 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasurement noise limits the advantage of nonlinear models over linear models in biomedical prediction
Jun 16, 2026On biomedical tabular data, flexible models such as deep networks, gradient-boosted trees, and kernel methods are repeatedly matched or beaten by linear and logistic regression given the same features. The usual reaction is to treat this as a model-side shortfall, to be fixed with more data, a better architecture, or tuning, on the assumption that the nonlinear structure is there and the model has failed to capture it. We argue that these fixes cannot help when the binding limit is the measurement rather than the model, as it frequently is in biomedicine. Additive noise blurs the population-optimal predictor, and because blurring removes a function's fine, rapidly varying detail before its broad shape, it erases nonlinear structure faster than linear structure. A degree-$k$ interaction is attenuated by the $k$-th power of feature reliability, while the linear part is attenuated only once. At the reliabilities typical of biomedical measurement, the nonlinear advantage can vanish even when the underlying biology is strongly nonlinear, and what the noise removes cannot be recovered by a larger cohort or a more flexible model, only by better measurement. The nonlinearity is hidden, not absent, and a tie between linear and flexible models is not by itself a verdict on the biology. These pieces are classical, drawn from measurement-error statistics, psychometrics, and Gaussian analysis, and we assemble them into an exact excess-risk identity. Measurement reliability is one of three conditions, alongside sample size and feature representation, that must align for a flexible model to help, and together they leave only a narrow window that most biomedical tasks fall outside. Across 140 UK Biobank tasks, the gap between flexible and linear models, where it exists, carries the predicted noise signature, and the three conditions can be separated by intervention but not by a benchmark alone.
Flow Matching with In-Context Priors for Out-of-Distribution Brain Dynamics
Jun 10, 2026Flow matching and diffusion models enable conditional generation across domains ranging from images to proteins, with recent extensions to out-of-distribution contexts. Yet generative models of neural time series have largely remained restricted to categorical conditioning, precluding compositional and zero-shot generalization. In this work, we propose a per-timestep conditioned diffusion transformer for generating realistic fMRI brain dynamics during unseen cognitive tasks by injecting both compositional language and optional spatial priors in-context. Such zero-shot generation could enable counterfactual neuroscience by supporting in-silico design and evaluation of novel cognitive experiments before empirical validation. Leveraging this model, we evaluate across hundreds of held-out task conditions and characterize predictive performance in relation to the training manifold. From language alone, the model recovers region-specific recruitment across tasks and held-out spatial activation patterns. Spatial priors, when available, complement the text pathway by anchoring generation in regions of task space where language alone degrades, while retaining the compositional structure needed for counterfactual task specification. To our knowledge this is the first generative model of whole-cortex fMRI dynamics for unseen cognitive tasks, advancing counterfactual neuroscience and data-driven experimental design.
Redefining Instance Matching: A Unified Framework for Part-Aware Matching in Panoptic Segmentation Evaluation
May 29, 2026The Panoptic Quality (PQ) metric is the standard for jointly evaluating instance and semantic segmentation. However, its original definition relies on a One-to-One matching between predicted and ground truth segments, which is only straightforward when the IoU threshold exceeds 0.5. Below 0.5, multiple matching strategies emerge in a poorly explored problem space. We systematically elucidate this space by recasting segment matching as a constrained bipartite assignment problem. Independently bounding the prediction- and ground-truth-side degrees yields four matching strategies: One-to-One, Many-to-One, One-to-Many, and Many-to-Many. We show that the first three are well-defined within the PQ framework, while Many-to-Many falls outside it. These strategies become relevant when instances are fragmented, adjacent objects are difficult to delineate, or annotations are noisy. Central to our framework is a vertex-based accounting of TP, FN, and FP, anchored to ground truth and predicted segments rather than to matching edges. We further show that the framework extends naturally to part-aware panoptic segmentation, and we explore part-aware evaluation on biomedical data. Across configurable case studies we report how different combinations of thresholds and matching strategies behave in practice. We release a unified open-source package built on Panoptica. It exposes Voronoi-based region-wise analysis, part-aware evaluation, and Area Under Threshold Curve computations as configurable options.
Beyond Binary: Speech Representations Across the Cognitive Score Hierarchy
May 26, 2026This study examines the relationship between speech representations and the hierarchical structure of cognitive assessment in mild cognitive impairment. Utilizing 5,754 German neuropsychological assessment recordings, we evaluate six cognitive tasks across three score levels: task, domain, and global levels. We compare hand-crafted acoustic features with self-supervised learning (SSL) embeddings. Results show that although SSL representations generally outperform hand-crafted features at lower levels, this trend reverses for MCI classification. Furthermore, task-specific constraints influence performance: tasks with greater response freedom exhibit performance dilution as hierarchical levels increase, suggesting ``specialist'' representations, whereas the performance of highly structured tasks increases toward higher levels, suggesting ``generalist'' representations. These findings show links between task constraints and assessment hierarchy in automated clinical speech analysis.
