 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dynamic Context-guided Capsule Network for Multimodal Machine Translation
Sep 04, 2020
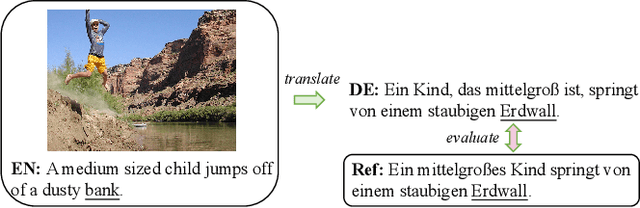
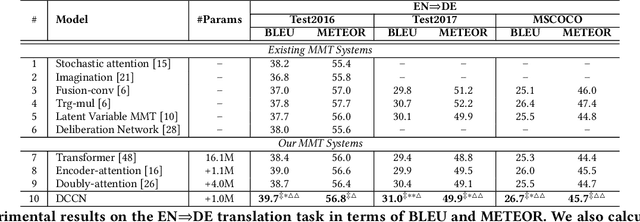
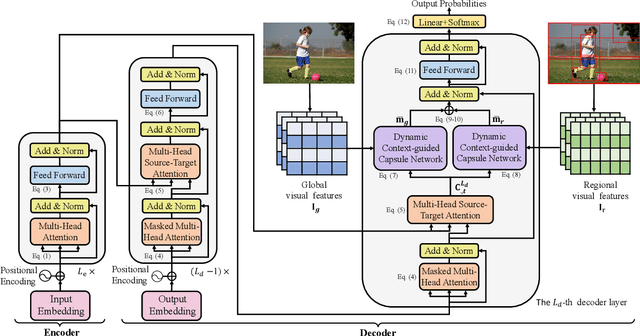
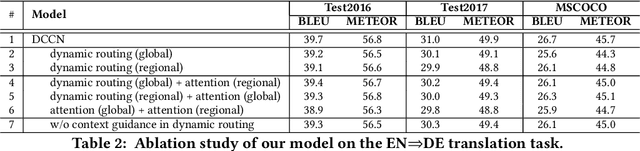
Multimodal machine translation (MMT), which mainly focuses on enhancing text-only translation with visual features, has attracted considerable attention from both computer vision and natural language processing communities. Most current MMT models resort to attention mechanism, global context modeling or multimodal joint representation learning to utilize visual features. However, the attention mechanism lacks sufficient semantic interactions between modalities while the other two provide fixed visual context, which is unsuitable for modeling the observed variability when generating translation. To address the above issues, in this paper, we propose a novel Dynamic Context-guided Capsule Network (DCCN) for MMT. Specifically, at each timestep of decoding, we first employ the conventional source-target attention to produce a timestep-specific source-side context vector. Next, DCCN takes this vector as input and uses it to guide the iterative extraction of related visual features via a context-guided dynamic routing mechanism. Particularly, we represent the input image with global and regional visual features, we introduce two parallel DCCNs to model multimodal context vectors with visual features at different granularities. Finally, we obtain two multimodal context vectors, which are fused and incorporated into the decoder for the prediction of the target word. Experimental results on the Multi30K dataset of English-to-German and English-to-French translation demonstrate the superiority of DCCN. Our code is available on https://github.com/DeepLearnXMU/MM-DCCN.
