 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Camera That CNNs: Towards Embedded Neural Networks on Pixel Processor Arrays
Sep 13, 2019
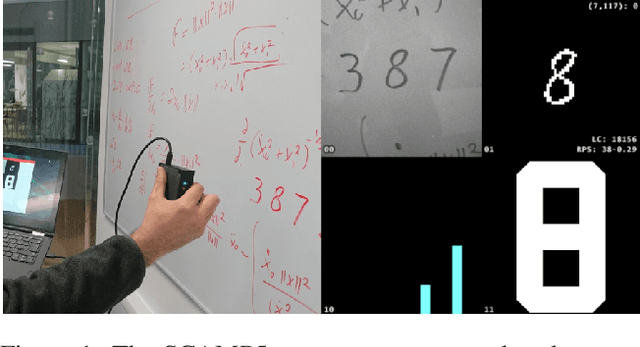
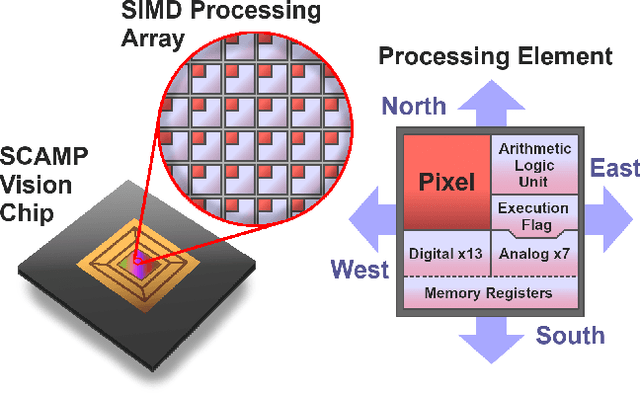
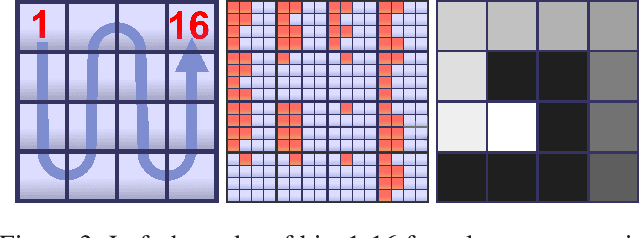

We present a convolutional neural network implementation for pixel processor array (PPA) sensors. PPA hardware consists of a fine-grained array of general-purpose processing elements, each capable of light capture, data storage, program execution, and communication with neighboring elements. This allows images to be stored and manipulated directly at the point of light capture, rather than having to transfer images to external processing hardware. Our CNN approach divides this array up into 4x4 blocks of processing elements, essentially trading-off image resolution for increased local memory capacity per 4x4 "pixel". We implement parallel operations for image addition, subtraction and bit-shifting images in this 4x4 block format. Using these components we formulate how to perform ternary weight convolutions upon these images, compactly store results of such convolutions, perform max-pooling, and transfer the resulting sub-sampled data to an attached micro-controller. We train ternary weight filter CNNs for digit recognition and a simple tracking task, and demonstrate inference of these networks upon the SCAMP5 PPA system. This work represents a first step towards embedding neural network processing capability directly onto the focal plane of a sensor.
