 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Select, Substitute, Search: A New Benchmark for Knowledge-Augmented Visual Question Answering
Mar 09, 2021

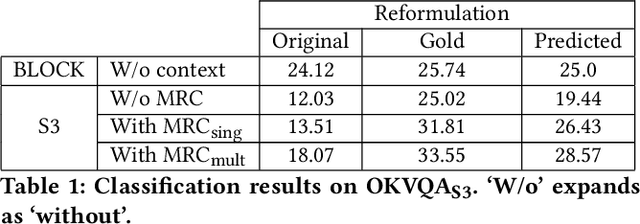

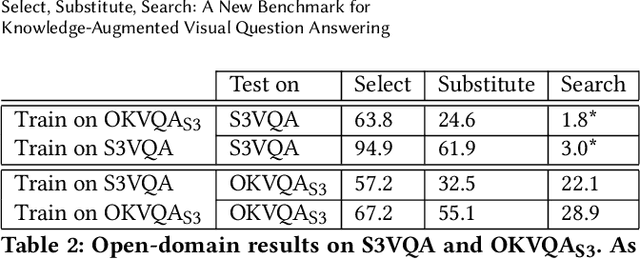
Multimodal IR, spanning text corpus, knowledge graph and images, called outside knowledge visual question answering (OKVQA), is of much recent interest. However, the popular data set has serious limitations. A surprisingly large fraction of queries do not assess the ability to integrate cross-modal information. Instead, some are independent of the image, some depend on speculation, some require OCR or are otherwise answerable from the image alone. To add to the above limitations, frequency-based guessing is very effective because of (unintended) widespread answer overlaps between the train and test folds. Overall, it is hard to determine when state-of-the-art systems exploit these weaknesses rather than really infer the answers, because they are opaque and their 'reasoning' process is uninterpretable. An equally important limitation is that the dataset is designed for the quantitative assessment only of the end-to-end answer retrieval task, with no provision for assessing the correct(semantic) interpretation of the input query. In response, we identify a key structural idiom in OKVQA ,viz., S3 (select, substitute and search), and build a new data set and challenge around it. Specifically, the questioner identifies an entity in the image and asks a question involving that entity which can be answered only by consulting a knowledge graph or corpus passage mentioning the entity. Our challenge consists of (i)OKVQAS3, a subset of OKVQA annotated based on the structural idiom and (ii)S3VQA, a new dataset built from scratch. We also present a neural but structurally transparent OKVQA system, S3, that explicitly addresses our challenge dataset, and outperforms recent competitive baselines.
SurgeonAssist-Net: Towards Context-Aware Head-Mounted Display-Based Augmented Reality for Surgical Guidance
Jul 13, 2021


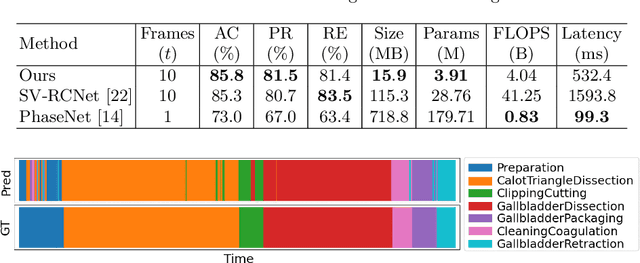
We present SurgeonAssist-Net: a lightweight framework making action-and-workflow-driven virtual assistance, for a set of predefined surgical tasks, accessible to commercially available optical see-through head-mounted displays (OST-HMDs). On a widely used benchmark dataset for laparoscopic surgical workflow, our implementation competes with state-of-the-art approaches in prediction accuracy for automated task recognition, and yet requires 7.4x fewer parameters, 10.2x fewer floating point operations per second (FLOPS), is 7.0x faster for inference on a CPU, and is capable of near real-time performance on the Microsoft HoloLens 2 OST-HMD. To achieve this, we make use of an efficient convolutional neural network (CNN) backbone to extract discriminative features from image data, and a low-parameter recurrent neural network (RNN) architecture to learn long-term temporal dependencies. To demonstrate the feasibility of our approach for inference on the HoloLens 2 we created a sample dataset that included video of several surgical tasks recorded from a user-centric point-of-view. After training, we deployed our model and cataloged its performance in an online simulated surgical scenario for the prediction of the current surgical task. The utility of our approach is explored in the discussion of several relevant clinical use-cases. Our code is publicly available at https://github.com/doughtmw/surgeon-assist-net.