Scan-based Semantic Segmentation of LiDAR Point Clouds: An Experimental Study
Apr 28, 2020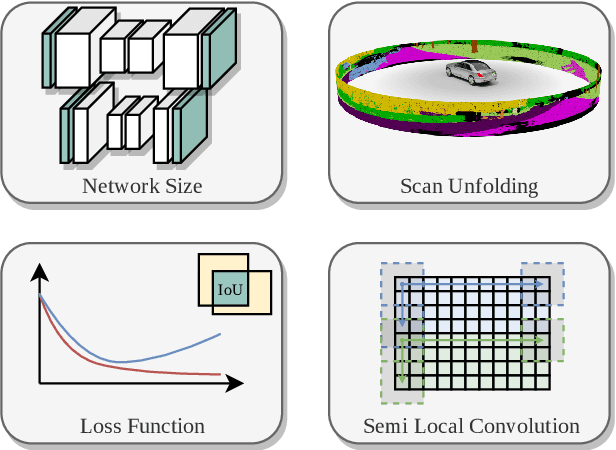
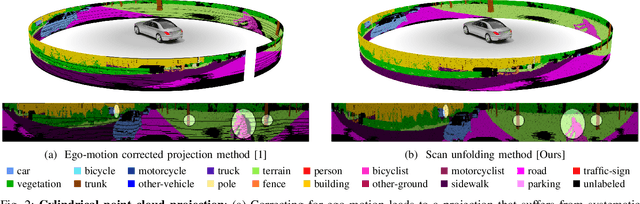
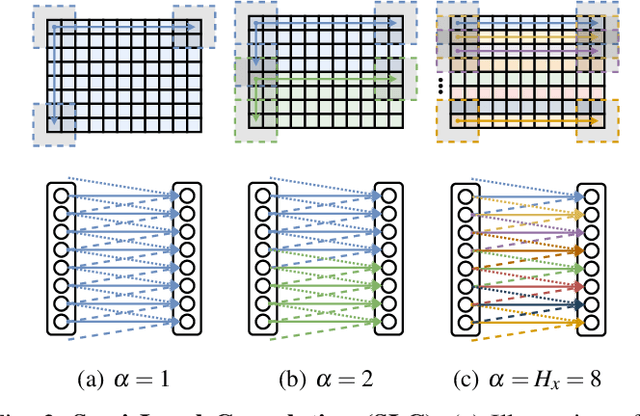
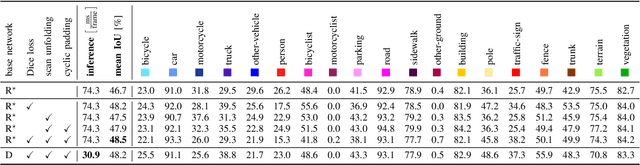
Autonomous vehicles need to have a semantic understanding of the three-dimensional world around them in order to reason about their environment. State of the art methods use deep neural networks to predict semantic classes for each point in a LiDAR scan. A powerful and efficient way to process LiDAR measurements is to use two-dimensional, image-like projections. In this work, we perform a comprehensive experimental study of image-based semantic segmentation architectures for LiDAR point clouds. We demonstrate various techniques to boost the performance and to improve runtime as well as memory constraints. First, we examine the effect of network size and suggest that much faster inference times can be achieved at a very low cost to accuracy. Next, we introduce an improved point cloud projection technique that does not suffer from systematic occlusions. We use a cyclic padding mechanism that provides context at the horizontal field-of-view boundaries. In a third part, we perform experiments with a soft Dice loss function that directly optimizes for the intersection-over-union metric. Finally, we propose a new kind of convolution layer with a reduced amount of weight-sharing along one of the two spatial dimensions, addressing the large difference in appearance along the vertical axis of a LiDAR scan. We propose a final set of the above methods with which the model achieves an increase of 3.2% in mIoU segmentation performance over the baseline while requiring only 42% of the original inference time.
