 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Two-Stage Multiple Instance Learning Framework for the Detection of Breast Cancer in Mammograms
Apr 24, 2020
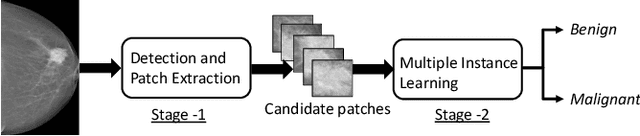
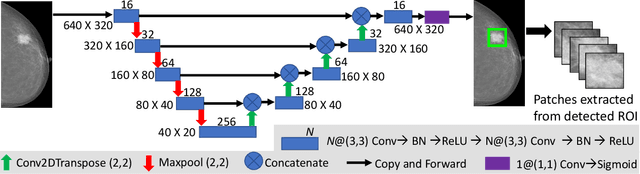
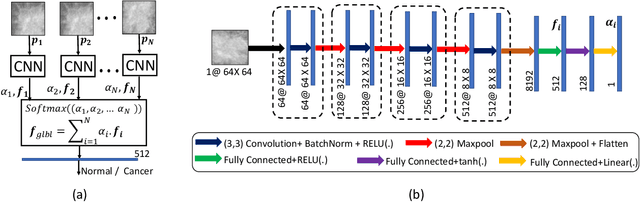
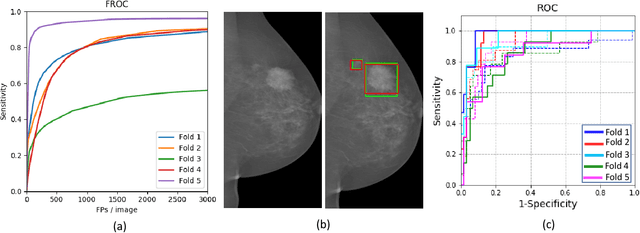
Mammograms are commonly employed in the large scale screening of breast cancer which is primarily characterized by the presence of malignant masses. However, automated image-level detection of malignancy is a challenging task given the small size of the mass regions and difficulty in discriminating between malignant, benign mass and healthy dense fibro-glandular tissue. To address these issues, we explore a two-stage Multiple Instance Learning (MIL) framework. A Convolutional Neural Network (CNN) is trained in the first stage to extract local candidate patches in the mammograms that may contain either a benign or malignant mass. The second stage employs a MIL strategy for an image level benign vs. malignant classification. A global image-level feature is computed as a weighted average of patch-level features learned using a CNN. Our method performed well on the task of localization of masses with an average Precision/Recall of 0.76/0.80 and acheived an average AUC of 0.91 on the imagelevel classification task using a five-fold cross-validation on the INbreast dataset. Restricting the MIL only to the candidate patches extracted in Stage 1 led to a significant improvement in classification performance in comparison to a dense extraction of patches from the entire mammogram.