Context-Aware Domain Adaptation in Semantic Segmentation
Mar 09, 2020
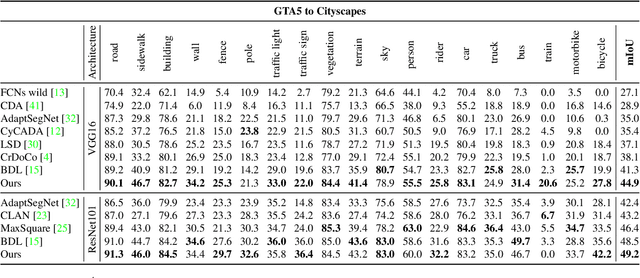
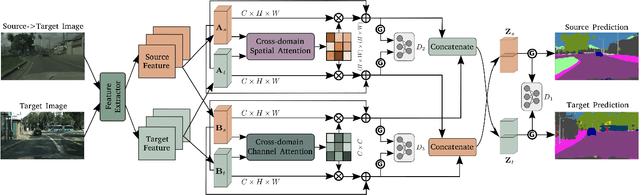
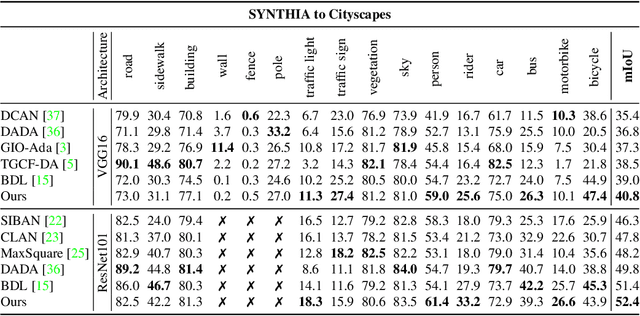
In this paper, we consider the problem of unsupervised domain adaptation in the semantic segmentation. There are two primary issues in this field, i.e., what and how to transfer domain knowledge across two domains. Existing methods mainly focus on adapting domain-invariant features (what to transfer) through adversarial learning (how to transfer). Context dependency is essential for semantic segmentation, however, its transferability is still not well understood. Furthermore, how to transfer contextual information across two domains remains unexplored. Motivated by this, we propose a cross-attention mechanism based on self-attention to capture context dependencies between two domains and adapt transferable context. To achieve this goal, we design two cross-domain attention modules to adapt context dependencies from both spatial and channel views. Specifically, the spatial attention module captures local feature dependencies between each position in the source and target image. The channel attention module models semantic dependencies between each pair of cross-domain channel maps. To adapt context dependencies, we further selectively aggregate the context information from two domains. The superiority of our method over existing state-of-the-art methods is empirically proved on "GTA5 to Cityscapes" and "SYNTHIA to Cityscapes".
Fast reconstruction of atomic-scale STEM-EELS images from sparse sampling
Feb 04, 2020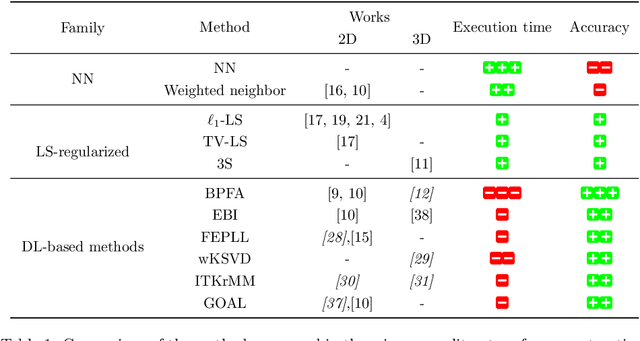

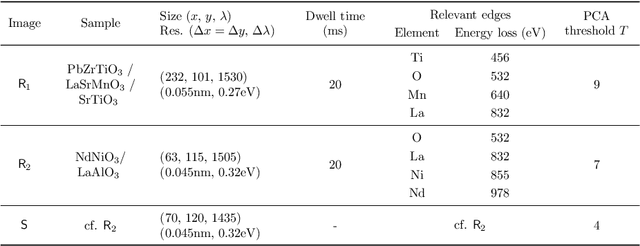
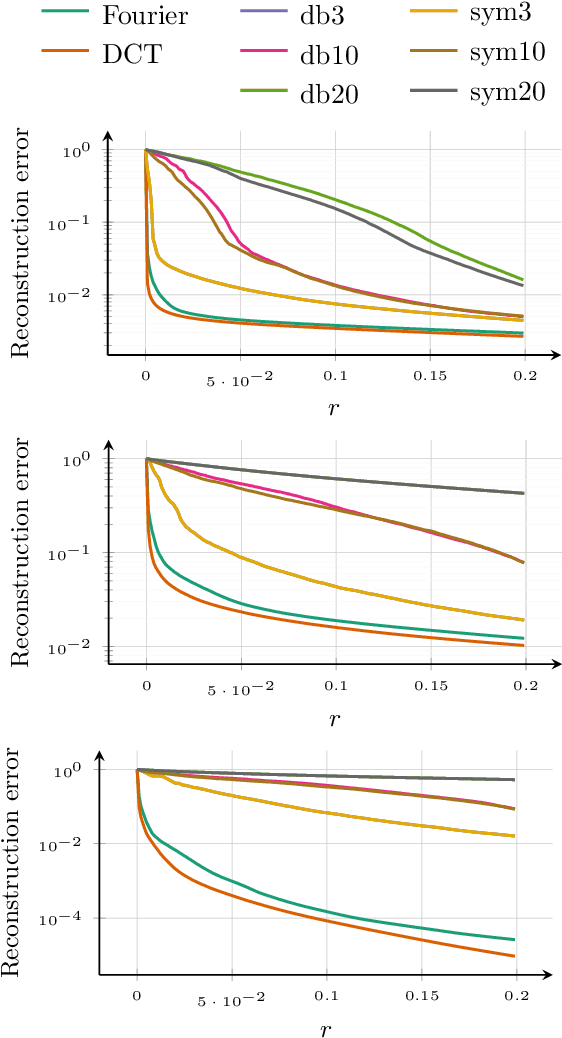
