 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
InteractDiffusion: Interaction Control in Text-to-Image Diffusion Models
Dec 10, 2023
Large-scale text-to-image (T2I) diffusion models have showcased incredible capabilities in generating coherent images based on textual descriptions, enabling vast applications in content generation. While recent advancements have introduced control over factors such as object localization, posture, and image contours, a crucial gap remains in our ability to control the interactions between objects in the generated content. Well-controlling interactions in generated images could yield meaningful applications, such as creating realistic scenes with interacting characters. In this work, we study the problems of conditioning T2I diffusion models with Human-Object Interaction (HOI) information, consisting of a triplet label (person, action, object) and corresponding bounding boxes. We propose a pluggable interaction control model, called InteractDiffusion that extends existing pre-trained T2I diffusion models to enable them being better conditioned on interactions. Specifically, we tokenize the HOI information and learn their relationships via interaction embeddings. A conditioning self-attention layer is trained to map HOI tokens to visual tokens, thereby conditioning the visual tokens better in existing T2I diffusion models. Our model attains the ability to control the interaction and location on existing T2I diffusion models, which outperforms existing baselines by a large margin in HOI detection score, as well as fidelity in FID and KID. Project page: https://jiuntian.github.io/interactdiffusion.
MS-DETR: Efficient DETR Training with Mixed Supervision
Jan 08, 2024DETR accomplishes end-to-end object detection through iteratively generating multiple object candidates based on image features and promoting one candidate for each ground-truth object. The traditional training procedure using one-to-one supervision in the original DETR lacks direct supervision for the object detection candidates. We aim at improving the DETR training efficiency by explicitly supervising the candidate generation procedure through mixing one-to-one supervision and one-to-many supervision. Our approach, namely MS-DETR, is simple, and places one-to-many supervision to the object queries of the primary decoder that is used for inference. In comparison to existing DETR variants with one-to-many supervision, such as Group DETR and Hybrid DETR, our approach does not need additional decoder branches or object queries. The object queries of the primary decoder in our approach directly benefit from one-to-many supervision and thus are superior in object candidate prediction. Experimental results show that our approach outperforms related DETR variants, such as DN-DETR, Hybrid DETR, and Group DETR, and the combination with related DETR variants further improves the performance.
Limitations of Data-Driven Spectral Reconstruction -- An Optics-Aware Analysis
Jan 08, 2024Hyperspectral imaging empowers computer vision systems with the distinct capability of identifying materials through recording their spectral signatures. Recent efforts in data-driven spectral reconstruction aim at extracting spectral information from RGB images captured by cost-effective RGB cameras, instead of dedicated hardware. In this paper we systematically analyze the performance of such methods, evaluating both the practical limitations with respect to current datasets and overfitting, as well as fundamental limits with respect to the nature of the information encoded in the RGB images, and the dependency of this information on the optical system of the camera. We find that the current models are not robust under slight variations, e.g., in noise level or compression of the RGB file. Both the methods and the datasets are also limited in their ability to cope with metameric colors. This issue can in part be overcome with metameric data augmentation. Moreover, optical lens aberrations can help to improve the encoding of the metameric information into the RGB image, which paves the road towards higher performing spectral imaging and reconstruction approaches.
Infrared Image Super-Resolution via GAN
Dec 01, 2023The ability of generative models to accurately fit data distributions has resulted in their widespread adoption and success in fields such as computer vision and natural language processing. In this chapter, we provide a brief overview of the application of generative models in the domain of infrared (IR) image super-resolution, including a discussion of the various challenges and adversarial training methods employed. We propose potential areas for further investigation and advancement in the application of generative models for IR image super-resolution.
Cascade-Zero123: One Image to Highly Consistent 3D with Self-Prompted Nearby Views
Dec 07, 2023Synthesizing multi-view 3D from one single image is a significant and challenging task. For this goal, Zero-1-to-3 methods aim to extend a 2D latent diffusion model to the 3D scope. These approaches generate the target-view image with a single-view source image and the camera pose as condition information. However, the one-to-one manner adopted in Zero-1-to-3 incurs challenges for building geometric and visual consistency across views, especially for complex objects. We propose a cascade generation framework constructed with two Zero-1-to-3 models, named Cascade-Zero123, to tackle this issue, which progressively extracts 3D information from the source image. Specifically, a self-prompting mechanism is designed to generate several nearby views at first. These views are then fed into the second-stage model along with the source image as generation conditions. With self-prompted multiple views as the supplementary information, our Cascade-Zero123 generates more highly consistent novel-view images than Zero-1-to-3. The promotion is significant for various complex and challenging scenes, involving insects, humans, transparent objects, and stacked multiple objects etc. The project page is at https://cascadezero123.github.io/.
Improve Supervised Representation Learning with Masked Image Modeling
Dec 01, 2023Training visual embeddings with labeled data supervision has been the de facto setup for representation learning in computer vision. Inspired by recent success of adopting masked image modeling (MIM) in self-supervised representation learning, we propose a simple yet effective setup that can easily integrate MIM into existing supervised training paradigms. In our design, in addition to the original classification task applied to a vision transformer image encoder, we add a shallow transformer-based decoder on top of the encoder and introduce an MIM task which tries to reconstruct image tokens based on masked image inputs. We show with minimal change in architecture and no overhead in inference that this setup is able to improve the quality of the learned representations for downstream tasks such as classification, image retrieval, and semantic segmentation. We conduct a comprehensive study and evaluation of our setup on public benchmarks. On ImageNet-1k, our ViT-B/14 model achieves 81.72% validation accuracy, 2.01% higher than the baseline model. On K-Nearest-Neighbor image retrieval evaluation with ImageNet-1k, the same model outperforms the baseline by 1.32%. We also show that this setup can be easily scaled to larger models and datasets. Code and checkpoints will be released.