Is the winner really the best? A critical analysis of common research practice in biomedical image analysis competitions
Jun 06, 2018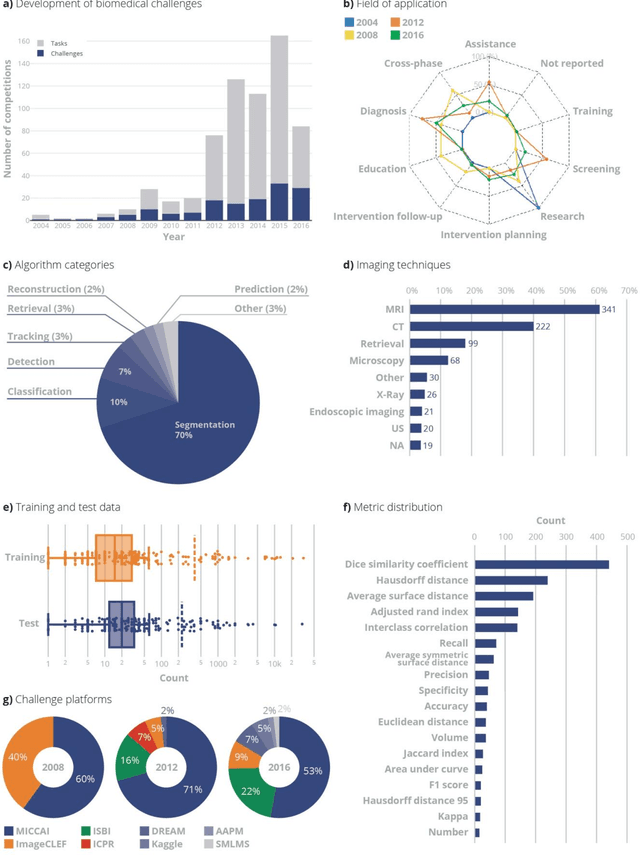
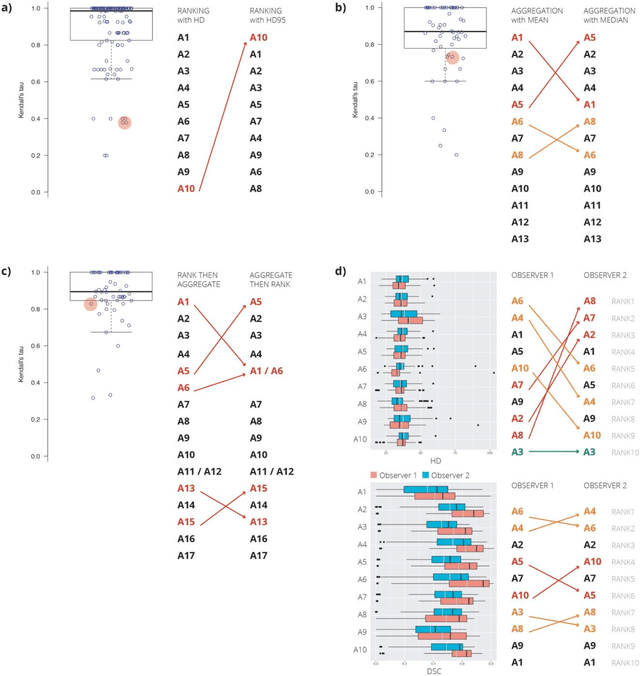
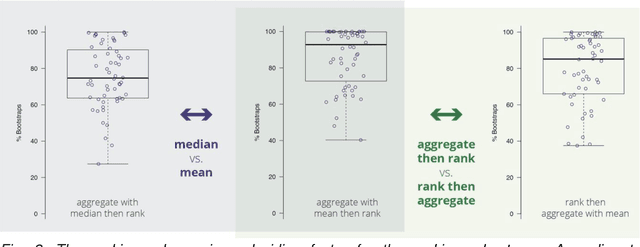
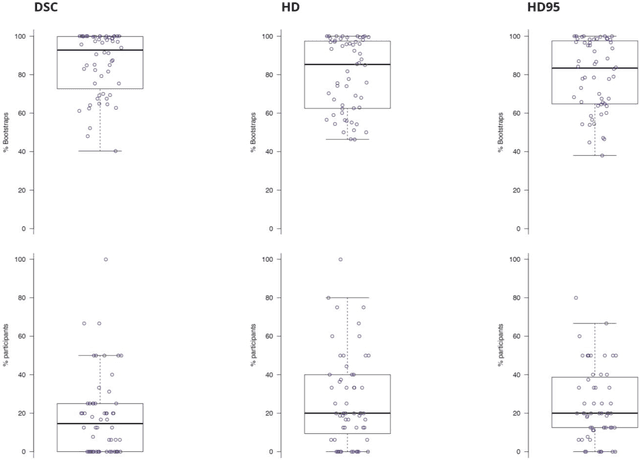
International challenges have become the standard for validation of biomedical image analysis methods. Given their scientific impact, it is surprising that a critical analysis of common practices related to the organization of challenges has not yet been performed. In this paper, we present a comprehensive analysis of biomedical image analysis challenges conducted up to now. We demonstrate the importance of challenges and show that the lack of quality control has critical consequences. First, reproducibility and interpretation of the results is often hampered as only a fraction of relevant information is typically provided. Second, the rank of an algorithm is generally not robust to a number of variables such as the test data used for validation, the ranking scheme applied and the observers that make the reference annotations. To overcome these problems, we recommend best practice guidelines and define open research questions to be addressed in the future.
