 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoptic nuScenes: A Large-Scale Benchmark for LiDAR Panoptic Segmentation and Tracking
Sep 10, 2021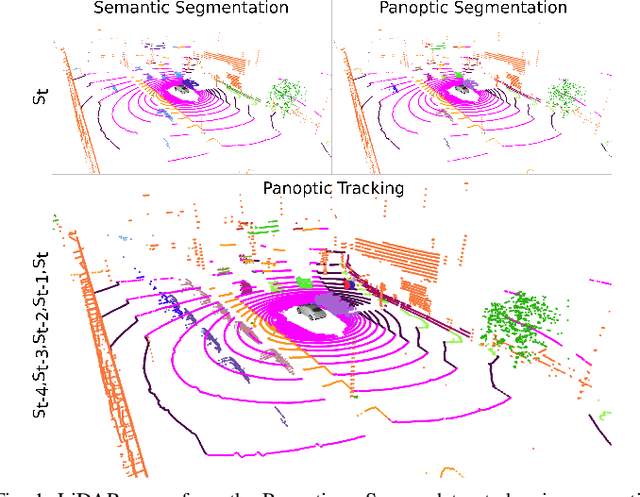
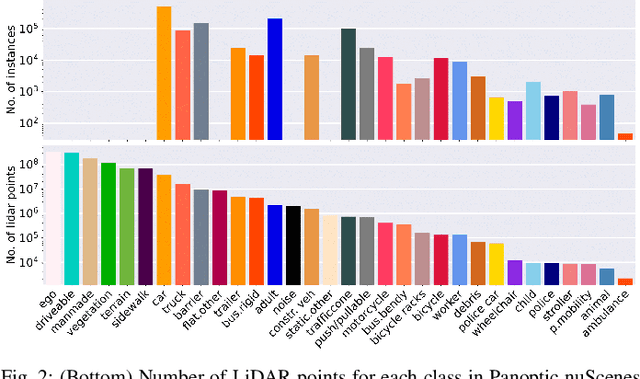
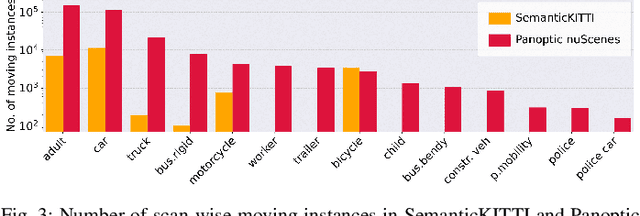
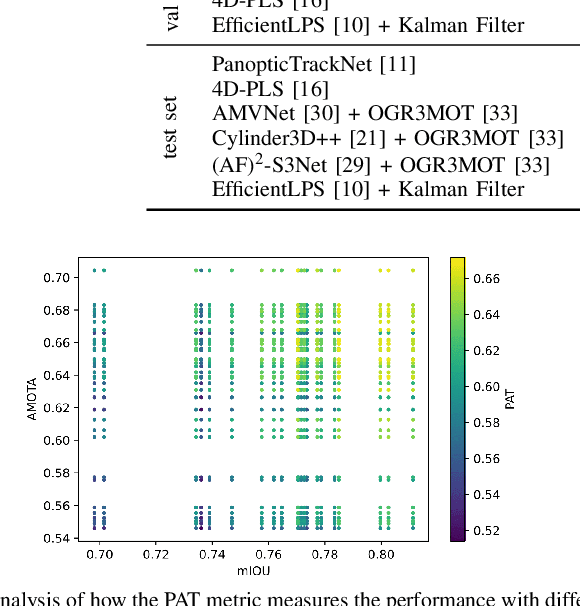
Panoptic scene understanding and tracking of dynamic agents are essential for robots and automated vehicles to navigate in urban environments. As LiDARs provide accurate illumination-independent geometric depictions of the scene, performing these tasks using LiDAR point clouds provides reliable predictions. However, existing datasets lack diversity in the type of urban scenes and have a limited number of dynamic object instances which hinders both learning of these tasks as well as credible benchmarking of the developed methods. In this paper, we introduce the large-scale Panoptic nuScenes benchmark dataset that extends our popular nuScenes dataset with point-wise groundtruth annotations for semantic segmentation, panoptic segmentation, and panoptic tracking tasks. To facilitate comparison, we provide several strong baselines for each of these tasks on our proposed dataset. Moreover, we analyze the drawbacks of the existing metrics for panoptic tracking and propose the novel instance-centric PAT metric that addresses the concerns. We present exhaustive experiments that demonstrate the utility of Panoptic nuScenes compared to existing datasets and make the online evaluation server available at nuScenes.org. We believe that this extension will accelerate the research of novel methods for scene understanding of dynamic urban environments.
