 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-View Image Matching for Geo-localization in Urban Environments
Mar 22, 2017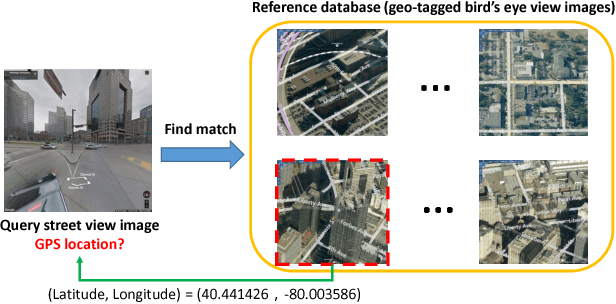
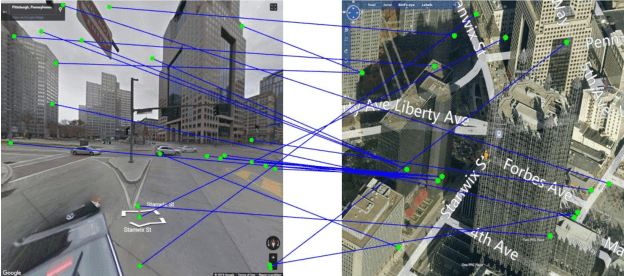


In this paper, we address the problem of cross-view image geo-localization. Specifically, we aim to estimate the GPS location of a query street view image by finding the matching images in a reference database of geo-tagged bird's eye view images, or vice versa. To this end, we present a new framework for cross-view image geo-localization by taking advantage of the tremendous success of deep convolutional neural networks (CNNs) in image classification and object detection. First, we employ the Faster R-CNN to detect buildings in the query and reference images. Next, for each building in the query image, we retrieve the $k$ nearest neighbors from the reference buildings using a Siamese network trained on both positive matching image pairs and negative pairs. To find the correct NN for each query building, we develop an efficient multiple nearest neighbors matching method based on dominant sets. We evaluate the proposed framework on a new dataset that consists of pairs of street view and bird's eye view images. Experimental results show that the proposed method achieves better geo-localization accuracy than other approaches and is able to generalize to images at unseen locations.
On Duality Of Multiple Target Tracking and Segmentation
Oct 14, 2016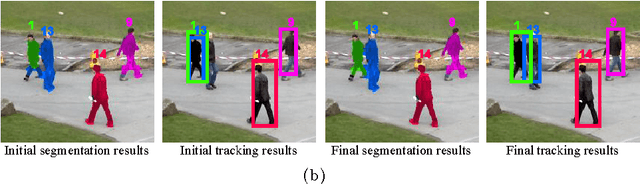
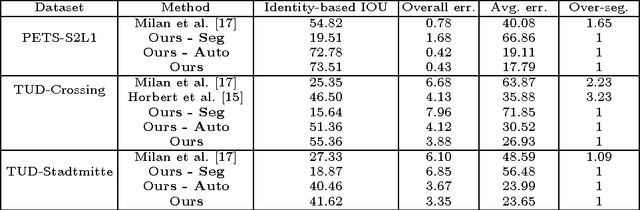

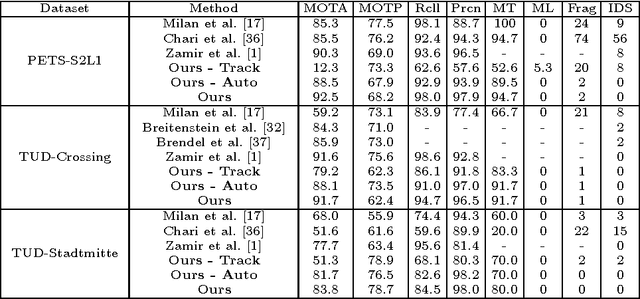
Traditionally, object tracking and segmentation are treated as two separate problems and solved independently. However, in this paper, we argue that tracking and segmentation are actually closely related and solving one should help the other. On one hand, the object track, which is a set of bounding boxes with one bounding box in every frame, would provide strong high-level guidance for the target/background segmentation task. On the other hand, the object segmentation would separate object from other objects and background, which will be useful for determining track locations in every frame. We propose a novel framework which combines online multiple target tracking and segmentation in a video. In our approach, the tracking and segmentation problems are coupled by Lagrange dual decomposition, which leads to more accurate segmentation results and also \emph{helps resolve typical difficulties in multiple target tracking, such as occlusion handling, ID-switch and track drifting}. To track targets, an individual appearance model is learned for each target via structured learning and network flow is employed to generate tracks from densely sampled candidates. For segmentation, multi-label Conditional Random Field (CRF) is applied to a superpixel based spatio-temporal graph in a segment of video to assign background or target labels to every superpixel. The experiments on diverse sequences show that our method outperforms state-of-the-art approaches for multiple target tracking as well as segmentation.