DF^2AM: Dual-level Feature Fusion and Affinity Modeling for RGB-Infrared Cross-modality Person Re-identification
Apr 01, 2021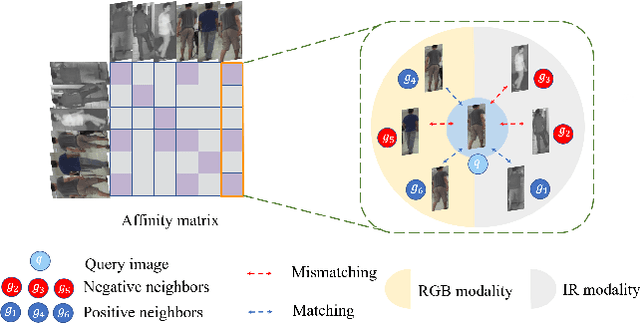
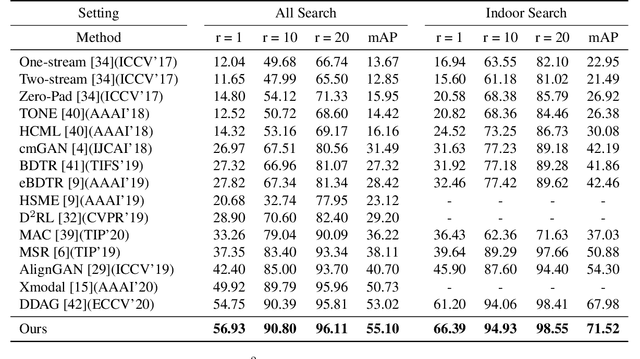
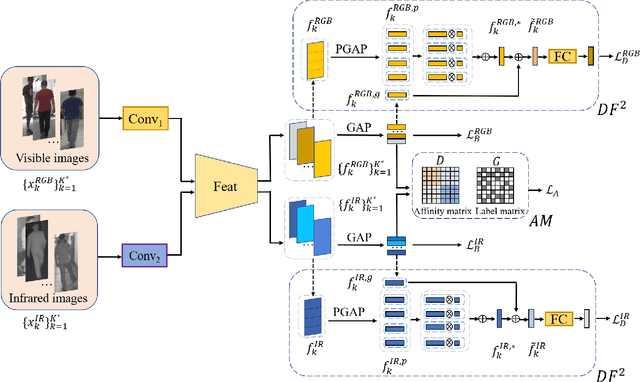
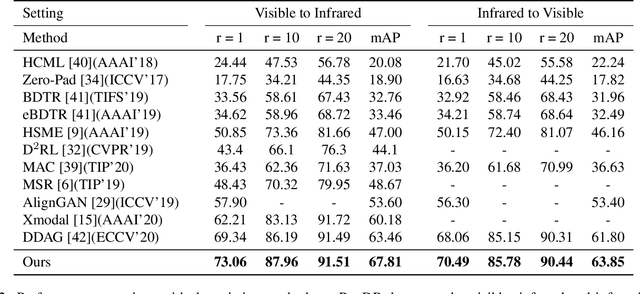
RGB-infrared person re-identification is a challenging task due to the intra-class variations and cross-modality discrepancy. Existing works mainly focus on learning modality-shared global representations by aligning image styles or feature distributions across modalities, while local feature from body part and relationships between person images are largely neglected. In this paper, we propose a Dual-level (i.e., local and global) Feature Fusion (DF^2) module by learning attention for discriminative feature from local to global manner. In particular, the attention for a local feature is determined locally, i.e., applying a learned transformation function on itself. Meanwhile, to further mining the relationships between global features from person images, we propose an Affinities Modeling (AM) module to obtain the optimal intra- and inter-modality image matching. Specifically, AM employes intra-class compactness and inter-class separability in the sample similarities as supervised information to model the affinities between intra- and inter-modality samples. Experimental results show that our proposed method outperforms state-of-the-arts by large margins on two widely used cross-modality re-ID datasets SYSU-MM01 and RegDB, respectively.
IdentityDP: Differential Private Identification Protection for Face Images
Mar 02, 2021

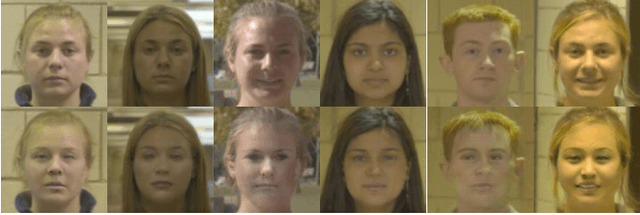

Because of the explosive growth of face photos as well as their widespread dissemination and easy accessibility in social media, the security and privacy of personal identity information becomes an unprecedented challenge. Meanwhile, the convenience brought by advanced identity-agnostic computer vision technologies is attractive. Therefore, it is important to use face images while taking careful consideration in protecting people's identities. Given a face image, face de-identification, also known as face anonymization, refers to generating another image with similar appearance and the same background, while the real identity is hidden. Although extensive efforts have been made, existing face de-identification techniques are either insufficient in photo-reality or incapable of well-balancing privacy and utility. In this paper, we focus on tackling these challenges to improve face de-identification. We propose IdentityDP, a face anonymization framework that combines a data-driven deep neural network with a differential privacy (DP) mechanism. This framework encompasses three stages: facial representations disentanglement, $\epsilon$-IdentityDP perturbation and image reconstruction. Our model can effectively obfuscate the identity-related information of faces, preserve significant visual similarity, and generate high-quality images that can be used for identity-agnostic computer vision tasks, such as detection, tracking, etc. Different from the previous methods, we can adjust the balance of privacy and utility through the privacy budget according to pratical demands and provide a diversity of results without pre-annotations. Extensive experiments demonstrate the effectiveness and generalization ability of our proposed anonymization framework.
