 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFace: Real-time Adversarial Attacks on Face Recognition Systems
Jun 09, 2022
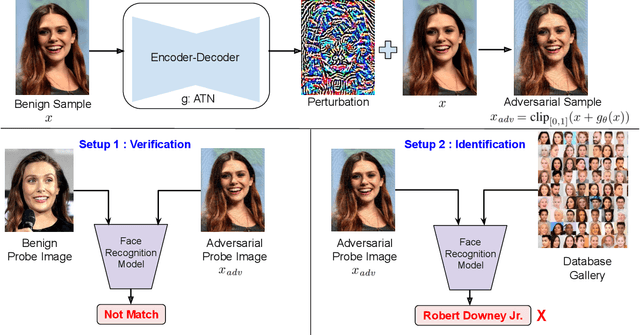
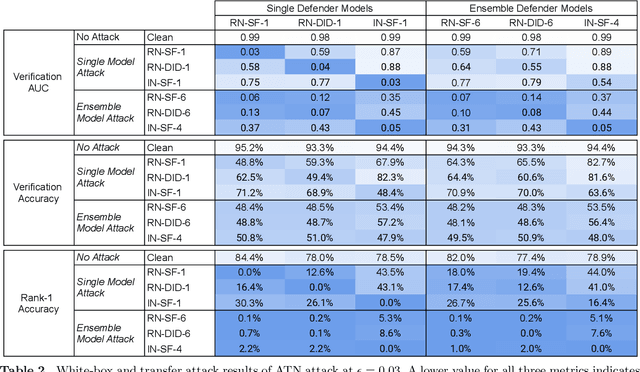
Deep neural network based face recognition models have been shown to be vulnerable to adversarial examples. However, many of the past attacks require the adversary to solve an input-dependent optimization problem using gradient descent which makes the attack impractical in real-time. These adversarial examples are also tightly coupled to the attacked model and are not as successful in transferring to different models. In this work, we propose ReFace, a real-time, highly-transferable attack on face recognition models based on Adversarial Transformation Networks (ATNs). ATNs model adversarial example generation as a feed-forward neural network. We find that the white-box attack success rate of a pure U-Net ATN falls substantially short of gradient-based attacks like PGD on large face recognition datasets. We therefore propose a new architecture for ATNs that closes this gap while maintaining a 10000x speedup over PGD. Furthermore, we find that at a given perturbation magnitude, our ATN adversarial perturbations are more effective in transferring to new face recognition models than PGD. ReFace attacks can successfully deceive commercial face recognition services in a transfer attack setting and reduce face identification accuracy from 82% to 16.4% for AWS SearchFaces API and Azure face verification accuracy from 91% to 50.1%.
Adversarial Scratches: Deployable Attacks to CNN Classifiers
Apr 20, 2022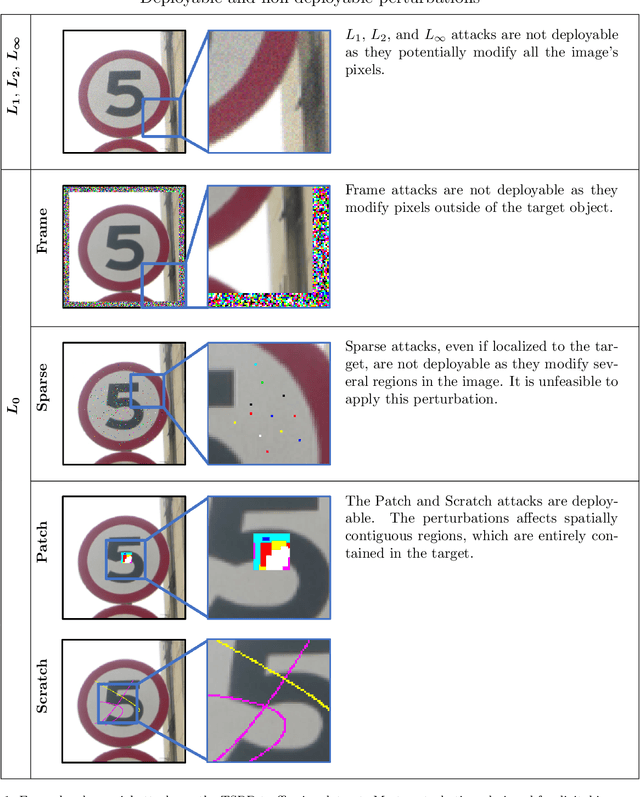
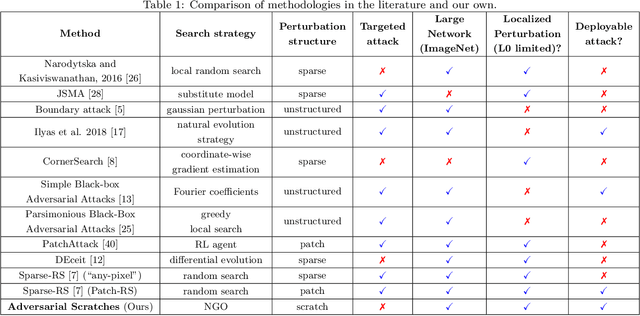