DPD-InfoGAN: Differentially Private Distributed InfoGAN
Oct 24, 2020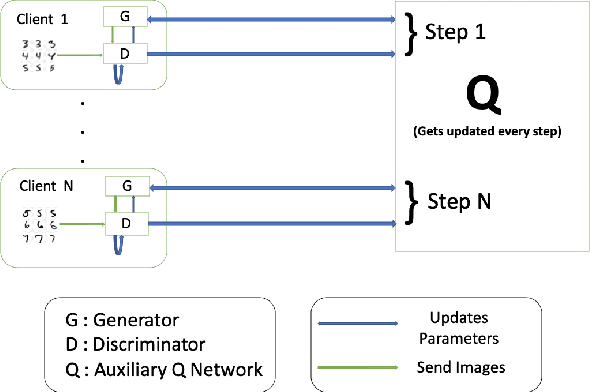
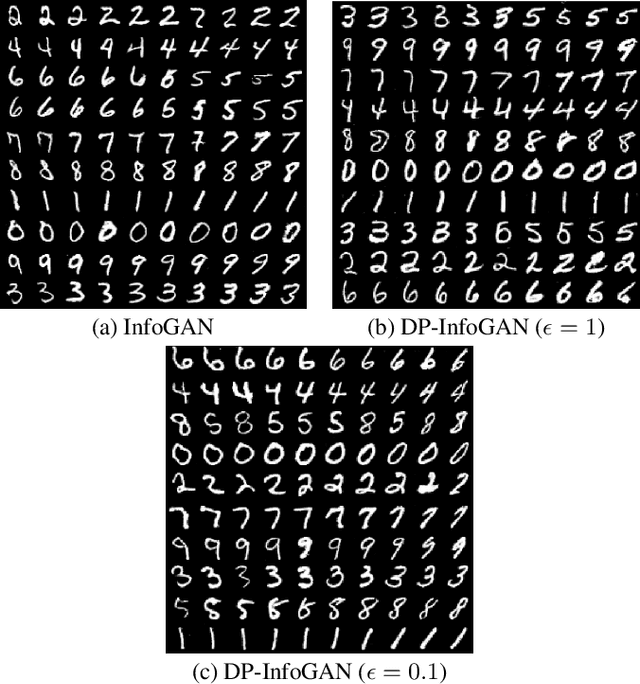


Generative Adversarial Networks (GANs) are deep learning architectures capable of generating synthetic datasets. Despite producing high-quality synthetic images, the default GAN has no control over the kinds of images it generates. The Information Maximizing GAN (InfoGAN) is a variant of the default GAN that introduces feature-control variables that are automatically learned by the framework, hence providing greater control over the different kinds of images produced. Due to the high model complexity of InfoGAN, the generative distribution tends to be concentrated around the training data points. This is a critical problem as the models may inadvertently expose the sensitive and private information present in the dataset. To address this problem, we propose a differentially private version of InfoGAN (DP-InfoGAN). We also extend our framework to a distributed setting (DPD-InfoGAN) to allow clients to learn different attributes present in other clients' datasets in a privacy-preserving manner. In our experiments, we show that both DP-InfoGAN and DPD-InfoGAN can synthesize high-quality images with flexible control over image attributes while preserving privacy.
