 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
C3VQG: Category Consistent Cyclic Visual Question Generation
May 27, 2020

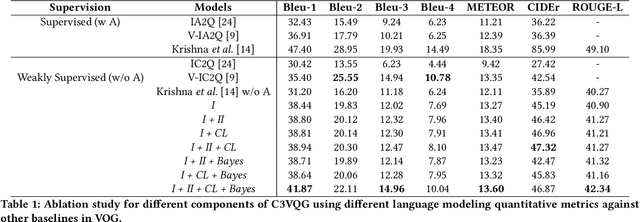
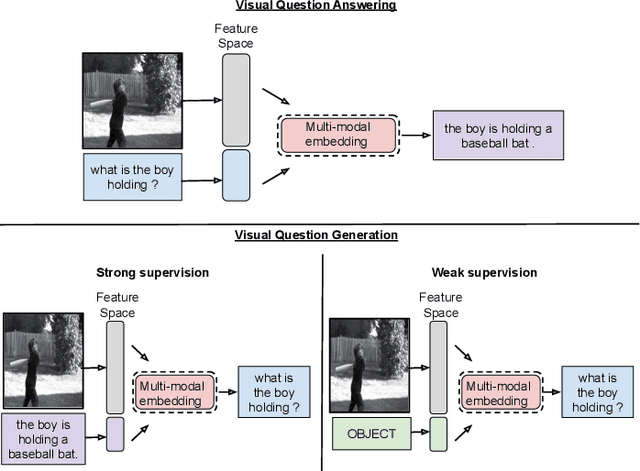
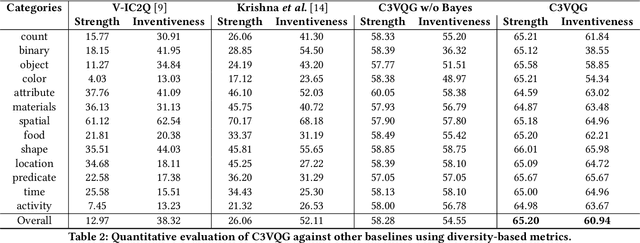
Visual Question Generation (VQG) is the task of generating natural questions based on an image. Popular methods in the past have explored image-to-sequence architectures trained with maximum likelihood which have demonstrated meaningful generated questions given an image and its associated ground-truth answer. VQG becomes more challenging if the image contains rich context information describing its different semantic categories. In this paper, we try to exploit the different visual cues and concepts in an image to generate questions using a variational autoencoder (VAE) without ground-truth answers. Our approach solves two major shortcomings of existing VQG systems: (i) minimize the level of supervision and (ii) replace generic questions with category relevant generations. Most importantly, through eliminating expensive answer annotations, the required supervision is weakened. Using different categories enables us to exploit different concepts as the inference requires only the image and category. Mutual information is maximized between the image, question, and answer category in the latent space of our VAE. A novel category consistent cyclic loss is proposed to enable the model to generate consistent predictions with respect to the answer category, reducing its redundancies and irregularities. Additionally, we also impose supplementary constraints on the latent space of our generative model to provide structure based on categories and enhance generalization by encapsulating decorrelated features within each dimension. Through extensive experiments, the proposed C3VQG outperforms the state-of-the-art visual question generation methods with weak supervision.
