 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Structure-Aware Completion of Photogrammetric Meshes in Urban Road Environment
Nov 23, 2020


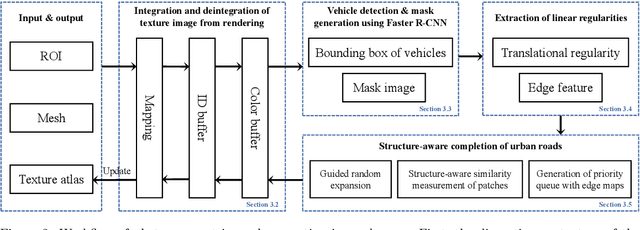

Photogrammetric mesh models obtained from aerial oblique images have been widely used for urban reconstruction. However, the photogrammetric meshes also suffer from severe texture problems, especially on the road areas due to occlusion. This paper proposes a structure-aware completion approach to improve the quality of meshes by removing undesired vehicles on the road seamlessly. Specifically, the discontinuous texture atlas is first integrated to a continuous screen space through rendering by the graphics pipeline; the rendering also records necessary mapping for deintegration to the original texture atlas after editing. Vehicle regions are masked by a standard object detection approach, e.g. Faster RCNN. Then, the masked regions are completed guided by the linear structures and regularities in the road region, which is implemented based on Patch Match. Finally, the completed rendered image is deintegrated to the original texture atlas and the triangles for the vehicles are also flattened for improved meshes. Experimental evaluations and analyses are conducted against three datasets, which are captured with different sensors and ground sample distances. The results reveal that the proposed method can quite realistic meshes after removing the vehicles. The structure-aware completion approach for road regions outperforms popular image completion methods and ablation study further confirms the effectiveness of the linear guidance. It should be noted that the proposed method is also capable to handle tiled mesh models for large-scale scenes. Dataset and code are available at vrlab.org.cn/~hanhu/projects/mesh.
ES-Net: Erasing Salient Parts to Learn More in Re-Identification
Mar 10, 2021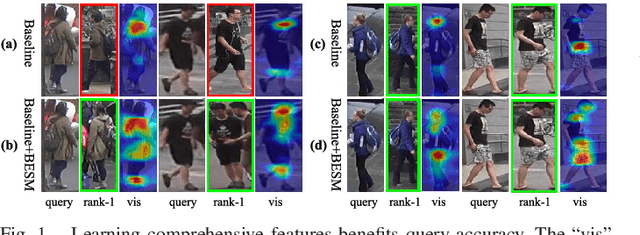
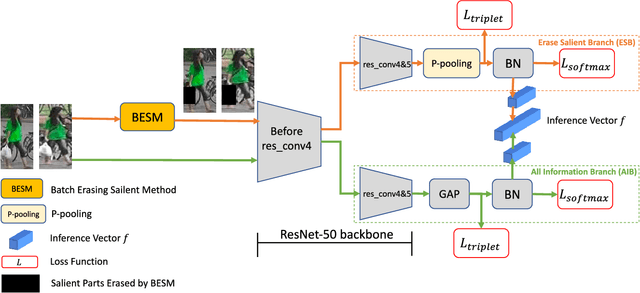
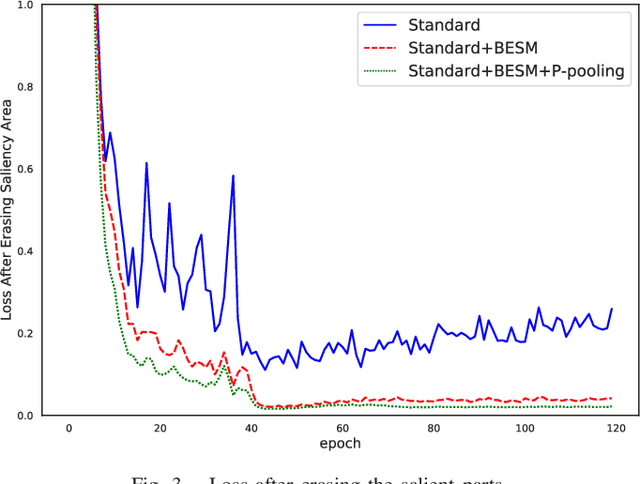

