 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Blood Glucose Control: Offline Reinforcement Learning from Human Feedback
Jan 27, 2025



Reinforcement learning (RL) has demonstrated success in automating insulin dosing in simulated type 1 diabetes (T1D) patients but is currently unable to incorporate patient expertise and preference. This work introduces PAINT (Preference Adaptation for INsulin control in T1D), an original RL framework for learning flexible insulin dosing policies from patient records. PAINT employs a sketch-based approach for reward learning, where past data is annotated with a continuous reward signal to reflect patient's desired outcomes. Labelled data trains a reward model, informing the actions of a novel safety-constrained offline RL algorithm, designed to restrict actions to a safe strategy and enable preference tuning via a sliding scale. In-silico evaluation shows PAINT achieves common glucose goals through simple labelling of desired states, reducing glycaemic risk by 15% over a commercial benchmark. Action labelling can also be used to incorporate patient expertise, demonstrating an ability to pre-empt meals (+10% time-in-range post-meal) and address certain device errors (-1.6% variance post-error) with patient guidance. These results hold under realistic conditions, including limited samples, labelling errors, and intra-patient variability. This work illustrates PAINT's potential in real-world T1D management and more broadly any tasks requiring rapid and precise preference learning under safety constraints.
Lightweight Decentralized Neural Network-Based Strategies for Multi-Robot Patrolling
Dec 16, 2024



The problem of decentralized multi-robot patrol has previously been approached primarily with hand-designed strategies for minimization of 'idlenes' over the vertices of a graph-structured environment. Here we present two lightweight neural network-based strategies to tackle this problem, and show that they significantly outperform existing strategies in both idleness minimization and against an intelligent intruder model, as well as presenting an examination of robustness to communication failure. Our results also indicate important considerations for future strategy design.
Transfer Learning of RSSI to Improve Indoor Localisation Performance
Dec 12, 2024



With the growing demand for health monitoring systems, in-home localisation is essential for tracking patient conditions. The unique spatial characteristics of each house required annotated data for Bluetooth Low Energy (BLE) Received Signal Strength Indicator (RSSI)-based monitoring system. However, collecting annotated training data is time-consuming, particularly for patients with limited health conditions. To address this, we propose Conditional Generative Adversarial Networks (ConGAN)-based augmentation, combined with our transfer learning framework (T-ConGAN), to enable the transfer of generic RSSI information between different homes, even when data is collected using different experimental protocols. This enhances the performance and scalability of such intelligent systems by reducing the need for annotation in each home. We are the first to demonstrate that BLE RSSI data can be shared across different homes, and that shared information can improve the indoor localisation performance. Our T-ConGAN enhances the macro F1 score of room-level indoor localisation by up to 12.2%, with a remarkable 51% improvement in challenging areas such as stairways or outside spaces. This state-of-the-art RSSI augmentation model significantly enhances the robustness of in-home health monitoring systems.
Optimising TinyML with Quantization and Distillation of Transformer and Mamba Models for Indoor Localisation on Edge Devices
Dec 12, 2024This paper proposes small and efficient machine learning models (TinyML) for resource-constrained edge devices, specifically for on-device indoor localisation. Typical approaches for indoor localisation rely on centralised remote processing of data transmitted from lower powered devices such as wearables. However, there are several benefits for moving this to the edge device itself, including increased battery life, enhanced privacy, reduced latency and lowered operational costs, all of which are key for common applications such as health monitoring. The work focuses on model compression techniques, including quantization and knowledge distillation, to significantly reduce the model size while maintaining high predictive performance. We base our work on a large state-of-the-art transformer-based model and seek to deploy it within low-power MCUs. We also propose a state-space-based architecture using Mamba as a more compact alternative to the transformer. Our results show that the quantized transformer model performs well within a 64 KB RAM constraint, achieving an effective balance between model size and localisation precision. Additionally, the compact Mamba model has strong performance under even tighter constraints, such as a 32 KB of RAM, without the need for model compression, making it a viable option for more resource-limited environments. We demonstrate that, through our framework, it is feasible to deploy advanced indoor localisation models onto low-power MCUs with restricted memory limitations. The application of these TinyML models in healthcare has the potential to revolutionize patient monitoring by providing accurate, real-time location data while minimizing power consumption, increasing data privacy, improving latency and reducing infrastructure costs.
Unsupervised Optimisation of GNNs for Node Clustering
Feb 20, 2024Graph Neural Networks (GNNs) can be trained to detect communities within a graph by learning from the duality of feature and connectivity information. Currently, the common approach for optimisation of GNNs is to use comparisons to ground-truth for hyperparameter tuning and model selection. In this work, we show that nodes can be clustered into communities with GNNs by solely optimising for modularity, without any comparison to ground-truth. Although modularity is a graph partitioning quality metric, we show that this can be used to optimise GNNs that also encode features without a drop in performance. We take it a step further and also study whether the unsupervised metric performance can predict ground-truth performance. To investigate why modularity can be used to optimise GNNs, we design synthetic experiments that show the limitations of this approach. The synthetic graphs are created to highlight current capabilities in distinct, random and zero information space partitions in attributed graphs. We conclude that modularity can be used for hyperparameter optimisation and model selection on real-world datasets as well as being a suitable proxy for predicting ground-truth performance, however, GNNs fail to balance the information duality when the spaces contain conflicting signals.
Uncertainty in GNN Learning Evaluations: A Comparison Between Measures for Quantifying Randomness in GNN Community Detection
Jan 04, 2024(1) The enhanced capability of Graph Neural Networks (GNNs) in unsupervised community detection of clustered nodes is attributed to their capacity to encode both the connectivity and feature information spaces of graphs. The identification of latent communities holds practical significance in various domains, from social networks to genomics. Current real-world performance benchmarks are perplexing due to the multitude of decisions influencing GNN evaluations for this task. (2) Three metrics are compared to assess the consistency of algorithm rankings in the presence of randomness. The consistency and quality of performance between the results under a hyperparameter optimisation with the default hyperparameters is evaluated. (3) The results compare hyperparameter optimisation with default hyperparameters, revealing a significant performance loss when neglecting hyperparameter investigation. A comparison of metrics indicates that ties in ranks can substantially alter the quantification of randomness. (4) Ensuring adherence to the same evaluation criteria may result in notable differences in the reported performance of methods for this task. The $W$ Randomness coefficient, based on the Wasserstein distance, is identified as providing the most robust assessment of randomness.
A Framework for Exploring Federated Community Detection
Dec 14, 2023


