 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Partial Regularization Method for Network Compression
Sep 04, 2020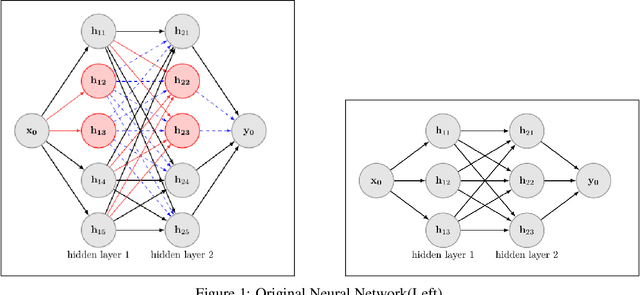
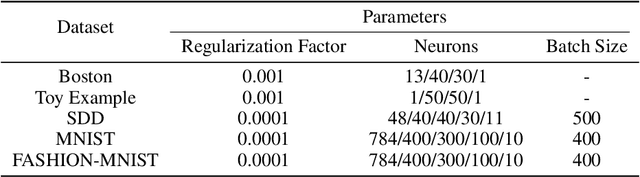
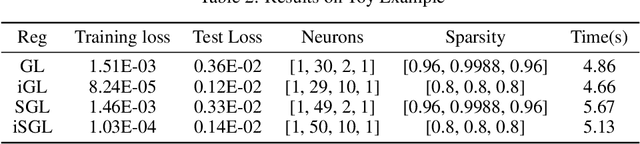
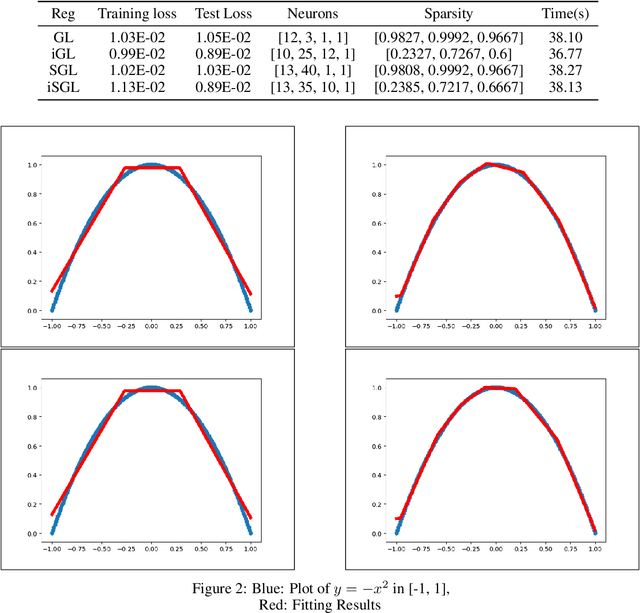
Deep Neural Networks have achieved remarkable success relying on the developing availability of GPUs and large-scale datasets with increasing network depth and width. However, due to the expensive computation and intensive memory, researchers have concentrated on designing compression methods in order to make them practical for constrained platforms. In this paper, we propose an approach of partial regularization rather than the original form of penalizing all parameters, which is said to be full regularization, to conduct model compression at a higher speed. It is reasonable and feasible according to the existence of the permutation invariant property of neural networks. Experimental results show that as we expected, the computational complexity is reduced by observing less running time in almost all situations. It should be owing to the fact that partial regularization method invovles a lower number of elements for calculation. Surprisingly, it helps to improve some important metrics such as regression fitting results and classification accuracy in both training and test phases on multiple datasets, telling us that the pruned models have better performance and generalization ability. What's more, we analyze the results and draw a conclusion that an optimal network structure must exist and depend on the input data.
An Improving Framework of regularization for Network Compression
Jan 07, 2020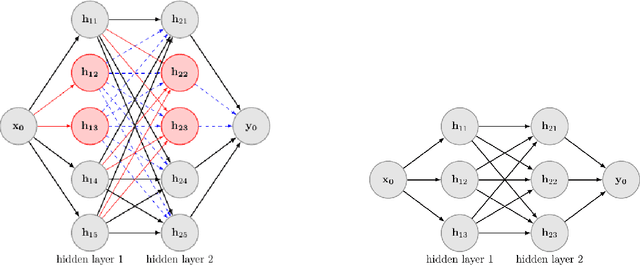
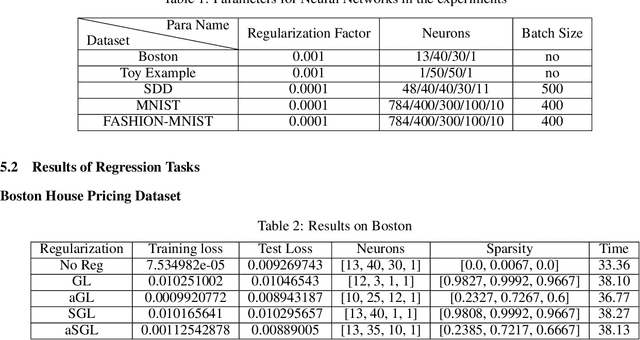
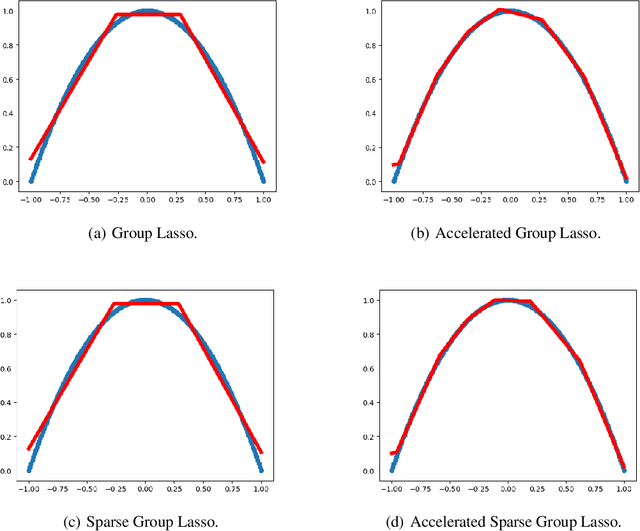

Deep Neural Networks have achieved remarkable success relying on the developing high computation capability of GPUs and large-scale datasets with increasing network depth and width in image recognition, object detection and many other applications. However, due to the expensive computation and intensive memory, researchers have concentrated on designing compression methods in recent years. In this paper, we briefly summarize the existing advanced techniques that are useful in model compression at first. After that, we give a detailed description on group lasso regularization and its variants. More importantly, we propose an improving framework of partial regularization based on the relationship between neurons and connections of adjacent layers. It is reasonable and feasible with the help of permutation property of neural network . Experiment results show that partial regularization methods brings improvements such as higher classification accuracy in both training and testing stages on multiple datasets. Since our regularizers contain the computation of less parameters, it shows competitive performances in terms of the total running time of experiments. Finally, we analysed the results and draw a conclusion that the optimal network structure must exist and depend on the input data.