As an instance-level recognition problem, re-identification (re-ID) requires models to capture diverse features. However, with continuous training, re-ID models pay more and more attention to the salient areas. As a result, the model may only focus on few small regions with salient representations and ignore other important information. This phenomenon leads to inferior performance, especially when models are evaluated on small inter-identity variation data. In this paper, we propose a novel network, Erasing-Salient Net (ES-Net), to learn comprehensive features by erasing the salient areas in an image. ES-Net proposes a novel method to locate the salient areas by the confidence of objects and erases them efficiently in a training batch. Meanwhile, to mitigate the over-erasing problem, this paper uses a trainable pooling layer P-pooling that generalizes global max and global average pooling. Experiments are conducted on two specific re-identification tasks (i.e., Person re-ID, Vehicle re-ID). Our ES-Net outperforms state-of-the-art methods on three Person re-ID benchmarks and two Vehicle re-ID benchmarks. Specifically, mAP / Rank-1 rate: 88.6% / 95.7% on Market1501, 78.8% / 89.2% on DuckMTMC-reID, 57.3% / 80.9% on MSMT17, 81.9% / 97.0% on Veri-776, respectively. Rank-1 / Rank-5 rate: 83.6% / 96.9% on VehicleID (Small), 79.9% / 93.5% on VehicleID (Medium), 76.9% / 90.7% on VehicleID (Large), respectively. Moreover, the visualized salient areas show human-interpretable visual explanations for the ranking results.
* 11 pages, 6 figures. Accepted for publication in IEEE Transactions on Image Processing 2021
Supervised Transfer Learning at Scale for Medical Imaging
Jan 21, 2021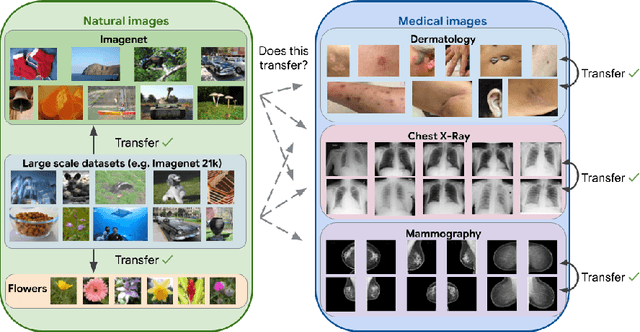
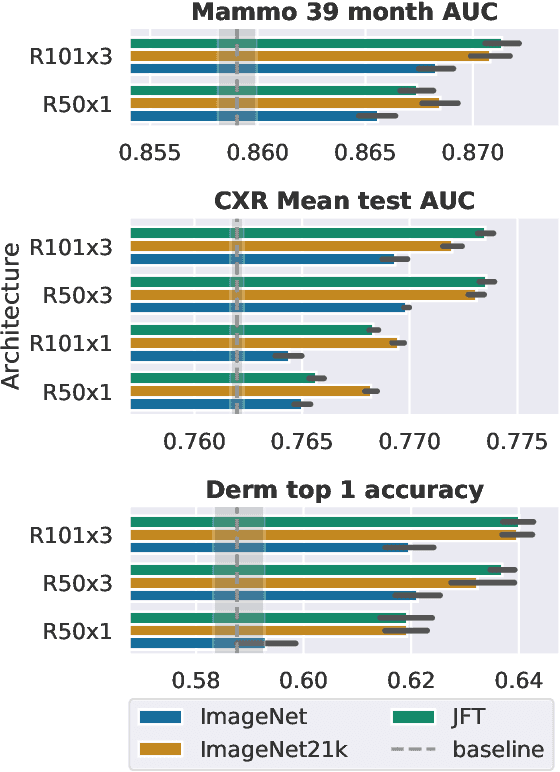
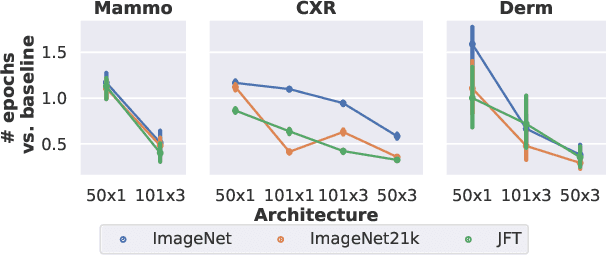
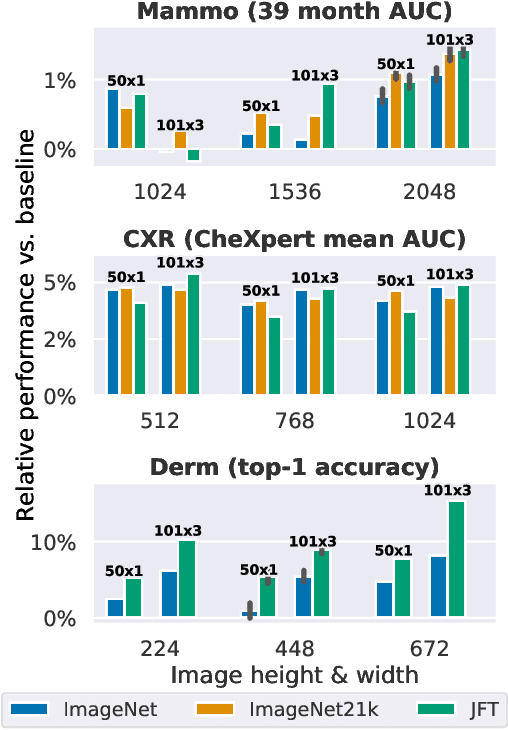
Transfer learning is a standard technique to improve performance on tasks with limited data. However, for medical imaging, the value of transfer learning is less clear. This is likely due to the large domain mismatch between the usual natural-image pre-training (e.g. ImageNet) and medical images. However, recent