Federated Learning is machine learning in the context of a network of clients whilst maintaining data residency and/or privacy constraints. Community detection is the unsupervised discovery of clusters of nodes within graph-structured data. The intersection of these two fields uncovers much opportunity, but also challenge. For example, it adds complexity due to missing connectivity information between privately held graphs. In this work, we explore the potential of federated community detection by conducting initial experiments across a range of existing datasets that showcase the gap in performance introduced by the distributed data. We demonstrate that isolated models would benefit from collaboration establishing a framework for investigating challenges within this domain. The intricacies of these research frontiers are discussed alongside proposed solutions to these issues.
The Safety Challenges of Deep Learning in Real-World Type 1 Diabetes Management
Oct 23, 2023



Blood glucose simulation allows the effectiveness of type 1 diabetes (T1D) management strategies to be evaluated without patient harm. Deep learning algorithms provide a promising avenue for extending simulator capabilities; however, these algorithms are limited in that they do not necessarily learn physiologically correct glucose dynamics and can learn incorrect and potentially dangerous relationships from confounders in training data. This is likely to be more important in real-world scenarios, as data is not collected under strict research protocol. This work explores the implications of using deep learning algorithms trained on real-world data to model glucose dynamics. Free-living data was processed from the OpenAPS Data Commons and supplemented with patient-reported tags of challenging diabetes events, constituting one of the most detailed real-world T1D datasets. This dataset was used to train and evaluate state-of-the-art glucose simulators, comparing their prediction error across safety critical scenarios and assessing the physiological appropriateness of the learned dynamics using Shapley Additive Explanations (SHAP). While deep learning prediction accuracy surpassed the widely-used mathematical simulator approach, the model deteriorated in safety critical scenarios and struggled to leverage self-reported meal and exercise information. SHAP value analysis also indicated the model had fundamentally confused the roles of insulin and carbohydrates, which is one of the most basic T1D management principles. This work highlights the importance of considering physiological appropriateness when using deep learning to model real-world systems in T1D and healthcare more broadly, and provides recommendations for building models that are robust to real-world data constraints.
Multimodal Indoor Localisation in Parkinson's Disease for Detecting Medication Use: Observational Pilot Study in a Free-Living Setting
Aug 03, 2023
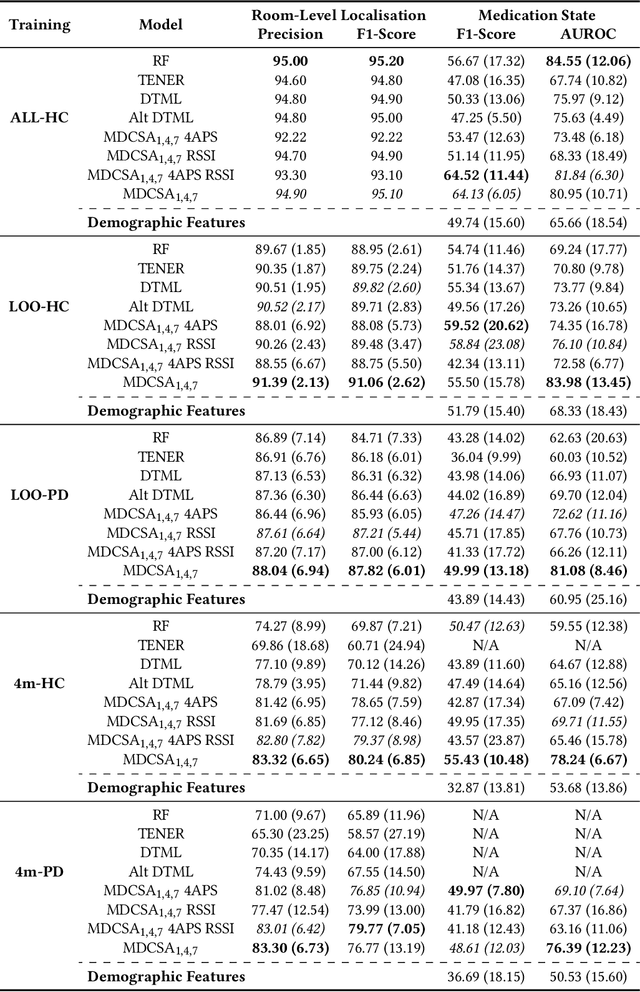