Image Inpainting using Block-wise Procedural Training with Annealed Adversarial Counterpart
Mar 28, 2018

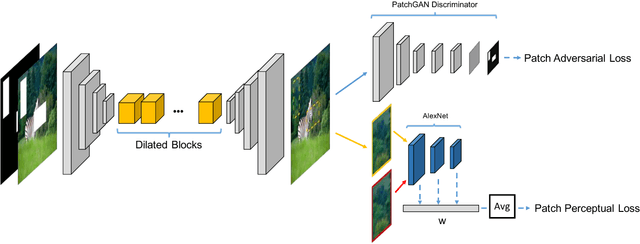
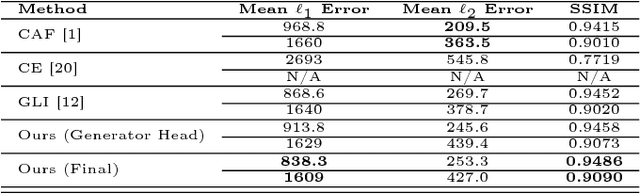
Recent advances in deep generative models have shown promising potential in image inpanting, which refers to the task of predicting missing pixel values of an incomplete image using the known context. However, existing methods can be slow or generate unsatisfying results with easily detectable flaws. In addition, there is often perceivable discontinuity near the holes and require further post-processing to blend the results. We present a new approach to address the difficulty of training a very deep generative model to synthesize high-quality photo-realistic inpainting. Our model uses conditional generative adversarial networks (conditional GANs) as the backbone, and we introduce a novel block-wise procedural training scheme to stabilize the training while we increase the network depth. We also propose a new strategy called adversarial loss annealing to reduce the artifacts. We further describe several losses specifically designed for inpainting and show their effectiveness. Extensive experiments and user-study show that our approach outperforms existing methods in several tasks such as inpainting, face completion and image harmonization. Finally, we show our framework can be easily used as a tool for interactive guided inpainting, demonstrating its practical value to solve common real-world challenges.
Realtime CNN-based Keypoint Detector with Sobel Filter and CNN-based Descriptor Trained with Keypoint Candidates
Nov 04, 2020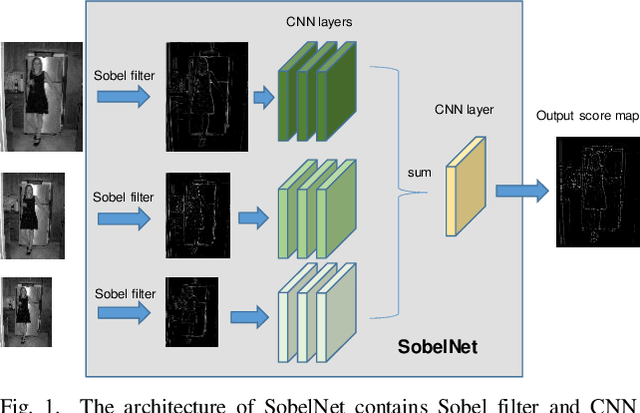
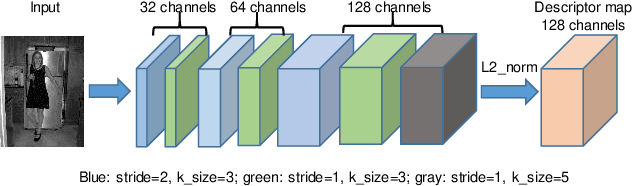
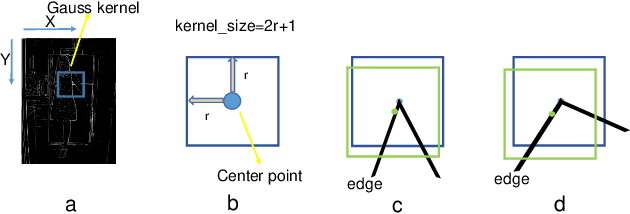
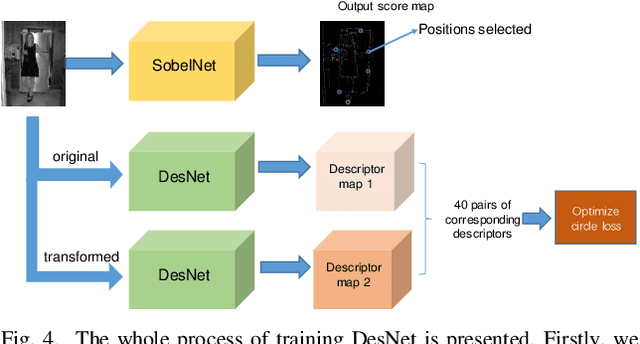
The local feature detector and descriptor are essential in many computer vision tasks, such as SLAM and 3D reconstruction. In this paper, we introduce two separate CNNs, lightweight SobelNet and DesNet, to detect key points and to compute dense local descriptors. The detector and the descriptor work in parallel. Sobel filter provides the edge structure of the input images as the input of CNN. The locations of key points will be obtained after exerting the non-maximum suppression (NMS) process on the output map of the CNN. We design Gaussian loss for the training process of SobelNet to detect corner points as keypoints. At the same time, the input of DesNet is the original grayscale image, and circle loss is used to train DesNet. Besides, output maps of SobelNet are needed while training DesNet. We have evaluated our method on several benchmarks including HPatches benchmark, ETH benchmark, and FM-Bench. SobelNet achieves better or comparable performance with less computation compared with SOTA methods in recent years. The inference time of an image of 640x480 is 7.59ms and 1.09ms for SobelNet and DesNet respectively on RTX 2070 SUPER.
