 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Underwater Image Haze Removal and Color Correction with an Underwater-ready Dark Channel Prior
Jul 11, 2018


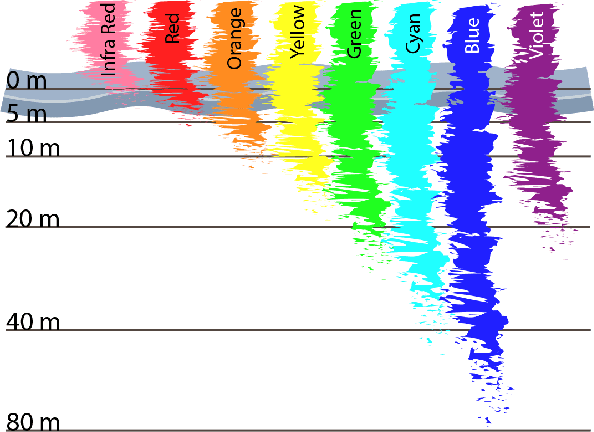

Underwater images suffer from extremely unfavourable conditions. Light is heavily attenuated and scattered. Attenuation creates change in hue, scattering causes so called veiling light. General state of the art methods for enhancing image quality are either unreliable or cannot be easily used in underwater operations. On the other hand there is a well known method for haze removal in air, called Dark Channel Prior. Even though there are known adaptations of this method to underwater applications, they do not always work correctly. This work elaborates and improves upon the initial concept presented in [1]. A modification to the Dark Channel Prior is proposed that allows for an easy application to underwater images. It is also shown that our method outperforms competing solutions based on the Dark Channel Prior. Experiments on real-life data collected within the DexROV project are also presented, showing the robustness and high performance of the proposed algorithm.
IllumiNet: Transferring Illumination from Planar Surfaces to Virtual Objects in Augmented Reality
Jul 12, 2020
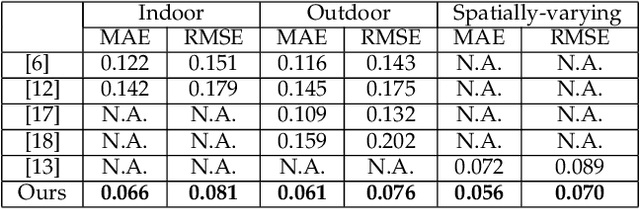
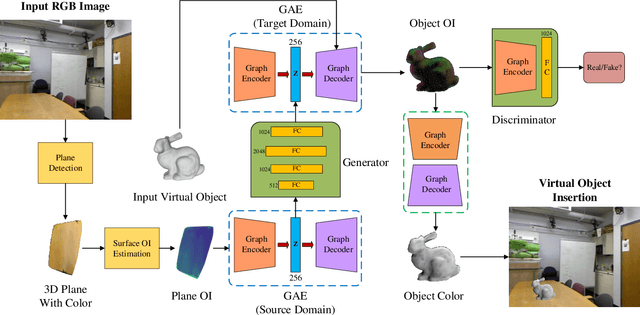

This paper presents an illumination estimation method for virtual objects in real environment by learning. While previous works tackled this problem by reconstructing high dynamic range (HDR) environment maps or the corresponding spherical harmonics, we do not seek to recover the lighting environment of the entire scene. Given a single RGB image, our method directly infers the relit virtual object by transferring the illumination features extracted from planar surfaces in the scene to the desired geometries. Compared to previous works, our approach is more robust as it works in both indoor and outdoor environments with spatially-varying illumination. Experiments and evaluation results show that our approach outperforms the state-of-the-art quantitatively and qualitatively, achieving realistic augmented experience.
