 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiSubs: A Large-scale Multimodal and Multilingual Dataset
Mar 02, 2021
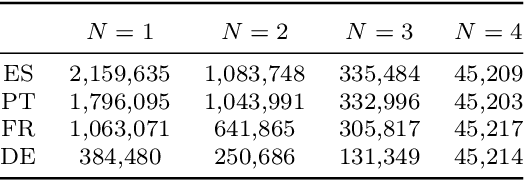
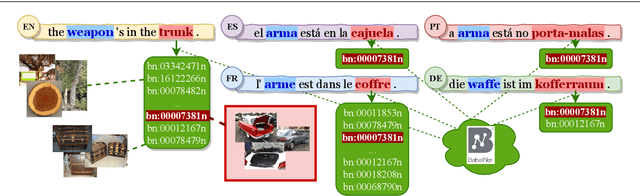
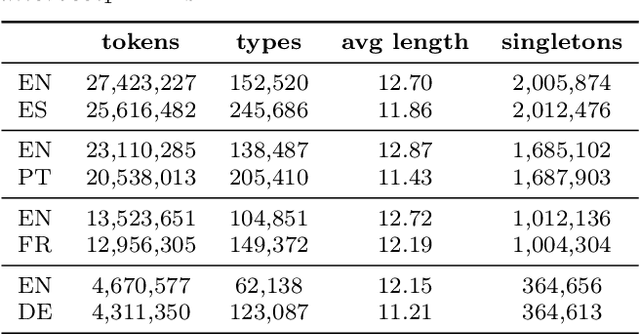
This paper introduces a large-scale multimodal and multilingual dataset that aims to facilitate research on grounding words to images in their contextual usage in language. The dataset consists of images selected to unambiguously illustrate concepts expressed in sentences from movie subtitles. The dataset is a valuable resource as (i) the images are aligned to text fragments rather than whole sentences; (ii) multiple images are possible for a text fragment and a sentence; (iii) the sentences are free-form and real-world like; (iv) the parallel texts are multilingual. We set up a fill-in-the-blank game for humans to evaluate the quality of the automatic image selection process of our dataset. We show the utility of the dataset on two automatic tasks: (i) fill-in-the blank; (ii) lexical translation. Results of the human evaluation and automatic models demonstrate that images can be a useful complement to the textual context. The dataset will benefit research on visual grounding of words especially in the context of free-form sentences.
Transformer-based Cascaded Multimodal Speech Translation
Nov 08, 2019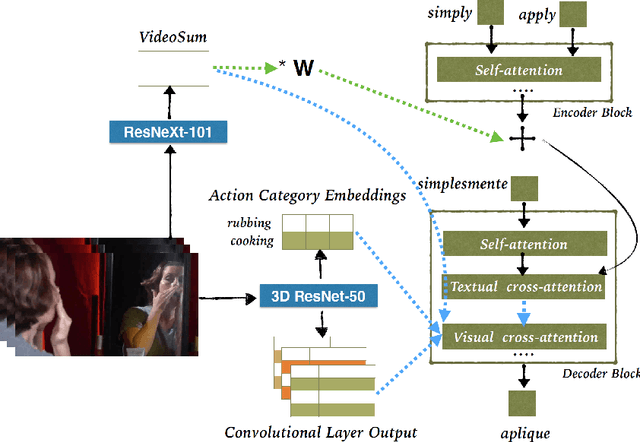
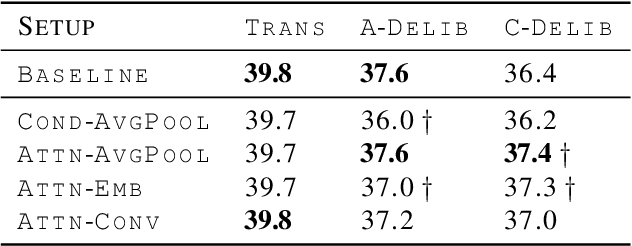
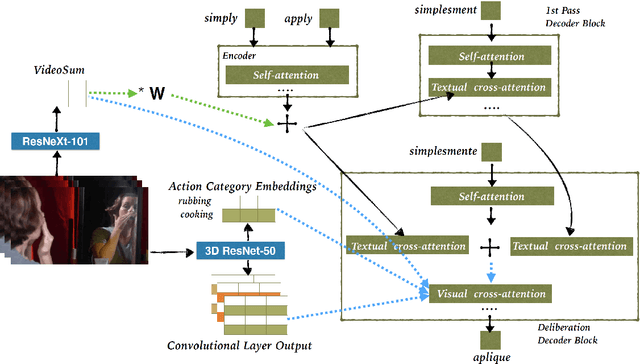
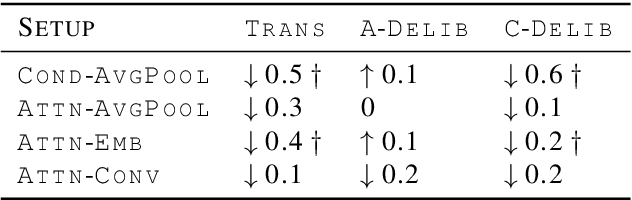
This paper describes the cascaded multimodal speech translation systems developed by Imperial College London for the IWSLT 2019 evaluation campaign. The architecture consists of an automatic speech recognition (ASR) system followed by a Transformer-based multimodal machine translation (MMT) system. While the ASR component is identical across the experiments, the