This paper discusses the reconstruction of partially sampled spectrum-images to accelerate the acquisition in scanning transmission electron microscopy (STEM). The problem of image reconstruction has been widely considered in the literature for many imaging modalities, but only a few attempts handled 3D data such as spectral images acquired by STEM electron energy loss spectroscopy (EELS). Besides, among the methods proposed in the microscopy literature, some are fast but inaccurate while others provide accurate reconstruction but at the price of a high computation burden. Thus none of the proposed reconstruction methods fulfills our expectations in terms of accuracy and computation complexity. In this paper, we propose a fast and accurate reconstruction method suited for atomic-scale EELS. This method is compared to popular solutions such as beta process factor analysis (BPFA) which is used for the first time on STEM-EELS images. Experiments based on real as synthetic data will be conducted.
Predicting Actions to Help Predict Translations
Aug 05, 2019
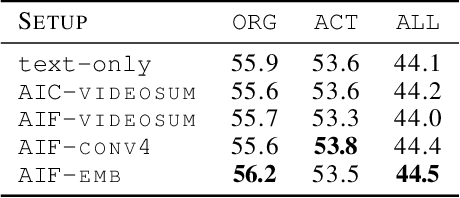


We address the task of text translation on the How2 dataset using a state of the art transformer-based multimodal approach. The question we ask ourselves is whether visual features can support the translation process, in particular, given that this is a dataset extracted from videos, we focus on the translation of actions, which we believe are poorly captured in current static image-text datasets currently used for multimodal translation. For that purpose, we extract different types of action features from the videos and carefully investigate how helpful this visual information is by testing whether it can increase translation quality when used in conjunction with (i) the original text and (ii) the original text where action-related words (or all verbs) are masked out. The latter is a simulation that helps us assess the utility of the image in cases where the text does not provide enough context about the action, or in the presence of noise in the input text.
Unsupervised Multiple Person Tracking using AutoEncoder-Based Lifted Multicuts
Feb 04, 2020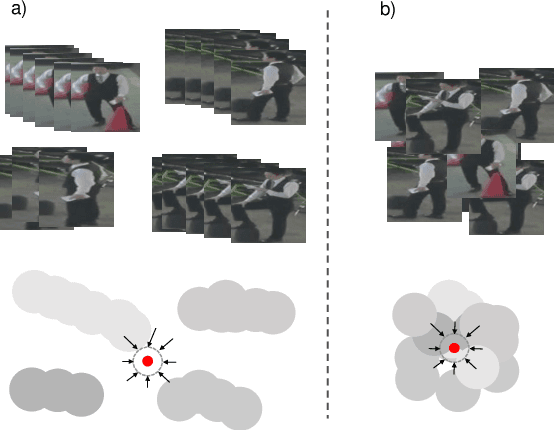
