 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PlaneRCNN: 3D Plane Detection and Reconstruction from a Single Image
Jan 08, 2019
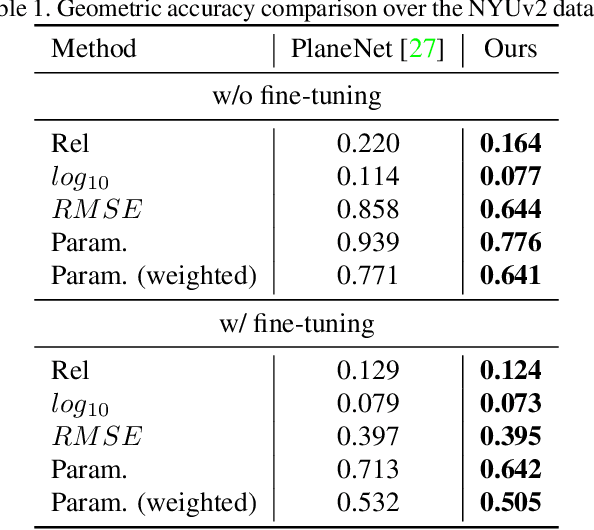
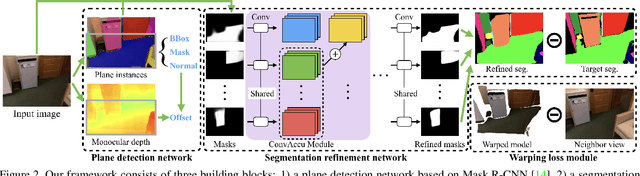
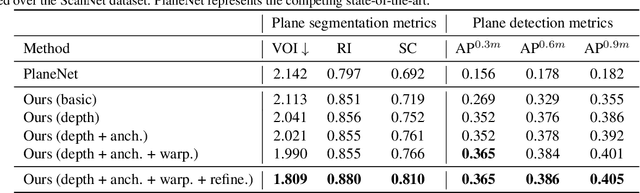

This paper proposes a deep neural architecture, PlaneRCNN, that detects and reconstructs piecewise planar surfaces from a single RGB image. PlaneRCNN employs a variant of Mask R-CNN to detect planes with their plane parameters and segmentation masks. PlaneRCNN then jointly refines all the segmentation masks with a novel loss enforcing the consistency with a nearby view during training. The paper also presents a new benchmark with more fine-grained plane segmentations in the ground-truth, in which, PlaneRCNN outperforms existing state-of-the-art methods with significant margins in the plane detection, segmentation, and reconstruction metrics. PlaneRCNN makes an important step towards robust plane extraction, which would have an immediate impact on a wide range of applications including Robotics, Augmented Reality, and Virtual Reality.
FloodNet: A High Resolution Aerial Imagery Dataset for Post Flood Scene Understanding
Dec 05, 2020
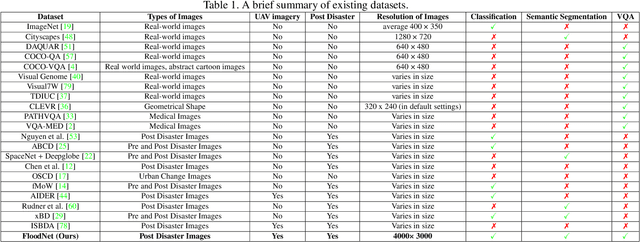
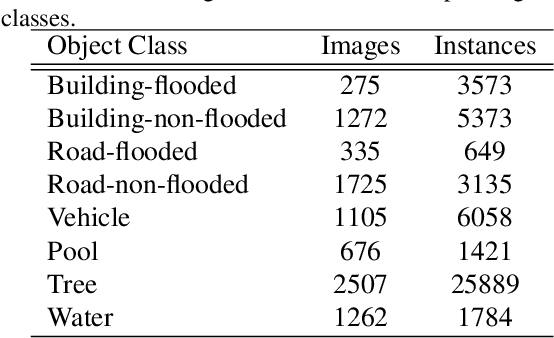
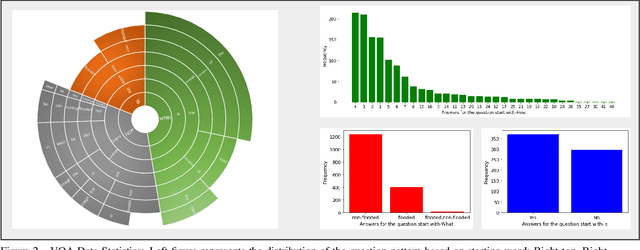
Visual scene understanding is the core task in making any crucial decision in any computer vision system. Although popular computer vision datasets like Cityscapes, MS-COCO, PASCAL provide good benchmarks for several tasks (e.g. image classification, segmentation, object detection), these datasets are hardly suitable for post disaster damage assessments. On the other hand, existing natural disaster datasets include mainly satellite imagery which have low spatial resolution and a high revisit period. Therefore, they do not have a scope to provide quick and efficient damage assessment tasks. Unmanned Aerial Vehicle(UAV) can effortlessly access difficult places during any disaster and collect high resolution imagery that is required for aforementioned tasks of computer vision. To address these issues we present a high resolution UAV imagery, FloodNet, captured after the hurricane Harvey. This dataset demonstrates the post flooded damages of the affected areas. The images are labeled pixel-wise for semantic segmentation task and questions are produced for the task of visual question answering. FloodNet poses several challenges including detection of