 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Space Imaging
Jul 09, 2024



Digital imaging systems have classically been based on brute-force measuring and processing of pixels organized on regular grids. The human visual system, on the other hand, performs a massive data reduction from the number of photo-receptors to the optic nerve, essentially encoding the image information into a low bandwidth latent space representation suitable for processing by the human brain. In this work, we propose to follow a similar approach for the development of artificial vision systems. Latent Space Imaging is a new paradigm that, through a combination of optics and software, directly encodes the image information into the semantically rich latent space of a generative model, thus substantially reducing bandwidth and memory requirements during the capture process. We demonstrate this new principle through an initial hardware prototype based on the single pixel camera. By designing an amplitude modulation scheme that encodes into the latent space of a generative model, we achieve compression ratios from 1:100 to 1:1,000 during the imaging process, illustrating the potential of latent space imaging for highly efficient imaging hardware, to enable future applications in high speed imaging, or task-specific cameras with substantially reduced hardware complexity.
End-to-End Hybrid Refractive-Diffractive Lens Design with Differentiable Ray-Wave Model
Jun 02, 2024



Hybrid refractive-diffractive lenses combine the light efficiency of refractive lenses with the information encoding power of diffractive optical elements (DOE), showing great potential as the next generation of imaging systems. However, accurately simulating such hybrid designs is generally difficult, and in particular, there are no existing differentiable image formation models for hybrid lenses with sufficient accuracy. In this work, we propose a new hybrid ray-tracing and wave-propagation (ray-wave) model for accurate simulation of both optical aberrations and diffractive phase modulation, where the DOE is placed between the last refractive surface and the image sensor, i.e. away from the Fourier plane that is often used as a DOE position. The proposed ray-wave model is fully differentiable, enabling gradient back-propagation for end-to-end co-design of refractive-diffractive lens optimization and the image reconstruction network. We validate the accuracy of the proposed model by comparing the simulated point spread functions (PSFs) with theoretical results, as well as simulation experiments that show our model to be more accurate than solutions implemented in commercial software packages like Zemax. We demonstrate the effectiveness of the proposed model through real-world experiments and show significant improvements in both aberration correction and extended depth-of-field (EDoF) imaging. We believe the proposed model will motivate further investigation into a wide range of applications in computational imaging, computational photography, and advanced optical design. Code will be released upon publication.
Limitations of Data-Driven Spectral Reconstruction -- An Optics-Aware Analysis
Jan 08, 2024



Hyperspectral imaging empowers computer vision systems with the distinct capability of identifying materials through recording their spectral signatures. Recent efforts in data-driven spectral reconstruction aim at extracting spectral information from RGB images captured by cost-effective RGB cameras, instead of dedicated hardware. In this paper we systematically analyze the performance of such methods, evaluating both the practical limitations with respect to current datasets and overfitting, as well as fundamental limits with respect to the nature of the information encoded in the RGB images, and the dependency of this information on the optical system of the camera. We find that the current models are not robust under slight variations, e.g., in noise level or compression of the RGB file. Both the methods and the datasets are also limited in their ability to cope with metameric colors. This issue can in part be overcome with metameric data augmentation. Moreover, optical lens aberrations can help to improve the encoding of the metameric information into the RGB image, which paves the road towards higher performing spectral imaging and reconstruction approaches.
MetaISP -- Exploiting Global Scene Structure for Accurate Multi-Device Color Rendition
Jan 06, 2024



Image signal processors (ISPs) are historically grown legacy software systems for reconstructing color images from noisy raw sensor measurements. Each smartphone manufacturer has developed its ISPs with its own characteristic heuristics for improving the color rendition, for example, skin tones and other visually essential colors. The recent interest in replacing the historically grown ISP systems with deep-learned pipelines to match DSLR's image quality improves structural features in the image. However, these works ignore the superior color processing based on semantic scene analysis that distinguishes mobile phone ISPs from DSLRs. Here, we present MetaISP, a single model designed to learn how to translate between the color and local contrast characteristics of different devices. MetaISP takes the RAW image from device A as input and translates it to RGB images that inherit the appearance characteristics of devices A, B, and C. We achieve this result by employing a lightweight deep learning technique that conditions its output appearance based on the device of interest. In this approach, we leverage novel attention mechanisms inspired by cross-covariance to learn global scene semantics. Additionally, we use the metadata that typically accompanies RAW images and estimate scene illuminants when they are unavailable.
