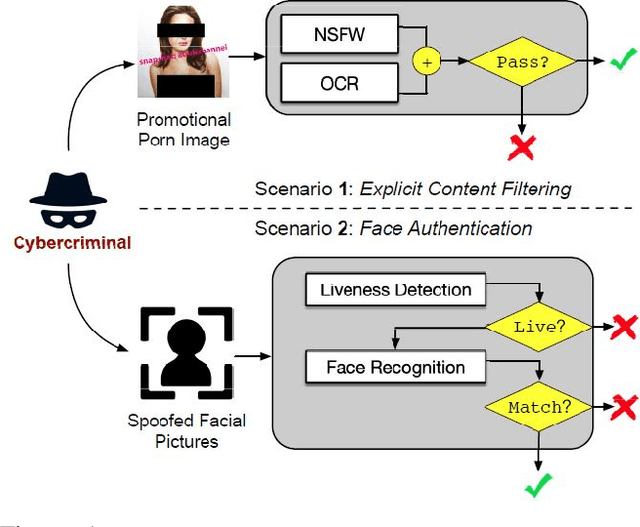
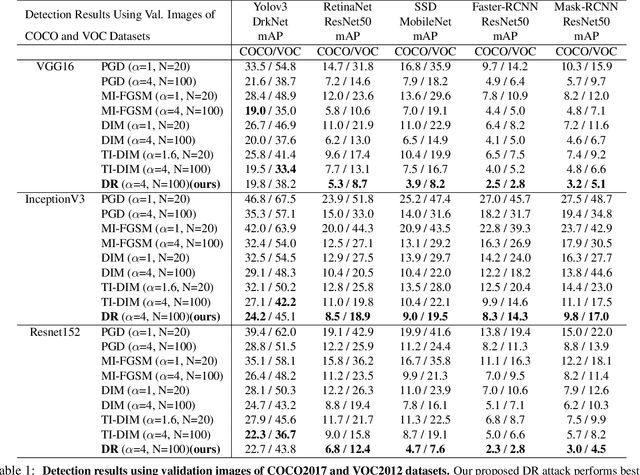
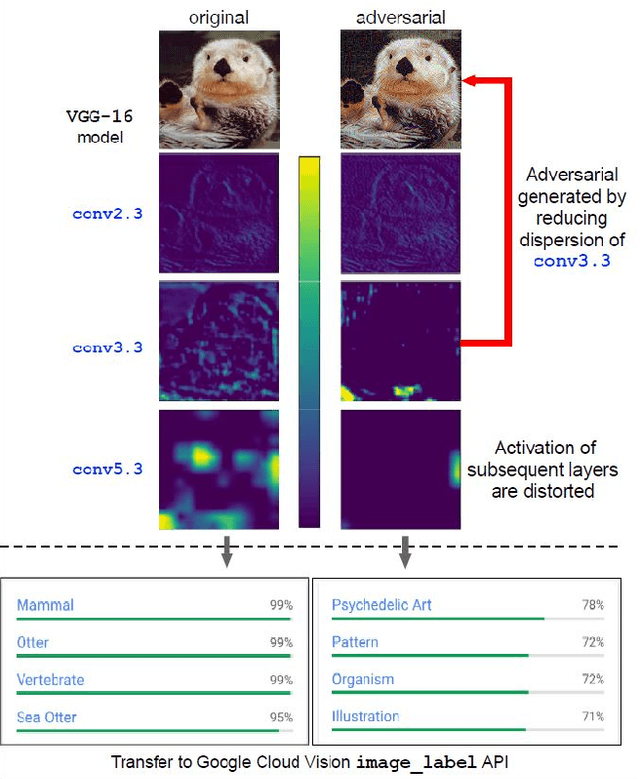
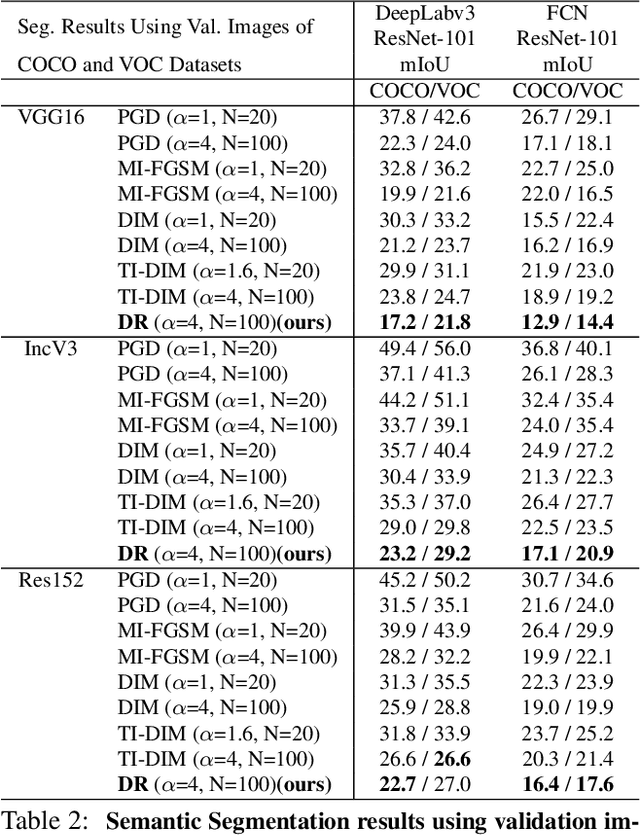
Neural networks are known to be vulnerable to carefully crafted adversarial examples, and these malicious samples often transfer, i.e., they remain adversarial even against other models. Although great efforts have been delved into the transferability across models, surprisingly, less attention has been paid to the cross-task transferability, which represents the real-world cybercriminal's situation, where an ensemble of different defense/detection mechanisms need to be evaded all at once. In this paper, we investigate the transferability of adversarial examples across a wide range of real-world computer vision tasks, including image classification, object detection, semantic segmentation, explicit content detection, and text detection. Our proposed attack minimizes the ``dispersion'' of the internal feature map, which overcomes existing attacks' limitation of requiring task-specific loss functions and/or probing a target model. We conduct evaluation on open source detection and segmentation models as well as four different computer vision tasks provided by Google Cloud Vision (GCV) APIs, to show how our approach outperforms existing attacks by degrading performance of multiple CV tasks by a large margin with only modest perturbations linf=16.