Evaluation of Cross-View Matching to Improve Ground Vehicle Localization with Aerial Perception
Mar 17, 2020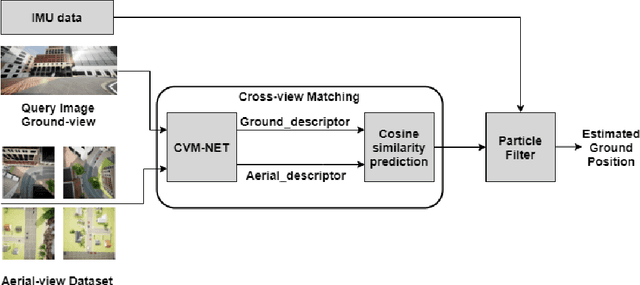
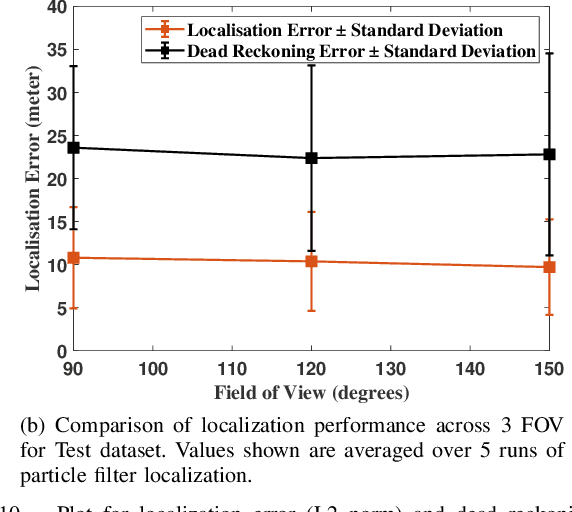

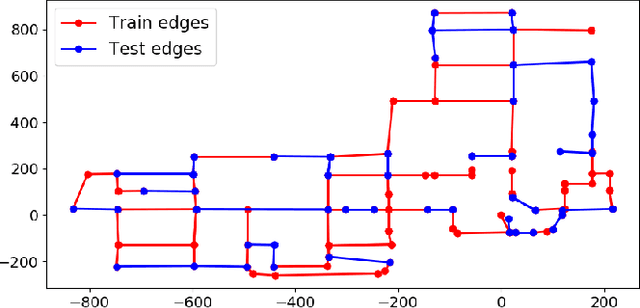
Cross-view matching refers to the problem of finding the closest match to a given query ground-view image to one from a database of aerial images. If the aerial images are geotagged, then the closest matching aerial image can be used to localize the query ground-view image. Recently, due to the success of deep learning methods, a number of cross-view matching techniques have been proposed. These techniques perform well for the matching of isolated query images. In this paper, we evaluate cross-view matching for the task of localizing a ground vehicle over a longer trajectory. We use the cross-view matching module as a sensor measurement fused with a particle filter. We evaluate the performance of this method using a city-wide dataset collected in photorealistic simulation using five parameters: height of aerial images, the pitch of the aerial camera mount, field-of-view of ground camera, measurement model and resampling strategy for the particles in the particle filter.