Old Photo Restoration via Deep Latent Space Translation
Sep 14, 2020
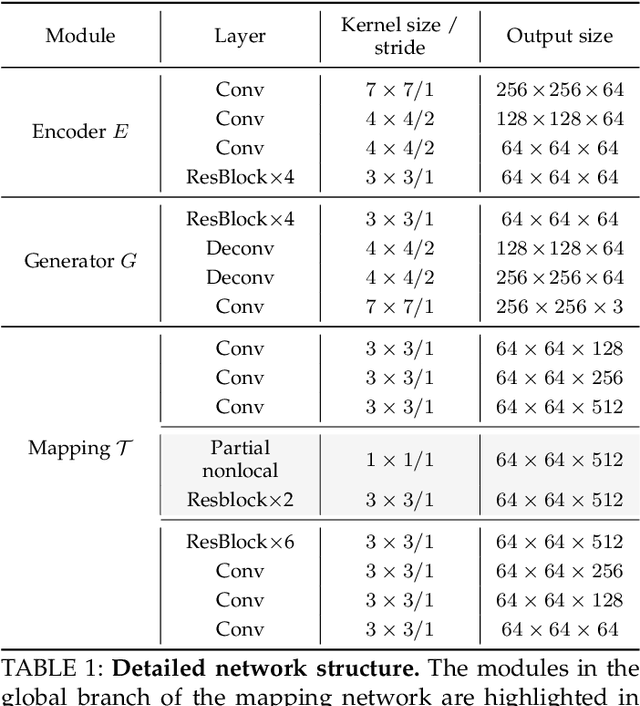
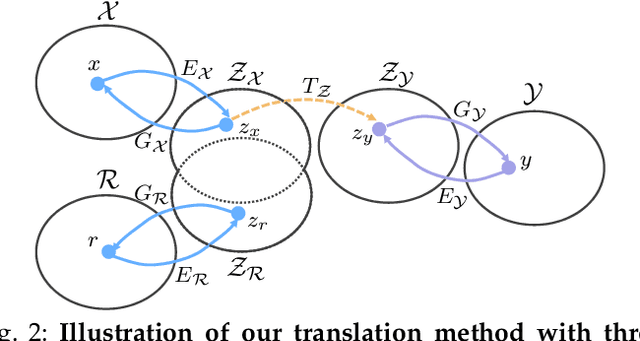
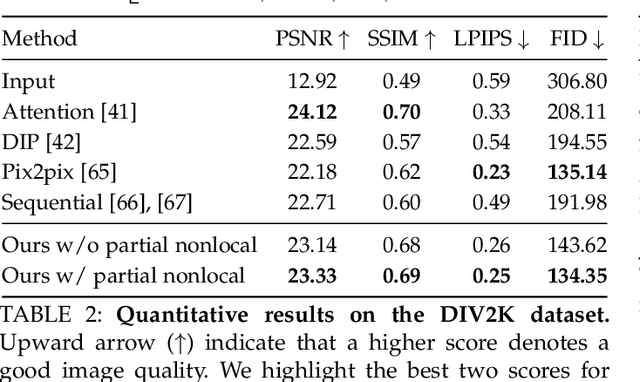
We propose to restore old photos that suffer from severe degradation through a deep learning approach. Unlike conventional restoration tasks that can be solved through supervised learning, the degradation in real photos is complex and the domain gap between synthetic images and real old photos makes the network fail to generalize. Therefore, we propose a novel triplet domain translation network by leveraging real photos along with massive synthetic image pairs. Specifically, we train two variational autoencoders (VAEs) to respectively transform old photos and clean photos into two latent spaces. And the translation between these two latent spaces is learned with synthetic paired data. This translation generalizes well to real photos because the domain gap is closed in the compact latent space. Besides, to address multiple degradations mixed in one old photo, we design a global branch with apartial nonlocal block targeting to the structured defects, such as scratches and dust spots, and a local branch targeting to the unstructured defects, such as noises and blurriness. Two branches are fused in the latent space, leading to improved capability to restore old photos from multiple defects. Furthermore, we apply another face refinement network to recover fine details of faces in the old photos, thus ultimately generating photos with enhanced perceptual quality. With comprehensive experiments, the proposed pipeline demonstrates superior performance over state-of-the-art methods as well as existing commercial tools in terms of visual quality for old photos restoration.
