 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Attending Category Disentangled Global Context for Image Classification
Dec 17, 2018
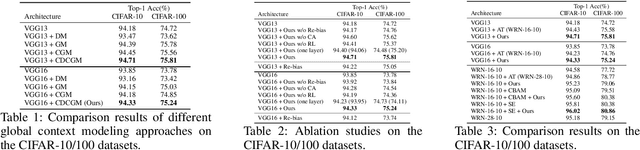
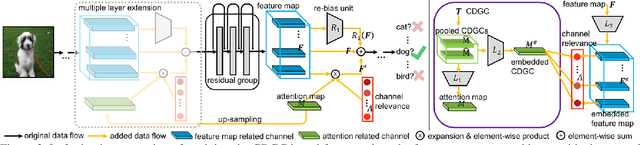
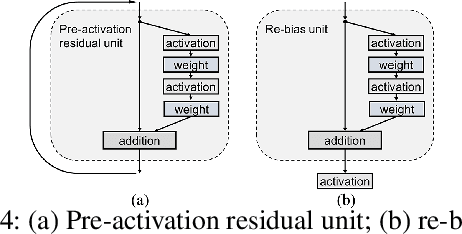
In this paper, we propose a general framework for image classification using the attention mechanism and global context, which could incorporate with various network architectures to improve their performance. To investigate the capability of the global context, we compare four mathematical models and observe the global context encoded in the category disentangled conditional generative model retains the richest complementary information to that in the baseline classification networks. Based on this observation, we define a novel Category Disentangled Global Context (CDGC) and devise a deep network to obtain it. By attending CDGC, the baseline networks could identify the objects of interest more accurately, thus improving the performance. We apply the framework to many different network architectures to demonstrate its effectiveness and versatility. Extensive results on four publicly available datasets validate our approach could generalize well and is superior to the state-of-the-art. In addition, the framework could be combined with various self-attention based methods to further promote the performance. Code and pretrained models will be made public upon paper acceptance.
SiT: Self-supervised vIsion Transformer
Apr 08, 2021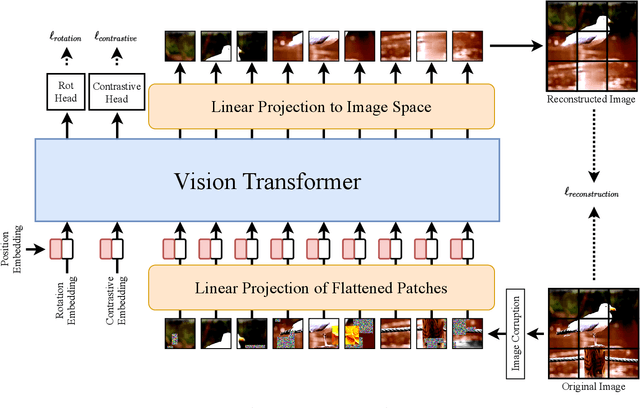
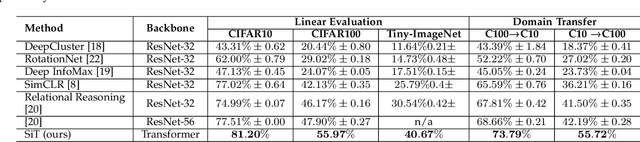

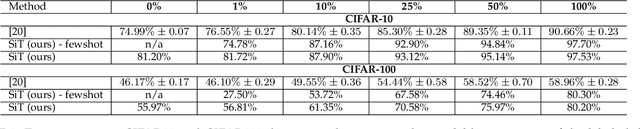
Self-supervised learning methods are gaining increasing traction in computer vision due to their recent success in reducing the gap with supervised learning. In natural language processing (NLP) self-supervised learning and transformers are already the methods of choice. The recent literature suggests that the transformers are becoming increasingly popular also in computer vision. So far, the vision transformers have been shown to work well when pretrained either using a large scale supervised data or with some kind of co-supervision, e.g. in terms of teacher network. These supervised pretrained vision transformers achieve very good results in downstream tasks with minimal changes. In this work we investigate the merits of self-supervised learning for pretraining image/vision transformers and then using them for downstream classification tasks. We propose Self-supervised vIsion Transformers (SiT) and discuss several self-supervised training mechanisms to obtain a pretext model. The architectural flexibility of SiT allows us to use it as an autoencoder and work with multiple self-supervised tasks seamlessly. We show that a pretrained SiT can be finetuned for a downstream classification task on small scale datasets, consisting of a few thousand images rather than several millions. The proposed approach is evaluated on standard datasets using common protocols. The results demonstrate the strength of the transformers and their suitability for self-supervised learning. We outperformed existing self-supervised learning methods by large margin. We also observed that SiT is good for few shot learning and also showed that it is learning useful representation by simply training a linear classifier on top of the learned features from SiT. Pretraining, finetuning, and evaluation codes will be available under: https://github.com/Sara-Ahmed/SiT.