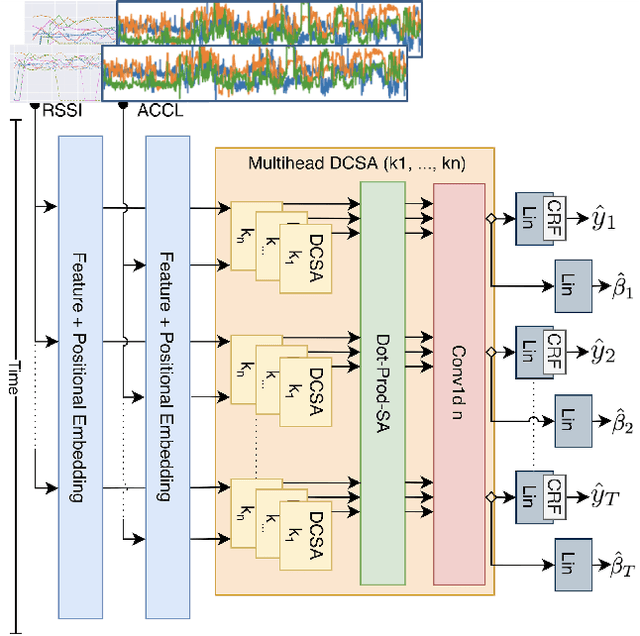
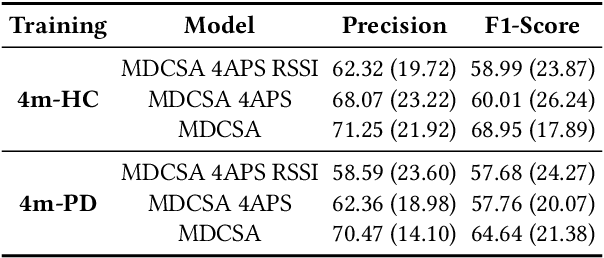
Parkinson's disease (PD) is a slowly progressive, debilitating neurodegenerative disease which causes motor symptoms including gait dysfunction. Motor fluctuations are alterations between periods with a positive response to levodopa therapy ("on") and periods marked by re-emergency of PD symptoms ("off") as the response to medication wears off. These fluctuations often affect gait speed and they increase in their disabling impact as PD progresses. To improve the effectiveness of current indoor localisation methods, a transformer-based approach utilising dual modalities which provide complementary views of movement, Received Signal Strength Indicator (RSSI) and accelerometer data from wearable devices, is proposed. A sub-objective aims to evaluate whether indoor localisation, including its in-home gait speed features (i.e. the time taken to walk between rooms), could be used to evaluate motor fluctuations by detecting whether the person with PD is taking levodopa medications or withholding them. To properly evaluate our proposed method, we use a free-living dataset where the movements and mobility are greatly varied and unstructured as expected in real-world conditions. 24 participants lived in pairs (consisting of one person with PD, one control) for five days in a smart home with various sensors. Our evaluation on the resulting dataset demonstrates that our proposed network outperforms other methods for indoor localisation. The sub-objective evaluation shows that precise room-level localisation predictions, transformed into in-home gait speed features, produce accurate predictions on whether the PD participant is taking or withholding their medications.
* 11 pages, 4 figures, 4 tables
Privacy in Multimodal Federated Human Activity Recognition
May 20, 2023



Human Activity Recognition (HAR) training data is often privacy-sensitive or held by non-cooperative entities. Federated Learning (FL) addresses such concerns by training ML models on edge clients. This work studies the impact of privacy in federated HAR at a user, environment, and sensor level. We show that the performance of FL for HAR depends on the assumed privacy level of the FL system and primarily upon the colocation of data from different sensors. By avoiding data sharing and assuming privacy at the human or environment level, as prior works have done, the accuracy decreases by 5-7%. However, extending this to the modality level and strictly separating sensor data between multiple clients may decrease the accuracy by 19-42%. As this form of privacy is necessary for the ethical utilisation of passive sensing methods in HAR, we implement a system where clients mutually train both a general FL model and a group-level one per modality. Our evaluation shows that this method leads to only a 7-13% decrease in accuracy, making it possible to build HAR systems with diverse hardware.