Generative Modelling of 3D in-silico Spongiosa with Controllable Micro-Structural Parameters
Sep 23, 2020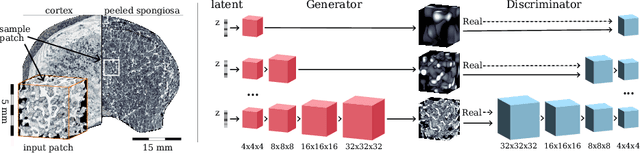
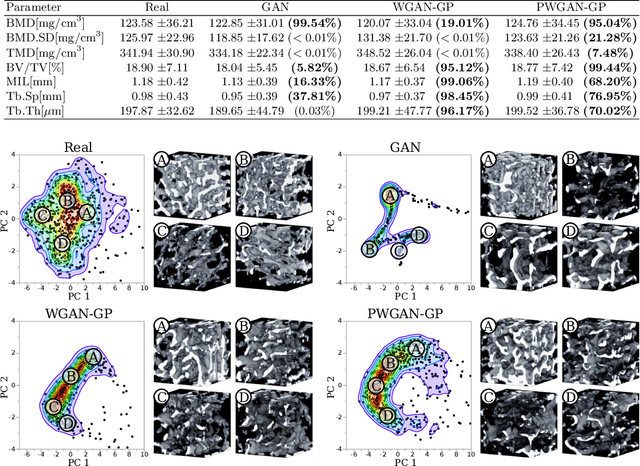
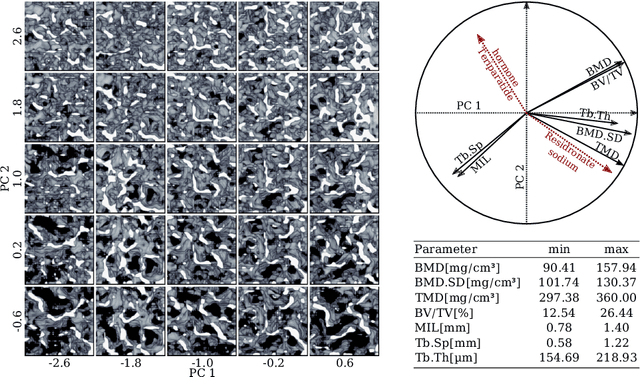

Research in vertebral bone micro-structure generally requires costly procedures to obtain physical scans of real bone with a specific pathology under study, since no methods are available yet to generate realistic bone structures in-silico. Here we propose to apply recent advances in generative adversarial networks (GANs) to develop such a method. We adapted style-transfer techniques, which have been largely used in other contexts, in order to transfer style between image pairs while preserving its informational content. In a first step, we trained a volumetric generative model in a progressive manner using a Wasserstein objective and gradient penalty (PWGAN-GP) to create patches of realistic bone structure in-silico. The training set contained 7660 purely spongeous bone samples from twelve human vertebrae (T12 or L1) with isotropic resolution of 164um and scanned with a high resolution peripheral quantitative CT (Scanco XCT). After training, we generated new samples with tailored micro-structure properties by optimizing a vector z in the learned latent space. To solve this optimization problem, we formulated a differentiable goal function that leads to valid samples while compromising the appearance (content) with target 3D properties (style). Properties of the learned latent space effectively matched the data distribution. Furthermore, we were able to simulate the resulting bone structure after deterioration or treatment effects of osteoporosis therapies based only on expected changes of micro-structural parameters. Our method allows to generate a virtually infinite number of patches of realistic bone micro-structure, and thereby likely serves for the development of bone-biomarkers and to simulate bone therapies in advance.