Scalability in Perception for Autonomous Driving: An Open Dataset Benchmark
Dec 10, 2019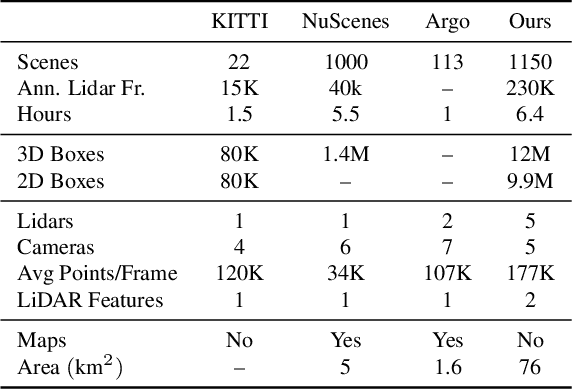
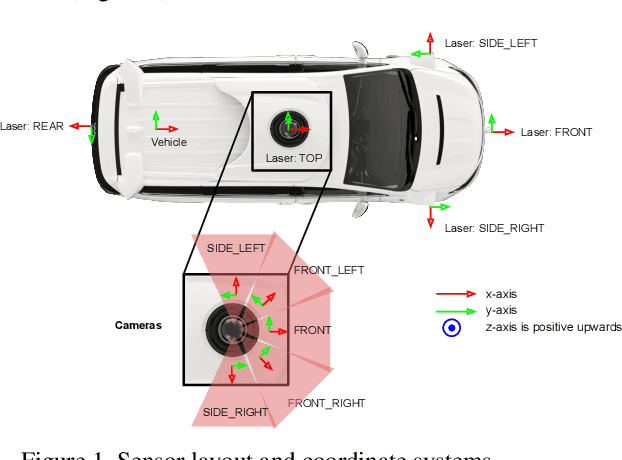

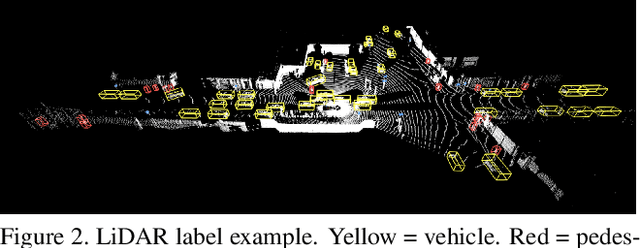
The research community has increasing interest in autonomous driving research, despite the resource intensity of obtaining representative real world data. Existing self-driving datasets are limited in the scale and variation of the environments they capture, even though generalization within and between operating regions is crucial to the overall viability of the technology. In an effort to help align the research community's contributions with real-world self-driving problems, we introduce a new large scale, high quality, diverse dataset. Our new dataset consists of 1150 scenes that each span 20 seconds, consisting of well synchronized and calibrated high quality LiDAR and camera data captured across a range of urban and suburban geographies. It is 15x more diverse than the largest camera+LiDAR dataset available based on our proposed diversity metric. We exhaustively annotated this data with 2D (camera image) and 3D (LiDAR) bounding boxes, with consistent identifiers across frames. Finally, we provide strong baselines for 2D as well as 3D detection and tracking tasks. We further study the effects of dataset size and generalization across geographies on 3D detection methods. Find data, code and more up-to-date information at http://www.waymo.com/open.