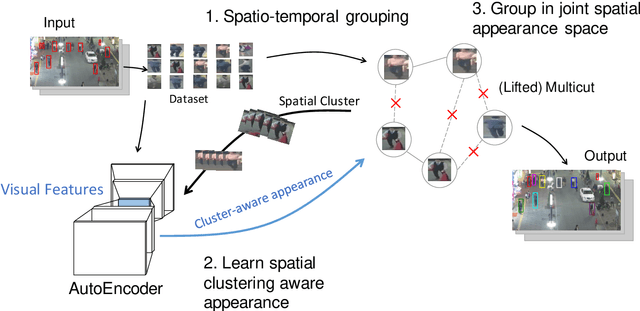
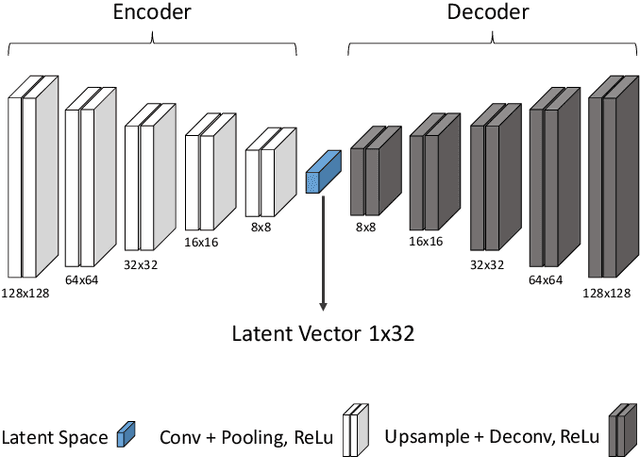

Multiple Object Tracking (MOT) is a long-standing task in computer vision. Current approaches based on the tracking by detection paradigm either require some sort of domain knowledge or supervision to associate data correctly into tracks. In this work, we present an unsupervised multiple object tracking approach based on visual features and minimum cost lifted multicuts. Our method is based on straight-forward spatio-temporal cues that can be extracted from neighboring frames in an image sequences without superivison. Clustering based on these cues enables us to learn the required appearance invariances for the tracking task at hand and train an autoencoder to generate suitable latent representation. Thus, the resulting latent representations can serve as robust appearance cues for tracking even over large temporal distances where no reliable spatio-temporal features could be extracted. We show that, despite being trained without using the provided annotations, our model provides competitive results on the challenging MOT Benchmark for pedestrian tracking.
Linear Spatial Pyramid Matching Using Non-convex and non-negative Sparse Coding for Image Classification
Apr 27, 2015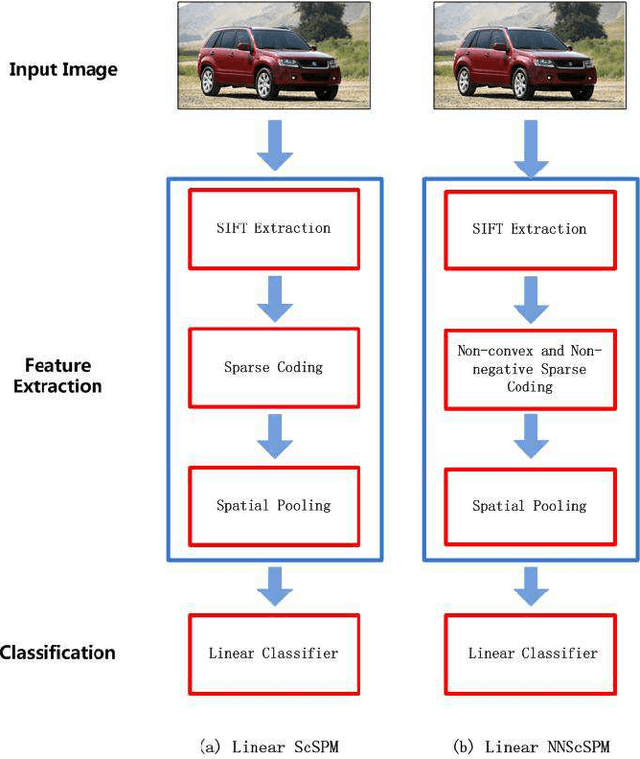
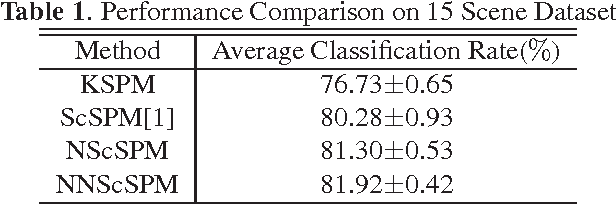
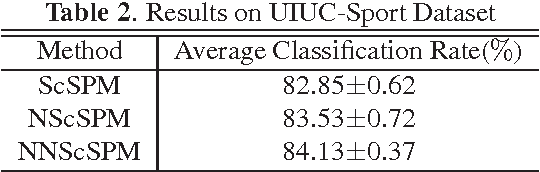
Recently sparse coding have been highly successful in image classification mainly due to its capability of incorporating the sparsity of image representation. In this paper, we propose an improved sparse coding model based on linear spatial pyramid matching(SPM) and Scale Invariant Feature Transform (SIFT ) descriptors. The novelty is the simultaneous non-convex and non-negative characters added to the sparse coding model. Our numerical experiments show that the improved approach using non-convex and non-negative sparse coding is superior than the original ScSPM[1] on several typical databases.