flooded roads and buildings and distinguishing between natural water and flooded water. With the advancement of deep learning algorithms, we can analyze the impact of any disaster which can make a precise understanding of the affected areas. In this paper, we compare and contrast the performances of baseline methods for image classification, semantic segmentation, and visual question answering on our dataset.
More Reliable AI Solution: Breast Ultrasound Diagnosis Using Multi-AI Combination
Jan 07, 2021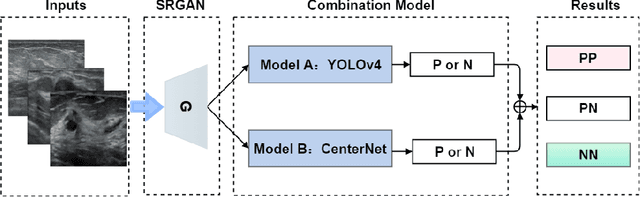
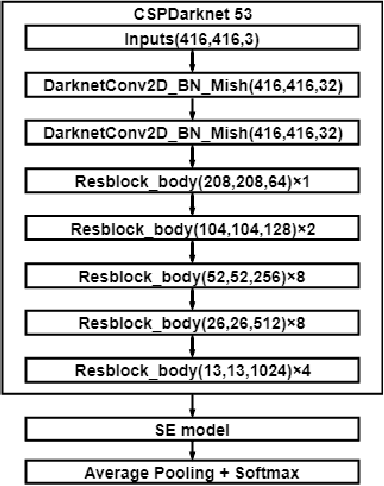

Objective: Breast cancer screening is of great significance in contemporary women's health prevention. The existing machines embedded in the AI system do not reach the accuracy that clinicians hope. How to make intelligent systems more reliable is a common problem. Methods: 1) Ultrasound image super-resolution: the SRGAN super-resolution network reduces the unclearness of ultrasound images caused by the device itself and improves the accuracy and generalization of the detection model. 2) In response to the needs of medical images, we have improved the YOLOv4 and the CenterNet models. 3) Multi-AI model: based on the respective advantages of different AI models, we employ two AI models to determine clinical resuls cross validation. And we accept the same results and refuses others. Results: 1) With the help of the super-resolution model, the YOLOv4 model and the CenterNet model both increased the mAP score by 9.6% and 13.8%. 2) Two methods for transforming the target model into a classification model are proposed. And the unified output is in a specified format to facilitate the call of the molti-AI model. 3) In the classification evaluation experiment, concatenated by the YOLOv4 model (sensitivity 57.73%, specificity 90.08%) and the CenterNet model (sensitivity 62.64%, specificity 92.54%), the multi-AI model will refuse to make judgments on 23.55% of the input data. Correspondingly, the performance has been greatly improved to 95.91% for the sensitivity and 96.02% for the specificity. Conclusion: Our work makes the AI model more reliable in medical image diagnosis. Significance: 1) The proposed method makes the target detection model more suitable for diagnosing breast ultrasound images. 2) It provides a new idea for artificial intelligence in medical diagnosis, which can more conveniently introduce target detection models from other fields to serve medical lesion screening.