Image Stitching by Line-guided Local Warping with Global Similarity Constraint
Oct 30, 2017

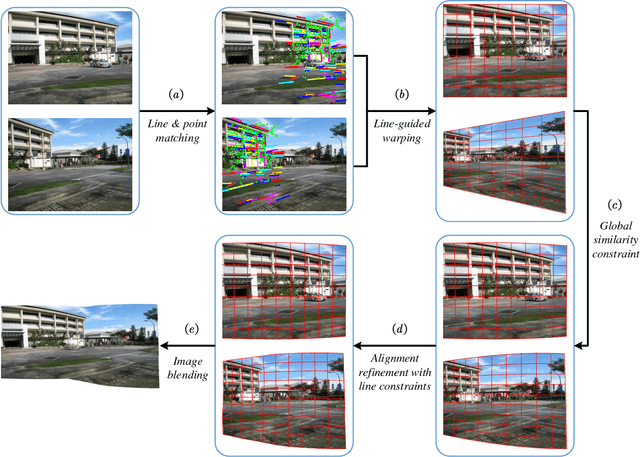
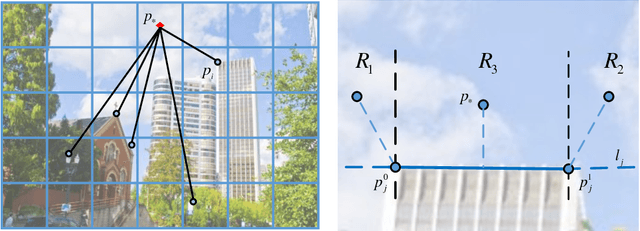
Low-textured image stitching remains a challenging problem. It is difficult to achieve good alignment and it is easy to break image structures due to insufficient and unreliable point correspondences. Moreover, because of the viewpoint variations between multiple images, the stitched images suffer from projective distortions. To solve these problems, this paper presents a line-guided local warping method with a global similarity constraint for image stitching. Line features which serve well for geometric descriptions and scene constraints, are employed to guide image stitching accurately. On one hand, the line features are integrated into a local warping model through a designed weight function. On the other hand, line features are adopted to impose strong geometric constraints, including line correspondence and line colinearity, to improve the stitching performance through mesh optimization. To mitigate projective distortions, we adopt a global similarity constraint, which is integrated with the projective warps via a designed weight strategy. This constraint causes the final warp to slowly change from a projective to a similarity transformation across the image. Finally, the images undergo a two-stage alignment scheme that provides accurate alignment and reduces projective distortion. We evaluate our method on a series of images and compare it with several other methods. The experimental results demonstrate that the proposed method provides a convincing stitching performance and that it outperforms other state-of-the-art methods.