TransVG: End-to-End Visual Grounding with Transformers
Apr 17, 2021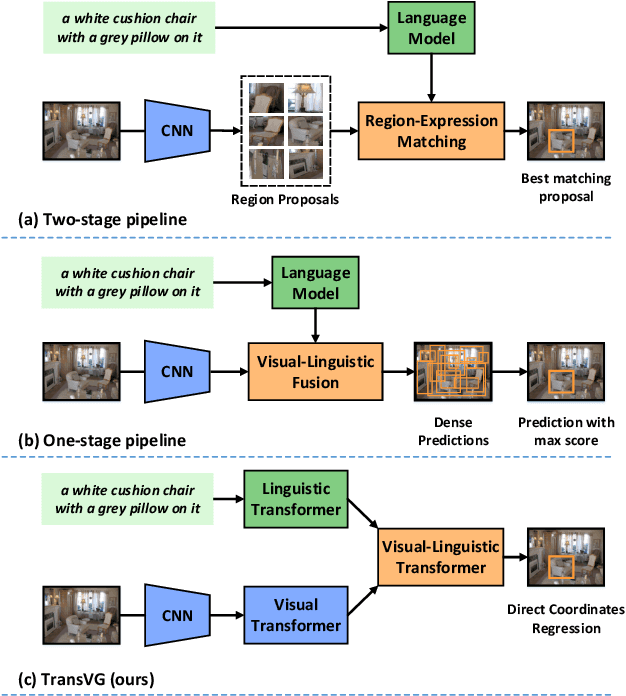
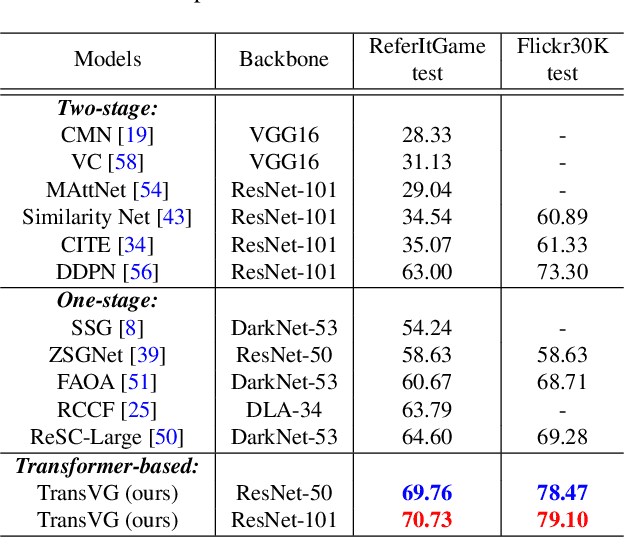
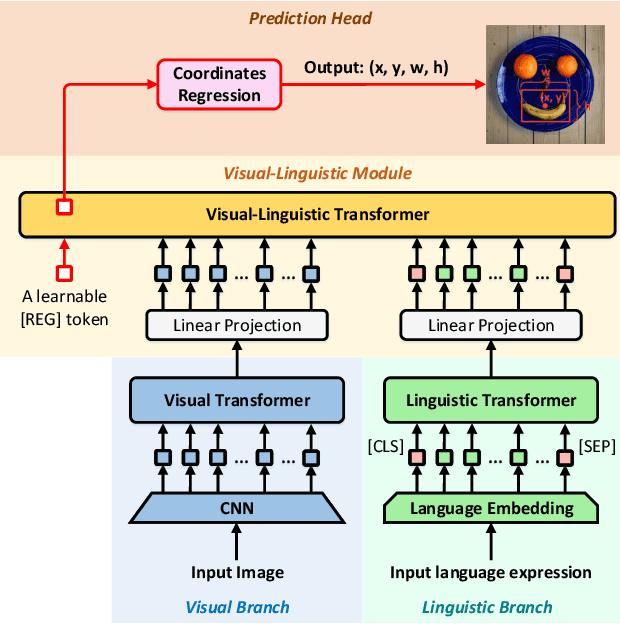
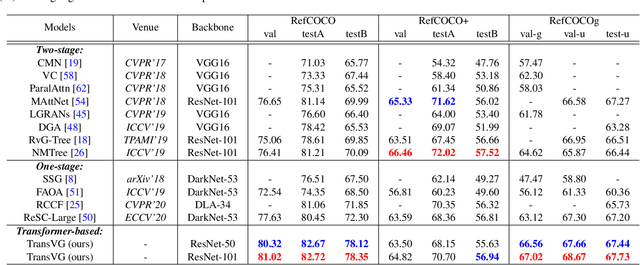
In this paper, we present a neat yet effective transformer-based framework for visual grounding, namely TransVG, to address the task of grounding a language query to the corresponding region onto an image. The state-of-the-art methods, including two-stage or one-stage ones, rely on a complex module with manually-designed mechanisms to perform the query reasoning and multi-modal fusion. However, the involvement of certain mechanisms in fusion module design, such as query decomposition and image scene graph, makes the models easily overfit to datasets with specific scenarios, and limits the plenitudinous interaction between the visual-linguistic context. To avoid this caveat, we propose to establish the multi-modal correspondence by leveraging transformers, and empirically show that the complex fusion modules (e.g., modular attention network, dynamic graph, and multi-modal tree) can be replaced by a simple stack of transformer encoder layers with higher performance. Moreover, we re-formulate the visual grounding as a direct coordinates regression problem and avoid making predictions out of a set of candidates (i.e., region proposals or anchor boxes). Extensive experiments are