Brain-Semantoks: Learning Semantic Tokens of Brain Dynamics with a Self-Distilled Foundation Model
Dec 12, 2025The development of foundation models for functional magnetic resonance imaging (fMRI) time series holds significant promise for predicting phenotypes related to disease and cognition. Current models, however, are often trained using a mask-and-reconstruct objective on small brain regions. This focus on low-level information leads to representations that are sensitive to noise and temporal fluctuations, necessitating extensive fine-tuning for downstream tasks. We introduce Brain-Semantoks, a self-supervised framework designed specifically to learn abstract representations of brain dynamics. Its architecture is built on two core innovations: a semantic tokenizer that aggregates noisy regional signals into robust tokens representing functional networks, and a self-distillation objective that enforces representational stability across time. We show that this objective is stabilized through a novel training curriculum, ensuring the model robustly learns meaningful features from low signal-to-noise time series. We demonstrate that learned representations enable strong performance on a variety of downstream tasks even when only using a linear probe. Furthermore, we provide comprehensive scaling analyses indicating more unlabeled data reliably results in out-of-distribution performance gains without domain adaptation.
Identifying confounders in deep-learning-based model predictions using DeepRepViz
Sep 27, 2023Deep Learning (DL) models are increasingly used to analyze neuroimaging data and uncover insights about the brain, brain pathologies, and psychological traits. However, extraneous `confounders' variables such as the age of the participants, sex, or imaging artifacts can bias model predictions, preventing the models from learning relevant brain-phenotype relationships. In this study, we provide a solution called the `DeepRepViz' framework that enables researchers to systematically detect confounders in their DL model predictions. The framework consists of (1) a metric that quantifies the effect of potential confounders and (2) a visualization tool that allows researchers to qualitatively inspect what the DL model is learning. By performing experiments on simulated and neuroimaging datasets, we demonstrate the benefits of using DeepRepViz in combination with DL models. For example, experiments on the neuroimaging datasets reveal that sex is a significant confounder in a DL model predicting chronic alcohol users (Con-score=0.35). Similarly, DeepRepViz identifies age as a confounder in a DL model predicting participants' performance on a cognitive task (Con-score=0.3). Overall, DeepRepViz enables researchers to systematically test for potential confounders and expose DL models that rely on extraneous information such as age, sex, or imaging artifacts.
Benchmark data to study the influence of pre-training on explanation performance in MR image classification
Jun 21, 2023



Convolutional Neural Networks (CNNs) are frequently and successfully used in medical prediction tasks. They are often used in combination with transfer learning, leading to improved performance when training data for the task are scarce. The resulting models are highly complex and typically do not provide any insight into their predictive mechanisms, motivating the field of 'explainable' artificial intelligence (XAI). However, previous studies have rarely quantitatively evaluated the 'explanation performance' of XAI methods against ground-truth data, and transfer learning and its influence on objective measures of explanation performance has not been investigated. Here, we propose a benchmark dataset that allows for quantifying explanation performance in a realistic magnetic resonance imaging (MRI) classification task. We employ this benchmark to understand the influence of transfer learning on the quality of explanations. Experimental results show that popular XAI methods applied to the same underlying model differ vastly in performance, even when considering only correctly classified examples. We further observe that explanation performance strongly depends on the task used for pre-training and the number of CNN layers pre-trained. These results hold after correcting for a substantial correlation between explanation and classification performance.
Promises and pitfalls of deep neural networks in neuroimaging-based psychiatric research
Jan 20, 2023



By promising more accurate diagnostics and individual treatment recommendations, deep neural networks and in particular convolutional neural networks have advanced to a powerful tool in medical imaging. Here, we first give an introduction into methodological key concepts and resulting methodological promises including representation and transfer learning, as well as modelling domain-specific priors. After reviewing recent applications within neuroimaging-based psychiatric research, such as the diagnosis of psychiatric diseases, delineation of disease subtypes, normative modeling, and the development of neuroimaging biomarkers, we discuss current challenges. This includes for example the difficulty of training models on small, heterogeneous and biased data sets, the lack of validity of clinical labels, algorithmic bias, and the influence of confounding variables.