Label-driven weakly-supervised learning for multimodal deformable image registration
Dec 24, 2017Spatially aligning medical images from different modalities remains a challenging task, especially for intraoperative applications that require fast and robust algorithms. We propose a weakly-supervised, label-driven formulation for learning 3D voxel correspondence from higher-level label correspondence, thereby bypassing classical intensity-based image similarity measures. During training, a convolutional neural network is optimised by outputting a dense displacement field (DDF) that warps a set of available anatomical labels from the moving image to match their corresponding counterparts in the fixed image. These label pairs, including solid organs, ducts, vessels, point landmarks and other ad hoc structures, are only required at training time and can be spatially aligned by minimising a cross-entropy function of the warped moving label and the fixed label. During inference, the trained network takes a new image pair to predict an optimal DDF, resulting in a fully-automatic, label-free, real-time and deformable registration. For interventional applications where large global transformation prevails, we also propose a neural network architecture to jointly optimise the global- and local displacements. Experiment results are presented based on cross-validating registrations of 111 pairs of T2-weighted magnetic resonance images and 3D transrectal ultrasound images from prostate cancer patients with a total of over 4000 anatomical labels, yielding a median target registration error of 4.2 mm on landmark centroids and a median Dice of 0.88 on prostate glands.
CheXseg: Combining Expert Annotations with DNN-generated Saliency Maps for X-ray Segmentation
Feb 21, 2021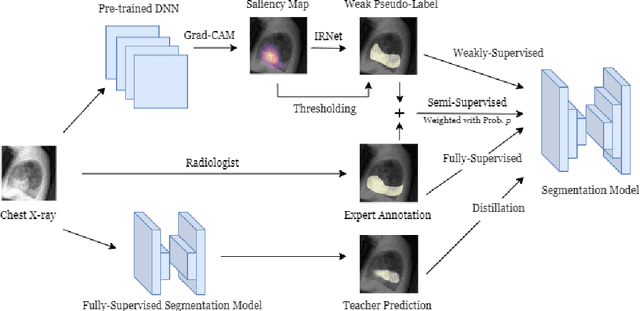
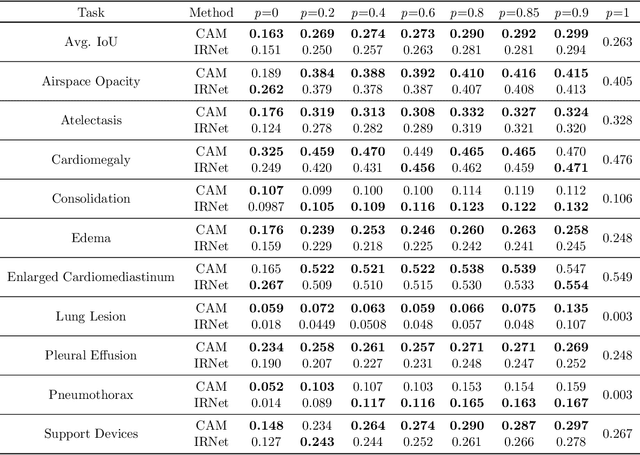
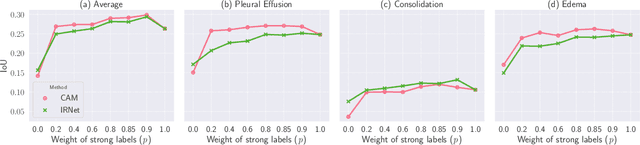
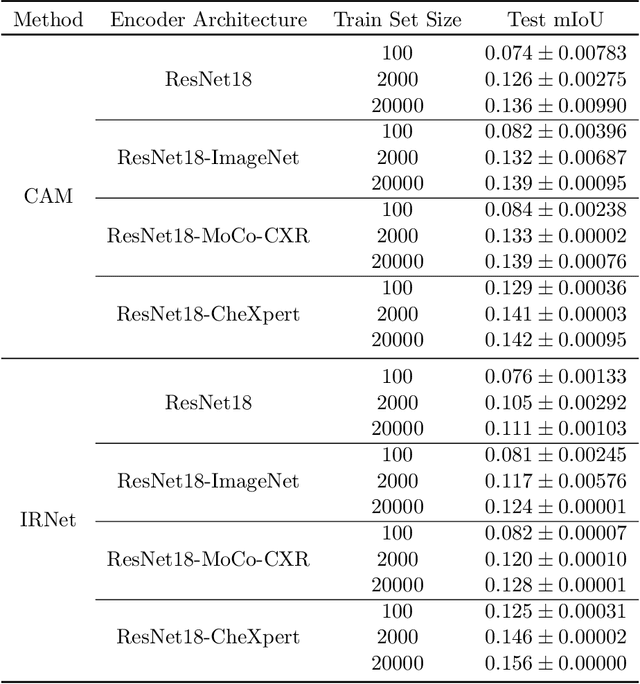