Boosting of Image Denoising Algorithms
Mar 12, 2015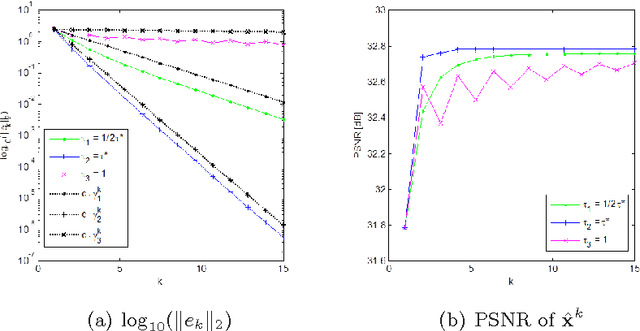


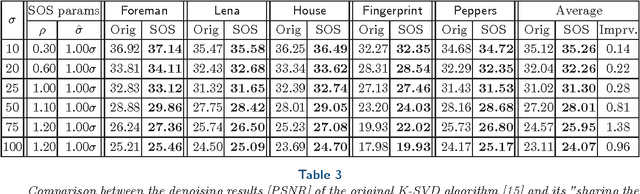
In this paper we propose a generic recursive algorithm for improving image denoising methods. Given the initial denoised image, we suggest repeating the following "SOS" procedure: (i) (S)trengthen the signal by adding the previous denoised image to the degraded input image, (ii) (O)perate the denoising method on the strengthened image, and (iii) (S)ubtract the previous denoised image from the restored signal-strengthened outcome. The convergence of this process is studied for the K-SVD image denoising and related algorithms. Still in the context of K-SVD image denoising, we introduce an interesting interpretation of the SOS algorithm as a technique for closing the gap between the local patch-modeling and the global restoration task, thereby leading to improved performance. In a quest for the theoretical origin of the SOS algorithm, we provide a graph-based interpretation of our method, where the SOS recursive update effectively minimizes a penalty function that aims to denoise the image, while being regularized by the graph Laplacian. We demonstrate the SOS boosting algorithm for several leading denoising methods (K-SVD, NLM, BM3D, and EPLL), showing tendency to further improve denoising performance.
Hyperspectral Image Clustering with Spatially-Regularized Ultrametrics
Apr 10, 2020
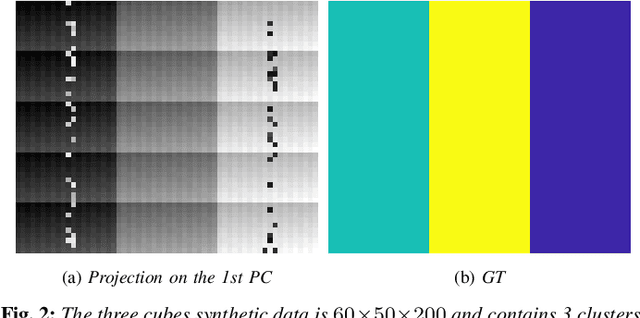


We propose a method for the unsupervised clustering of hyperspectral images based on spatially regularized spectral clustering with ultrametric path distances. The proposed method efficiently combines data density and geometry to distinguish between material classes in the data, without the need for training labels. The proposed method is efficient, with quasilinear scaling in the number of data points, and enjoys robust theoretical performance guarantees. Extensive experiments on synthetic and real HSI data demonstrate its strong performance compared to benchmark and state-of-the-art methods. In particular, the proposed method achieves not only excellent labeling accuracy, but also efficiently estimates the number of clusters.