Non-Convex Weighted Lp Nuclear Norm based ADMM Framework for Image Restoration
Jun 27, 2017

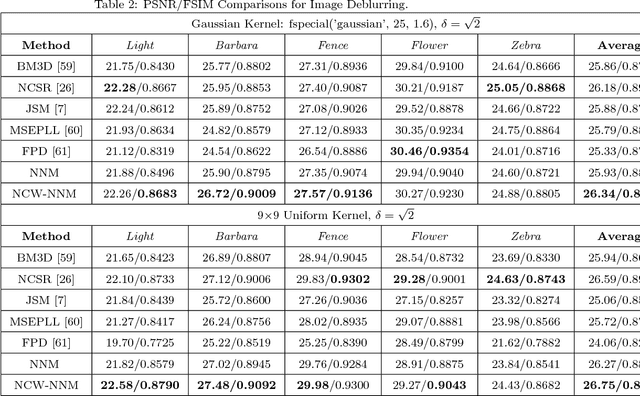

Since the matrix formed by nonlocal similar patches in a natural image is of low rank, the nuclear norm minimization (NNM) has been widely used in various image processing studies. Nonetheless, nuclear norm based convex surrogate of the rank function usually over-shrinks the rank components and makes different components equally, and thus may produce a result far from the optimum. To alleviate the above-mentioned limitations of the nuclear norm, in this paper we propose a new method for image restoration via the non-convex weighted Lp nuclear norm minimization (NCW-NNM), which is able to more accurately enforce the image structural sparsity and self-similarity simultaneously. To make the proposed model tractable and robust, the alternative direction multiplier method (ADMM) is adopted to solve the associated non-convex minimization problem. Experimental results on various types of image restoration problems, including image deblurring, image inpainting and image compressive sensing (CS) recovery, demonstrate that the proposed method outperforms many current state-of-the-art methods in both the objective and the perceptual qualities.