Commands 4 Autonomous Vehicles (C4AV) Workshop Summary
Sep 18, 2020
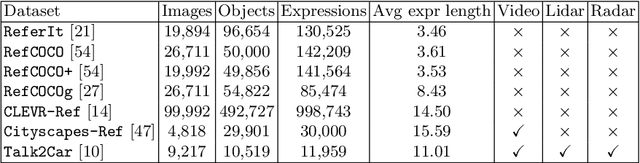

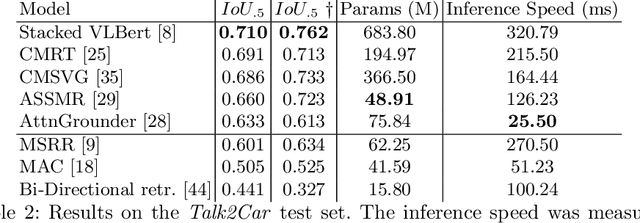
The task of visual grounding requires locating the most relevant region or object in an image, given a natural language query. So far, progress on this task was mostly measured on curated datasets, which are not always representative of human spoken language. In this work, we deviate from recent, popular task settings and consider the problem under an autonomous vehicle scenario. In particular, we consider a situation where passengers can give free-form natural language commands to a vehicle which can be associated with an object in the street scene. To stimulate research on this topic, we have organized the \emph{Commands for Autonomous Vehicles} (C4AV) challenge based on the recent \emph{Talk2Car} dataset (URL: https://www.aicrowd.com/challenges/eccv-2020-commands-4-autonomous-vehicles). This paper presents the results of the challenge. First, we compare the used benchmark against existing datasets for visual grounding. Second, we identify the aspects that render top-performing models successful, and relate them to existing state-of-the-art models for visual grounding, in addition to detecting potential failure cases by evaluating on carefully selected subsets. Finally, we discuss several possibilities for future work.
AD-Cluster: Augmented Discriminative Clustering for Domain Adaptive Person Re-identification
Apr 19, 2020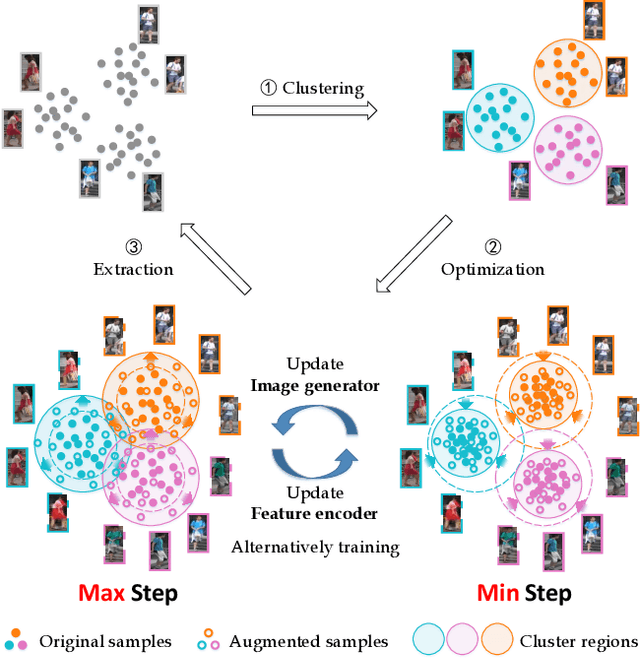
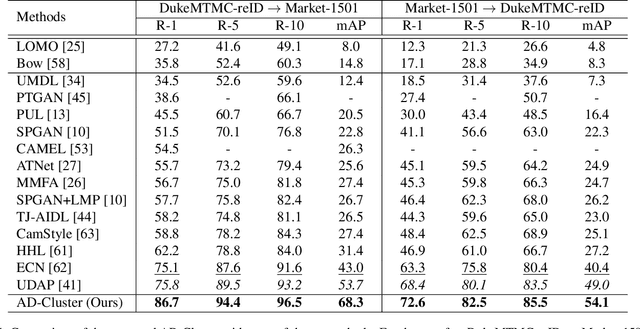
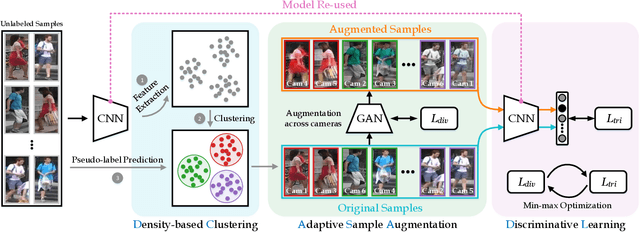
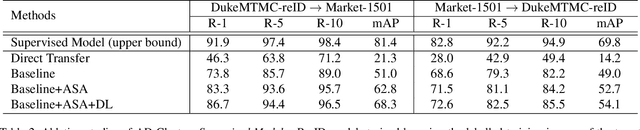
Domain adaptive person re-identification (re-ID) is a challenging task, especially when person identities in target domains are unknown. Existing methods attempt to address this challenge by transferring image styles or aligning feature distributions across domains, whereas the rich unlabeled samples in target domains are not sufficiently exploited. This paper presents a novel augmented discriminative clustering (AD-Cluster) technique that estimates and augments person clusters in target domains and enforces the discrimination ability of re-ID models with the