advances in transfer learning have shown substantial improvements from scale. We investigate whether modern methods can change the fortune of transfer learning for medical imaging. For this, we study the class of large-scale pre-trained networks presented by Kolesnikov et al. on three diverse imaging tasks: chest radiography, mammography, and dermatology. We study both transfer performance and critical properties for the deployment in the medical domain, including: out-of-distribution generalization, data-efficiency, sub-group fairness, and uncertainty estimation. Interestingly, we find that for some of these properties transfer from natural to medical images is indeed extremely effective, but only when performed at sufficient scale.
Cross-View Image Matching for Geo-localization in Urban Environments
Mar 22, 2017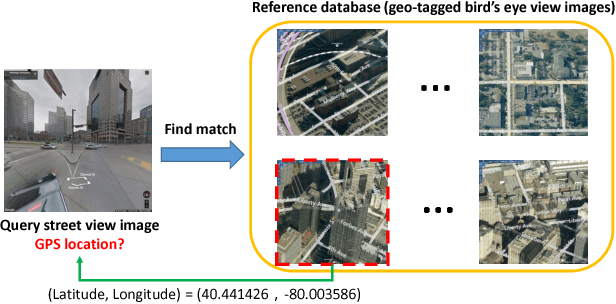
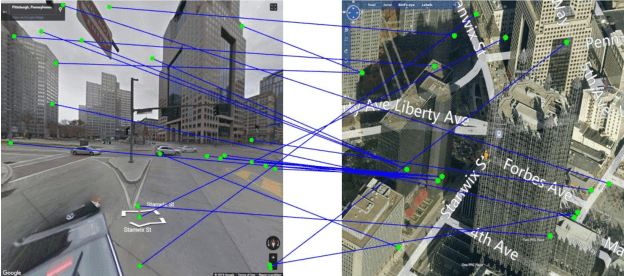


In this paper, we address the problem of cross-view image geo-localization. Specifically, we aim to estimate the GPS location of a query street view image by finding the matching images in a reference database of geo-tagged bird's eye view images, or vice versa. To this end, we present a new framework for cross-view image geo-localization by taking advantage of the tremendous success of deep convolutional neural networks (CNNs) in image classification and object detection. First, we employ the Faster R-CNN to detect buildings in the query and reference images. Next, for each building in the query image, we retrieve the $k$ nearest neighbors from the reference buildings using a Siamese network trained on both positive matching image pairs and negative pairs. To find the correct NN for each query building, we develop an efficient multiple nearest neighbors matching method based on dominant sets. We evaluate the proposed framework on a new dataset that consists of pairs of street view and bird's eye view images. Experimental results show that the proposed method achieves better geo-localization accuracy than other approaches and is able to generalize to images at unseen locations.