A growing body of work has shown that deep neural networks are susceptible to adversarial examples. These take the form of small perturbations applied to the model's input which lead to incorrect predictions. Unfortunately, most literature focuses on visually imperceivable perturbations to be applied to digital images that often are, by design, impossible to be deployed to physical targets. We present Adversarial Scratches: a novel L0 black-box attack, which takes the form of scratches in images, and which possesses much greater deployability than other state-of-the-art attacks. Adversarial Scratches leverage B\'ezier Curves to reduce the dimension of the search space and possibly constrain the attack to a specific location. We test Adversarial Scratches in several scenarios, including a publicly available API and images of traffic signs. Results show that, often, our attack achieves higher fooling rate than other deployable state-of-the-art methods, while requiring significantly fewer queries and modifying very few pixels.
A Singular Value Perspective on Model Robustness
Dec 07, 2020
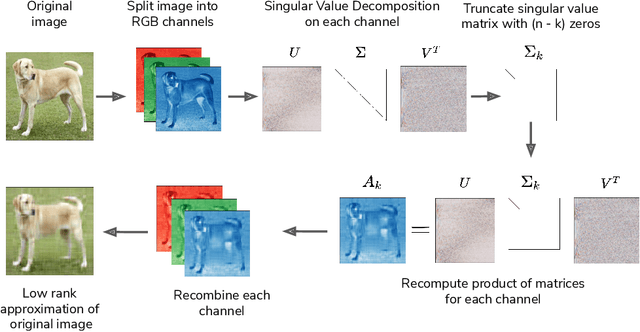
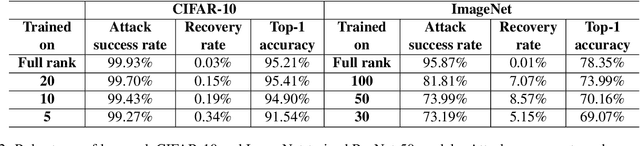
Convolutional Neural Networks (CNNs) have made significant progress on several computer vision benchmarks, but are fraught with numerous non-human biases such as vulnerability to adversarial samples. Their lack of explainability makes identification and rectification of these biases difficult, and understanding their generalization behavior remains an open problem. In this work we explore the relationship between the generalization behavior of CNNs and the Singular Value Decomposition (SVD) of images. We show that naturally trained and adversarially robust CNNs exploit highly different features for the same dataset. We demonstrate that these features can be disentangled by SVD for ImageNet and CIFAR-10 trained networks. Finally, we propose Rank Integrated Gradients (RIG), the first rank-based feature attribution method to understand the dependence of CNNs on image rank.