Medical image segmentation models are typically supervised by expert annotations at the pixel-level, which can be expensive to acquire. In this work, we propose a method that combines the high quality of pixel-level expert annotations with the scale of coarse DNN-generated saliency maps for training multi-label semantic segmentation models. We demonstrate the application of our semi-supervised method, which we call CheXseg, on multi-label chest x-ray interpretation. We find that CheXseg improves upon the performance (mIoU) of fully-supervised methods that use only pixel-level expert annotations by 13.4% and weakly-supervised methods that use only DNN-generated saliency maps by 91.2%. Furthermore, we implement a semi-supervised method using knowledge distillation and find that though it is outperformed by CheXseg, it exceeds the performance (mIoU) of the best fully-supervised method by 4.83%. Our best method is able to match radiologist agreement on three out of ten pathologies and reduces the overall performance gap by 71.6% as compared to weakly-supervised methods.
Variational Inference for Deblending Crowded Starfields
Feb 04, 2021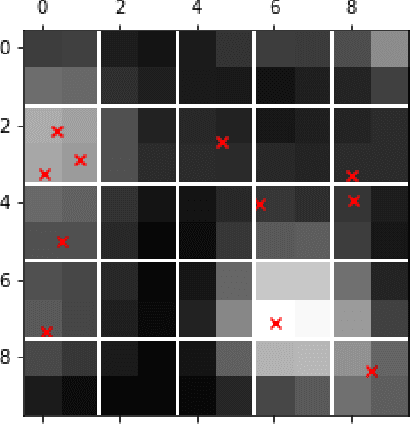
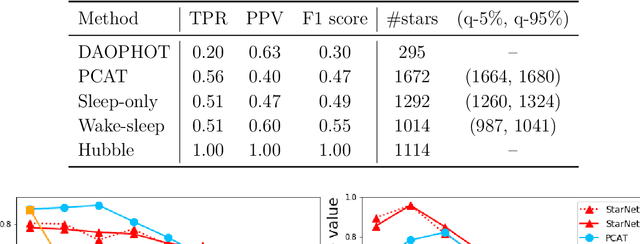
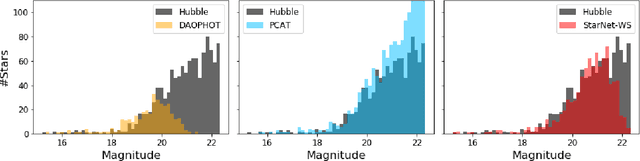
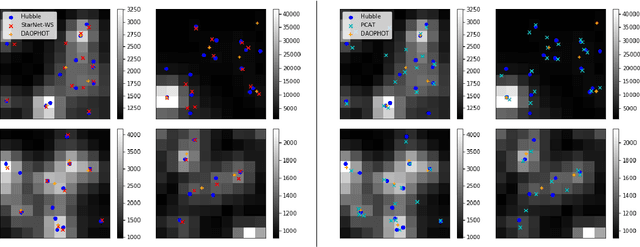
In the image data collected by astronomical surveys, stars and galaxies often overlap. Deblending is the task of distinguishing and characterizing individual light sources from survey images. We propose StarNet, a fully Bayesian method to deblend sources in astronomical images of crowded star fields. StarNet leverages recent advances in variational inference, including amortized variational distributions and the wake-sleep algorithm. Wake-sleep, which minimizes forward KL divergence, has significant benefits compared to traditional variational inference, which minimizes a reverse KL divergence. In our experiments with SDSS images of the M2 globular cluster, StarNet is substantially more accurate than two competing methods: Probablistic Cataloging (PCAT), a method that uses MCMC for inference, and a software pipeline employed by SDSS for deblending (DAOPHOT). In addition, StarNet is as much as $100,000$ times faster than PCAT, exhibiting the scaling characteristics necessary to perform fully Bayesian inference on modern astronomical surveys.