The Reasonable Crowd: Towards evidence-based and interpretable models of driving behavior
Jul 28, 2021
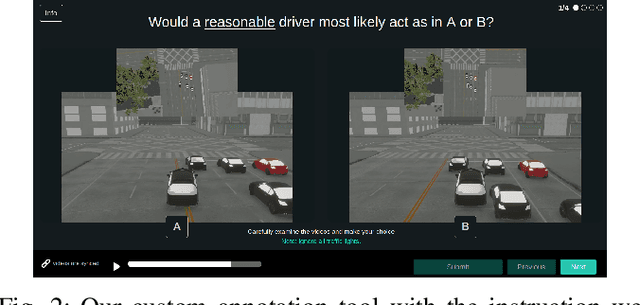

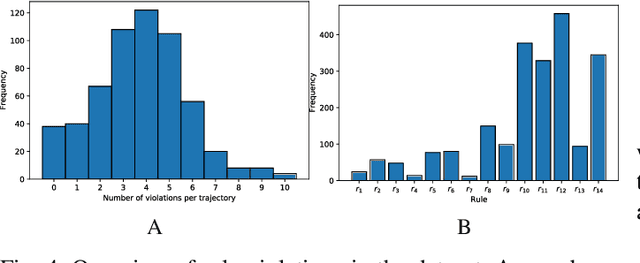
Autonomous vehicles must balance a complex set of objectives. There is no consensus on how they should do so, nor on a model for specifying a desired driving behavior. We created a dataset to help address some of these questions in a limited operating domain. The data consists of 92 traffic scenarios, with multiple ways of traversing each scenario. Multiple annotators expressed their preference between pairs of scenario traversals. We used the data to compare an instance of a rulebook, carefully hand-crafted independently of the dataset, with several interpretable machine learning models such as Bayesian networks, decision trees, and logistic regression trained on the dataset. To compare driving behavior, these models use scores indicating by how much different scenario traversals violate each of 14 driving rules. The rules are interpretable and designed by subject-matter experts. First, we found that these rules were enough for these models to achieve a high classification accuracy on the dataset. Second, we found that the rulebook provides high interpretability without excessively sacrificing performance. Third, the data pointed to possible improvements in the rulebook and the rules, and to potential new rules. Fourth, we explored the interpretability vs performance trade-off by also training non-interpretable models such as a random forest. Finally, we make the dataset publicly available to encourage a discussion from the wider community on behavior specification for AVs. Please find it at github.com/bassam-motional/Reasonable-Crowd.
NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles
Jul 12, 2021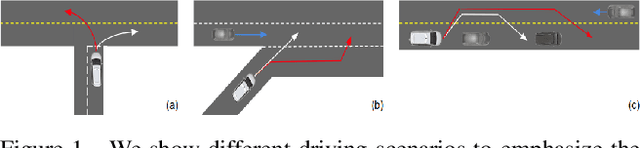

In this work, we propose the world's first closed-loop ML-based planning benchmark for autonomous driving. While there is a growing body of ML-based motion planners, the lack of established datasets and metrics has limited the progress in this area. Existing benchmarks for autonomous vehicle motion prediction have focused on short-term motion forecasting, rather than long-term planning. This has led previous works to use open-loop evaluation with L2-based metrics, which are not suitable for fairly evaluating long-term planning. Our benchmark overcomes these limitations by introducing a large-scale driving dataset, lightweight closed-loop simulator, and motion-planning-specific metrics. We provide a high-quality dataset with 1500h of human driving data from 4 cities across the US and Asia with widely varying traffic patterns (Boston, Pittsburgh, Las Vegas and Singapore). We will provide a closed-loop simulation framework with reactive agents and provide a large set of both general and scenario-specific planning metrics. We plan to release the dataset at NeurIPS 2021 and organize benchmark challenges starting in early 2022.