Harnessing spatial homogeneity of neuroimaging data: patch individual filter layers for CNNs
Jul 23, 2020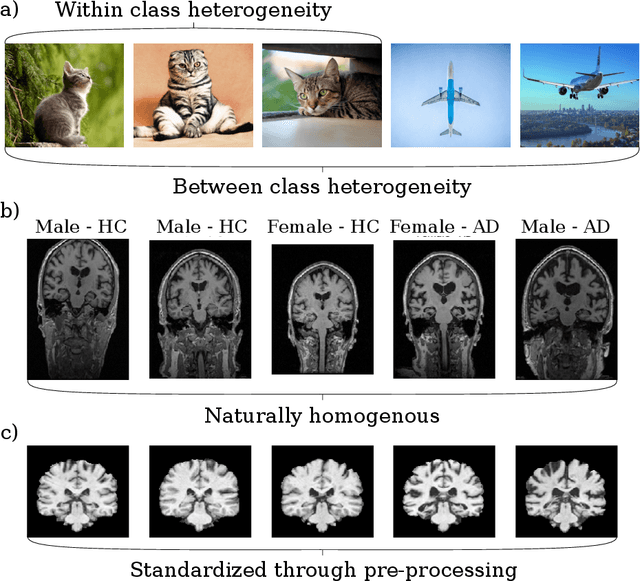
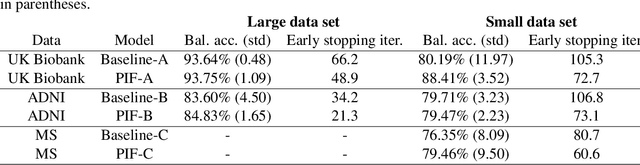
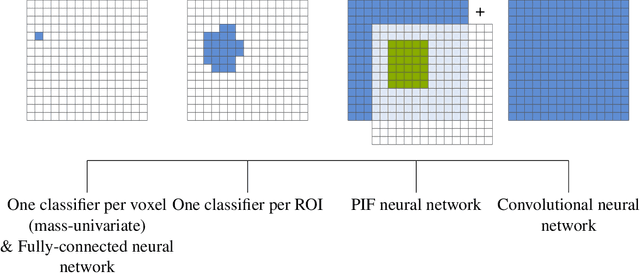
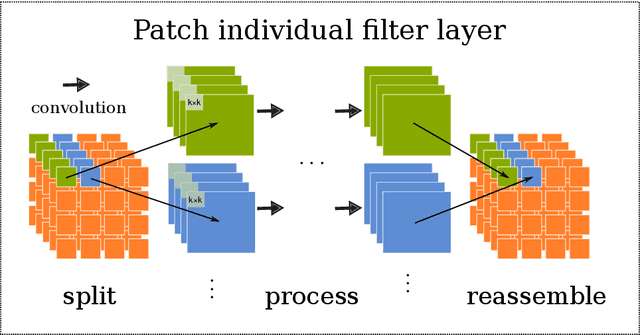
Neuroimaging data, e.g. obtained from magnetic resonance imaging (MRI), is comparably homogeneous due to (1) the uniform structure of the brain and (2) additional efforts to spatially normalize the data to a standard template using linear and non-linear transformations. Convolutional neural networks (CNNs), in contrast, have been specifically designed for highly heterogeneous data, such as natural images, by sliding convolutional filters over different positions in an image. Here, we suggest a new CNN architecture that combines the idea of hierarchical abstraction in neural networks with a prior on the spatial homogeneity of neuroimaging data: Whereas early layers are trained globally using standard convolutional layers, we introduce for higher, more abstract layers patch individual filters (PIF). By learning filters in individual image regions (patches) without sharing weights, PIF layers can learn abstract features faster and with fewer samples. We thoroughly evaluated PIF layers for three different tasks and data sets, namely sex classification on UK Biobank data, Alzheimer's disease detection on ADNI data and multiple sclerosis detection on private hospital data. We demonstrate that CNNs using PIF layers result in higher accuracies, especially in low sample size settings, and need fewer training epochs for convergence. To the best of our knowledge, this is the first study which introduces a prior on brain MRI for CNN learning.
Shift-Net: Image Inpainting via Deep Feature Rearrangement
Apr 13, 2018
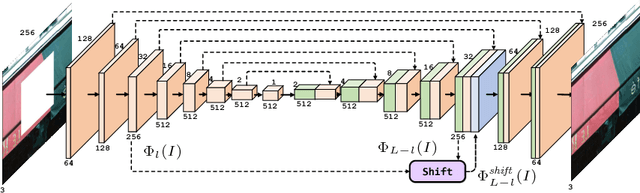


Deep convolutional networks (CNNs) have exhibited their potential in image inpainting for producing plausible results. However, in most existing methods, e.g., context encoder, the missing parts are predicted by propagating the surrounding convolutional features through a fully connected layer, which intends to produce semantically plausible but blurry result. In this paper, we introduce a special shift-connection layer to the U-Net architecture, namely Shift-Net, for filling in missing regions of any shape with sharp structures and fine-detailed textures. To this end, the encoder feature of the known region is shifted to serve as an estimation of the missing parts. A guidance loss is introduced on decoder feature to minimize the distance between the decoder feature after fully connected layer and the ground-truth encoder feature of the missing parts. With such constraint, the decoder feature in missing region can be used to guide the shift of encoder feature in known region. An end-to-end learning algorithm is further developed to train the Shift-Net. Experiments on the Paris StreetView and Places datasets demonstrate the efficiency and effectiveness of our Shift-Net in producing sharper, fine-detailed, and visually plausible results. The codes and pre-trained models are available at https://github.com/Zhaoyi-Yan/Shift-Net.