PX-NET: Simple, Efficient Pixel-Wise Training of Photometric Stereo Networks
Aug 11, 2020
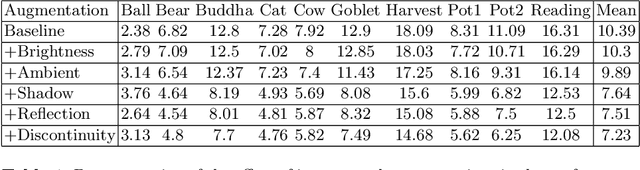
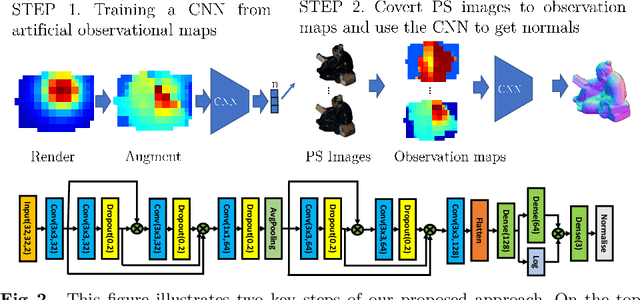
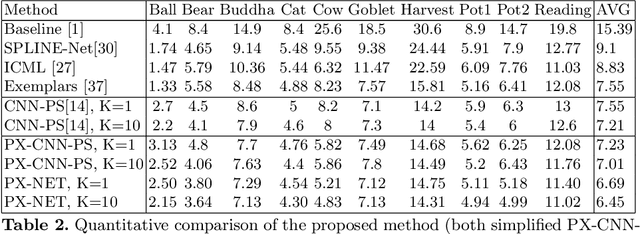
Retrieving accurate 3D reconstructions of objects from the way they reflect light is a very challenging task in computer vision. Despite more than four decades since the definition of the Photometric Stereo problem, most of the literature has had limited success when global illumination effects such as cast shadows, self-reflections and ambient light come into play, especially for specular surfaces. Recent approaches have leveraged the power of deep learning in conjunction with computer graphics in order to cope with the need of a vast number of training data in order to invert the image irradiance equation and retrieve the geometry of the object. However, rendering global illumination effects is a slow process which can limit the amount of training data that can be generated. In this work we propose a novel pixel-wise training procedure for normal prediction by replacing the training data of globally rendered images with independent per-pixel renderings. We show that robustness to global physical effects can be achieved via data-augmentation which greatly simplifies and speeds up the data creation procedure. Our network, PX-NET, achieves the state-of-the-art performance on synthetic datasets, as well as the Diligent real dataset.
Principal Component Properties of Adversarial Samples
Dec 07, 2019
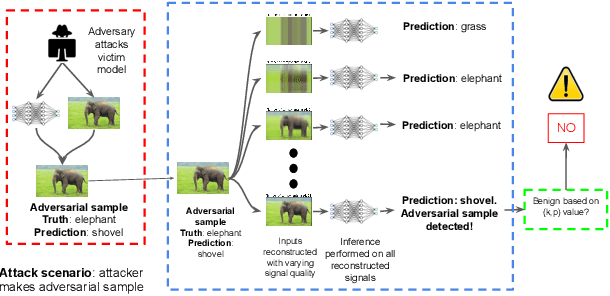
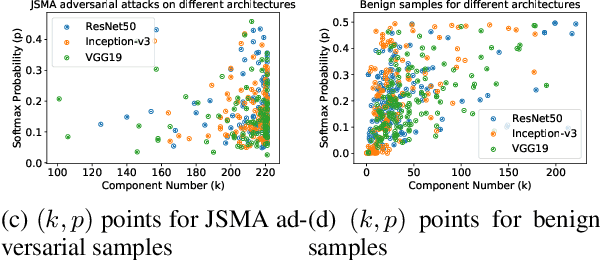
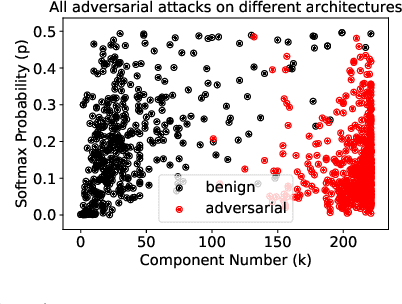
Deep Neural Networks for image classification have been found to be vulnerable to adversarial samples, which consist of sub-perceptual noise added to a benign image that can easily fool trained neural networks, posing a significant risk to their commercial deployment. In this work, we analyze adversarial samples through the lens of their contributions to the principal components of each image, which is different than prior works in which authors performed PCA on the entire dataset. We investigate a number of state-of-the-art deep neural networks trained on ImageNet as well as several attacks for each of the networks. Our results demonstrate empirically that adversarial samples across several attacks have similar properties in their contributions to the principal components of neural network inputs. We propose a new metric for neural networks to measure their robustness to adversarial samples, termed the (k,p) point. We utilize this metric to achieve 93.36% accuracy in detecting adversarial samples independent of architecture and attack type for models trained on ImageNet.