An Attention-Driven Approach of No-Reference Image Quality Assessment
May 29, 2017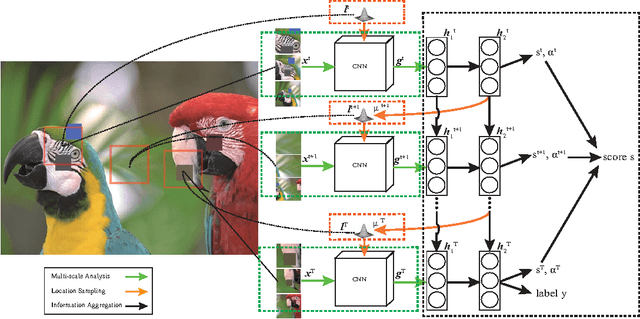
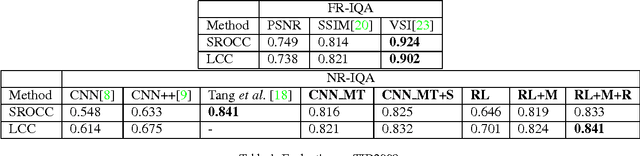
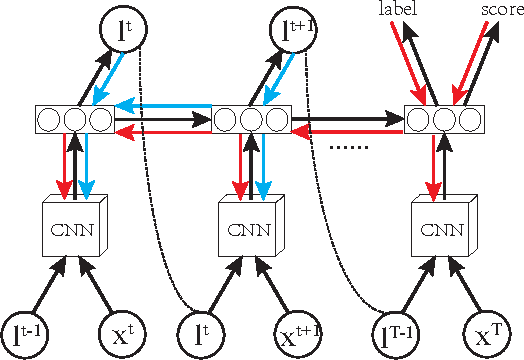
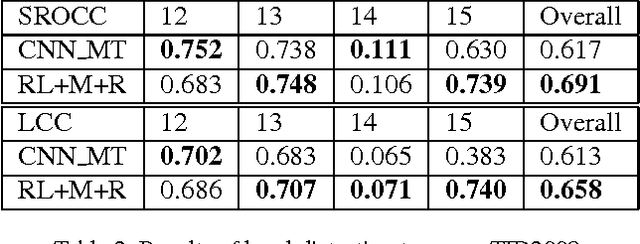
In this paper, we present a novel method of no-reference image quality assessment (NR-IQA), which is to predict the perceptual quality score of a given image without using any reference image. The proposed method harnesses three functions (i) the visual attention mechanism, which affects many aspects of visual perception including image quality assessment, however, is overlooked in the NR-IQA literature. The method assumes that the fixation areas on an image contain key information to the process of IQA. (ii) the robust averaging strategy, which is a means \--- supported by psychology studies \--- to integrating multiple/step-wise evidence to make a final perceptual judgment. (iii) the multi-task learning, which is believed to be an effectual means to shape representation learning and could result in a more generalized model. To exploit the synergy of the three, we consider the NR-IQA as a dynamic perception process, in which the model samples a sequence of "informative" areas and aggregates the information to learn a representation for the tasks of jointly predicting the image quality score and the distortion type. The model learning is implemented by a reinforcement strategy, in which the rewards of both tasks guide the learning of the optimal sampling policy to acquire the "task-informative" image regions so that the predictions can be made accurately and efficiently (in terms of the sampling steps). The reinforcement learning is realized by a deep network with the policy gradient method and trained through back-propagation. In experiments, the model is tested on the TID2008 dataset and it outperforms several state-of-the-art methods. Furthermore, the model is very efficient in the sense that a small number of fixations are used in NR-IQA.