A Task is Worth One Word: Learning with Task Prompts for High-Quality Versatile Image Inpainting
Dec 12, 2023Achieving high-quality versatile image inpainting, where user-specified regions are filled with plausible content according to user intent, presents a significant challenge. Existing methods face difficulties in simultaneously addressing context-aware image inpainting and text-guided object inpainting due to the distinct optimal training strategies required. To overcome this challenge, we introduce PowerPaint, the first high-quality and versatile inpainting model that excels in both tasks. First, we introduce learnable task prompts along with tailored fine-tuning strategies to guide the model's focus on different inpainting targets explicitly. This enables PowerPaint to accomplish various inpainting tasks by utilizing different task prompts, resulting in state-of-the-art performance. Second, we demonstrate the versatility of the task prompt in PowerPaint by showcasing its effectiveness as a negative prompt for object removal. Additionally, we leverage prompt interpolation techniques to enable controllable shape-guided object inpainting. Finally, we extensively evaluate PowerPaint on various inpainting benchmarks to demonstrate its superior performance for versatile image inpainting. We release our codes and models on our project page: https://powerpaint.github.io/.
On the Image-Based Detection of Tomato and Corn leaves Diseases : An in-depth comparative experiments
Dec 14, 2023The research introduces a novel plant disease detection model based on Convolutional Neural Networks (CNN) for plant image classification, marking a significant contribution to image categorization. The innovative training approach enables a streamlined and efficient system implementation. The model classifies two distinct plant diseases into four categories, presenting a novel technique for plant disease identification. In Experiment 1, Inception-V3, Dense-Net-121, ResNet-101-V2, and Xception models were employed for CNN training. The newly created plant disease image dataset includes 1963 tomato plant images and 7316 corn plant images from the PlantVillage dataset. Of these, 1374 tomato images and 5121 corn images were used for training, while 589 tomato images and 2195 corn images were used for testing/validation. Results indicate that the Xception model outperforms the other three models, yielding val_accuracy values of 95.08% and 92.21% for the tomato and corn datasets, with corresponding val_loss values of 0.3108 and 0.4204, respectively. In Experiment 2, CNN with Batch Normalization achieved disease detection rates of approximately 99.89% in the training set and val_accuracy values exceeding 97.52%, accompanied by a val_loss of 0.103. Experiment 3 employed a CNN architecture as the base model, introducing additional layers in Model 2, skip connections in Model 3, and regularizations in Model 4. Detailed experiment results and model efficiency are outlined in the paper's sub-section 1.5. Experiment 4 involved combining all corn and tomato images, utilizing various models, including MobileNet (val_accuracy=86.73%), EfficientNetB0 (val_accuracy=93.973%), Xception (val_accuracy=74.91%), InceptionResNetV2 (val_accuracy=31.03%), and CNN (59.79%). Additionally, our proposed model achieved a val_accuracy of 84.42%.
New Filters for Image Interpolation and Resizing
Dec 01, 2023We propose a new class of kernels to simplify the design of filters for image interpolation and resizing. Their properties are defined according to two parameters, specifying the width of the transition band and the height of a unique sidelobe. By varying these parameters it is possible to efficiently explore the space with only the filters that are suitable for image interpolation and resizing, and identify the filter that is best for a given application. These two parameters are also sufficient to obtain very good approximations of many commonly-used interpolation kernels. We also show that, because the Fourier transforms of these kernels have very fast decay, these filters produce better results when time-stretched for image downsizing.
PixLore: A Dataset-driven Approach to Rich Image Captioning
Dec 08, 2023
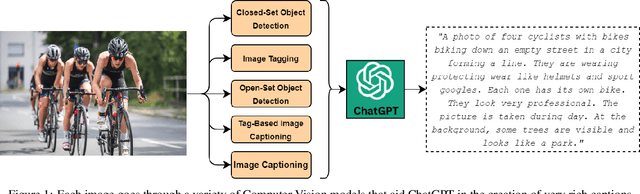

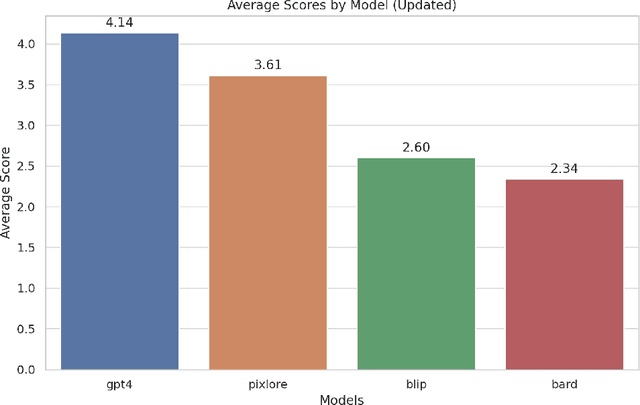
In the domain of vision-language integration, generating detailed image captions poses a significant challenge due to the lack of a curated and rich dataset. This study introduces PixLore, a novel method that leverages Querying Transformers through the fine-tuning of the BLIP-2 model using the LoRa method on a standard commercial GPU. Our approach, which involves training on a carefully assembled dataset from state-of-the-art Computer Vision models combined and augmented by ChatGPT, addresses the question of whether intricate image understanding can be achieved with an ensemble of smaller-scale models. Comparative evaluations against major models such as GPT-4 and Google Bard demonstrate that PixLore-2.7B, despite having considerably fewer parameters, is rated higher than the existing State-of-the-Art models in over half of the assessments. This research not only presents a groundbreaking approach but also highlights the importance of well-curated datasets in enhancing the performance of smaller models.