 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing JPEG Quantization for Classification Networks
Paper and Code
Mar 05, 2020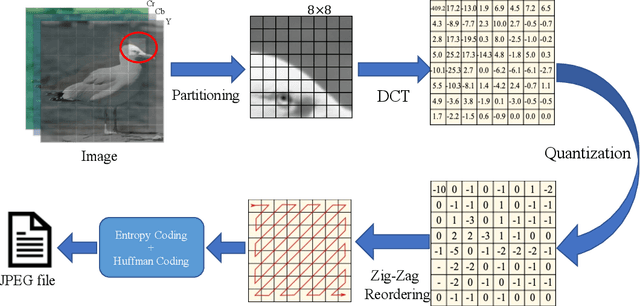

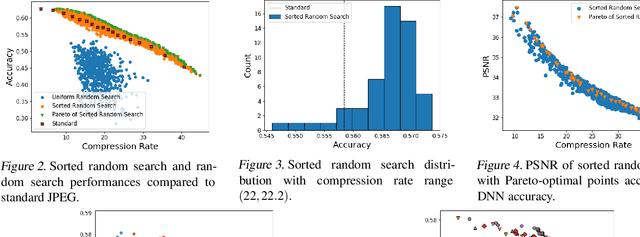
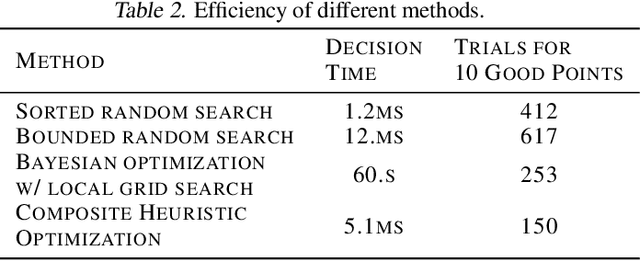
Deep learning for computer vision depends on lossy image compression: it reduces the storage required for training and test data and lowers transfer costs in deployment. Mainstream datasets and imaging pipelines all rely on standard JPEG compression. In JPEG, the degree of quantization of frequency coefficients controls the lossiness: an 8 by 8 quantization table (Q-table) decides both the quality of the encoded image and the compression ratio. While a long history of work has sought better Q-tables, existing work either seeks to minimize image distortion or to optimize for models of the human visual system. This work asks whether JPEG Q-tables exist that are "better" for specific vision networks and can offer better quality--size trade-offs than ones designed for human perception or minimal distortion. We reconstruct an ImageNet test set with higher resolution to explore the effect of JPEG compression under novel Q-tables. We attempt several approaches to tune a Q-table for a vision task. We find that a simple sorted random sampling method can exceed the performance of the standard JPEG Q-table. We also use hyper-parameter tuning techniques including bounded random search, Bayesian optimization, and composite heuristic optimization methods. The new Q-tables we obtained can improve the compression rate by 10% to 200% when the accuracy is fixed, or improve accuracy up to $2\%$ at the same compression rate.