Multimodal Trajectory Prediction Conditioned on Lane-Graph Traversals
Jun 28, 2021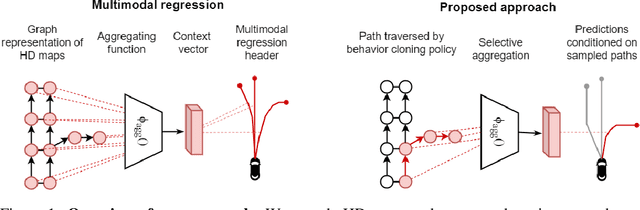
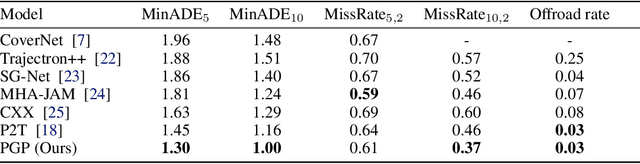
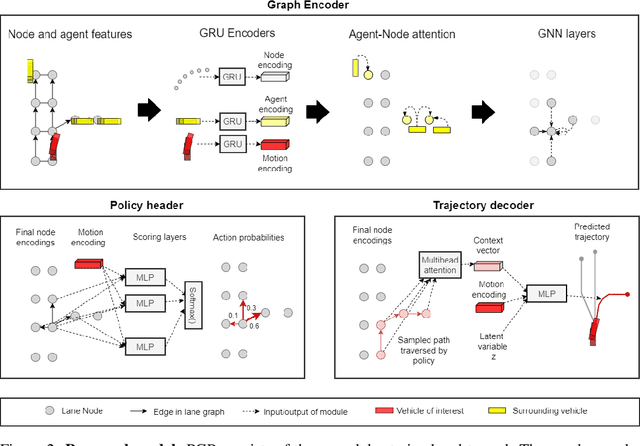
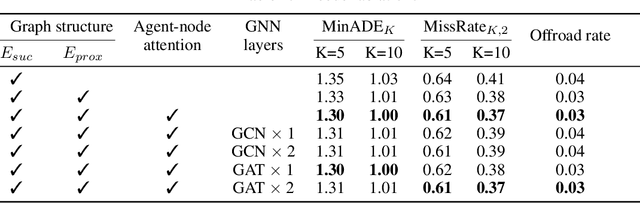
Accurately predicting the future motion of surrounding vehicles requires reasoning about the inherent uncertainty in goals and driving behavior. This uncertainty can be loosely decoupled into lateral (e.g., keeping lane, turning) and longitudinal (e.g., accelerating, braking). We present a novel method that combines learned discrete policy rollouts with a focused decoder on subsets of the lane graph. The policy rollouts explore different goals given our current observations, ensuring that the model captures lateral variability. The longitudinal variability is captured by our novel latent variable model decoder that is conditioned on various subsets of the lane graph. Our model achieves state-of-the-art performance on the nuScenes motion prediction dataset, and qualitatively demonstrates excellent scene compliance. Detailed ablations highlight the importance of both the policy rollouts and the decoder architecture.