Adversarial Deepfakes: Evaluating Vulnerability of Deepfake Detectors to Adversarial Examples
Mar 14, 2020
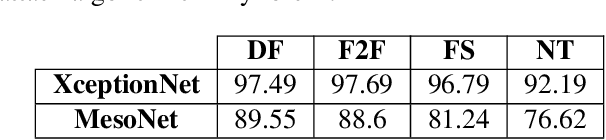
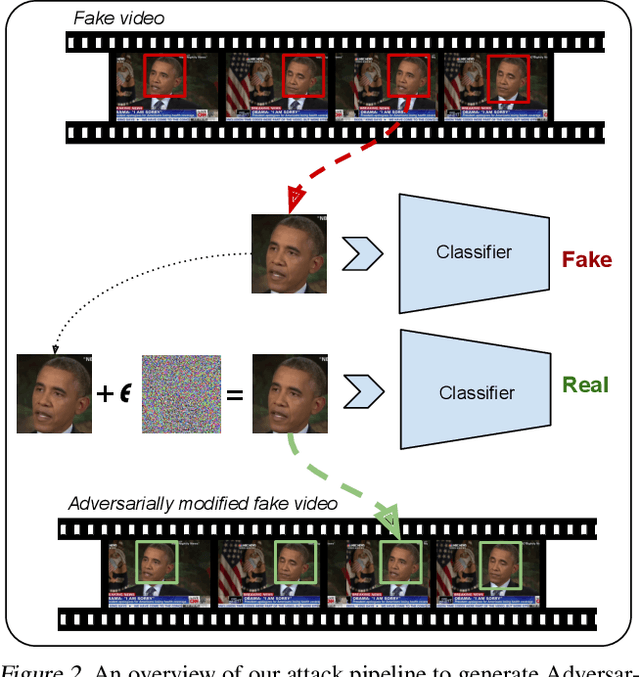
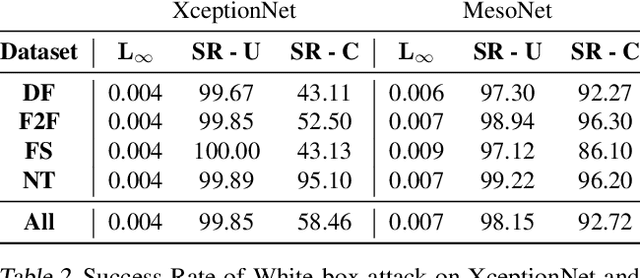
Recent advances in video manipulation techniques have made the generation of fake videos more accessible than ever before. Manipulated videos can fuel disinformation and reduce trust in media. Therefore detection of fake videos has garnered immense interest in academia and industry. Recently developed Deepfake detection methods rely on deep neural networks (DNNs) to distinguish AI-generated fake videos from real videos. In this work, we demonstrate that it is possible to bypass such detectors by adversarially modifying fake videos synthesized using existing Deepfake generation methods. We further demonstrate that our adversarial perturbations are robust to image and video compression codecs, making them a real-world threat. We present pipelines in both white-box and black-box attack scenarios that can fool DNN based Deepfake detectors into classifying fake videos as real.
Principal Component Properties of Adversarial Samples
Dec 07, 2019
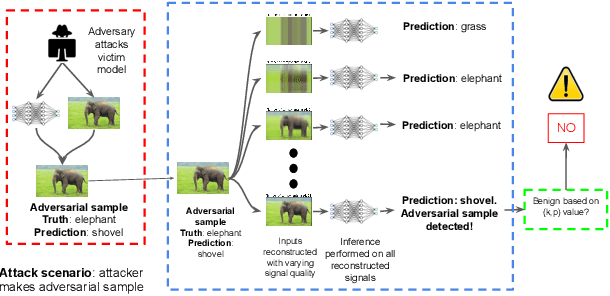
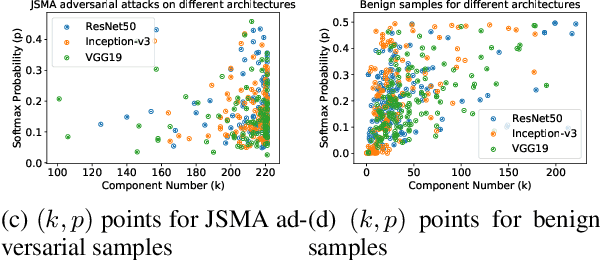
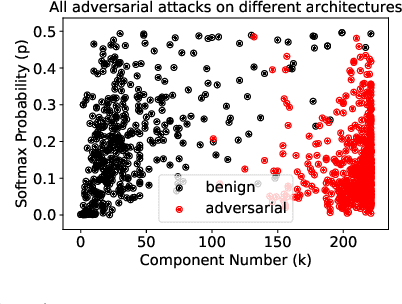
Deep Neural Networks for image classification have been found to be vulnerable to adversarial samples, which consist of sub-perceptual noise added to a benign image that can easily fool trained neural networks, posing a significant risk to their commercial deployment. In this work, we analyze adversarial samples through the lens of their contributions to the principal components of each image, which is different than prior works in which authors performed PCA on the entire dataset. We investigate a number of state-of-the-art deep neural networks trained on ImageNet as well as several attacks for each of the networks. Our results demonstrate empirically that adversarial samples across several attacks have similar properties in their contributions to the principal components of neural network inputs. We propose a new metric for neural networks to measure their robustness to adversarial samples, termed the (k,p) point. We utilize this metric to achieve 93.36% accuracy in detecting adversarial samples independent of architecture and attack type for models trained on ImageNet.