Black-Box Saliency Map Generation Using Bayesian Optimisation
Jan 30, 2020
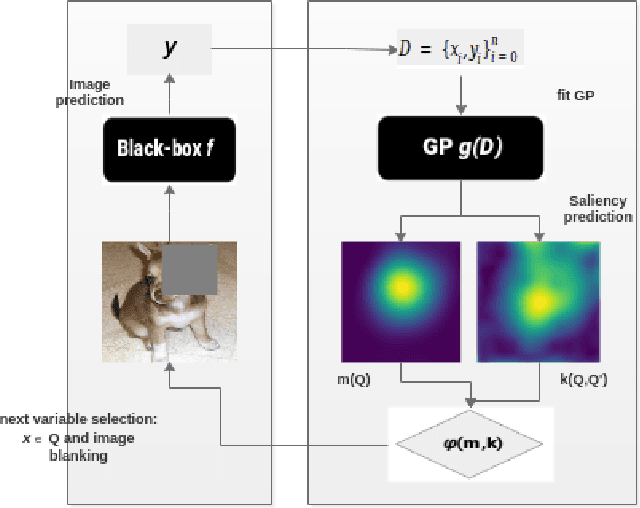
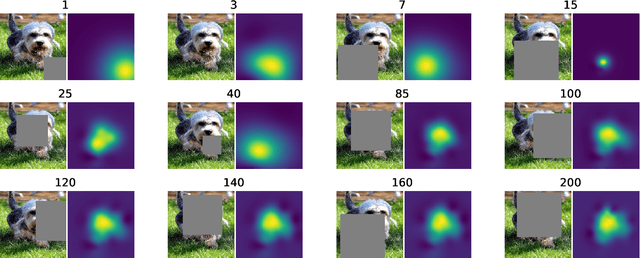
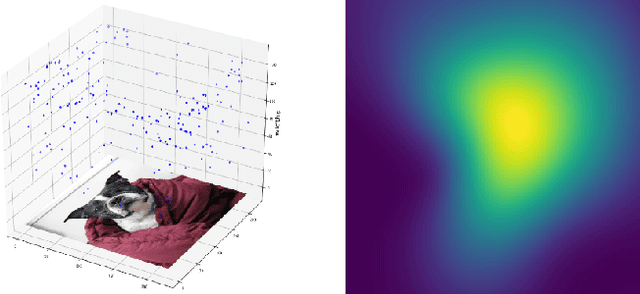
Saliency maps are often used in computer vision to provide intuitive interpretations of what input regions a model has used to produce a specific prediction. A number of approaches to saliency map generation are available, but most require access to model parameters. This work proposes an approach for saliency map generation for black-box models, where no access to model parameters is available, using a Bayesian optimisation sampling method. The approach aims to find the global salient image region responsible for a particular (black-box) model's prediction. This is achieved by a sampling-based approach to model perturbations that seeks to localise salient regions of an image to the black-box model. Results show that the proposed approach to saliency map generation outperforms grid-based perturbation approaches, and performs similarly to gradient-based approaches which require access to model parameters.