CRISPnet: Color Rendition ISP Net
Mar 22, 2022
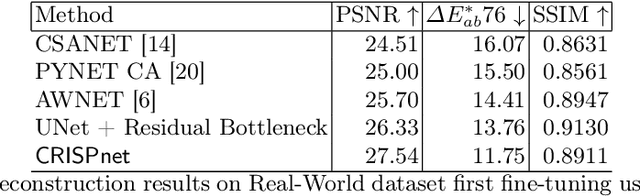
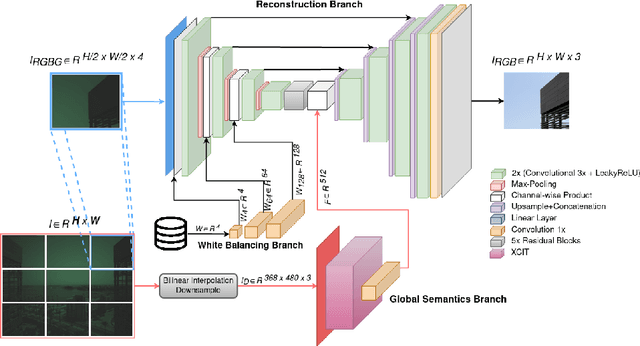
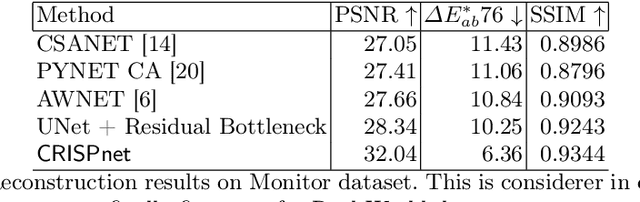
Image signal processors (ISPs) are historically grown legacy software systems for reconstructing color images from noisy raw sensor measurements. They are usually composited of many heuristic blocks for denoising, demosaicking, and color restoration. Color reproduction in this context is of particular importance, since the raw colors are often severely distorted, and each smart phone manufacturer has developed their own characteristic heuristics for improving the color rendition, for example of skin tones and other visually important colors. In recent years there has been strong interest in replacing the historically grown ISP systems with deep learned pipelines. Much progress has been made in approximating legacy ISPs with such learned models. However, so far the focus of these efforts has been on reproducing the structural features of the images, with less attention paid to color rendition. Here we present CRISPnet, the first learned ISP model to specifically target color rendition accuracy relative to a complex, legacy smart phone ISP. We achieve this by utilizing both image metadata (like a legacy ISP would), as well as by learning simple global semantics based on image classification -- similar to what a legacy ISP does to determine the scene type. We also contribute a new ISP image dataset consisting of both high dynamic range monitor data, as well as real-world data, both captured with an actual cell phone ISP pipeline under a variety of lighting conditions, exposure times, and gain settings.