RIFT: Multi-modal Image Matching Based on Radiation-invariant Feature Transform
Apr 25, 2018

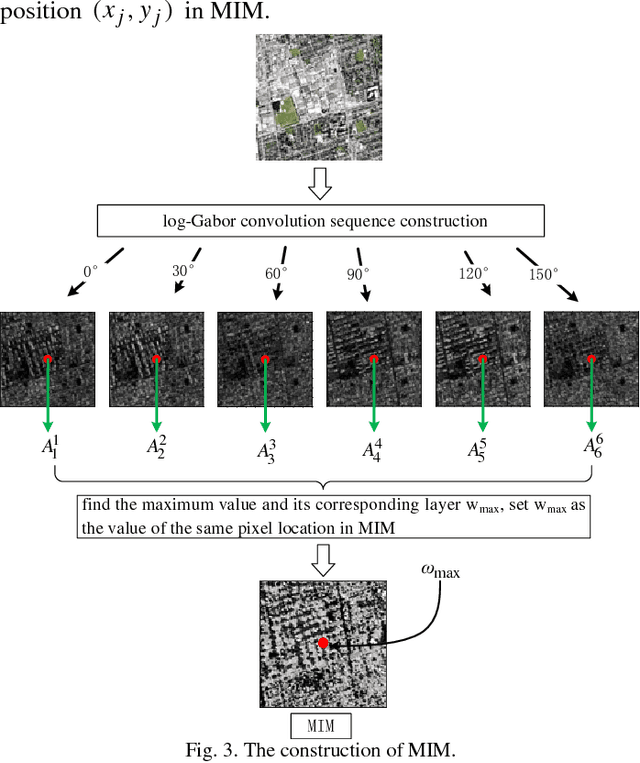

Traditional feature matching methods such as scale-invariant feature transform (SIFT) usually use image intensity or gradient information to detect and describe feature points; however, both intensity and gradient are sensitive to nonlinear radiation distortions (NRD). To solve the problem, this paper proposes a novel feature matching algorithm that is robust to large NRD. The proposed method is called radiation-invariant feature transform (RIFT). There are three main contributions in RIFT: first, RIFT uses phase congruency (PC) instead of image intensity for feature point detection. RIFT considers both the number and repeatability of feature points, and detects both corner points and edge points on the PC map. Second, RIFT originally proposes a maximum index map (MIM) for feature description. MIM is constructed from the log-Gabor convolution sequence and is much more robust to NRD than traditional gradient map. Thus, RIFT not only largely improves the stability of feature detection, but also overcomes the limitation of gradient information for feature description. Third, RIFT analyzes the inherent influence of rotations on the values of MIM, and realizes rotation invariance. We use six different types of multi-model image datasets to evaluate RIFT, including optical-optical, infrared-optical, synthetic aperture radar (SAR)-optical, depth-optical, map-optical, and day-night datasets. Experimental results show that RIFT is much more superior to SIFT and SAR-SIFT. To the best of our knowledge, RIFT is the first feature matching algorithm that can achieve good performance on all the above-mentioned types of multi-model images. The source code of RIFT and multi-modal remote sensing image datasets are made public .