MMT model varies in terms of the way of integrating the visual context (simple conditioning vs. attention), the type of visual features exploited (pooled, convolutional, action categories) and the underlying architecture. For the latter, we explore both the canonical transformer and its deliberation version with additive and cascade variants which differ in how they integrate the textual attention. Upon conducting extensive experiments, we found that (i) the explored visual integration schemes often harm the translation performance for the transformer and additive deliberation, but considerably improve the cascade deliberation; (ii) the transformer and cascade deliberation integrate the visual modality better than the additive deliberation, as shown by the incongruence analysis.
Imperial College London Submission to VATEX Video Captioning Task
Oct 16, 2019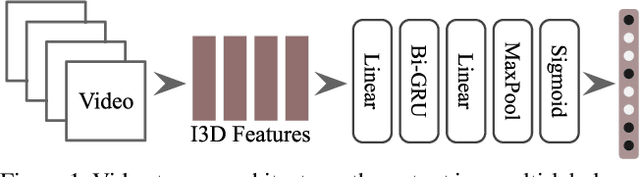
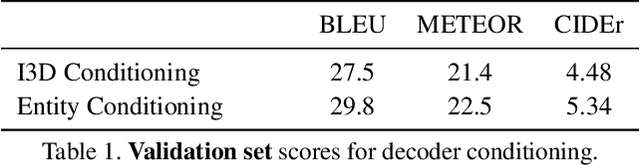
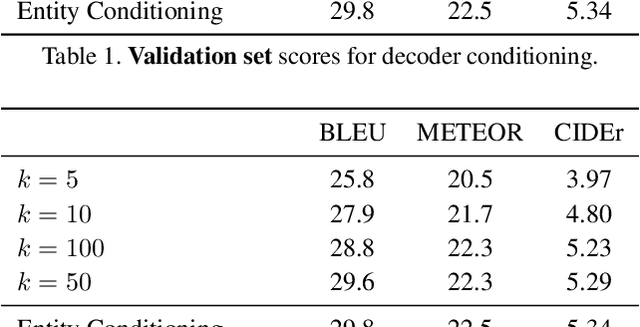
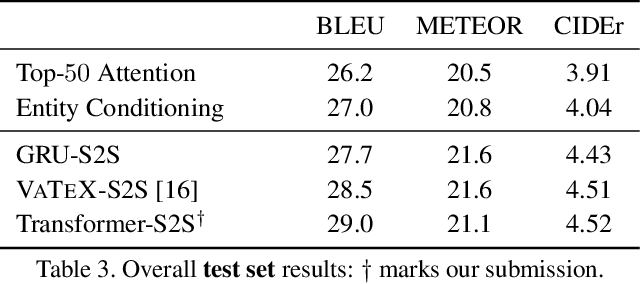
This paper describes the Imperial College London team's submission to the 2019' VATEX video captioning challenge, where we first explore two sequence-to-sequence models, namely a recurrent (GRU) model and a transformer model, which generate captions from the I3D action features. We then investigate the effect of dropping the encoder and the attention mechanism and instead conditioning the GRU decoder over two different vectorial representations: (i) a max-pooled action feature vector and (ii) the output of a multi-label classifier trained to predict visual entities from the action features. Our baselines achieved scores comparable to the official baseline. Conditioning over entity predictions performed substantially better than conditioning on the max-pooled feature vector, and only marginally worse than the GRU-based sequence-to-sequence baseline.
