 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ACD: Action Concept Discovery from Image-Sentence Corpora
Apr 16, 2016

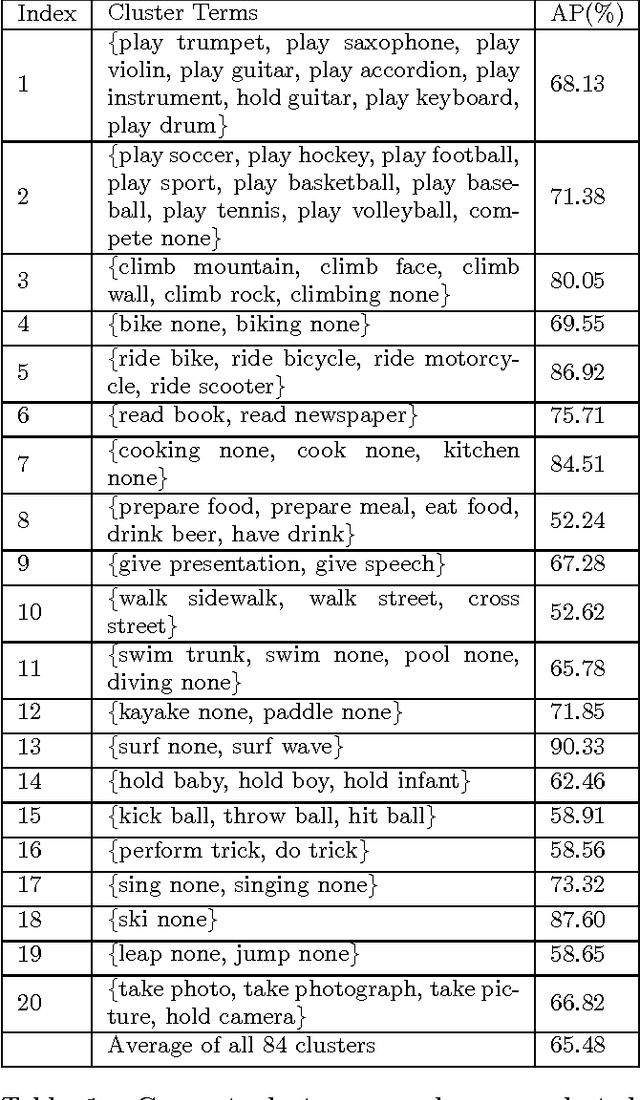
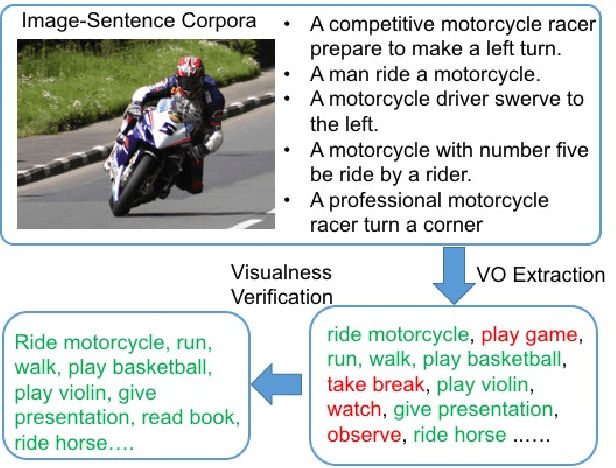

Action classification in still images is an important task in computer vision. It is challenging as the appearances of ac- tions may vary depending on their context (e.g. associated objects). Manually labeling of context information would be time consuming and difficult to scale up. To address this challenge, we propose a method to automatically discover and cluster action concepts, and learn their classifiers from weakly supervised image-sentence corpora. It obtains candidate action concepts by extracting verb-object pairs from sentences and verifies their visualness with the associated images. Candidate action concepts are then clustered by using a multi-modal representation with image embeddings from deep convolutional networks and text embeddings from word2vec. More than one hundred human action concept classifiers are learned from the Flickr 30k dataset with no additional human effort and promising classification results are obtained. We further apply the AdaBoost algorithm to automatically select and combine relevant action concepts given an action query. Promising results have been shown on the PASCAL VOC 2012 action classification benchmark, which has zero overlap with Flickr30k.