CLEVR Parser: A Graph Parser Library for Geometric Learning on Language Grounded Image Scenes
Oct 01, 2020

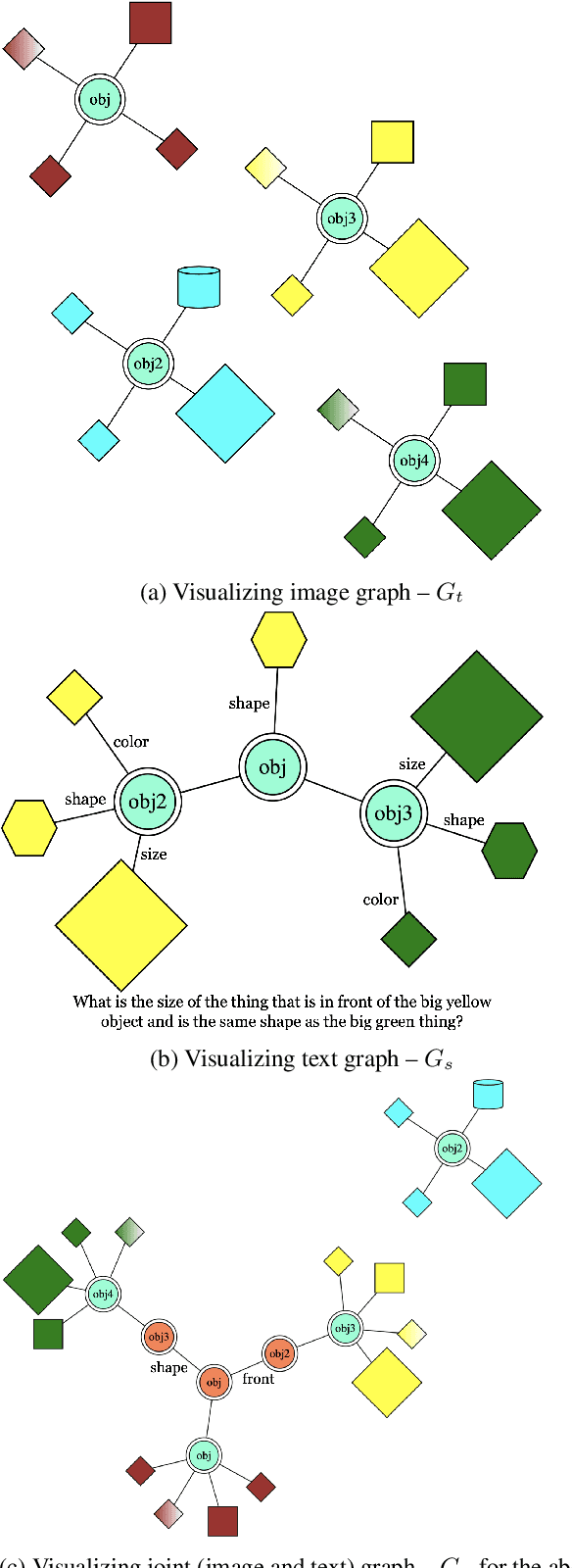
The CLEVR dataset has been used extensively in language grounded visual reasoning in Machine Learning (ML) and Natural Language Processing (NLP) domains. We present a graph parser library for CLEVR, that provides functionalities for object-centric attributes and relationships extraction, and construction of structural graph representations for dual modalities. Structural order-invariant representations enable geometric learning and can aid in downstream tasks like language grounding to vision, robotics, compositionality, interpretability, and computational grammar construction. We provide three extensible main components - parser, embedder, and visualizer that can be tailored to suit specific learning setups. We also provide out-of-the-box functionality for seamless integration with popular deep graph neural network (GNN) libraries. Additionally, we discuss downstream usage and applications of the library, and how it accelerates research for the NLP research community.
Deep Learning based Inter-Modality Image Registration Supervised by Intra-Modality Similarity
Apr 28, 2018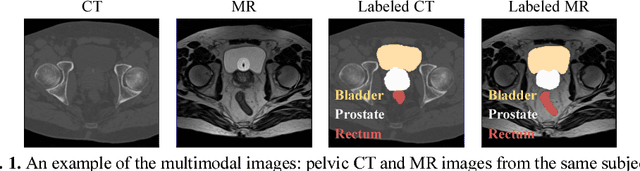
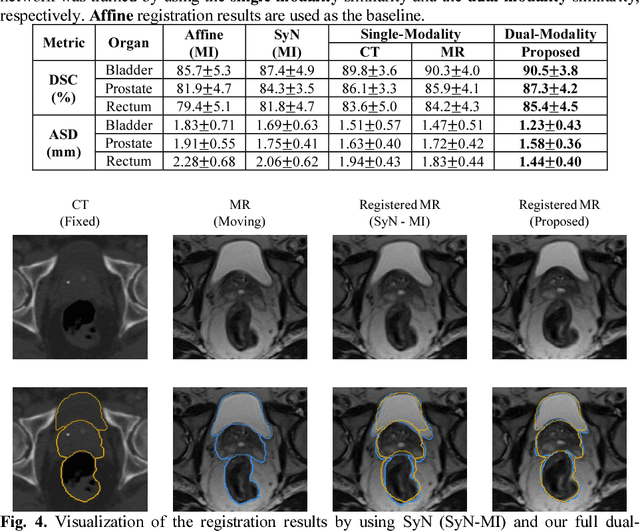

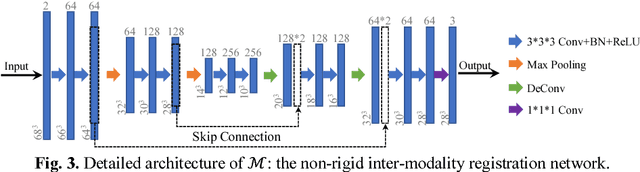
Non-rigid inter-modality registration can facilitate accurate information fusion from different modalities, but it is challenging due to the very different image appearances across modalities. In this paper, we propose to train a non-rigid inter-modality image registration network, which can directly predict the transformation field from the input multimodal images, such as CT and MR images. In particular, the training of our inter-modality registration network is supervised by intra-modality similarity metric based on the available paired data, which is derived from a pre-aligned CT and MR dataset. Specifically, in the training