Phrase Localization Without Paired Training Examples
Aug 20, 2019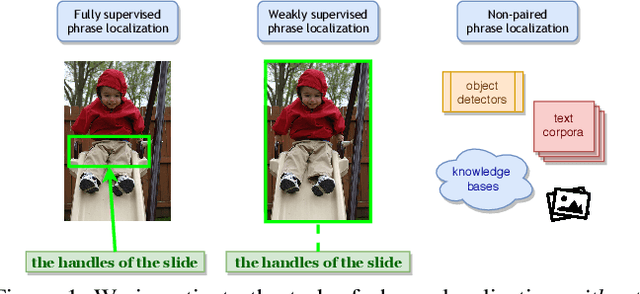
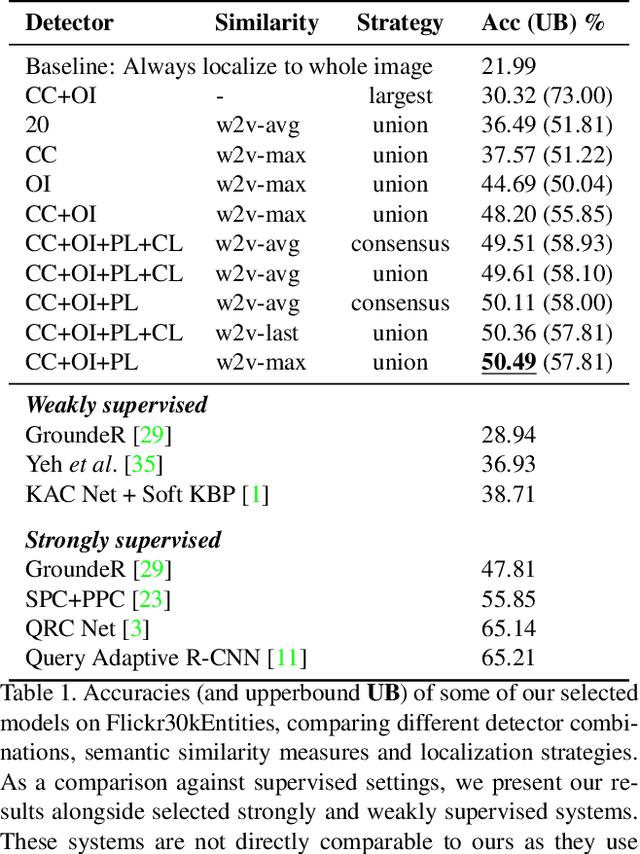
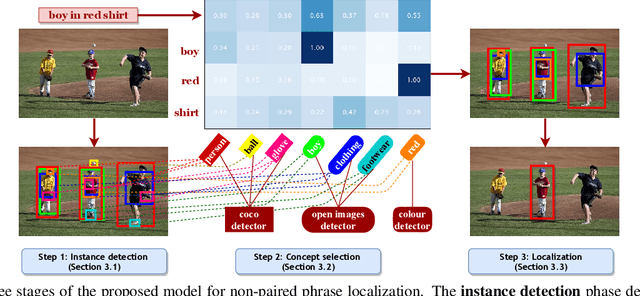
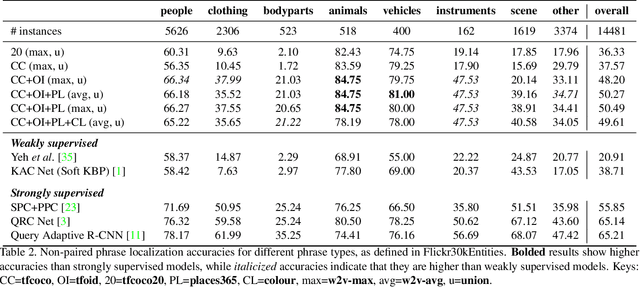
Localizing phrases in images is an important part of image understanding and can be useful in many applications that require mappings between textual and visual information. Existing work attempts to learn these mappings from examples of phrase-image region correspondences (strong supervision) or from phrase-image pairs (weak supervision). We postulate that such paired annotations are unnecessary, and propose the first method for the phrase localization problem where neither training procedure nor paired, task-specific data is required. Our method is simple but effective: we use off-the-shelf approaches to detect objects, scenes and colours in images, and explore different approaches to measure semantic similarity between the categories of detected visual elements and words in phrases. Experiments on two well-known phrase localization datasets show that this approach surpasses all weakly supervised methods by a large margin and performs very competitively to strongly supervised methods, and can thus be considered a strong baseline to the task. The non-paired nature of our method makes it applicable to any domain and where no paired phrase localization annotation is available.