Contrastive Explanations in Neural Networks
Aug 01, 2020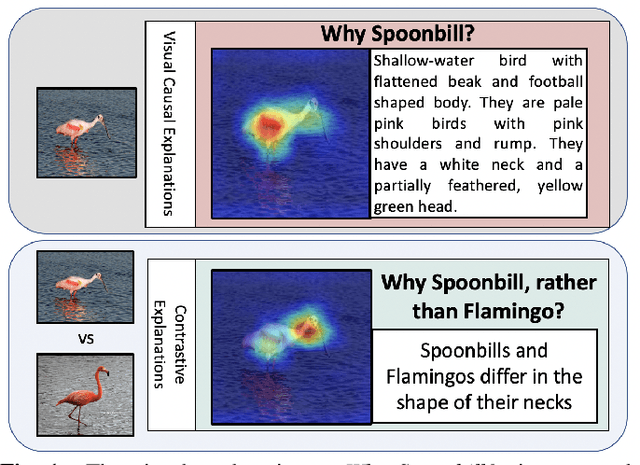
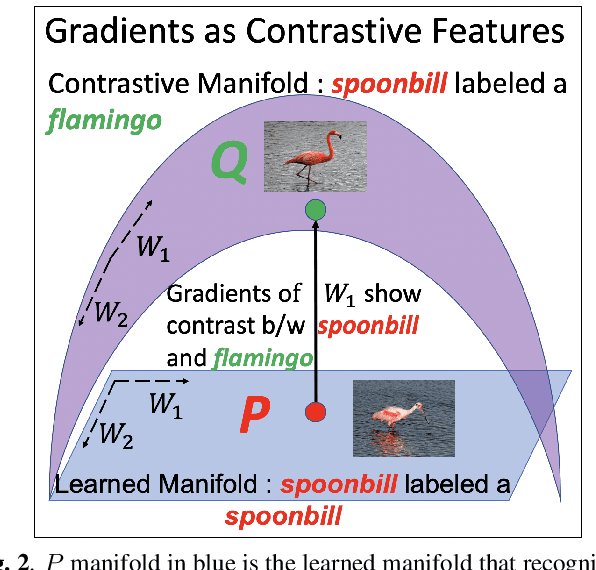
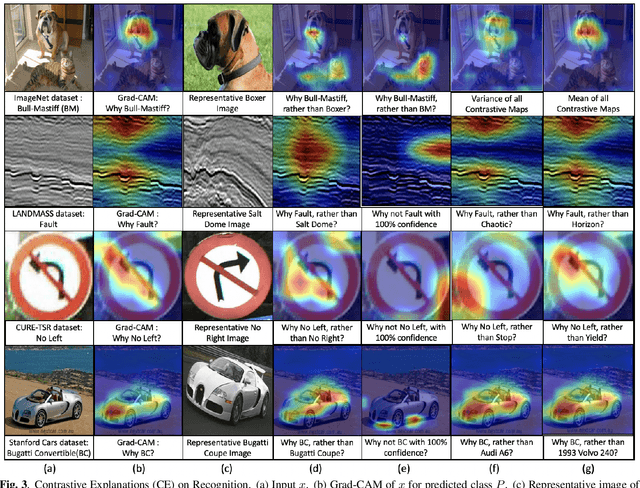

Visual explanations are logical arguments based on visual features that justify the predictions made by neural networks. Current modes of visual explanations answer questions of the form $`Why \text{ } P?'$. These $Why$ questions operate under broad contexts thereby providing answers that are irrelevant in some cases. We propose to constrain these $Why$ questions based on some context $Q$ so that our explanations answer contrastive questions of the form $`Why \text{ } P, \text{} rather \text{ } than \text{ } Q?'$. In this paper, we formalize the structure of contrastive visual explanations for neural networks. We define contrast based on neural networks and propose a methodology to extract defined contrasts. We then use the extracted contrasts as a plug-in on top of existing $`Why \text{ } P?'$ techniques, specifically Grad-CAM. We demonstrate their value in analyzing both networks and data in applications of large-scale recognition, fine-grained recognition, subsurface seismic analysis, and image quality assessment.