MLSL: Multi-Level Self-Supervised Learning for Domain Adaptation with Spatially Independent and Semantically Consistent Labeling
Sep 30, 2019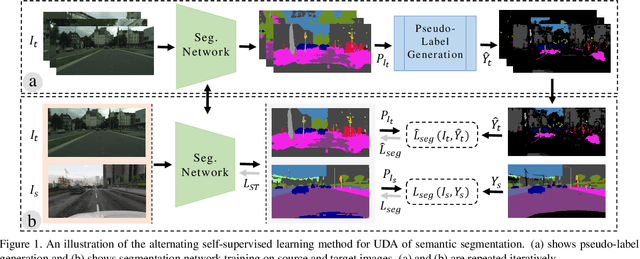
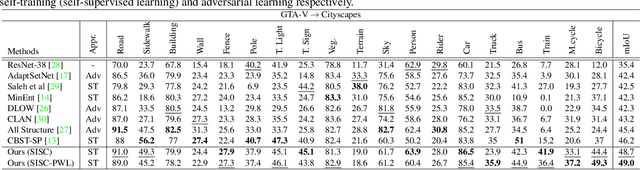
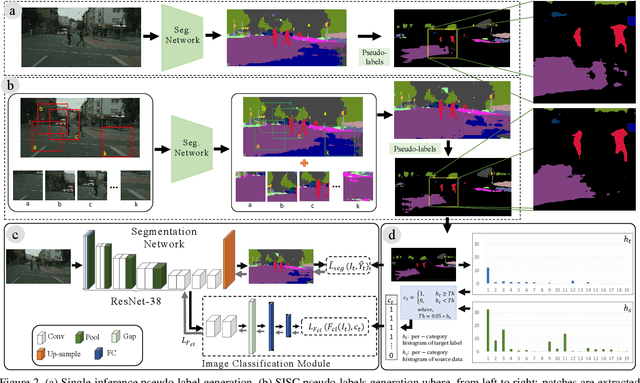
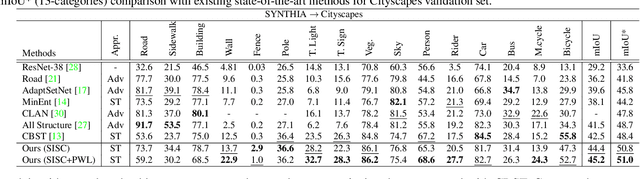
Most of the recent Deep Semantic Segmentation algorithms suffer from large generalization errors, even when powerful hierarchical representation models based on convolutional neural networks have been employed. This could be attributed to limited training data and large distribution gap in train and test domain datasets. In this paper, we propose a multi-level self-supervised learning model for domain adaptation of semantic segmentation. Exploiting the idea that an object (and most of the stuff given context) should be labeled consistently regardless of its location, we generate spatially independent and semantically consistent (SISC) pseudo-labels by segmenting multiple sub-images using base model and designing an aggregation strategy. Image level pseudo weak-labels, PWL, are computed to guide domain adaptation by capturing global context similarity in source and domain at latent space level. Thus helping latent space learn the representation even when there are very few pixels belonging to the domain category (small object for example) compared to rest of the image. Our multi-level Self-supervised learning (MLSL) outperforms existing state-of art (self or adversarial learning) algorithms. Specifically, keeping all setting similar and employing MLSL we obtain an mIoU gain of 5:1% on GTA-V to Cityscapes adaptation and 4:3% on SYNTHIA to Cityscapes adaptation compared to existing state-of-art method.