Predictability and Fairness in Social Sensing
Jul 31, 2020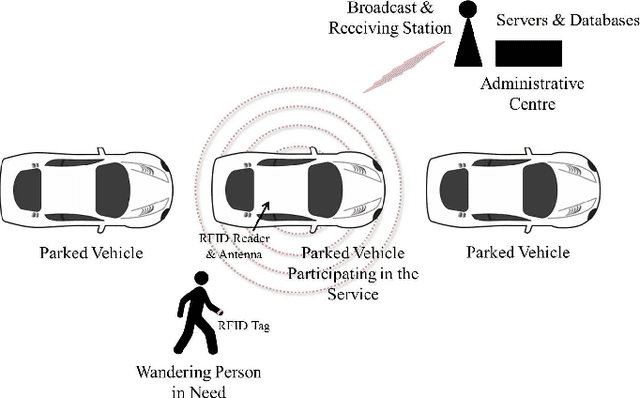
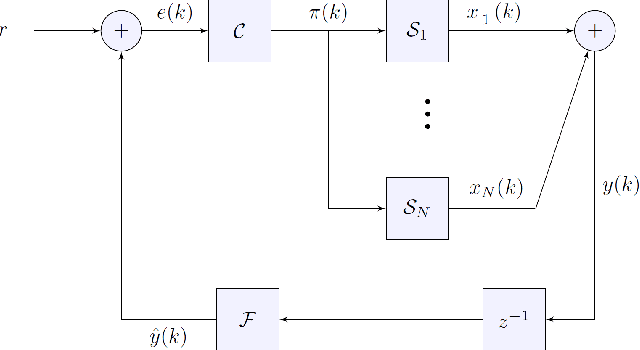
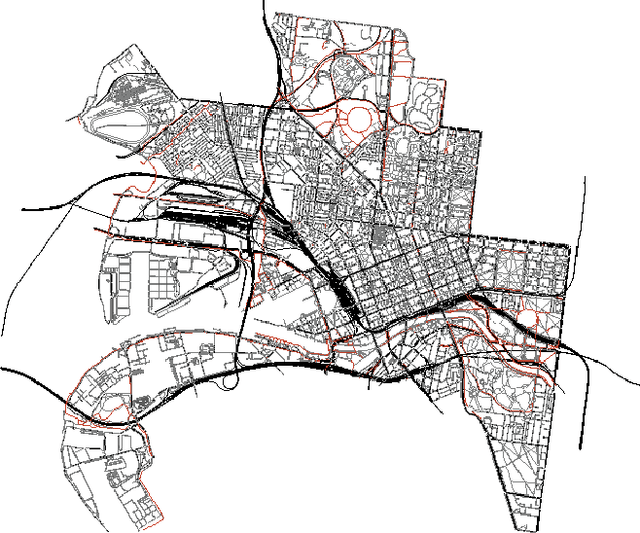
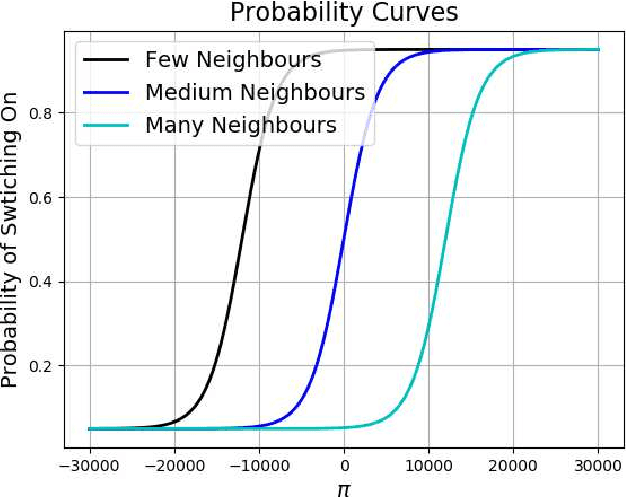
In many applications, one may benefit from the collaborative collection of data for sensing a physical phenomenon, which is known as social sensing. We show how to make social sensing (1) predictable, in the sense of guaranteeing that the number of queries per participant will be independent of the initial state, in expectation, even when the population of participants varies over time, and (2) fair, in the sense of guaranteeing that the number of queries per participant will be equalised among the participants, in expectation, even when the population of participants varies over time. In a use case, we consider a large, high-density network of participating parked vehicles. When awoken by an administrative centre, this network proceeds to search for moving, missing entities of interest using RFID-based techniques. We regulate the number and geographical distribution of the parked vehicles that are "Switched On" and thus actively searching for the moving entity of interest. In doing so, we seek to conserve vehicular energy consumption while, at the same time, maintaining good geographical coverage of the city such that the moving entity of interest is likely to be located within an acceptable time frame. Which vehicle participants are "Switched On" at any point in time is determined periodically through the use of stochastic techniques. This is illustrated on the example of a missing Alzheimer's patient in Melbourne, Australia.