Deep neural network heatmaps capture Alzheimer's disease patterns reported in a large meta-analysis of neuroimaging studies
Jul 22, 2022
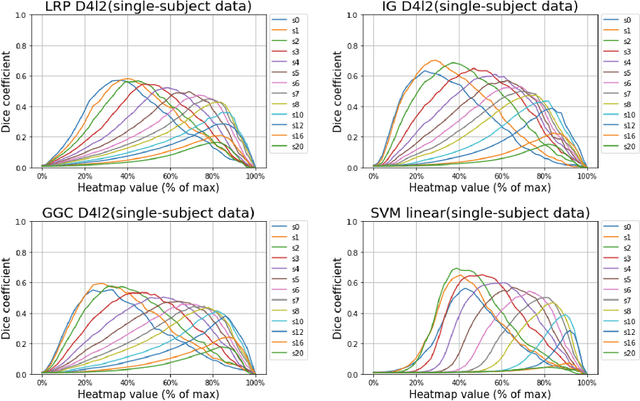
Deep neural networks currently provide the most advanced and accurate machine learning models to distinguish between structural MRI scans of subjects with Alzheimer's disease and healthy controls. Unfortunately, the subtle brain alterations captured by these models are difficult to interpret because of the complexity of these multi-layer and non-linear models. Several heatmap methods have been proposed to address this issue and analyze the imaging patterns extracted from the deep neural networks, but no quantitative comparison between these methods has been carried out so far. In this work, we explore these questions by deriving heatmaps from Convolutional Neural Networks (CNN) trained using T1 MRI scans of the ADNI data set, and by comparing these heatmaps with brain maps corresponding to Support Vector Machines (SVM) coefficients. Three prominent heatmap methods are studied: Layer-wise Relevance Propagation (LRP), Integrated Gradients (IG), and Guided Grad-CAM (GGC). Contrary to prior studies where the quality of heatmaps was visually or qualitatively assessed, we obtained precise quantitative measures by computing overlap with a ground-truth map from a large meta-analysis that combined 77 voxel-based morphometry (VBM) studies independently from ADNI. Our results indicate that all three heatmap methods were able to capture brain regions covering the meta-analysis map and achieved better results than SVM coefficients. Among them, IG produced the heatmaps with the best overlap with the independent meta-analysis.
Feature visualization for convolutional neural network models trained on neuroimaging data
Mar 24, 2022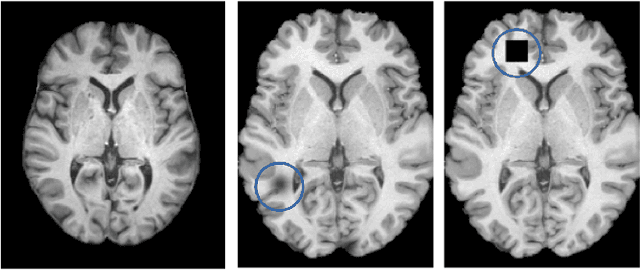
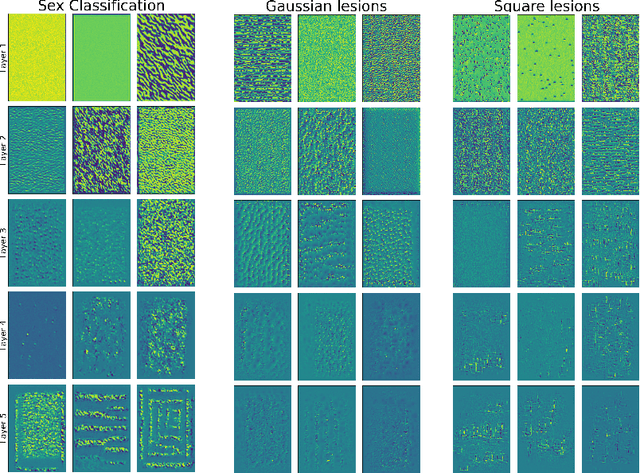
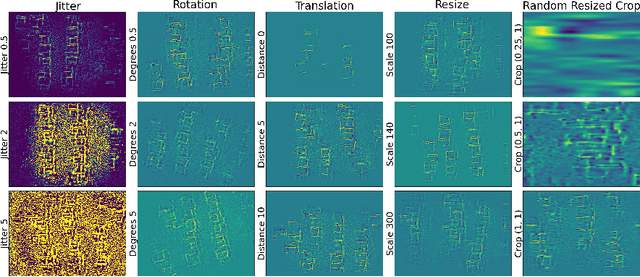
A major prerequisite for the application of machine learning models in clinical decision making is trust and interpretability. Current explainability studies in the neuroimaging community have mostly focused on explaining individual decisions of trained models, e.g. obtained by a convolutional neural network (CNN). Using attribution methods such as layer-wise relevance propagation or SHAP heatmaps can be created that highlight which regions of an input are more relevant for the decision than others. While this allows the detection of potential data set biases and can be used as a guide for a human expert, it does not allow an understanding of the underlying principles the model has learned. In this study, we instead show, to the best of our knowledge, for the first time results using feature visualization of neuroimaging CNNs. Particularly, we have trained CNNs for different tasks including sex classification and artificial lesion classification based on structural magnetic resonance imaging (MRI) data. We have then iteratively generated images that maximally activate specific neurons, in order to visualize the patterns they respond to. To improve the visualizations we compared several regularization strategies. The resulting images reveal the learned concepts of the artificial lesions, including their shapes, but remain hard to interpret for abstract features in the sex classification task.