A two-stage data association approach for 3D Multi-object Tracking
Jan 21, 2021
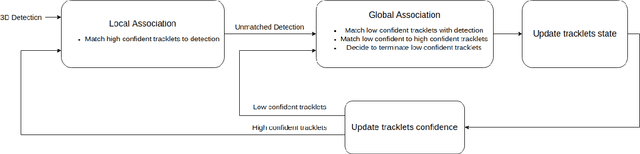
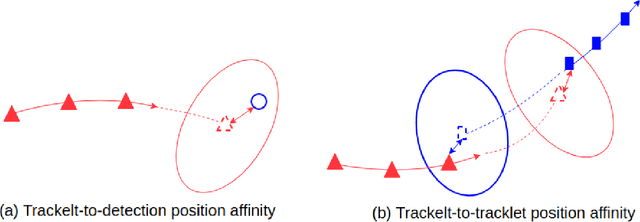
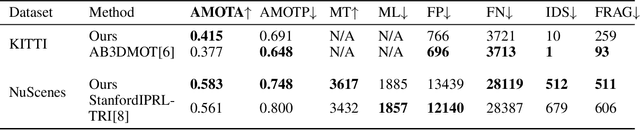
Multi-object tracking (MOT) is an integral part of any autonomous driving pipelines because itproduces trajectories which has been taken by other moving objects in the scene and helps predicttheir future motion. Thanks to the recent advances in 3D object detection enabled by deep learning,track-by-detection has become the dominant paradigm in 3D MOT. In this paradigm, a MOT systemis essentially made of an object detector and a data association algorithm which establishes track-to-detection correspondence. While 3D object detection has been actively researched, associationalgorithms for 3D MOT seem to settle at a bipartie matching formulated as a linear assignmentproblem (LAP) and solved by the Hungarian algorithm. In this paper, we adapt a two-stage dataassociation method which was successful in image-based tracking to the 3D setting, thus providingan alternative for data association for 3D MOT. Our method outperforms the baseline using one-stagebipartie matching for data association by achieving 0.587 AMOTA in NuScenes validation set.
BIKED: A Dataset and Machine Learning Benchmarks for Data-Driven Bicycle Design
Mar 10, 2021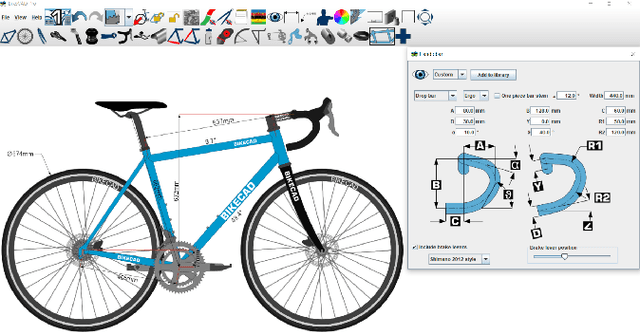
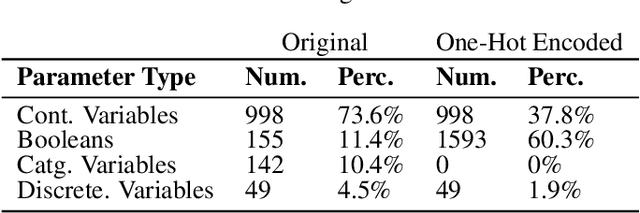

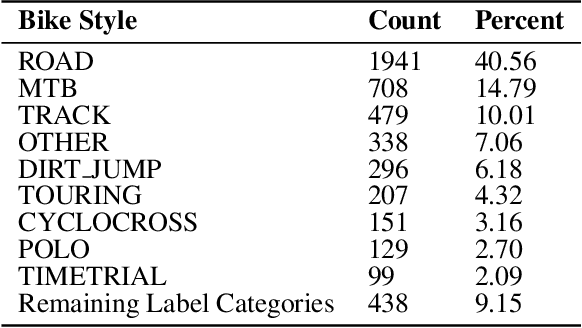
In this paper, we present "BIKED," a dataset comprised of 4500 individually designed bicycle models sourced from hundreds of designers. We expect BIKED to enable a variety of data-driven design applications for bicycles and generally support the development of data-driven design methods. The dataset is comprised of a variety of design information including assembly images, component images, numerical design parameters, and class labels. In this paper, we first discuss the processing of the dataset and present the various features provided. We then illustrate the scale, variety, and structure of the data using several unsupervised clustering studies. Next, we explore a variety of data-driven applications. We provide baseline classification performance for 10 algorithms trained on differing amounts of training data. We then contrast classification performance of three deep neural networks using parametric data, image data, and a combination of the two. Using one of the trained classification models, we conduct a Shapley Additive Explanations Analysis to better understand the extent to which certain design parameters impact classification predictions. Next, we test bike reconstruction and design synthesis using two Variational Autoencoders (VAEs) trained on images and parametric data. We furthermore contrast the performance of interpolation and extrapolation tasks in the original parameter space and the latent space of a VAE. Finally, we discuss some exciting possibilities for other applications beyond the few actively explored in this paper and summarize overall strengths and weaknesses of the dataset.