Copy and Paste GAN: Face Hallucination from Shaded Thumbnails
Mar 19, 2020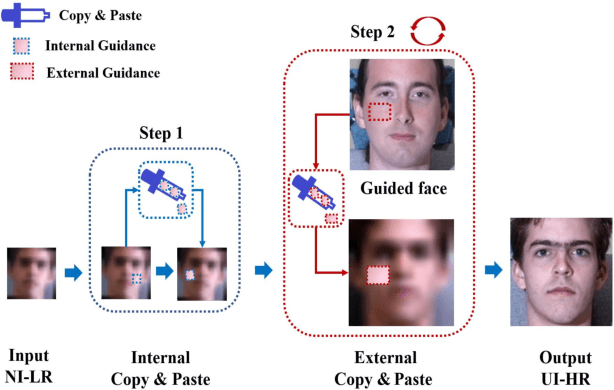
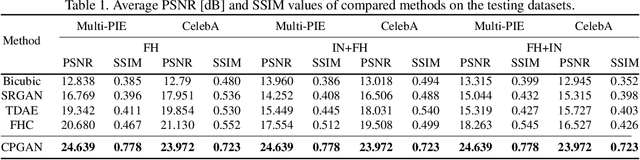

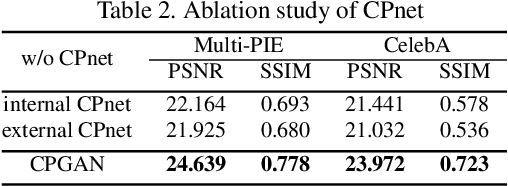
Existing face hallucination methods based on convolutional neural networks (CNN) have achieved impressive performance on low-resolution (LR) faces in a normal illumination condition. However, their performance degrades dramatically when LR faces are captured in low or non-uniform illumination conditions. This paper proposes a Copy and Paste Generative Adversarial Network (CPGAN) to recover authentic high-resolution (HR) face images while compensating for low and non-uniform illumination. To this end, we develop two key components in our CPGAN: internal and external Copy and Paste nets (CPnets). Specifically, our internal CPnet exploits facial information residing in the input image to enhance facial details; while our external CPnet leverages an external HR face for illumination compensation. A new illumination compensation loss is thus developed to capture illumination from the external guided face image effectively. Furthermore, our method offsets illumination and upsamples facial details alternately in a coarse-to-fine fashion, thus alleviating the correspondence ambiguity between LR inputs and external HR inputs. Extensive experiments demonstrate that our method manifests authentic HR face images in a uniform illumination condition and outperforms state-of-the-art methods qualitatively and quantitatively.
Double Backpropagation for Training Autoencoders against Adversarial Attack
Mar 04, 2020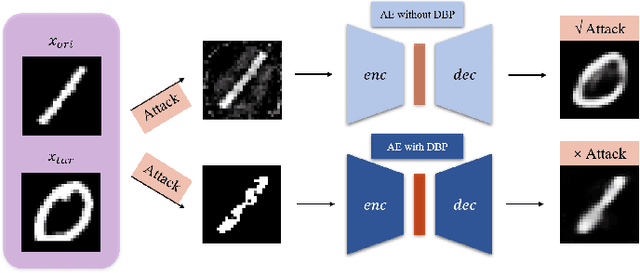

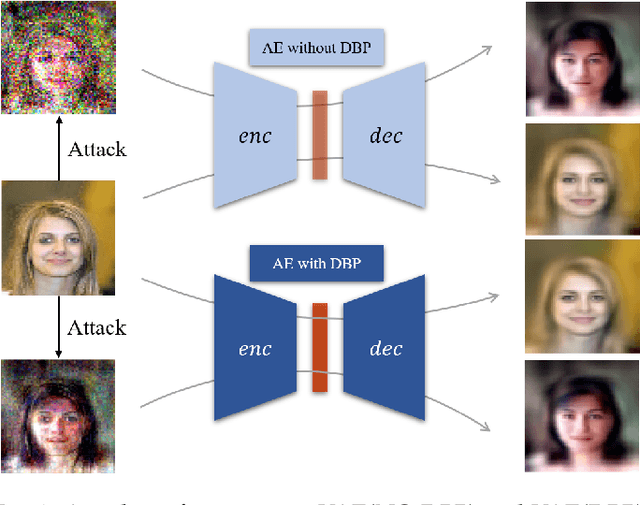

Deep learning, as widely known, is vulnerable to adversarial samples. This paper focuses on the adversarial attack on autoencoders. Safety of the autoencoders (AEs) is important because they are widely used as a compression scheme for data storage and transmission, however, the current autoencoders are easily attacked, i.e., one can slightly modify an input but has totally different codes. The vulnerability is rooted the sensitivity of the autoencoders and to enhance the robustness, we propose to adopt double backpropagation (DBP) to secure autoencoder such as VAE and DRAW. We restrict the gradient from the reconstruction image to the original one so that the autoencoder is not sensitive to trivial perturbation produced by the adversarial attack. After smoothing the gradient by DBP, we further smooth the label by Gaussian Mixture Model (GMM), aiming for accurate and robust classification. We demonstrate in MNIST, CelebA, SVHN that our method leads to a robust autoencoder resistant to attack and a robust classifier able for image transition and immune to adversarial attack if combined with GMM.