L-CO-Net: Learned Condensation-Optimization Network for Clinical Parameter Estimation from Cardiac Cine MRI
Apr 21, 2020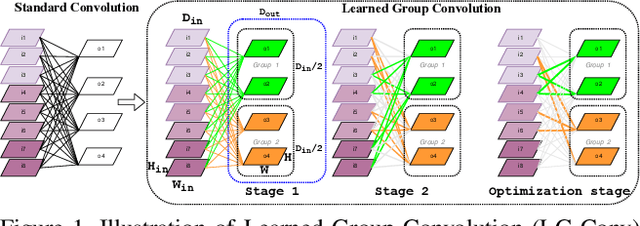
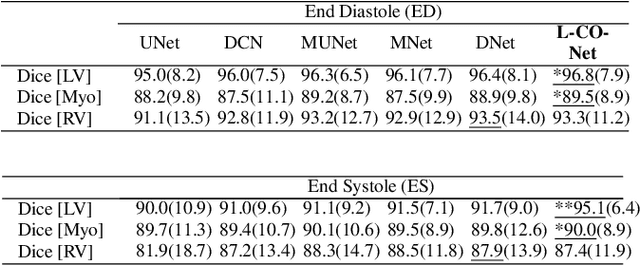
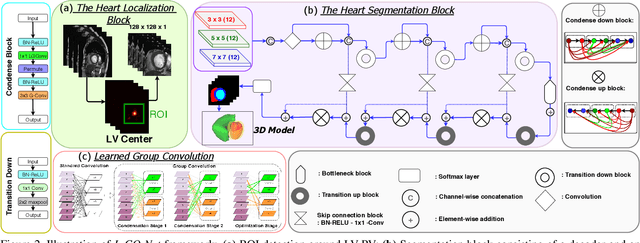
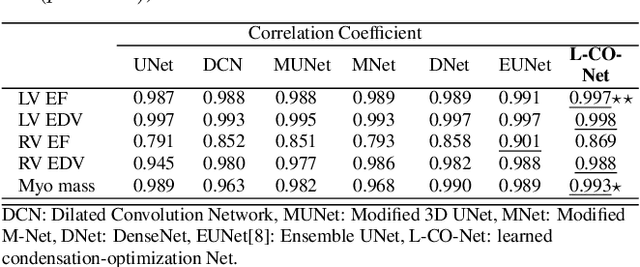
In this work, we implement a fully convolutional segmenter featuring both a learned group structure and a regularized weight-pruner to reduce the high computational cost in volumetric image segmentation. We validated our framework on the ACDC dataset featuring one healthy and four pathology groups imaged throughout the cardiac cycle. Our technique achieved Dice scores of 96.8% (LV blood-pool), 93.3% (RV blood-pool) and 90.0% (LV Myocardium) with five-fold cross-validation and yielded similar clinical parameters as those estimated from the ground truth segmentation data. Based on these results, this technique has the potential to become an efficient and competitive cardiac image segmentation tool that may be used for cardiac computer-aided diagnosis, planning, and guidance applications.