All at Once Network Quantization via Collaborative Knowledge Transfer
Mar 02, 2021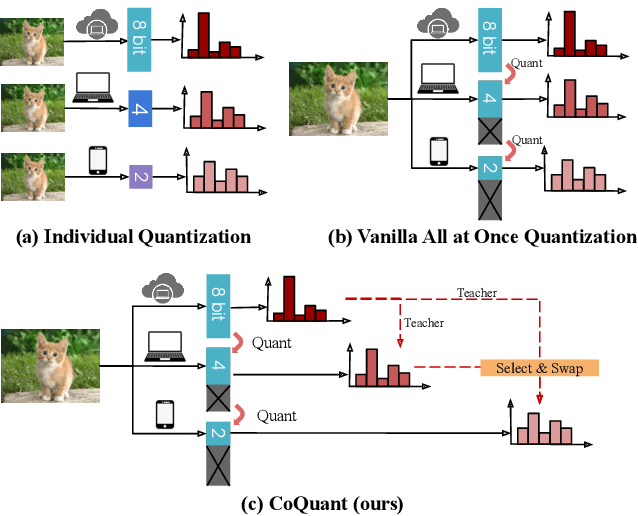
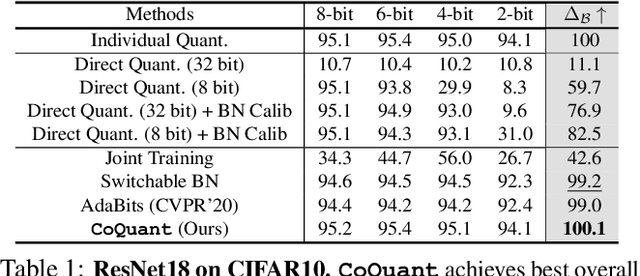
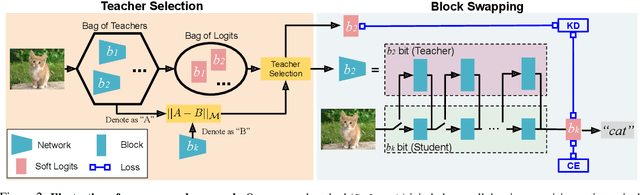
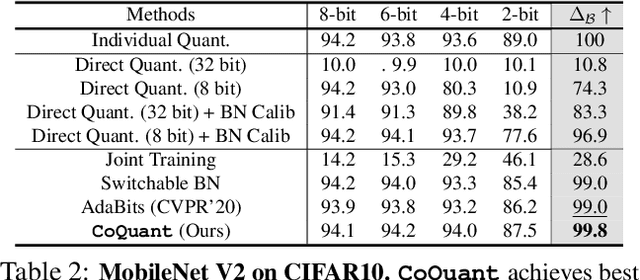
Network quantization has rapidly become one of the most widely used methods to compress and accelerate deep neural networks on edge devices. While existing approaches offer impressive results on common benchmark datasets, they generally repeat the quantization process and retrain the low-precision network from scratch, leading to different networks tailored for different resource constraints. This limits scalable deployment of deep networks in many real-world applications, where in practice dynamic changes in bit-width are often desired. All at Once quantization addresses this problem, by flexibly adjusting the bit-width of a single deep network during inference, without requiring re-training or additional memory to store separate models, for instant adaptation in different scenarios. In this paper, we develop a novel collaborative knowledge transfer approach for efficiently training the all-at-once quantization network. Specifically, we propose an adaptive selection strategy to choose a high-precision \enquote{teacher} for transferring knowledge to the low-precision student while jointly optimizing the model with all bit-widths. Furthermore, to effectively transfer knowledge, we develop a dynamic block swapping method by randomly replacing the blocks in the lower-precision student network with the corresponding blocks in the higher-precision teacher network. Extensive experiments on several challenging and diverse datasets for both image and video classification well demonstrate the efficacy of our proposed approach over state-of-the-art methods.