nnU-Net: Breaking the Spell on Successful Medical Image Segmentation
Apr 17, 2019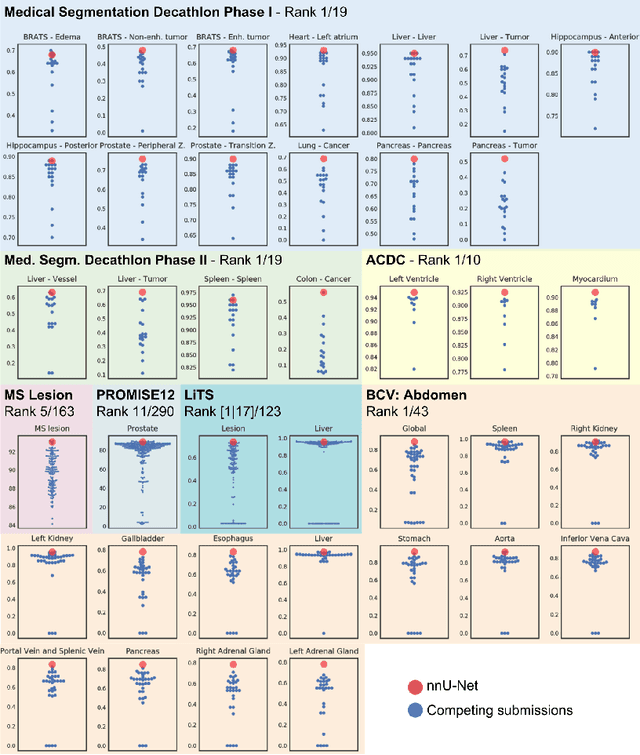

Fueled by the diversity of datasets, semantic segmentation is a popular subfield in medical image analysis with a vast number of new methods being proposed each year. This ever-growing jungle of methodologies, however, becomes increasingly impenetrable. At the same time, many proposed methods fail to generalize beyond the experiments they were demonstrated on, thus hampering the process of developing a segmentation algorithm on a new dataset. Here we present nnU-Net ('no-new-Net'), a framework that automatically adapts itself to any given new dataset. While this process was completely human-driven so far, we make a first attempt to automate necessary adaptations such as preprocessing, the exact patch size, batch size, and inference settings based on the properties of a given dataset. Remarkably, nnU-Net strips away the architectural bells and whistles that are typically proposed in the literature and relies on just a simple U-Net architecture embedded in a robust training scheme. Out of the box, nnU-Net achieves state of the art performance on six well-established segmentation challenges. Source code is available at https://github.com/MIC-DKFZ/nnunet.
On Self-Contact and Human Pose
Apr 08, 2021
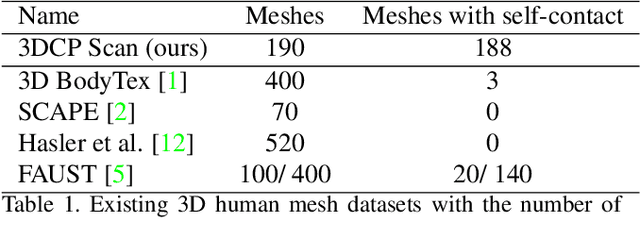
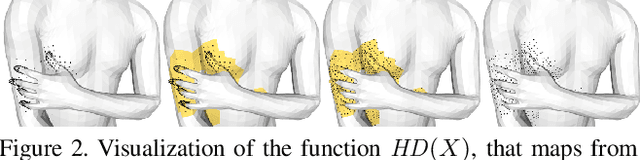

People touch their face 23 times an hour, they cross their arms and legs, put their hands on their hips, etc. While many images of people contain some form of self-contact, current 3D human pose and shape (HPS) regression methods typically fail to estimate this contact. To address this, we develop new datasets and methods that significantly improve human pose estimation with self-contact. First, we create a dataset of 3D Contact Poses (3DCP) containing SMPL-X bodies fit to 3D scans as well as poses from AMASS, which we refine to ensure good contact. Second, we leverage this to create the Mimic-The-Pose (MTP) dataset of images, collected via Amazon Mechanical Turk, containing people mimicking the 3DCP poses with selfcontact. Third, we develop a novel HPS optimization method, SMPLify-XMC, that includes contact constraints and uses the known 3DCP body pose during fitting to create near ground-truth poses for MTP images. Fourth, for more image variety, we label a dataset of in-the-wild images with Discrete Self-Contact (DSC) information and use another new optimization method, SMPLify-DC, that exploits discrete contacts during pose optimization. Finally, we use our datasets during SPIN training to learn a new 3D human pose regressor, called TUCH (Towards Understanding Contact in Humans). We show that the new self-contact training data significantly improves 3D human pose estimates on withheld test data and existing datasets like 3DPW. Not only does our method improve results for self-contact poses, but it also improves accuracy for non-contact poses. The code and data are available for research purposes at https://tuch.is.tue.mpg.de.