augmented clusters. AD-Cluster is trained by iterative density-based clustering, adaptive sample augmentation, and discriminative feature learning. It learns an image generator and a feature encoder which aim to maximize the intra-cluster diversity in the sample space and minimize the intra-cluster distance in the feature space in an adversarial min-max manner. Finally, AD-Cluster increases the diversity of sample clusters and improves the discrimination capability of re-ID models greatly. Extensive experiments over Market-1501 and DukeMTMC-reID show that AD-Cluster outperforms the state-of-the-art with large margins.
Generating Holistic 3D Scene Abstractions for Text-based Image Retrieval
Apr 11, 2017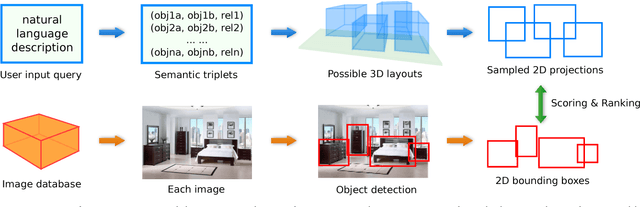

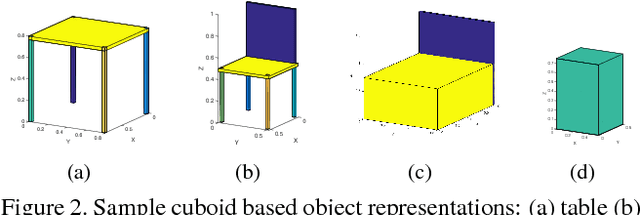
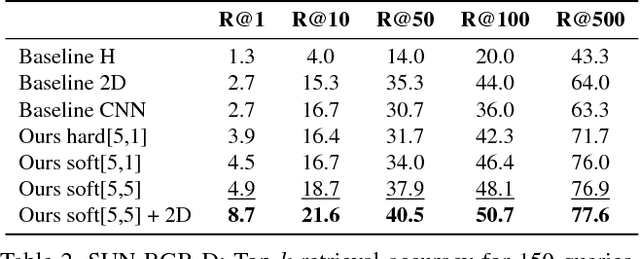
Spatial relationships between objects provide important information for text-based image retrieval. As users are more likely to describe a scene from a real world perspective, using 3D spatial relationships rather than 2D relationships that assume a particular viewing direction, one of the main challenges is to infer the 3D structure that bridges images with users' text descriptions. However, direct inference of 3D structure from images requires learning from large scale annotated data. Since interactions between objects can be reduced to a limited set of atomic spatial relations in 3D, we study the possibility of inferring 3D structure from a text description rather than an image, applying physical relation models to synthesize holistic 3D abstract object layouts satisfying the spatial constraints present in a textual description. We present a generic framework for retrieving images from a textual description of a scene by matching images with these generated abstract object layouts. Images are ranked by matching object detection outputs (bounding boxes) to 2D layout candidates (also represented by bounding boxes) which are obtained by projecting the 3D scenes with sampled camera directions. We validate our approach using public indoor scene datasets and show that our method outperforms baselines built upon object occurrence histograms and learned 2D pairwise relations.