Fidelity-Naturalness Evaluation of Single Image Super Resolution
Nov 21, 2015
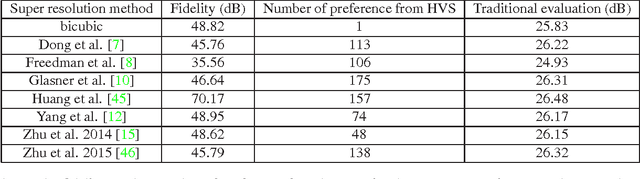


We study the problem of evaluating super resolution methods. Traditional evaluation methods usually judge the quality of super resolved images based on a single measure of their difference with the original high resolution images. In this paper, we proposed to use both fidelity (the difference with original images) and naturalness (human visual perception of super resolved images) for evaluation. For fidelity evaluation, a new metric is proposed to solve the bias problem of traditional evaluation. For naturalness evaluation, we let humans label preference of super resolution results using pair-wise comparison, and test the correlation between human labeling results and image quality assessment metrics' outputs. Experimental results show that our fidelity-naturalness method is better than the traditional evaluation method for super resolution methods, which could help future research on single-image super resolution.
FA-GANs: Facial Attractiveness Enhancement with Generative Adversarial Networks on Frontal Faces
May 17, 2020
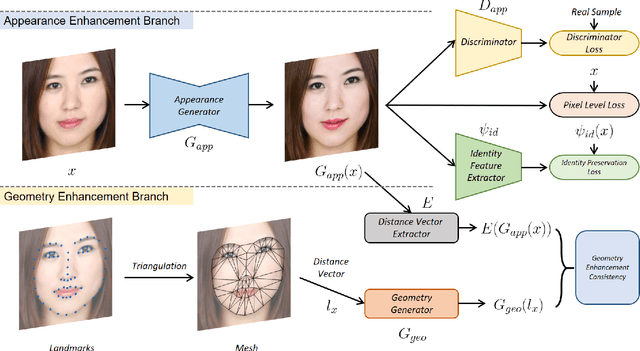


Facial attractiveness enhancement has been an interesting application in Computer Vision and Graphics over these years. It aims to generate a more attractive face via manipulations on image and geometry structure while preserving face identity. In this paper, we propose the first Generative Adversarial Networks (GANs) for enhancing facial attractiveness in both geometry and appearance aspects, which we call "FA-GANs". FA-GANs contain two branches and enhance facial attractiveness in two perspectives: facial geometry and facial appearance. Each branch consists of individual GANs with the appearance branch adjusting the facial image and the geometry branch adjusting the facial landmarks in appearance and geometry aspects, respectively. Unlike the traditional facial manipulations learning from paired faces, which are infeasible to collect before and after enhancement of the same individual, we achieve this by learning the features of attractiveness faces through unsupervised adversarial learning. The proposed FA-GANs are able to extract attractiveness features and impose them on the enhancement results. To better enhance faces, both the geometry and appearance networks are considered to refine the facial attractiveness by adjusting the geometry layout of faces and the appearance of faces independently. To the best of our knowledge, we are the first to enhance the facial attractiveness with GANs in both geometry and appearance aspects. The experimental results suggest that our FA-GANs can generate compelling perceptual results in both geometry structure and facial appearance and outperform current state-of-the-art methods.