Deep Manifold Learning for Dynamic MR Imaging
Mar 09, 2021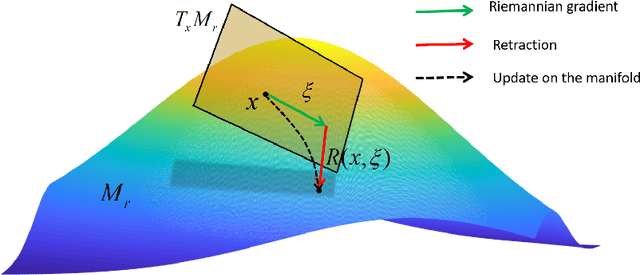
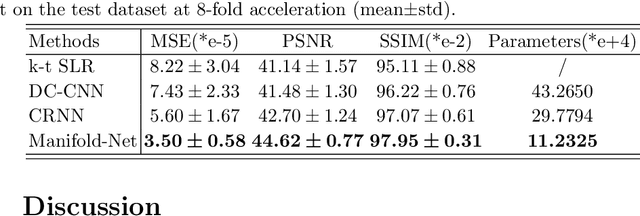
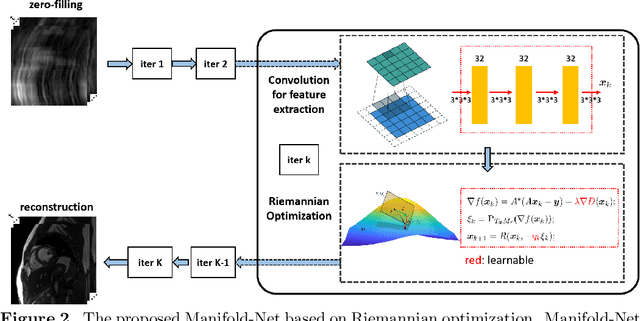
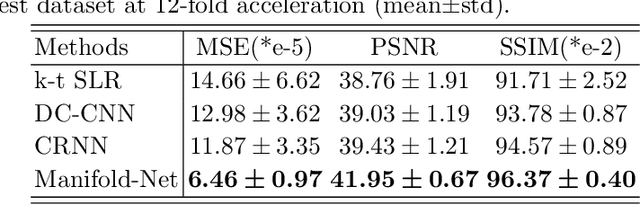
Purpose: To develop a deep learning method on a nonlinear manifold to explore the temporal redundancy of dynamic signals to reconstruct cardiac MRI data from highly undersampled measurements. Methods: Cardiac MR image reconstruction is modeled as general compressed sensing (CS) based optimization on a low-rank tensor manifold. The nonlinear manifold is designed to characterize the temporal correlation of dynamic signals. Iterative procedures can be obtained by solving the optimization model on the manifold, including gradient calculation, projection of the gradient to tangent space, and retraction of the tangent space to the manifold. The iterative procedures on the manifold are unrolled to a neural network, dubbed as Manifold-Net. The Manifold-Net is trained using in vivo data with a retrospective electrocardiogram (ECG)-gated segmented bSSFP sequence. Results: Experimental results at high accelerations demonstrate that the proposed method can obtain improved reconstruction compared with a compressed sensing (CS) method k-t SLR and two state-of-the-art deep learning-based methods, DC-CNN and CRNN. Conclusion: This work represents the first study unrolling the optimization on manifolds into neural networks. Specifically, the designed low-rank manifold provides a new technical route for applying low-rank priors in dynamic MR imaging.