MS and PAN image fusion by combining Brovey and wavelet methods
Jan 08, 2017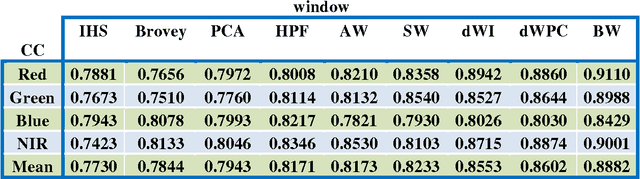


Among the existing fusion algorithms, the wavelet fusion method is the most frequently discussed one in recent publications because the wavelet approach preserves the spectral characteristics of the multispectral image better than other methods. The Brovey is also a popular fusion method used for its ability in preserving the spatial information of the PAN image. This study presents a new fusion approach that integrates the advantages of both the Brovey (which preserves a high degree of spatial information) and the wavelet (which preserves a high degree of spectral information) techniques to reduce the colour distortion of fusion results. Visual and statistical analyzes show that the proposed algorithm clearly improves the merging quality in terms of: correlation coefficient and UIQI; compared to fusion methods including, IHS, Brovey, PCA , HPF, discrete wavelet transform (DWT), and a-trous wavelet.
Item Popularity Prediction in E-commerce Using Image Quality Feature Vectors
May 12, 2016



Online retail is a visual experience- Shoppers often use images as first order information to decide if an item matches their personal style. Image characteristics such as color, simplicity, scene composition, texture, style, aesthetics and overall quality play a crucial role in making a purchase decision, clicking on or liking a product listing. In this paper we use a set of image features that indicate quality to predict product listing popularity on a major e-commerce website, Etsy. We first define listing popularity through search clicks, favoriting and purchase activity. Next, we infer listing quality from the pixel-level information of listed images as quality features. We then compare our findings to text-only models for popularity prediction. Our initial results indicate that a combined image and text modeling of product listings outperforms text-only models in popularity prediction.
Optimizing JPEG Quantization for Classification Networks
Mar 05, 2020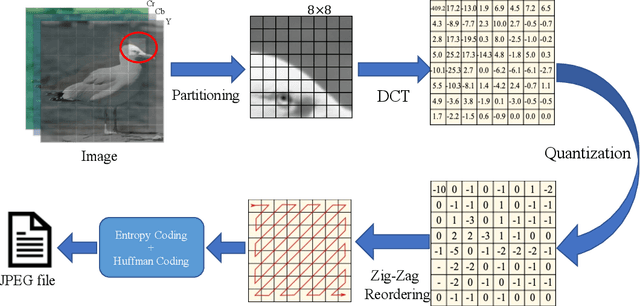

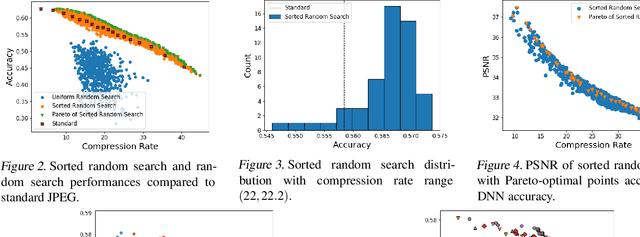
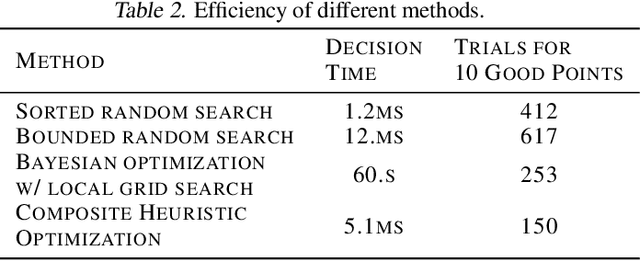
Deep learning for computer vision depends on lossy image compression: it reduces the storage required for training and test data and lowers transfer costs in deployment. Mainstream datasets and imaging pipelines all rely on standard JPEG compression. In JPEG, the degree of quantization of frequency coefficients controls the lossiness: an 8 by 8 quantization table (Q-table) decides both the quality of the encoded image and the compression ratio. While a long history of work has sought better Q-tables, existing work either seeks to minimize image distortion or to optimize for models of the human visual system. This work asks whether JPEG Q-tables exist that are "better" for specific vision networks and can offer better quality--size trade-offs than ones designed for human perception or minimal distortion. We reconstruct an ImageNet test set with higher resolution to explore the effect of JPEG compression under novel Q-tables. We attempt several approaches to tune a Q-table for a vision task. We find that a simple sorted random sampling method can exceed the performance of the standard JPEG Q-table. We also use hyper-parameter tuning techniques including bounded random search, Bayesian optimization, and composite heuristic optimization methods. The new Q-tables we obtained can improve the compression rate by 10% to 200% when the accuracy is fixed, or improve accuracy up to $2\%$ at the same compression rate.