Assessing the validity of saliency maps for abnormality localization in medical imaging
May 29, 2020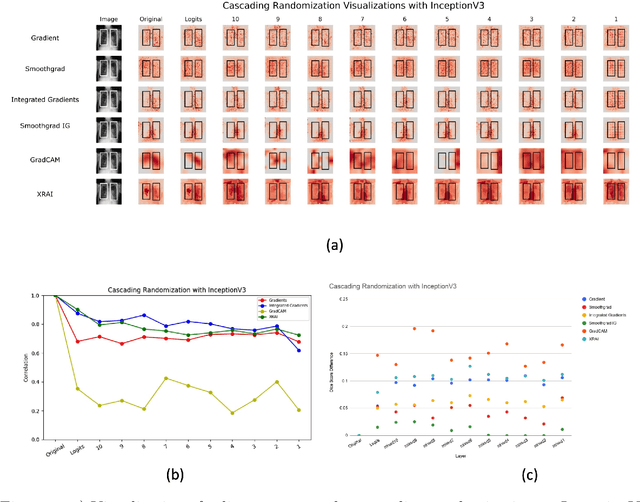
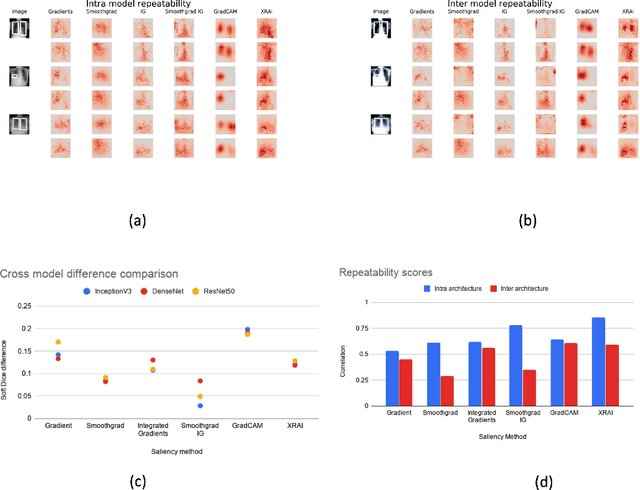
Saliency maps have become a widely used method to assess which areas of the input image are most pertinent to the prediction of a trained neural network. However, in the context of medical imaging, there is no study to our knowledge that has examined the efficacy of these techniques and quantified them using overlap with ground truth bounding boxes. In this work, we explored the credibility of the various existing saliency map methods on the RSNA Pneumonia dataset. We found that GradCAM was the most sensitive to model parameter and label randomization, and was highly agnostic to model architecture.
Same Same But DifferNet: Semi-Supervised Defect Detection with Normalizing Flows
Aug 28, 2020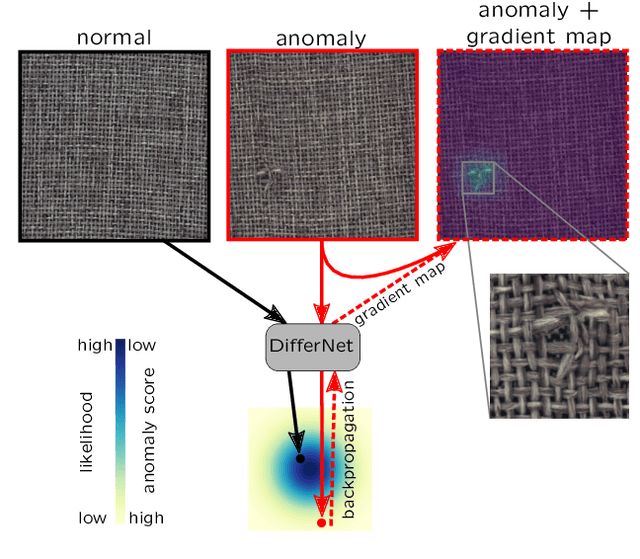
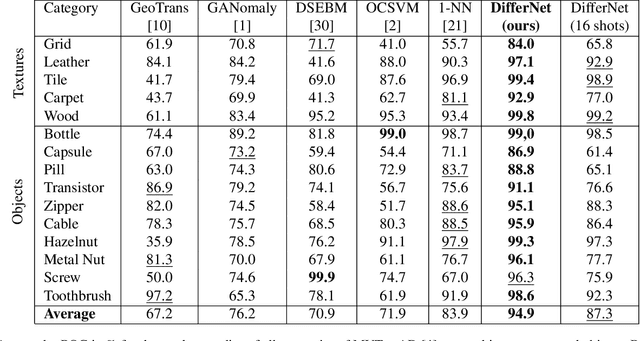

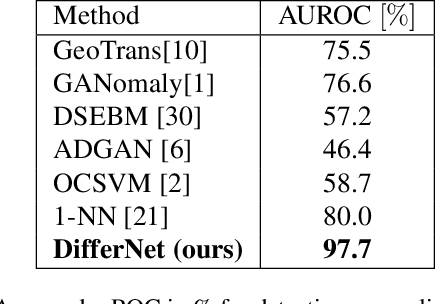
The detection of manufacturing errors is crucial in fabrication processes to ensure product quality and safety standards. Since many defects occur very rarely and their characteristics are mostly unknown a priori, their detection is still an open research question. To this end, we propose DifferNet: It leverages the descriptiveness of features extracted by convolutional neural networks to estimate their density using normalizing flows. Normalizing flows are well-suited to deal with low dimensional data distributions. However, they struggle with the high dimensionality of images. Therefore, we employ a multi-scale feature extractor which enables the normalizing flow to assign meaningful likelihoods to the images. Based on these likelihoods we develop a scoring function that indicates defects. Moreover, propagating the score back to the image enables pixel-wise localization. To achieve a high robustness and performance we exploit multiple transformations in training and evaluation. In contrast to most other methods, ours does not require a large number of training samples and performs well with as low as 16 images. We demonstrate the superior performance over existing approaches on the challenging and newly proposed MVTec AD and Magnetic Tile Defects datasets.