Weighted Mean Curvature
Mar 17, 2019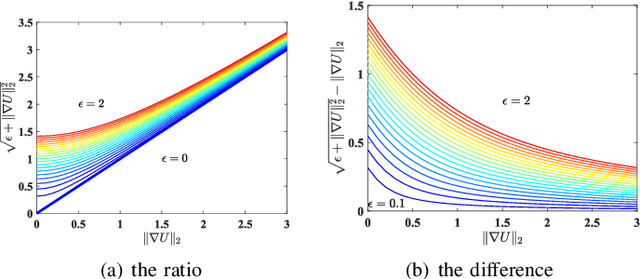
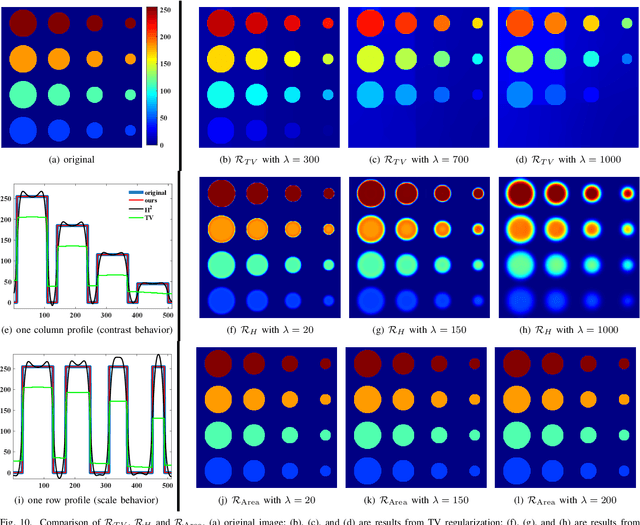
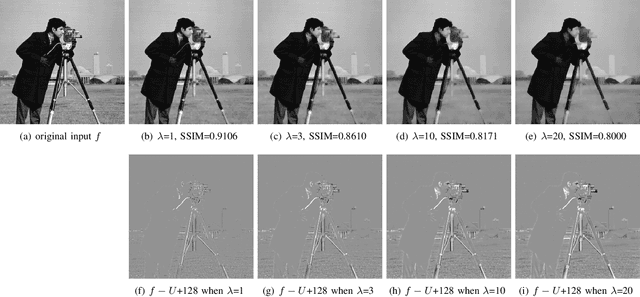

In image processing tasks, spatial priors are essential for robust computations, regularization, algorithmic design and Bayesian inference. In this paper, we introduce weighted mean curvature (WMC) as a novel image prior and present an efficient computation scheme for its discretization in practical image processing applications. We first demonstrate the favorable properties of WMC, such as sampling invariance, scale invariance, and contrast invariance with Gaussian noise model; and we show the relation of WMC to area regularization. We further propose an efficient computation scheme for discretized WMC, which is demonstrated herein to process over 33.2 giga-pixels/second on GPU. This scheme yields itself to a convolutional neural network representation. Finally, WMC is evaluated on synthetic and real images, showing its superiority quantitatively to total-variation and mean curvature.
Dense RepPoints: Representing Visual Objects with Dense Point Sets
Dec 24, 2019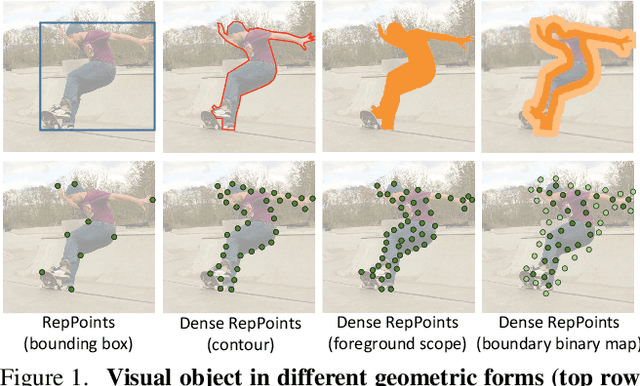
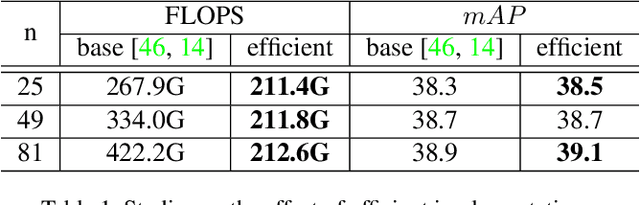
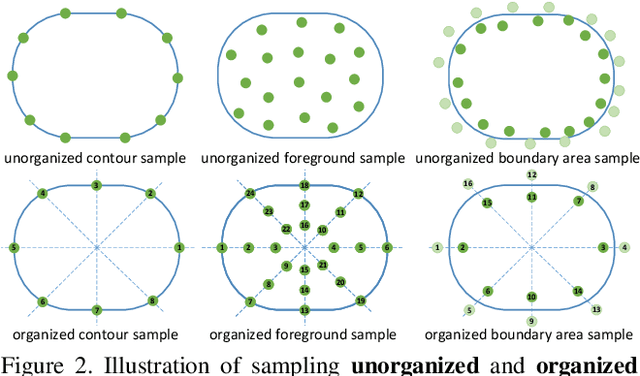
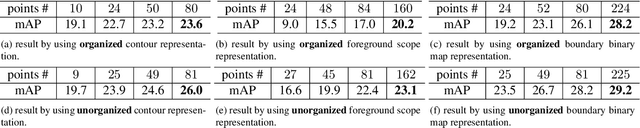
We present an object representation, called \textbf{Dense RepPoints}, for flexible and detailed modeling of object appearance and geometry. In contrast to the coarse geometric localization and feature extraction of bounding boxes, Dense RepPoints adaptively distributes a dense set of points to semantically and geometrically significant positions on an object, providing informative cues for object analysis. Techniques are developed to address challenges related to supervised training for dense point sets from image segments annotations and making this extensive representation computationally practical. In addition, the versatility of this representation is exploited to model object structure over multiple levels of granularity. Dense RepPoints significantly improves performance on geometrically-oriented visual understanding tasks, including a $1.6$ AP gain in object detection on the challenging COCO benchmark.