Monocular Real-time Hand Shape and Motion Capture using Multi-modal Data
Apr 03, 2020
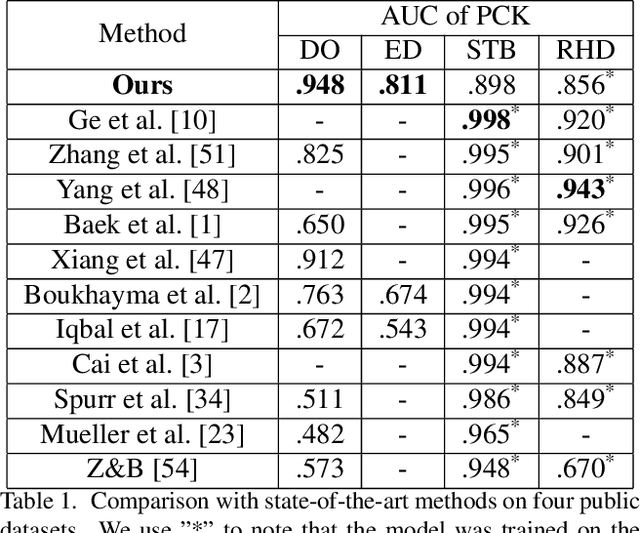
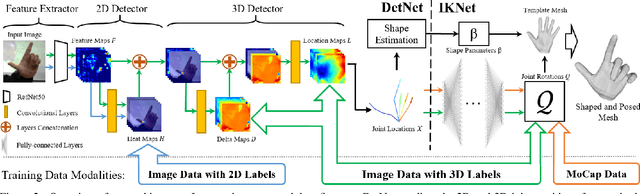
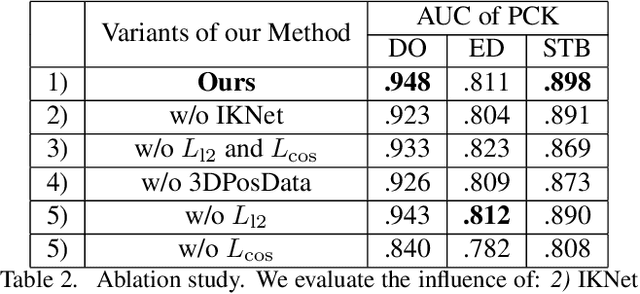
We present a novel method for monocular hand shape and pose estimation at unprecedented runtime performance of 100fps and at state-of-the-art accuracy. This is enabled by a new learning based architecture designed such that it can make use of all the sources of available hand training data: image data with either 2D or 3D annotations, as well as stand-alone 3D animations without corresponding image data. It features a 3D hand joint detection module and an inverse kinematics module which regresses not only 3D joint positions but also maps them to joint rotations in a single feed-forward pass. This output makes the method more directly usable for applications in computer vision and graphics compared to only regressing 3D joint positions. We demonstrate that our architectural design leads to a significant quantitative and qualitative improvement over the state of the art on several challenging benchmarks. Our model is publicly available for future research.