PolarStream: Streaming Lidar Object Detection and Segmentation with Polar Pillars
Jun 14, 2021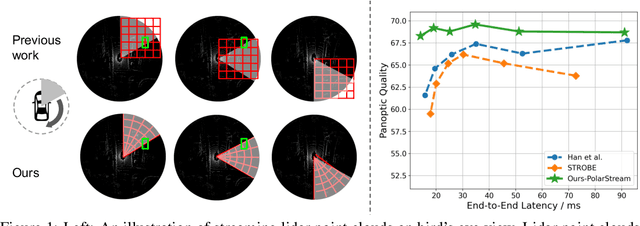
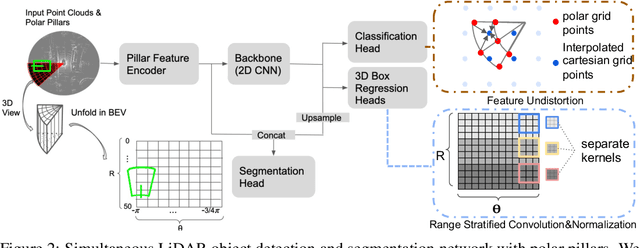

Recent works recognized lidars as an inherently streaming data source and showed that the end-to-end latency of lidar perception models can be reduced significantly by operating on wedge-shaped point cloud sectors rather then the full point cloud. However, due to use of cartesian coordinate systems these methods represent the sectors as rectangular regions, wasting memory and compute. In this work we propose using a polar coordinate system and make two key improvements on this design. First, we increase the spatial context by using multi-scale padding from neighboring sectors: preceding sector from the current scan and/or the following sector from the past scan. Second, we improve the core polar convolutional architecture by introducing feature undistortion and range stratified convolutions. Experimental results on the nuScenes dataset show significant improvements over other streaming based methods. We also achieve comparable results to existing non-streaming methods but with lower latencies.
The efficacy of Neural Planning Metrics: A meta-analysis of PKL on nuScenes
Oct 24, 2020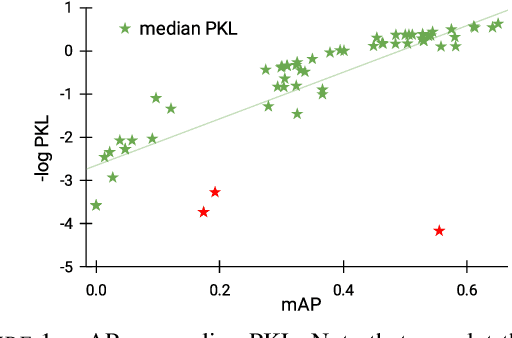
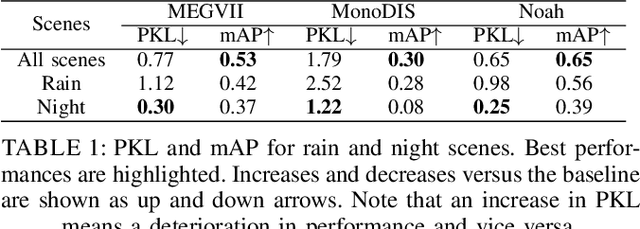
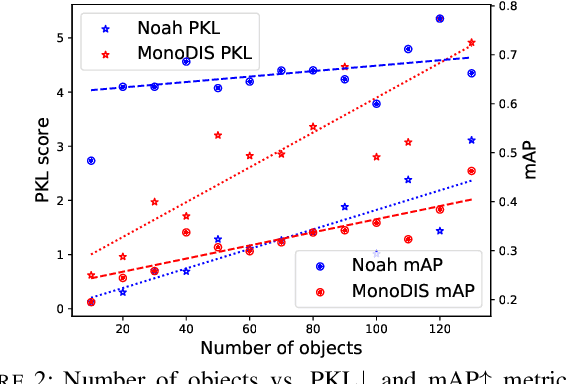
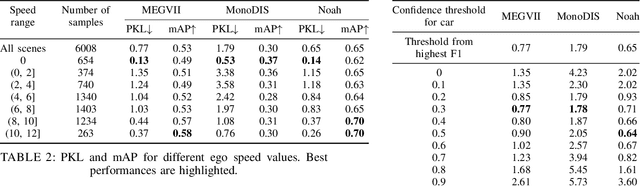
A high-performing object detection system plays a crucial role in autonomous driving (AD). The performance, typically evaluated in terms of mean Average Precision, does not take into account orientation and distance of the actors in the scene, which are important for the safe AD. It also ignores environmental context. Recently, Philion et al. proposed a neural planning metric (PKL), based on the KL divergence of a planner's trajectory and the groundtruth route, to accommodate these requirements. In this paper, we use this neural planning metric to score all submissions of the nuScenes detection challenge and analyze the results. We find that while somewhat correlated with mAP, the PKL metric shows different behavior to increased traffic density, ego velocity, road curvature and intersections. Finally, we propose ideas to extend the neural planning metric.
