 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocalComm: Hard Instance-Aware Multi-Agent Perception
Dec 20, 2025



Multi-agent collaborative perception (CP) is a promising paradigm for improving autonomous driving safety, particularly for vulnerable road users like pedestrians, via robust 3D perception. However, existing CP approaches often optimize for vehicle detection performance metrics, underperforming on smaller, safety-critical objects such as pedestrians, where detection failures can be catastrophic. Furthermore, previous CP methods rely on full feature exchange rather than communicating only salient features that help reduce false negatives. To this end, we present FocalComm, a novel collaborative perception framework that focuses on exchanging hard-instance-oriented features among connected collaborative agents. FocalComm consists of two key novel designs: (1) a learnable progressive hard instance mining (HIM) module to extract hard instance-oriented features per agent, and (2) a query-based feature-level (intermediate) fusion technique that dynamically weights these identified features during collaboration. We show that FocalComm outperforms state-of-the-art collaborative perception methods on two challenging real-world datasets (V2X-Real and DAIR-V2X) across both vehicle-centric and infrastructure-centric collaborative setups. FocalComm also shows a strong performance gain in pedestrian detection in V2X-Real.
Towards More Accurate Fake Detection on Images Generated from Advanced Generative and Neural Rendering Models
Nov 13, 2024



The remarkable progress in neural-network-driven visual data generation, especially with neural rendering techniques like Neural Radiance Fields and 3D Gaussian splatting, offers a powerful alternative to GANs and diffusion models. These methods can produce high-fidelity images and lifelike avatars, highlighting the need for robust detection methods. In response, an unsupervised training technique is proposed that enables the model to extract comprehensive features from the Fourier spectrum magnitude, thereby overcoming the challenges of reconstructing the spectrum due to its centrosymmetric properties. By leveraging the spectral domain and dynamically combining it with spatial domain information, we create a robust multimodal detector that demonstrates superior generalization capabilities in identifying challenging synthetic images generated by the latest image synthesis techniques. To address the absence of a 3D neural rendering-based fake image database, we develop a comprehensive database that includes images generated by diverse neural rendering techniques, providing a robust foundation for evaluating and advancing detection methods.
Comprehensive Attention Self-Distillation for Weakly-Supervised Object Detection
Oct 22, 2020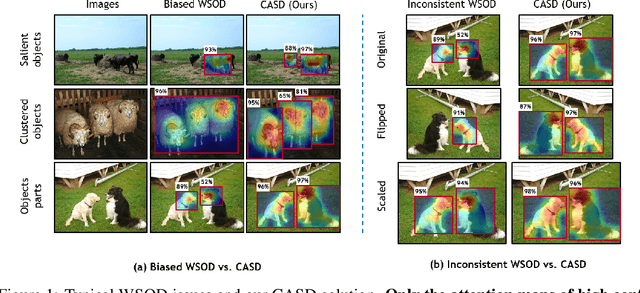

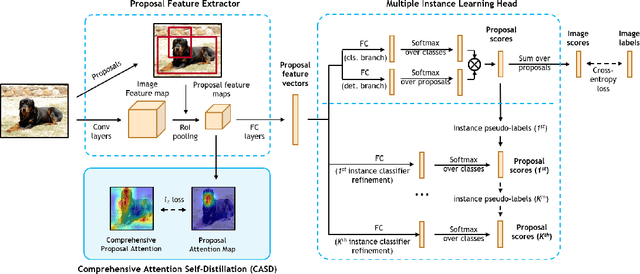

Weakly Supervised Object Detection (WSOD) has emerged as an effective tool to train object detectors using only the image-level category labels. However, without object-level labels, WSOD detectors are prone to detect bounding boxes on salient objects, clustered objects and discriminative object parts. Moreover, the image-level category labels do not enforce consistent object detection across different transformations of the same images. To address the above issues, we propose a Comprehensive Attention Self-Distillation (CASD) training approach for WSOD. To balance feature learning among all object instances, CASD computes the comprehensive attention aggregated from multiple transformations and feature layers of the same images. To enforce consistent spatial supervision on objects, CASD conducts self-distillation on the WSOD networks, such that the comprehensive attention is approximated simultaneously by multiple transformations and feature layers of the same images. CASD produces new state-of-the-art WSOD results on standard benchmarks such as PASCAL VOC 2007/2012 and MS-COCO.