CRFace: Confidence Ranker for Model-Agnostic Face Detection Refinement
Mar 12, 2021
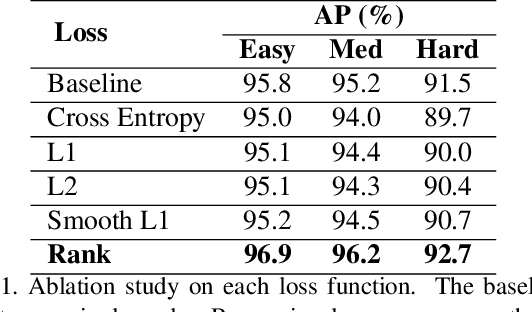
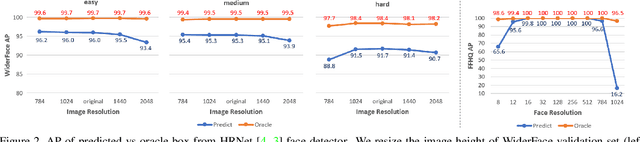
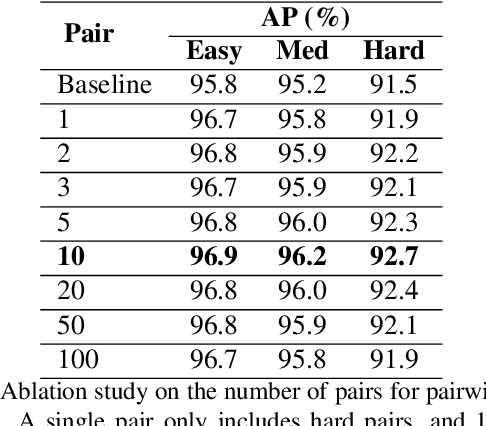
Face detection is a fundamental problem for many downstream face applications, and there is a rising demand for faster, more accurate yet support for higher resolution face detectors. Recent smartphones can record a video in 8K resolution, but many of the existing face detectors still fail due to the anchor size and training data. We analyze the failure cases and observe a large number of correct predicted boxes with incorrect confidences. To calibrate these confidences, we propose a confidence ranking network with a pairwise ranking loss to re-rank the predicted confidences locally within the same image. Our confidence ranker is model-agnostic, so we can augment the data by choosing the pairs from multiple face detectors during the training, and generalize to a wide range of face detectors during the testing. On WiderFace, we achieve the highest AP on the single-scale, and our AP is competitive with the previous multi-scale methods while being significantly faster. On 8K resolution, our method solves the GPU memory issue and allows us to indirectly train on 8K. We collect 8K resolution test set to show the improvement, and we will release our test set as a new benchmark for future research.
Efficient Near-Field Imaging Using Cylindrical MIMO Arrays
Jan 22, 2021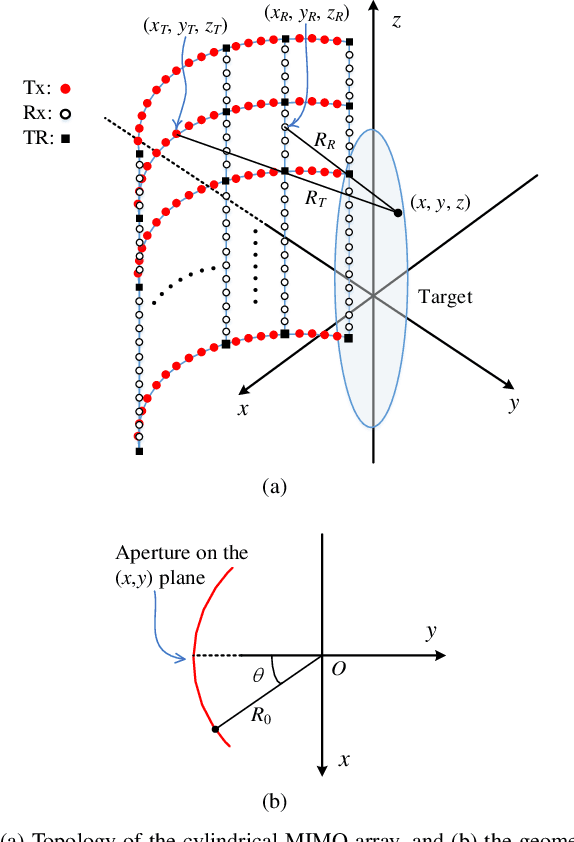
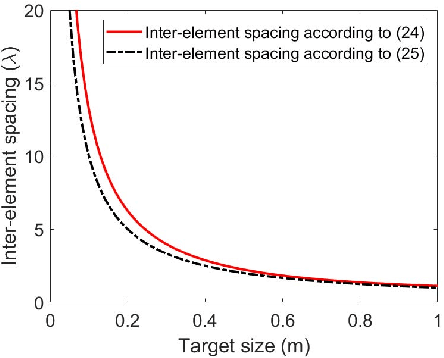
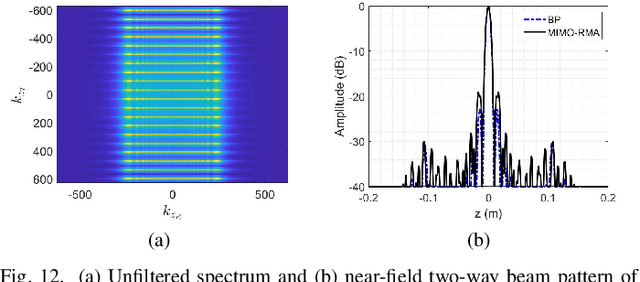
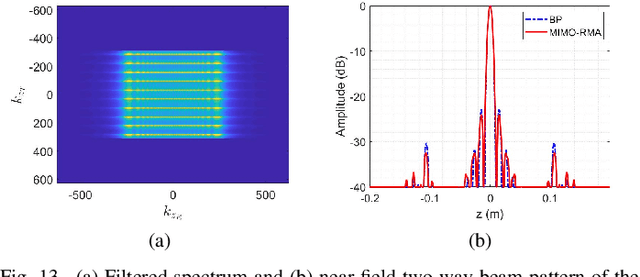