Hardware-Efficient Guided Image Filtering For Multi-Label Problem
Feb 28, 2018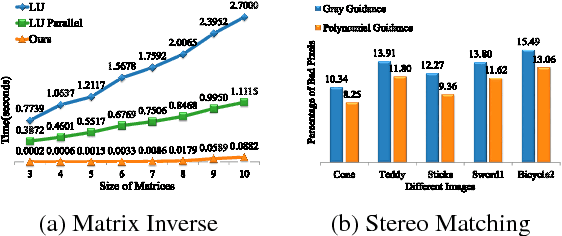


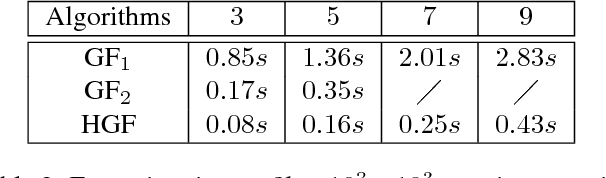
The Guided Filter (GF) is well-known for its linear complexity. However, when filtering an image with an n-channel guidance, GF needs to invert an n x n matrix for each pixel. To the best of our knowledge existing matrix inverse algorithms are inefficient on current hardwares. This shortcoming limits applications of multichannel guidance in computation intensive system such as multi-label system. We need a new GF-like filter that can perform fast multichannel image guided filtering. Since the optimal linear complexity of GF cannot be minimized further, the only way thus is to bring all potentialities of current parallel computing hardwares into full play. In this paper we propose a hardware-efficient Guided Filter (HGF), which solves the efficiency problem of multichannel guided image filtering and yields competent results when applying it to multi-label problems with synthesized polynomial multichannel guidance. Specifically, in order to boost the filtering performance, HGF takes a new matrix inverse algorithm which only involves two hardware-efficient operations: element-wise arithmetic calculations and box filtering. In order to break the linear model restriction, HGF synthesizes a polynomial multichannel guidance to introduce nonlinearity. Benefiting from our polynomial guidance and hardware-efficient matrix inverse algorithm, HGF not only is more sensitive to the underlying structure of guidance but also achieves the fastest computing speed. Due to these merits, HGF obtains state-of-the-art results in terms of accuracy and efficiency in the computation intensive multi-label
Super-resolved Chromatic Mapping of Snapshot Mosaic Image Sensors via a Texture Sensitive Residual Network
Sep 05, 2019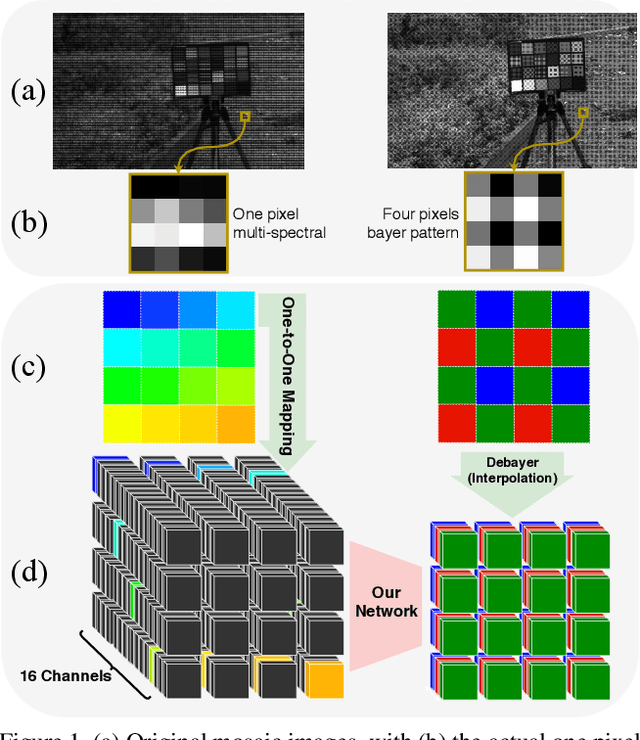
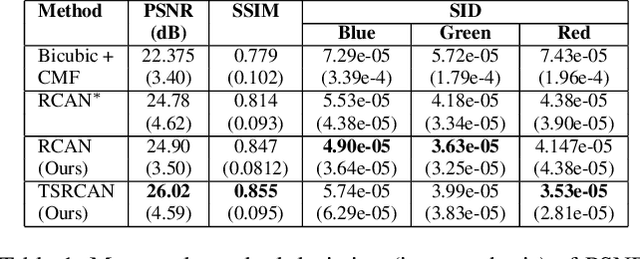
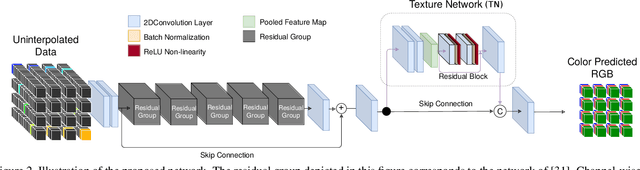
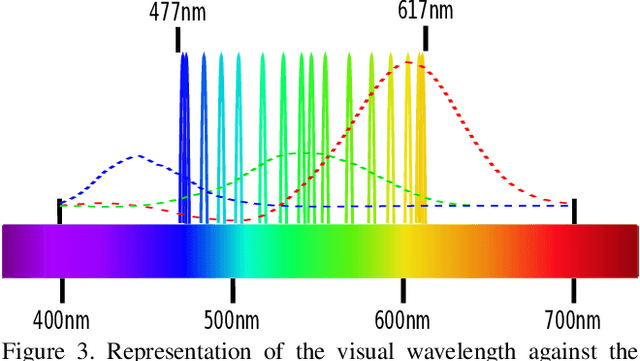