Approximately Optimal Binning for the Piecewise Constant Approximation of the Normalized Unexplained Variance (nUV) Dissimilarity Measure
Jul 24, 2020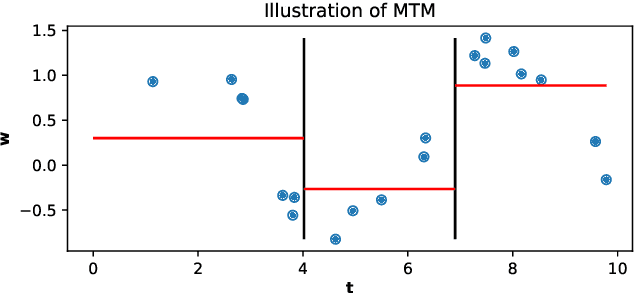
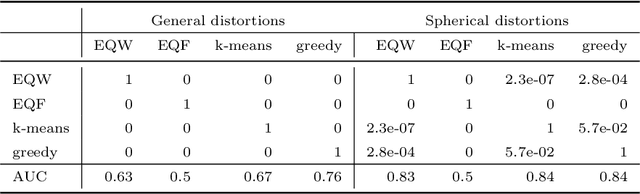
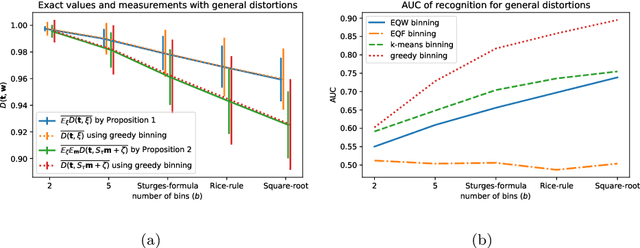
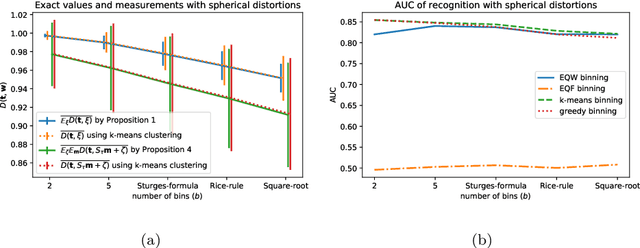
The recently introduced Matching by Tone Mapping (MTM) dissimilarity measure enables template matching under smooth non-linear distortions and also has a well-established mathematical background. MTM operates by binning the template, but the ideal binning for a particular problem is an open question. By pointing out an important analogy between the well known mutual information (MI) and MTM, we introduce the term "normalized unexplained variance" (nUV) for MTM to emphasize its relevance and applicability beyond image processing. Then, we provide theoretical results on the optimal binning technique for the nUV measure and propose algorithms to find approximate solutions. The theoretical findings are supported by numerical experiments. Using the proposed techniques for binning shows 4-13% increase in terms of AUC scores with statistical significance, enabling us to conclude that the proposed binning techniques have the potential to improve the performance of the nUV measure in real applications.