Bespoke vs. Prêt-à-Porter Lottery Tickets: Exploiting Mask Similarity for Trainable Sub-Network Finding
Jul 06, 2020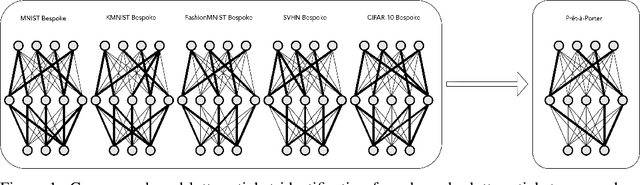
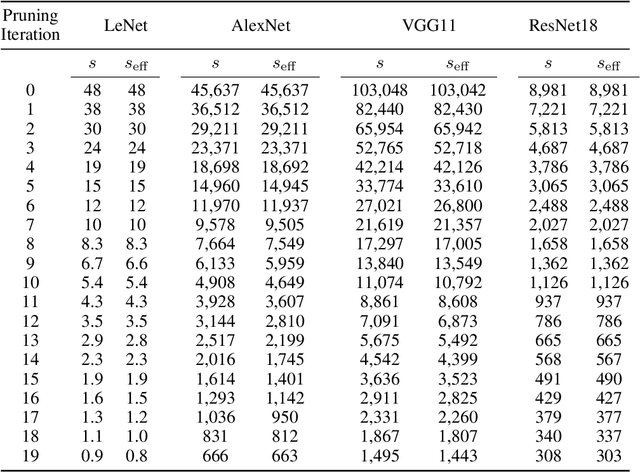
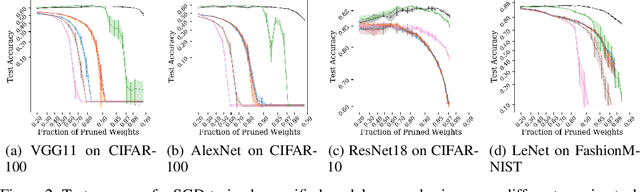
The observation of sparse trainable sub-networks within over-parametrized networks - also known as Lottery Tickets (LTs) - has prompted inquiries around their trainability, scaling, uniqueness, and generalization properties. Across 28 combinations of image classification tasks and architectures, we discover differences in the connectivity structure of LTs found through different iterative pruning techniques, thus disproving their uniqueness and connecting emergent mask structure to the choice of pruning. In addition, we propose a consensus-based method for generating refined lottery tickets. This lottery ticket denoising procedure, based on the principle that parameters that always go unpruned across different tasks more reliably identify important sub-networks, is capable of selecting a meaningful portion of the architecture in an embarrassingly parallel way, while quickly discarding extra parameters without the need for further pruning iterations. We successfully train these sub-networks to performance comparable to that of ordinary lottery tickets.