Predicting Actions to Help Predict Translations
Aug 18, 2019
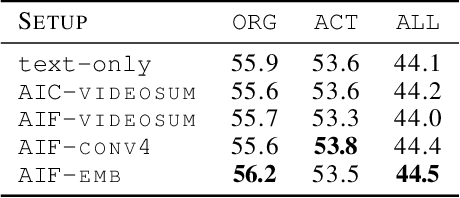


We address the task of text translation on the How2 dataset using a state of the art transformer-based multimodal approach. The question we ask ourselves is whether visual features can support the translation process, in particular, given that this is a dataset extracted from videos, we focus on the translation of actions, which we believe are poorly captured in current static image-text datasets currently used for multimodal translation. For that purpose, we extract different types of action features from the videos and carefully investigate how helpful this visual information is by testing whether it can increase translation quality when used in conjunction with (i) the original text and (ii) the original text where action-related words (or all verbs) are masked out. The latter is a simulation that helps us assess the utility of the image in cases where the text does not provide enough context about the action, or in the presence of noise in the input text.
VIFIDEL: Evaluating the Visual Fidelity of Image Descriptions
Jul 22, 2019
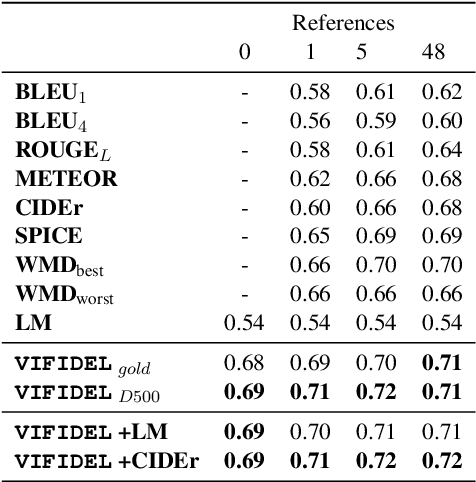
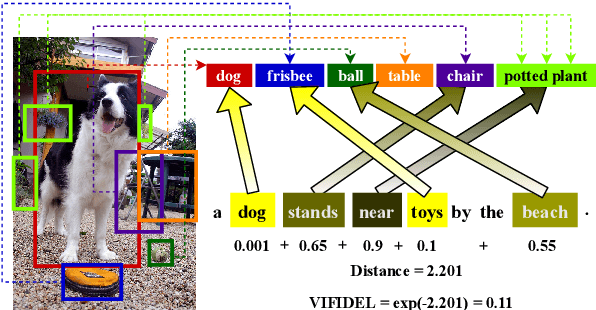
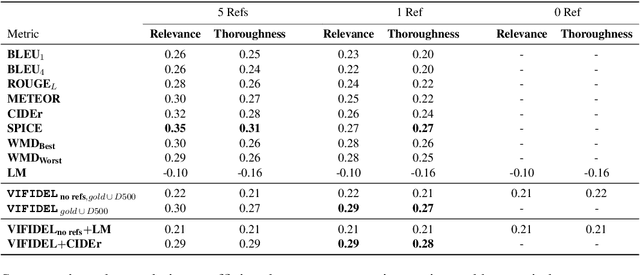
We address the task of evaluating image description generation systems. We propose a novel image-aware metric for this task: VIFIDEL. It estimates the faithfulness of a generated caption with respect to the content of the actual image, based on the semantic similarity between labels of objects depicted in images and words in the description. The metric is also able to take into account the relative importance of objects mentioned in human reference descriptions during evaluation. Even if these human reference descriptions are not available, VIFIDEL can still reliably evaluate system descriptions. The metric achieves high correlation with human judgments on two well-known datasets and is competitive with metrics that depend on human references
End-to-end Image Captioning Exploits Multimodal Distributional Similarity
Sep 11, 2018
We hypothesize that end-to-end neural image captioning systems work seemingly well because they exploit and learn `distributional similarity' in a multimodal feature space by mapping a test image to similar training images in this space and generating a caption from the same space. To validate our hypothesis, we focus on the `image' side of image captioning, and vary the input image representation but keep the RNN text generation component of a CNN-RNN model constant. Our analysis indicates that image captioning models (i) are capable of separating structure from noisy input representations; (ii) suffer virtually no significant performance loss when a high dimensional representation is compressed to a lower dimensional space; (iii) cluster images with similar visual and linguistic information together. Our findings indicate that our distributional similarity hypothesis holds. We conclude that regardless of the image representation used image captioning systems seem to match images and generate captions in a learned joint image-text semantic subspace.