This paper introduces a novel method to simultaneously super-resolve and colour-predict images acquired by snapshot mosaic sensors. These sensors allow for spectral images to be acquired using low-power, small form factor, solid-state CMOS sensors that can operate at video frame rates without the need for complex optical setups. Despite their desirable traits, their main drawback stems from the fact that the spatial resolution of the imagery acquired by these sensors is low. Moreover, chromatic mapping in snapshot mosaic sensors is not straightforward since the bands delivered by the sensor tend to be narrow and unevenly distributed across the range in which they operate. We tackle this drawback as applied to chromatic mapping by using a residual channel attention network equipped with a texture sensitive block. Our method significantly outperforms the traditional approach of interpolating the image and, afterwards, applying a colour matching function. This work establishes state-of-the-art in this domain while also making available to the research community a dataset containing 296 registered stereo multi-spectral/RGB images pairs.
Denoising Diffusion Implicit Models
Oct 06, 2020
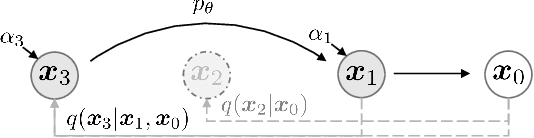

Denoising diffusion probabilistic models (DDPMs) have achieved high quality image generation without adversarial training, yet they require simulating a Markov chain for many steps to produce a sample. To accelerate sampling, we present denoising diffusion implicit models (DDIMs), a more efficient class of iterative implicit probabilistic models with the same training procedure as DDPMs. In DDPMs, the generative process is defined as the reverse of a Markovian diffusion process. We construct a class of non-Markovian diffusion processes that lead to the same training objective, but whose reverse process can be much faster to sample from. We empirically demonstrate that DDIMs can produce high quality samples $10 \times$ to $50 \times$ faster in terms of wall-clock time compared to DDPMs, allow us to trade off computation for sample quality, and can perform semantically meaningful image interpolation directly in the latent space.