Learning to Deblur and Generate High Frame Rate Video with an Event Camera
Mar 02, 2020
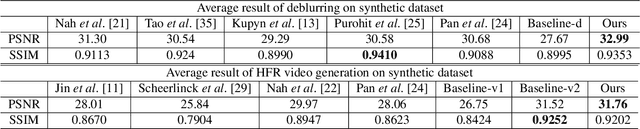
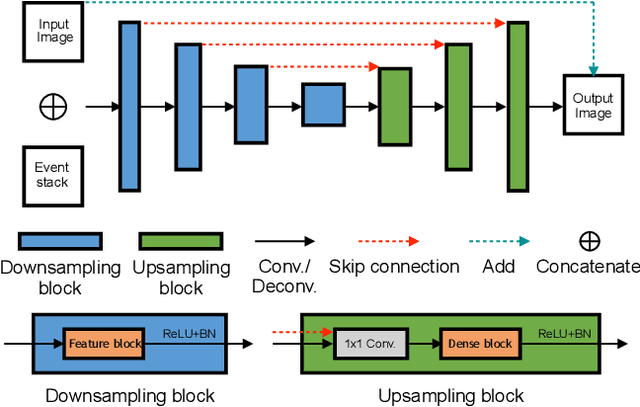
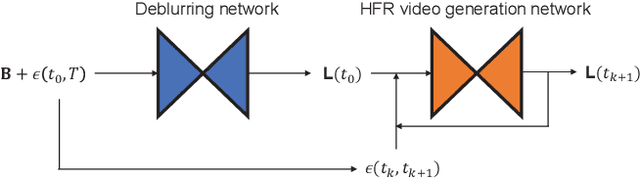
Event cameras are bio-inspired cameras which can measure the change of intensity asynchronously with high temporal resolution. One of the event cameras' advantages is that they do not suffer from motion blur when recording high-speed scenes. In this paper, we formulate the deblurring task on traditional cameras directed by events to be a residual learning one, and we propose corresponding network architectures for effective learning of deblurring and high frame rate video generation tasks. We first train a modified U-Net network to restore a sharp image from a blurry image using corresponding events. Then we train another similar network with different downsampling blocks to generate high frame rate video using the restored sharp image and events. Experiment results show that our method can restore sharper images and videos than state-of-the-art methods.
Crisscrossed Captions: Extended Intramodal and Intermodal Semantic Similarity Judgments for MS-COCO
Apr 30, 2020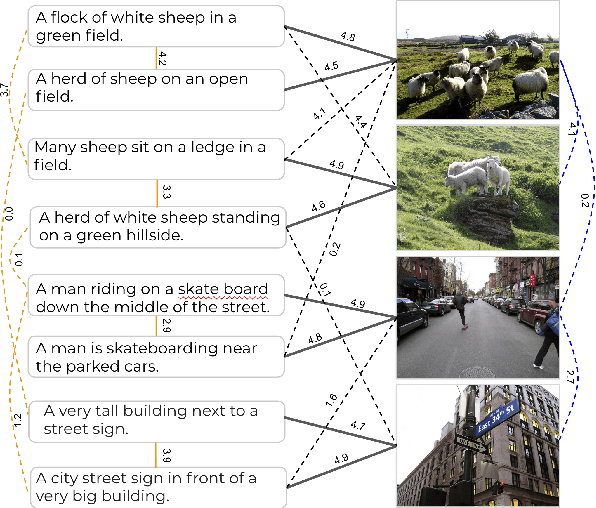



Image captioning datasets have proven useful for multimodal representation learning, and a common evaluation paradigm based on multimodal retrieval has emerged. Unfortunately, datasets have only limited cross-modal associations: images are not paired with others, captions are only paired with others that describe the same image, there are no negative associations and there are missing positive cross-modal associations. This undermines retrieval evaluation and limits research into how inter-modality learning impacts intra-modality tasks. To address this gap, we create the \textit{Crisscrossed Captions} (CxC) dataset, extending MS-COCO with new semantic similarity judgments for \textbf{247,315} intra- and inter-modality pairs. We provide baseline model performance results for both retrieval and correlations with human rankings, emphasizing both intra- and inter-modality learning.