Enforcing Perceptual Consistency on Generative Adversarial Networks by Using the Normalised Laplacian Pyramid Distance
Aug 09, 2019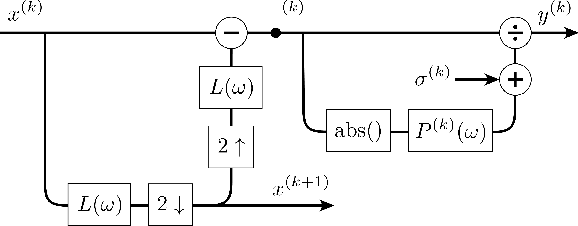
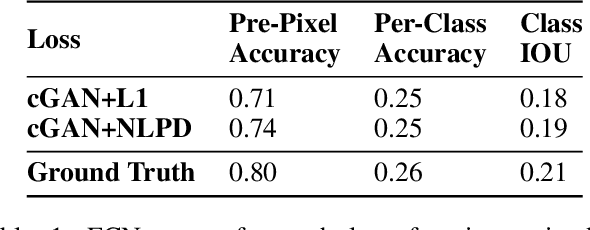
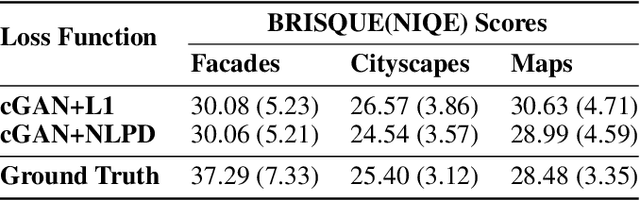

In recent years there has been a growing interest in image generation through deep learning. While an important part of the evaluation of the generated images usually involves visual inspection, the inclusion of human perception as a factor in the training process is often overlooked. In this paper we propose an alternative perceptual regulariser for image-to-image translation using conditional generative adversarial networks (cGANs). To do so automatically (avoiding visual inspection), we use the Normalised Laplacian Pyramid Distance (NLPD) to measure the perceptual similarity between the generated image and the original image. The NLPD is based on the principle of normalising the value of coefficients with respect to a local estimate of mean energy at different scales and has already been successfully tested in different experiments involving human perception. We compare this regulariser with the originally proposed L1 distance and note that when using NLPD the generated images contain more realistic values for both local and global contrast. We found that using NLPD as a regulariser improves image segmentation accuracy on generated images as well as improving two no-reference image quality metrics.
Light Stage Super-Resolution: Continuous High-Frequency Relighting
Oct 17, 2020
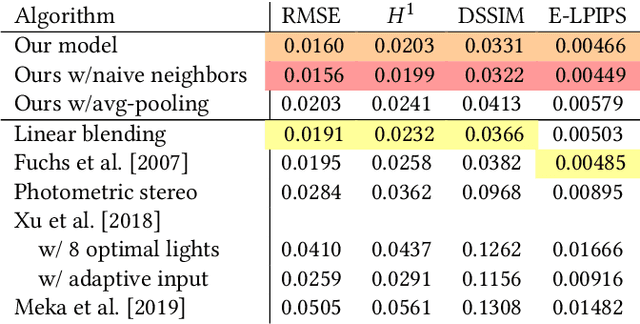
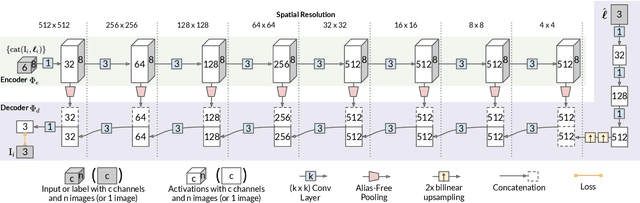
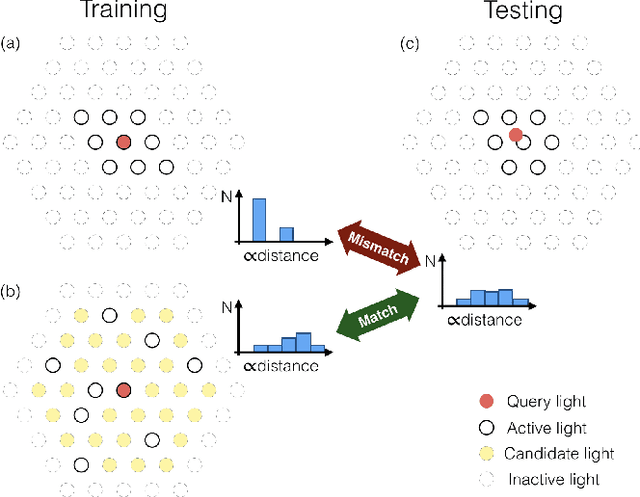
The light stage has been widely used in computer graphics for the past two decades, primarily to enable the relighting of human faces. By capturing the appearance of the human subject under different light sources, one obtains the light transport matrix of that subject, which enables image-based relighting in novel environments. However, due to the finite number of lights in the