Non-rigid image registration using fully convolutional networks with deep self-supervision
Sep 04, 2017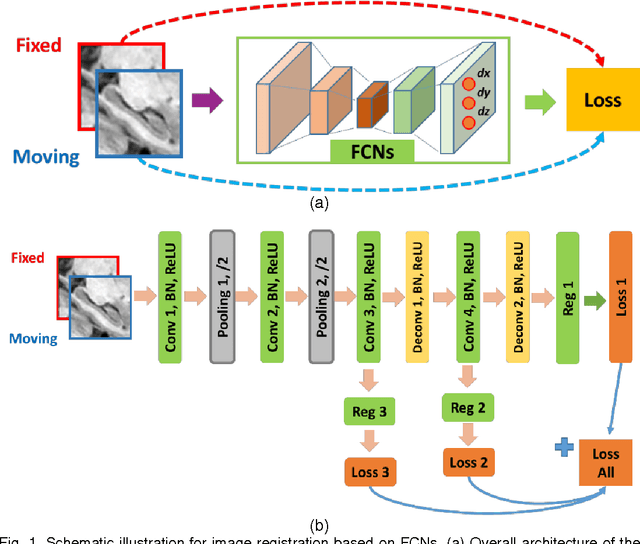
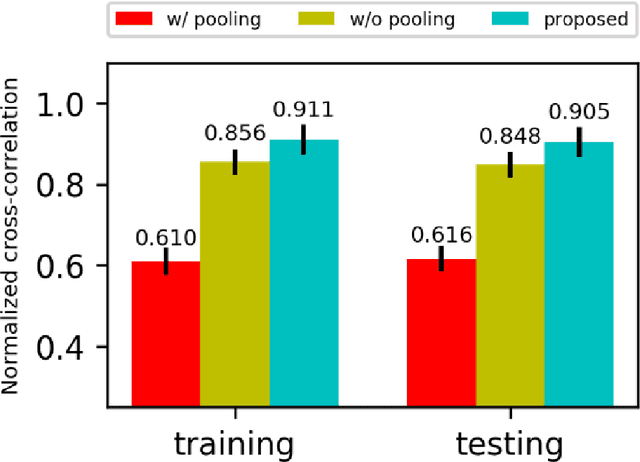
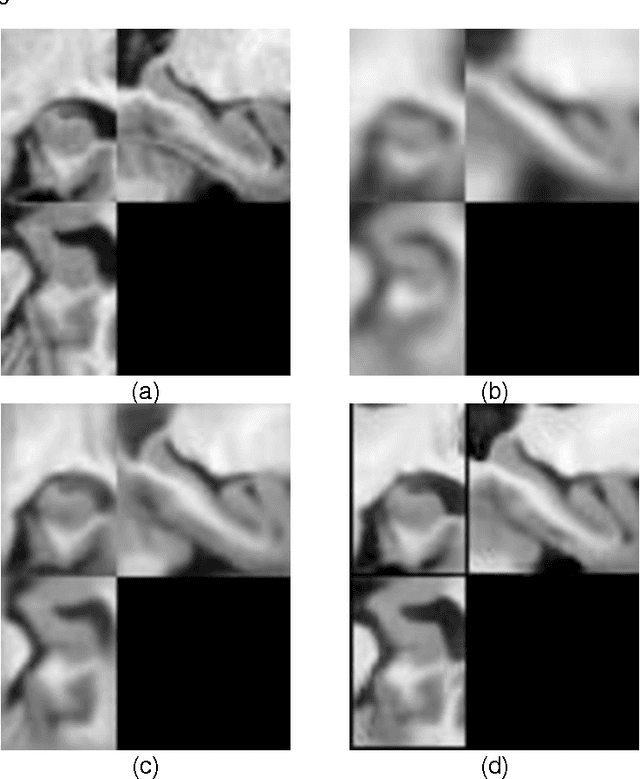
We propose a novel non-rigid image registration algorithm that is built upon fully convolutional networks (FCNs) to optimize and learn spatial transformations between pairs of images to be registered. Different from most existing deep learning based image registration methods that learn spatial transformations from training data with known corresponding spatial transformations, our method directly estimates spatial transformations between pairs of images by maximizing an image-wise similarity metric between fixed and deformed moving images, similar to conventional image registration algorithms. At the same time, our method also learns FCNs for encoding the spatial transformations at the same spatial resolution of images to be registered, rather than learning coarse-grained spatial transformation information. The image registration is implemented in a multi-resolution image registration framework to jointly optimize and learn spatial transformations and FCNs at different resolutions with deep self-supervision through typical feedforward and backpropagation computation. Since our method simultaneously optimizes and learns spatial transformations for the image registration, our method can be directly used to register a pair of images, and the registration of a set of images is also a training procedure for FCNs so that the trained FCNs can be directly adopted to register new images by feedforward computation of the learned FCNs without any optimization. The proposed method has been evaluated for registering 3D structural brain magnetic resonance (MR) images and obtained better performance than state-of-the-art image registration algorithms.