A linear method for camera pair self-calibration and multi-view reconstruction with geometrically verified correspondences
Jun 28, 2019
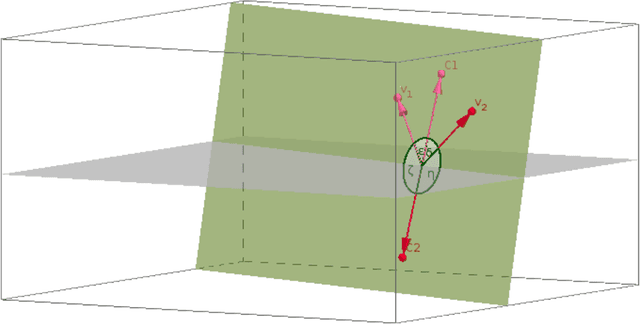
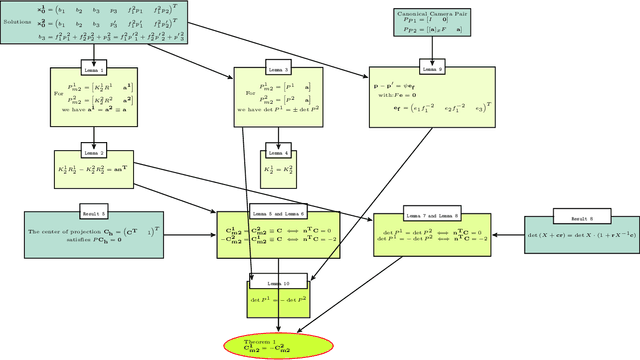

We examine 3D reconstruction of architectural scenes in unordered sets of uncalibrated images. We introduce a linear method to self-calibrate and find the metric reconstruction of a camera pair. We assume unknown and different focal lengths but otherwise known internal camera parameters and a known projective reconstruction of the camera pair. We recover two possible camera configurations in space and use the Cheirality condition, that all 3D scene points are in front of both cameras, to disambiguate the solution. We show in two Theorems, first that the two solutions are in mirror positions and then the relations between their viewing directions. Our new method performs on par (median rotation error $\Delta R = 3.49^{\circ}$) with the standard approach of Kruppa equations ($\Delta R = 3.77^{\circ}$) for self-calibration and 5-Point algorithm for calibrated metric reconstruction of a camera pair. We reject erroneous image correspondences by introducing a method to examine whether point correspondences appear in the same order along $x, y$ image axes in image pairs. We evaluate this method by its precision and recall and show that it improves the robustness of point matches in architectural and general scenes. Finally, we integrate all the introduced methods to a 3D reconstruction pipeline. We utilize the numerous camera pair metric recontructions using rotation-averaging algorithms and a novel method to average focal length estimates.