stage, the light transport matrix only represents a sparse sampling on the entire sphere. As a consequence, relighting the subject with a point light or a directional source that does not coincide exactly with one of the lights in the stage requires interpolation and resampling the images corresponding to nearby lights, and this leads to ghosting shadows, aliased specularities, and other artifacts. To ameliorate these artifacts and produce better results under arbitrary high-frequency lighting, this paper proposes a learning-based solution for the "super-resolution" of scans of human faces taken from a light stage. Given an arbitrary "query" light direction, our method aggregates the captured images corresponding to neighboring lights in the stage, and uses a neural network to synthesize a rendering of the face that appears to be illuminated by a "virtual" light source at the query location. This neural network must circumvent the inherent aliasing and regularity of the light stage data that was used for training, which we accomplish through the use of regularized traditional interpolation methods within our network. Our learned model is able to produce renderings for arbitrary light directions that exhibit realistic shadows and specular highlights, and is able to generalize across a wide variety of subjects.
Cityscapes-Panoptic-Parts and PASCAL-Panoptic-Parts datasets for Scene Understanding
Apr 16, 2020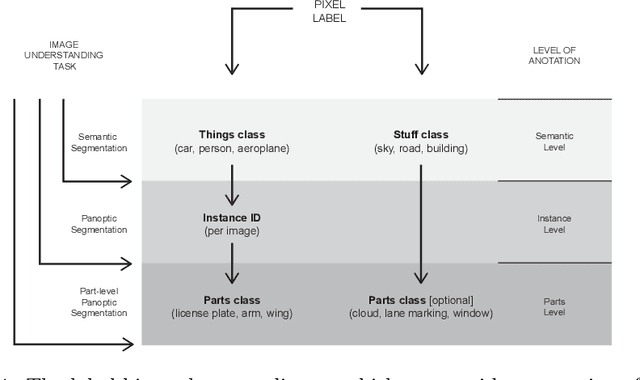
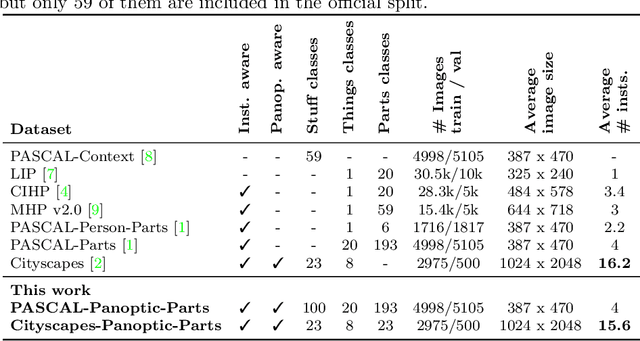

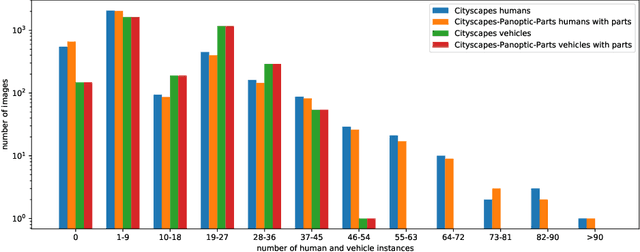
In this technical report, we present two novel datasets for image scene understanding. Both datasets have annotations compatible with panoptic segmentation and additionally they have part-level labels for selected semantic classes. This report describes the format of the two datasets, the annotation protocols, the merging strategies, and presents the datasets statistics. The datasets labels together with code for processing and visualization will be published at https://github.com/tue-mps/panoptic_parts.