CoverNet: Multimodal Behavior Prediction using Trajectory Sets
Nov 23, 2019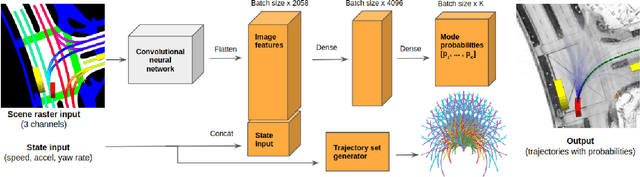
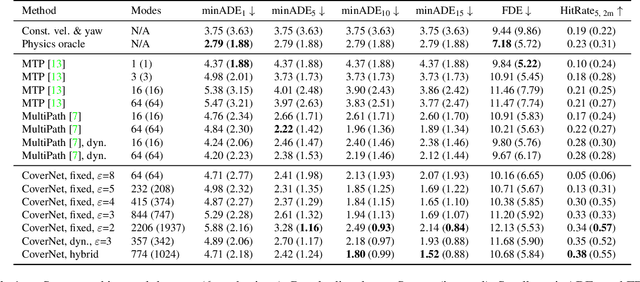
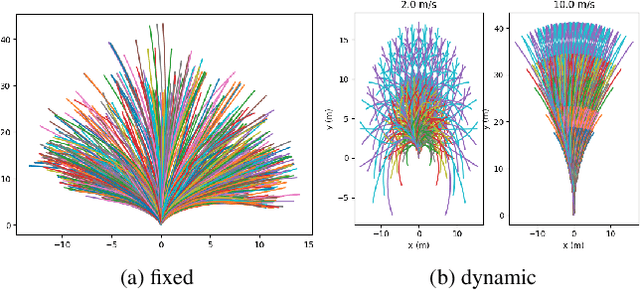
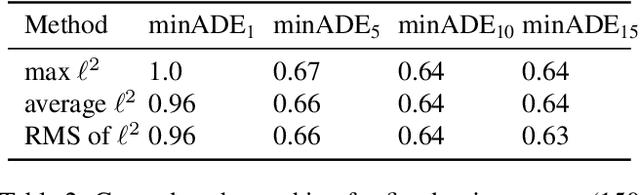
We present CoverNet, a new method for multimodal, probabilistic trajectory prediction in urban driving scenarios. Previous work has employed a variety of methods, including multimodal regression, occupancy maps, and 1-step stochastic policies. We instead frame the trajectory prediction problem as classification over a diverse set of trajectories. The size of this set remains manageable, due to the fact that there are a limited number of distinct actions that can be taken over a reasonable prediction horizon. We structure the trajectory set to a) ensure a desired level of coverage of the state space, and b) eliminate physically impossible trajectories. By dynamically generating trajectory sets based on the agent's current state, we can further improve the efficiency of our method. We demonstrate our approach on public, real-world self-driving datasets, and show that it outperforms state-of-the-art methods.
PointPainting: Sequential Fusion for 3D Object Detection
Nov 22, 2019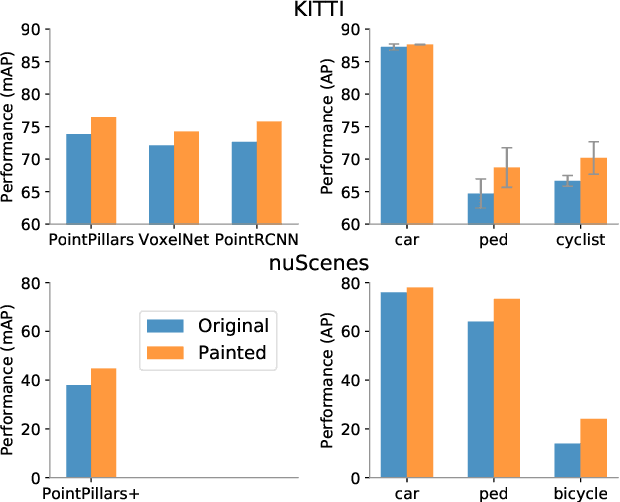
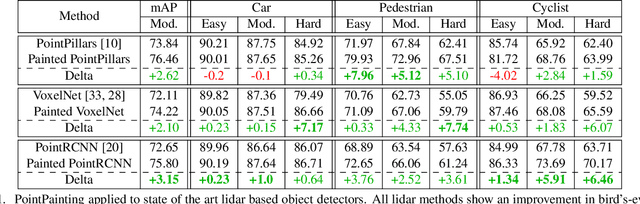
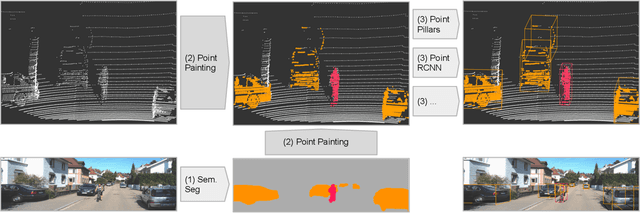
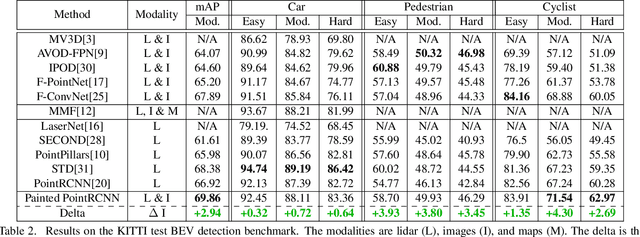
Camera and lidar are important sensor modalities for robotics in general and self-driving cars in particular. The sensors provide complementary information offering an opportunity for tight sensor-fusion. Surprisingly, lidar-only methods outperform fusion methods on the main benchmark datasets, suggesting a gap in the literature. In this work, we propose PointPainting: a sequential fusion method to fill this gap. PointPainting works by projecting lidar points into the output of an image-only semantic segmentation network and appending the class scores to each point. The appended (painted) point cloud can then be