Scratch that! An Evolution-based Adversarial Attack against Neural Networks
Dec 05, 2019
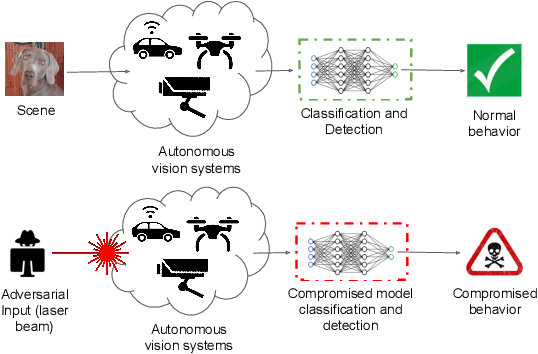
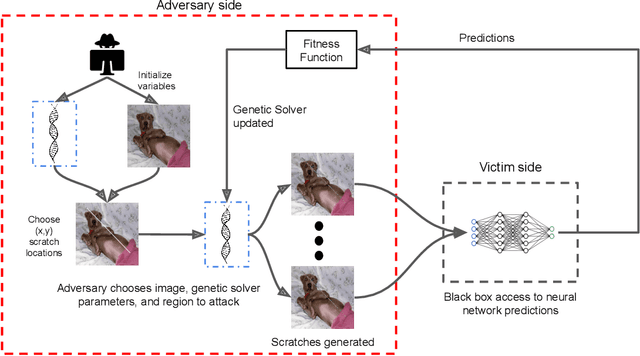
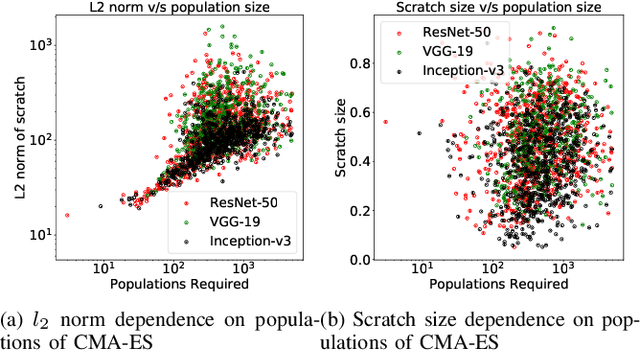
Recent research has shown that Deep Neural Networks (DNNs) for image classification are vulnerable to adversarial attacks. However, most works on adversarial samples utilize sub-perceptual noise that, while invisible or slightly visible to humans, often covers the entire image. Additionally, most of these attacks often require knowledge of the neural network architecture and its parameters, and the ability to calculate the gradients of the parameters with respect to the inputs. In this work, we show that it is possible to attack neural networks in a highly restricted threat setting, where attackers have no knowledge of the neural network (i.e., in a black-box setting) and can only modify highly localized adversarial noise in the form of randomly chosen straight lines or scratches. Our Adversarial Scratches attack method covers only 1-2% of the image pixels and are generated using the Covariance Matrix Adaptation Evolutionary Strategy, a purely black-box method that does not require knowledge of the neural network architecture and its gradients. Against ImageNet models, Adversarial Scratches requires 3 times fewer queries than GenAttack (without any optimizations) and 73 times fewer queries than ZOO, both prior state-of-the-art black-box attacks. We successfully deceive state-of-the-art Inception-v3, ResNet-50 and VGG-19 models trained on ImageNet with deceiving rates of 75.8%, 62.7%, and 45% respectively, with fewer queries than several state-of-the-art black-box attacks, while modifying less than 2% of the image pixels. Additionally, we provide a new threat scenario for neural networks, demonstrate a new attack surface that can be used to perform adversarial attacks, and discuss its potential implications.