PointPainting: Sequential Fusion for 3D Object Detection
Nov 22, 2019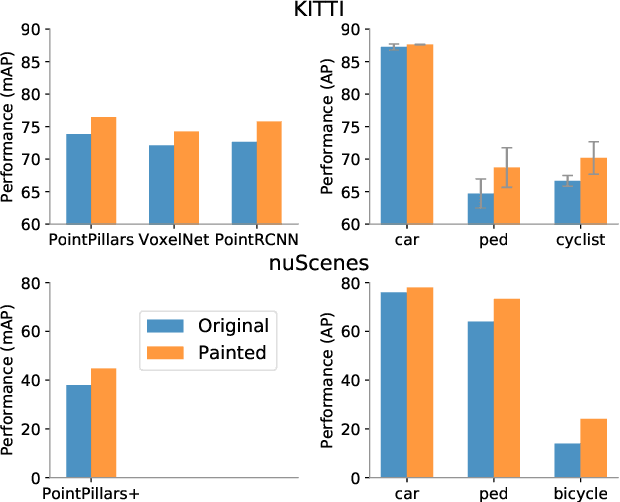
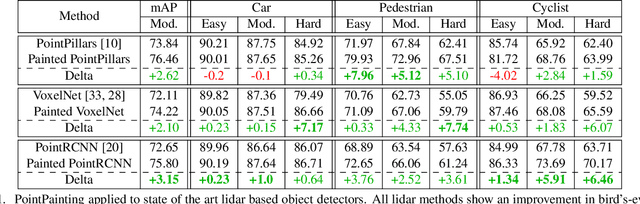
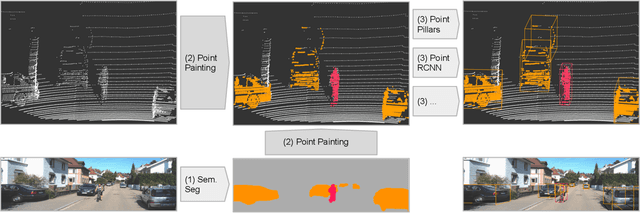
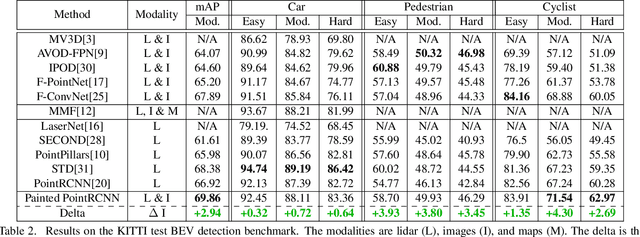
Camera and lidar are important sensor modalities for robotics in general and self-driving cars in particular. The sensors provide complementary information offering an opportunity for tight sensor-fusion. Surprisingly, lidar-only methods outperform fusion methods on the main benchmark datasets, suggesting a gap in the literature. In this work, we propose PointPainting: a sequential fusion method to fill this gap. PointPainting works by projecting lidar points into the output of an image-only semantic segmentation network and appending the class scores to each point. The appended (painted) point cloud can then be fed to any lidar-only method. Experiments show large improvements on three different state-of-the art methods, Point-RCNN, VoxelNet and PointPillars on the KITTI and nuScenes datasets. The painted version of PointRCNN represents a new state of the art on the KITTI leaderboard for the bird's-eye view detection task. In ablation, we study how the effects of Painting depends on the quality and format of the semantic segmentation output, and demonstrate how latency can be minimized through pipelining.