fed to any lidar-only method. Experiments show large improvements on three different state-of-the art methods, Point-RCNN, VoxelNet and PointPillars on the KITTI and nuScenes datasets. The painted version of PointRCNN represents a new state of the art on the KITTI leaderboard for the bird's-eye view detection task. In ablation, we study how the effects of Painting depends on the quality and format of the semantic segmentation output, and demonstrate how latency can be minimized through pipelining.
nuScenes: A multimodal dataset for autonomous driving
Mar 26, 2019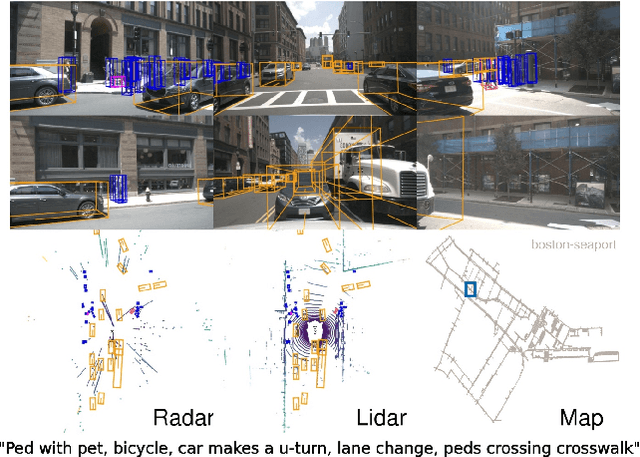
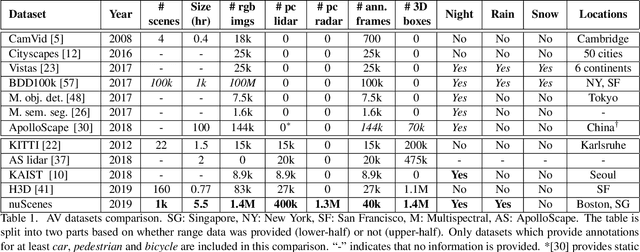


Robust detection and tracking of objects is crucial for the deployment of autonomous vehicle technology. Image-based benchmark datasets have driven the development in computer vision tasks such as object detection, tracking and segmentation of agents in the environment. Most autonomous vehicles, however, carry a combination of cameras and range sensors such as lidar and radar. As machine learning based methods for detection and tracking become more prevalent, there is a need to train and evaluate such methods on datasets containing range sensor data along with images. In this work we present nuTonomy scenes (nuScenes), the first dataset to carry the full autonomous vehicle sensor suite: 6 cameras, 5 radars and 1 lidar, all with full 360 degree field of view. nuScenes comprises 1000 scenes, each 20s long and fully annotated with 3D bounding boxes for 23 classes and 8 attributes. It has 7x as many annotations and 100x as many images as the pioneering KITTI dataset. We also define a new metric for 3D detection which consolidates the multiple aspects of the detection task: classification, localization, size, orientation, velocity and attribute estimation. We provide careful dataset analysis as well as baseline performance for lidar and image based detection methods. Data, development kit, and more information are available at www.nuscenes.org.