Grasp-type Recognition Leveraging Object Affordance
Aug 26, 2020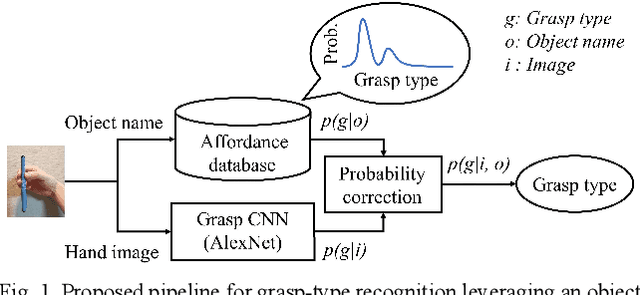
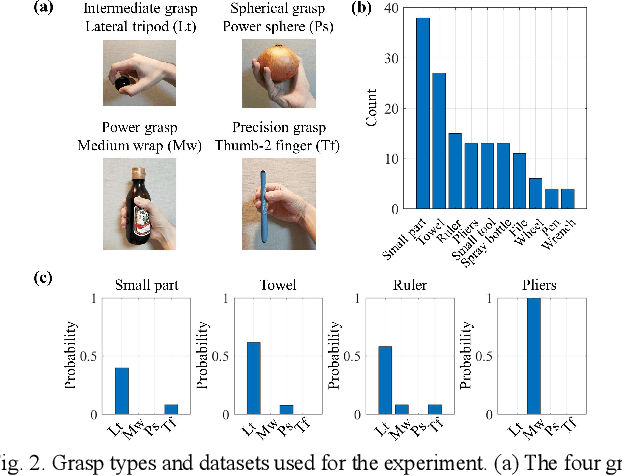
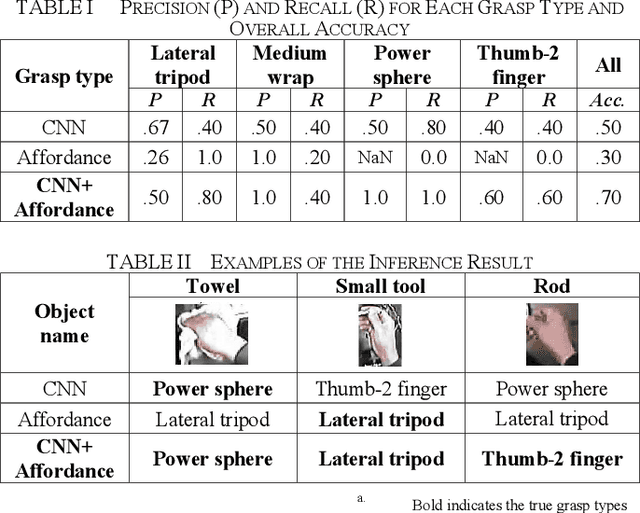
A key challenge in robot teaching is grasp-type recognition with a single RGB image and a target object name. Here, we propose a simple yet effective pipeline to enhance learning-based recognition by leveraging a prior distribution of grasp types for each object. In the pipeline, a convolutional neural network (CNN) recognizes the grasp type from an RGB image. The recognition result is further corrected using the prior distribution (i.e., affordance), which is associated with the target object name. Experimental results showed that the proposed method outperforms both a CNN-only and an affordance-only method. The results highlight the effectiveness of linguistically-driven object affordance for enhancing grasp-type recognition in robot teaching.