A Convex Similarity Index for Sparse Recovery of Missing Image Samples
Oct 17, 2017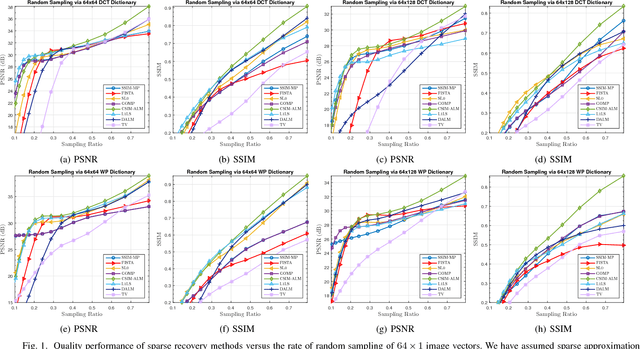
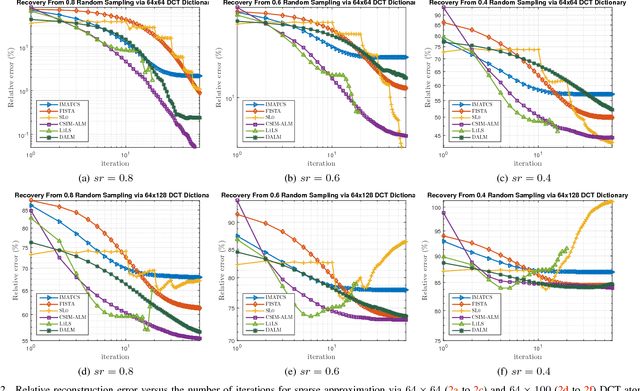
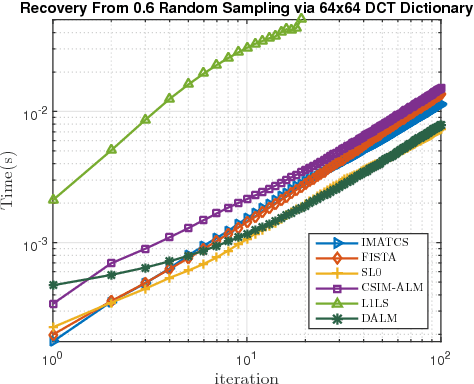
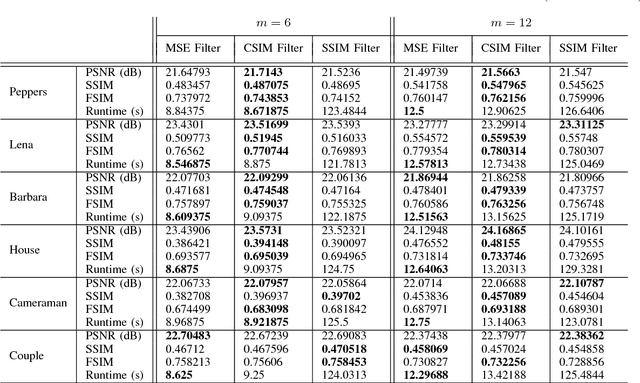
This paper investigates the problem of recovering missing samples using methods based on sparse representation adapted especially for image signals. Instead of $l_2$-norm or Mean Square Error (MSE), a new perceptual quality measure is used as the similarity criterion between the original and the reconstructed images. The proposed criterion called Convex SIMilarity (CSIM) index is a modified version of the Structural SIMilarity (SSIM) index, which despite its predecessor, is convex and uni-modal. We derive mathematical properties for the proposed index and show how to optimally choose the parameters of the proposed criterion, investigating the Restricted Isometry (RIP) and error-sensitivity properties. We also propose an iterative sparse recovery method based on a constrained $l_1$-norm minimization problem, incorporating CSIM as the fidelity criterion. The resulting convex optimization problem is solved via an algorithm based on Alternating Direction Method of Multipliers (ADMM). Taking advantage of the convexity of the CSIM index, we also prove the convergence of the algorithm to the globally optimal solution of the proposed optimization problem, starting from any arbitrary point. Simulation results confirm the performance of the new similarity index as well as the proposed algorithm for missing sample recovery of image patch signals.