stage, to register the input CT and MR images, their similarity is evaluated on the warped MR image and the MR image that is paired with the input CT. So that, the intra-modality similarity metric can be directly applied to measure whether the input CT and MR images are well registered. Moreover, we use the idea of dual-modality fashion, in which we measure the similarity on both CT modality and MR modality. In this way, the complementary anatomies in both modalities can be jointly considered to more accurately train the inter-modality registration network. In the testing stage, the trained inter-modality registration network can be directly applied to register the new multimodal images without any paired data. Experimental results have shown that, the proposed method can achieve promising accuracy and efficiency for the challenging non-rigid inter-modality registration task and also outperforms the state-of-the-art approaches.
The ND-IRIS-0405 Iris Image Dataset
Jun 15, 2016
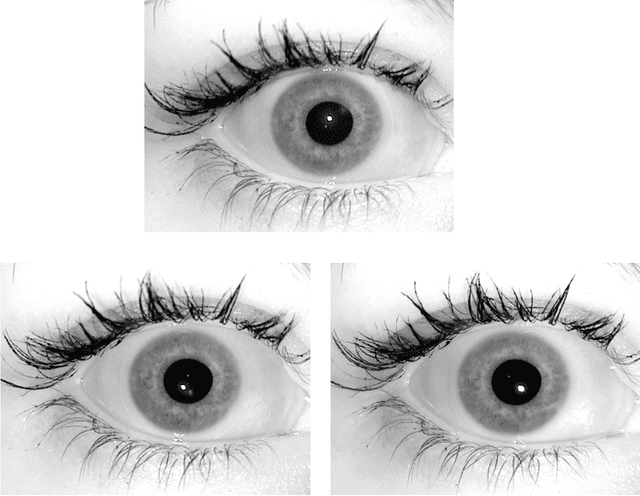
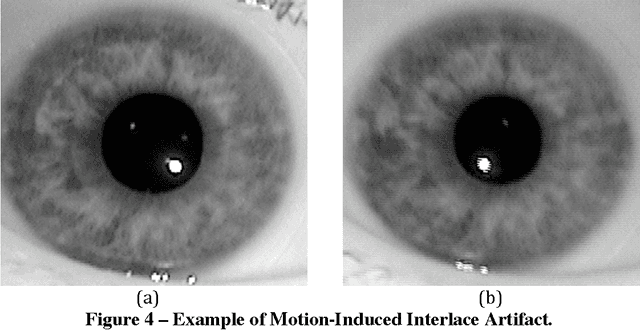
The Computer Vision Research Lab at the University of Notre Dame began collecting iris images in the spring semester of 2004. The initial data collections used an LG 2200 iris imaging system for image acquisition. Image datasets acquired in 2004-2005 at Notre Dame with this LG 2200 have been used in the ICE 2005 and ICE 2006 iris biometric evaluations. The ICE 2005 iris image dataset has been distributed to over 100 research groups around the world. The purpose of this document is to describe the content of the ND-IRIS-0405 iris image dataset. This dataset is a superset of the iris image datasets used in ICE 2005 and ICE 2006. The ND 2004-2005 iris image dataset contains 64,980 images corresponding to 356 unique subjects, and 712 unique irises. The age range of the subjects is 18 to 75 years old. 158 of the subjects are female, and 198 are male. 250 of the subjects are Caucasian, 82 are Asian, and 24 are other ethnicities.
Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection
Mar 02, 2021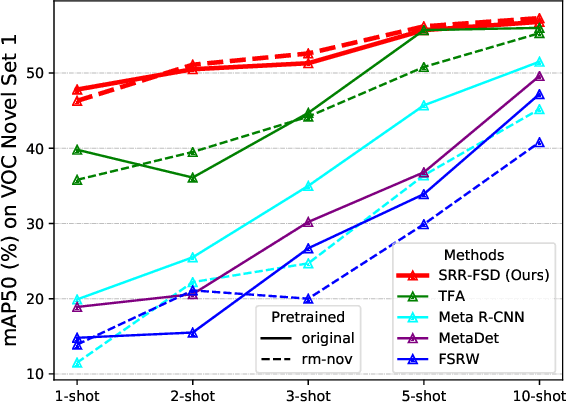
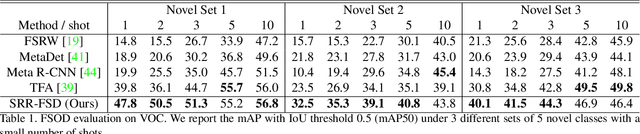
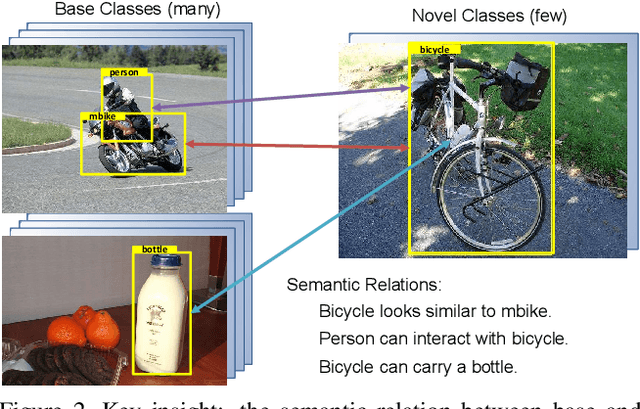
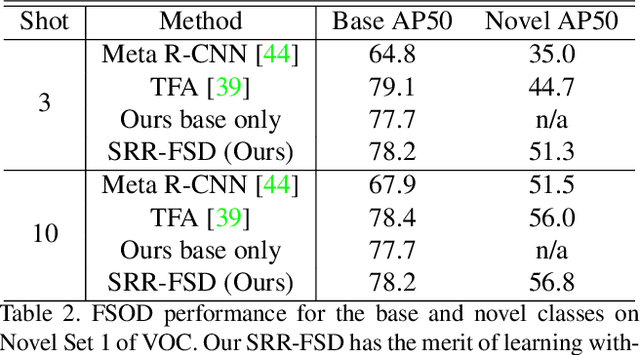
Few-shot object detection is an imperative and long-lasting problem due to the inherent long-tail distribution of real-world data. Its performance is largely affected by the data scarcity of novel classes. But the semantic relation between the novel classes and the base classes is constant regardless of the data availability. In this work, we investigate utilizing this semantic relation together with the visual information and introduce explicit relation reasoning into the learning of novel object detection. Specifically, we represent each class concept by a semantic embedding learned from a large corpus of text. The detector is trained to project the image representations of objects into this embedding space. We also identify the problems of trivially using the raw embeddings with a heuristic knowledge graph and propose to augment the embeddings with a dynamic relation graph. As a result, our few-shot detector, termed SRR-FSD, is robust and stable to the variation of shots of novel objects. Experiments show that SRR-FSD can achieve competitive results at higher shots, and more importantly, a significantly better performance given both lower explicit and implicit shots. The proposed benchmark protocol with implicit shots removed from the pretrained classification dataset can serve as a more realistic setting for future research.