Defoiling Foiled Image Captions
May 16, 2018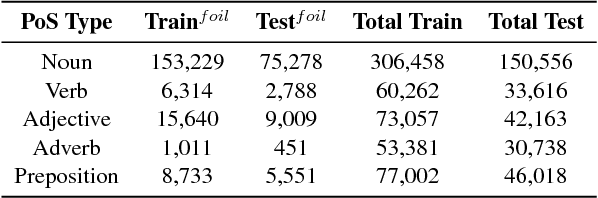

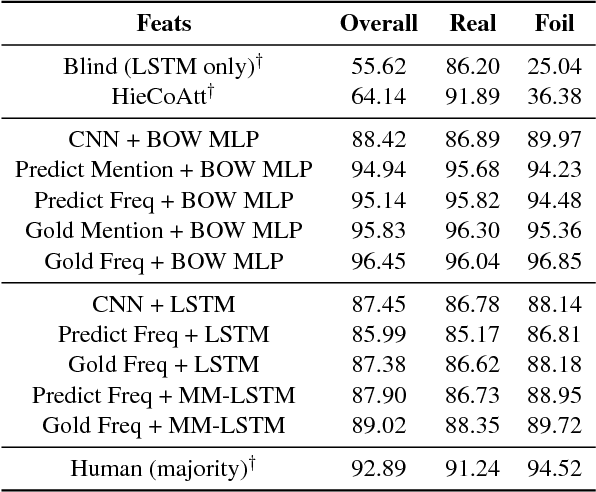
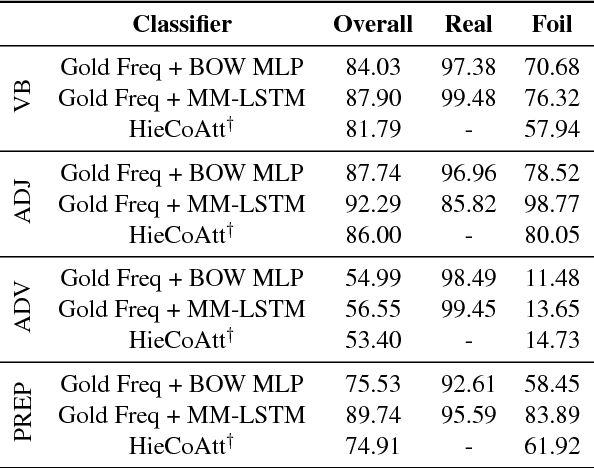
We address the task of detecting foiled image captions, i.e. identifying whether a caption contains a word that has been deliberately replaced by a semantically similar word, thus rendering it inaccurate with respect to the image being described. Solving this problem should in principle require a fine-grained understanding of images to detect linguistically valid perturbations in captions. In such contexts, encoding sufficiently descriptive image information becomes a key challenge. In this paper, we demonstrate that it is possible to solve this task using simple, interpretable yet powerful representations based on explicit object information. Our models achieve state-of-the-art performance on a standard dataset, with scores exceeding those achieved by humans on the task. We also measure the upper-bound performance of our models using gold standard annotations. Our analysis reveals that the simpler model performs well even without image information, suggesting that the dataset contains strong linguistic bias.