Convolutional Mean: A Simple Convolutional Neural Network for Illuminant Estimation
Jan 14, 2020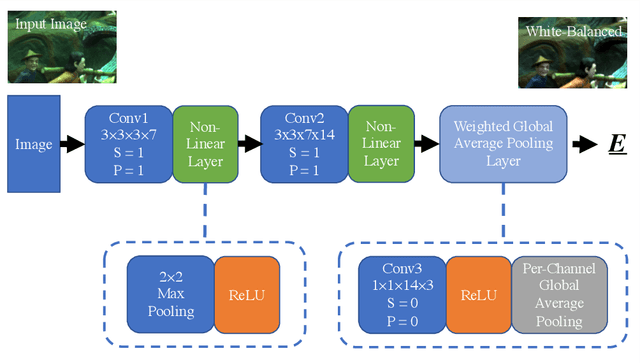
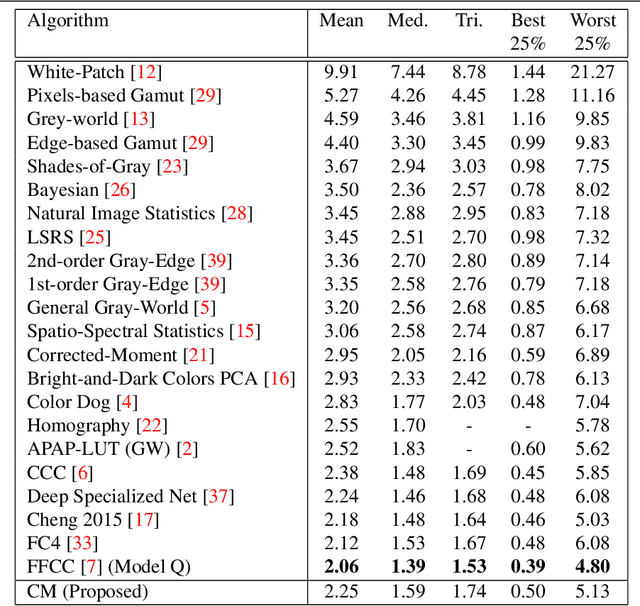
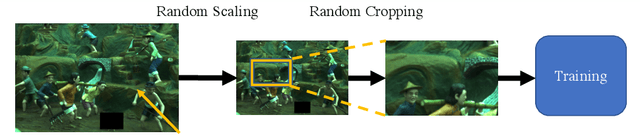
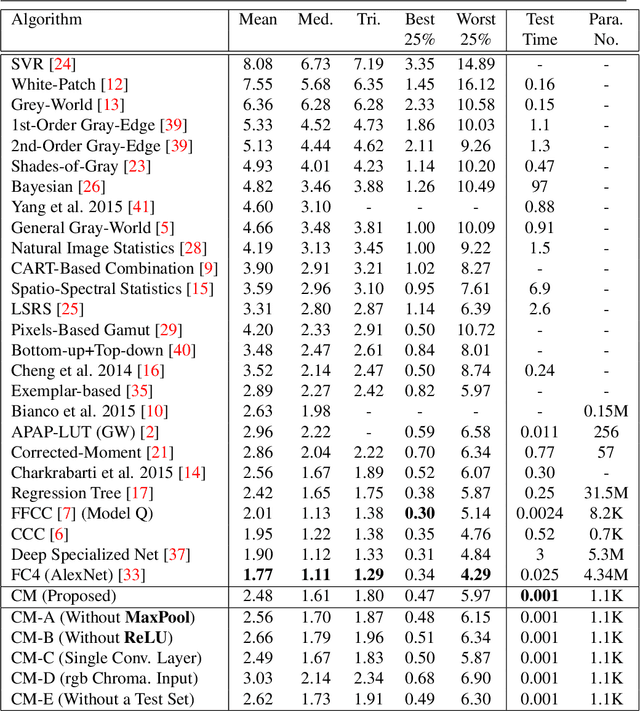
We present Convolutional Mean (CM) - a simple and fast convolutional neural network for illuminant estimation. Our proposed method only requires a small neural network model (1.1K parameters) and a 48 x 32 thumbnail input image. Our unoptimized Python implementation takes 1 ms/image, which is arguably 3-3750x faster than the current leading solutions with similar accuracy. Using two public datasets, we show that our proposed light-weight method offers accuracy comparable to the current leading methods' (which consist of thousands/millions of parameters) across several measures.