MRSaiFE: Tissue Heating Prediction for MRI: a Feasibility Study
Feb 01, 2021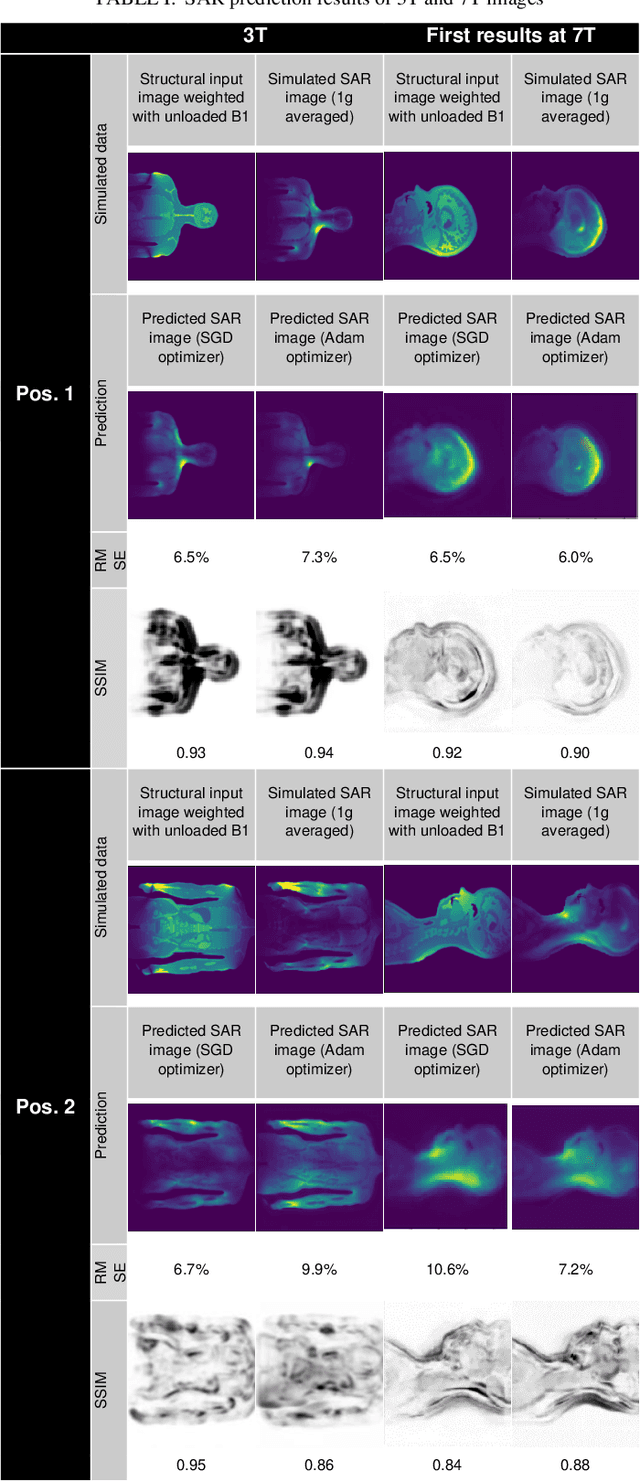
A to-date unsolved and highly limiting safety concern for Ultra High-Field (UHF) magnetic resonance imaging (MRI) is the deposition of radiofrequency (RF) power in the body, quantified by the specific absorption rate (SAR), leading to dangerous tissue heating/damage in the form of local SAR hotspots that cannot currently be measured/monitored, thereby severely limiting the applicability of the technology for clinical practice and in regulatory approval. The goal of this study has been to show proof of concept of an artificial intelligence (AI) based exam-integrated real-time MRI safety prediction software (MRSaiFE) facilitating the safe generation of 3T and 7T images by means of accurate local SAR-monitoring at sub-W/kg levels. We trained the software with a small database of image as a feasibility study and achieved successful proof of concept for both field strengths. SAR patterns were predicted with a residual root mean squared error (RSME) of <11% along with a structural similarity (SSIM) level of >84% for both field strengths (3T and 7T).