Object Counts! Bringing Explicit Detections Back into Image Captioning
Apr 23, 2018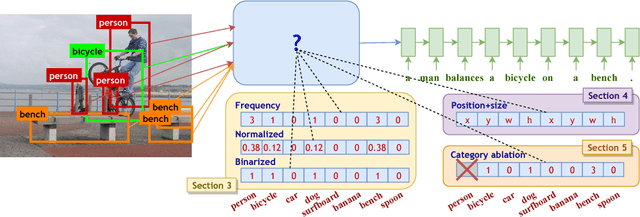
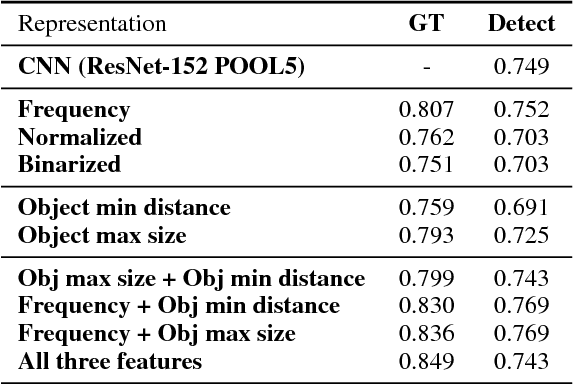


The use of explicit object detectors as an intermediate step to image captioning - which used to constitute an essential stage in early work - is often bypassed in the currently dominant end-to-end approaches, where the language model is conditioned directly on a mid-level image embedding. We argue that explicit detections provide rich semantic information, and can thus be used as an interpretable representation to better understand why end-to-end image captioning systems work well. We provide an in-depth analysis of end-to-end image captioning by exploring a variety of cues that can be derived from such object detections. Our study reveals that end-to-end image captioning systems rely on matching image representations to generate captions, and that encoding the frequency, size and position of objects are complementary and all play a role in forming a good image representation. It also reveals that different object categories contribute in different ways towards image captioning.
Visual and Semantic Knowledge Transfer for Large Scale Semi-supervised Object Detection
Mar 13, 2018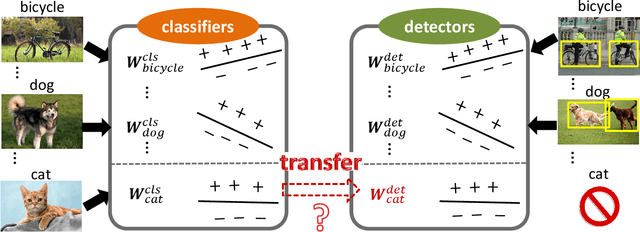
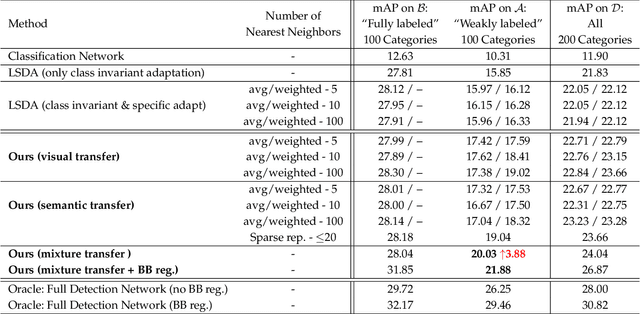
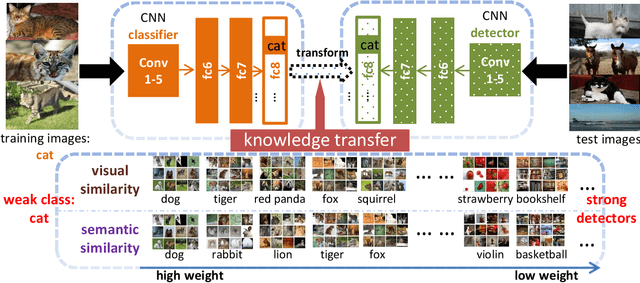

Deep CNN-based object detection systems have achieved remarkable success on several large-scale object detection benchmarks. However, training such detectors requires a large number of labeled bounding boxes, which are more difficult to obtain than image-level annotations. Previous work addresses this issue by transforming image-level classifiers into object detectors. This is done by modeling the differences between the two on categories with both image-level and bounding box annotations, and transferring this information to convert classifiers to detectors for categories without bounding box annotations. We improve this previous work by incorporating knowledge about object similarities from visual and semantic domains during the transfer process. The intuition behind our proposed method is that visually and semantically similar categories should exhibit more common transferable properties than dissimilar categories, e.g. a better detector would result by transforming the differences between a dog classifier and a dog detector onto the cat class, than would by transforming from the violin class. Experimental results on the challenging ILSVRC2013 detection dataset demonstrate that each of our proposed object similarity based knowledge transfer methods outperforms the baseline methods. We found strong evidence that visual similarity and semantic relatedness are complementary for the task, and when combined notably improve detection, achieving state-of-the-art detection performance in a semi-supervised setting.
* TPAMI. correct some typos