Random 2.5D U-net for Fully 3D Segmentation
Oct 23, 2019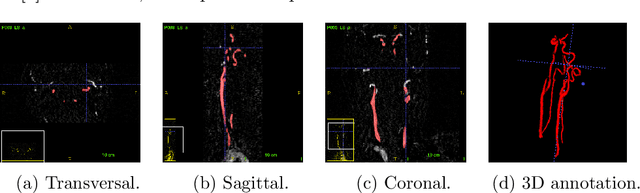
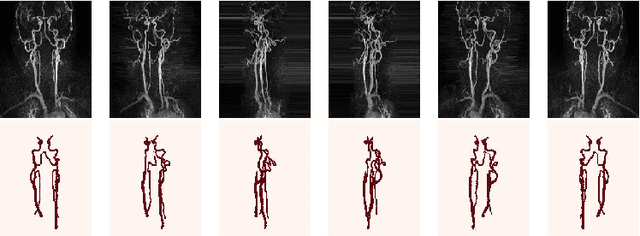
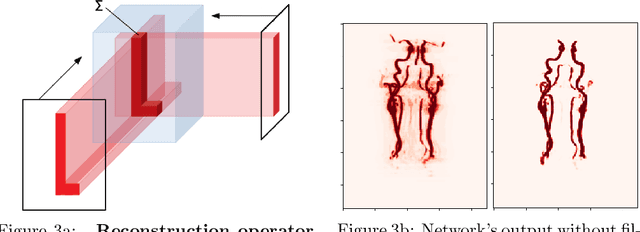
Convolutional neural networks are state-of-the-art for various segmentation tasks. While for 2D images these networks are also computationally efficient, 3D convolutions have huge storage requirements and therefore, end-to-end training is limited by GPU memory and data size. To overcome this issue, we introduce a network structure for volumetric data without 3D convolution layers. The main idea is to include projections from different directions to transform the volumetric data to a sequence of images, where each image contains information of the full data. We then apply 2D convolutions to these projection images and lift them again to volumetric data using a trainable reconstruction algorithm. The proposed architecture can be applied end-to-end to very large data volumes without cropping or sliding-window techniques. For a tested sparse binary segmentation task, it outperforms already known standard approaches and is more resistant to generation of artefacts.