PointPillars: Fast Encoders for Object Detection from Point Clouds
Dec 14, 2018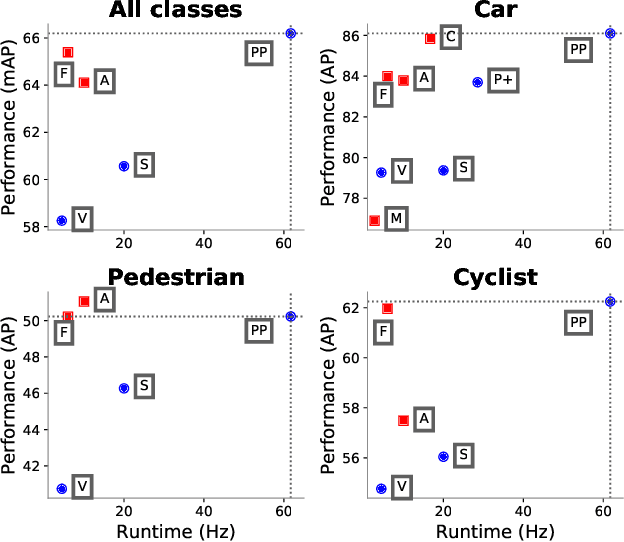
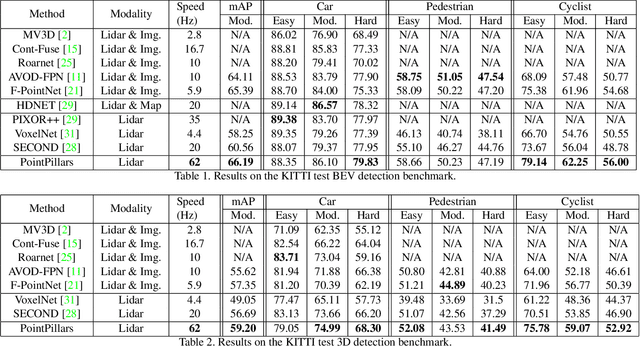
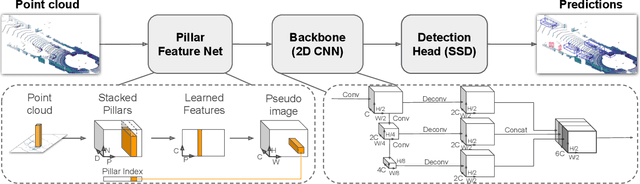

Object detection in point clouds is an important aspect of many robotics applications such as autonomous driving. In this paper we consider the problem of encoding a point cloud into a format appropriate for a downstream detection pipeline. Recent literature suggests two types of encoders; fixed encoders tend to be fast but sacrifice accuracy, while encoders that are learned from data are more accurate, but slower. In this work we propose PointPillars, a novel encoder which utilizes PointNets to learn a representation of point clouds organized in vertical columns (pillars). While the encoded features can be used with any standard 2D convolutional detection architecture, we further propose a lean downstream network. Extensive experimentation shows that PointPillars outperforms previous encoders with respect to both speed and accuracy by a large margin. Despite only using lidar, our full detection pipeline significantly outperforms the state of the art, even among fusion methods, with respect to both the 3D and bird's eye view KITTI benchmarks. This detection performance is achieved while running at 62 Hz: a 2 - 4 fold runtime improvement. A faster version of our method matches the state of the art at 105 Hz. These benchmarks suggest that PointPillars is an appropriate encoding for object detection in point clouds.