Multiple-input multiple-output (MIMO) array based millimeter-wave (MMW) imaging has a tangible prospect in applications of concealed weapons detection. A near-field imaging algorithm based on wavenumber domain processing is proposed for a cylindrical MIMO array scheme with uniformly spaced transmit and receive antennas over both the vertical and horizontal-arc directions. The spectrum aliasing associated with the proposed MIMO array is analyzed through a zero-filling discrete-time Fourier transform. The analysis shows that an undersampled array can be used in recovering the MMW image by a wavenumber domain algorithm. The requirements for the antenna inter-element spacing of the MIMO array are delineated. Numerical simulations as well as comparisons with the backprojection (BP) algorithm are provided to demonstrate the effectiveness of the proposed method.
Comprehensive Attention Self-Distillation for Weakly-Supervised Object Detection
Oct 22, 2020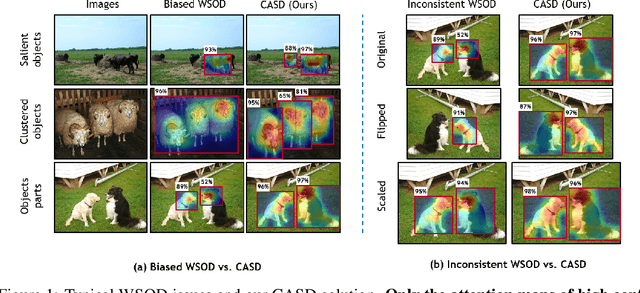

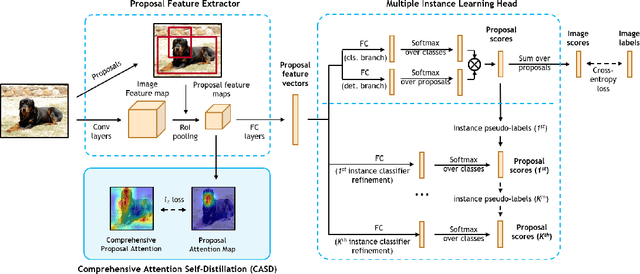

Weakly Supervised Object Detection (WSOD) has emerged as an effective tool to train object detectors using only the image-level category labels. However, without object-level labels, WSOD detectors are prone to detect bounding boxes on salient objects, clustered objects and discriminative object parts. Moreover, the image-level category labels do not enforce consistent object detection across different transformations of the same images. To address the above issues, we propose a Comprehensive Attention Self-Distillation (CASD) training approach for WSOD. To balance feature learning among all object instances, CASD computes the comprehensive attention aggregated from multiple transformations and feature layers of the same images. To enforce consistent spatial supervision on objects, CASD conducts self-distillation on the WSOD networks, such that the comprehensive attention is approximated simultaneously by multiple transformations and feature layers of the same images. CASD produces new state-of-the-art WSOD results on standard benchmarks such as PASCAL VOC 2007/2012 and MS-COCO.