conducted on five widely used datasets, and a series of state-of-the-art records are set by our TransVG. We build the benchmark of transformer-based visual grounding framework and will make our code available to the public.
LOST: A flexible framework for semi-automatic image annotation
Oct 16, 2019
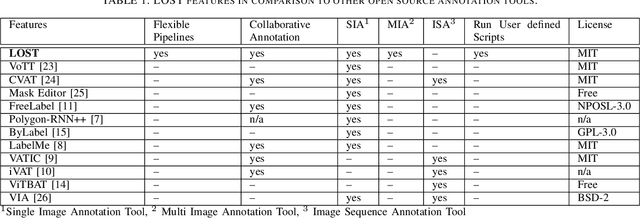
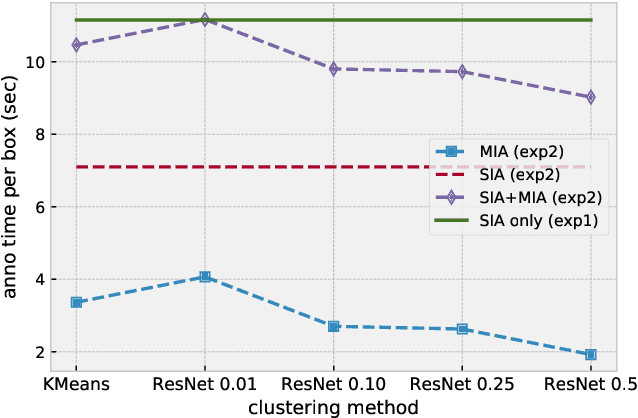

State-of-the-art computer vision approaches rely on huge amounts of annotated data. The collection of such data is a time consuming process since it is mainly performed by humans. The literature shows that semi-automatic annotation approaches can significantly speed up the annotation process by the automatic generation of annotation proposals to support the annotator. In this paper we present a framework that allows for a quick and flexible design of semi-automatic annotation pipelines. We show that a good design of the process will speed up the collection of annotations. Our contribution is a new approach to image annotation that allows for the combination of different annotation tools and machine learning algorithms in one process. We further present potential applications of our approach. The source code of our framework called LOST (Label Objects and Save Time) is available at: https://github.com/l3p-cv/lost.
HDMapNet: An Online HD Map Construction and Evaluation Framework
Jul 13, 2021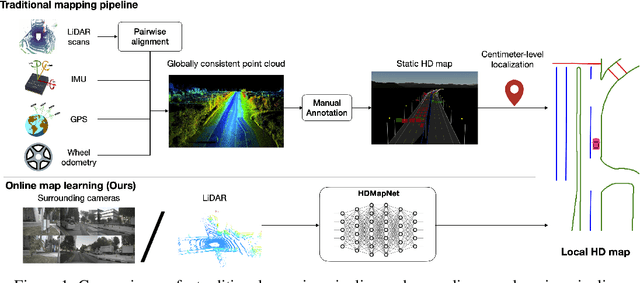

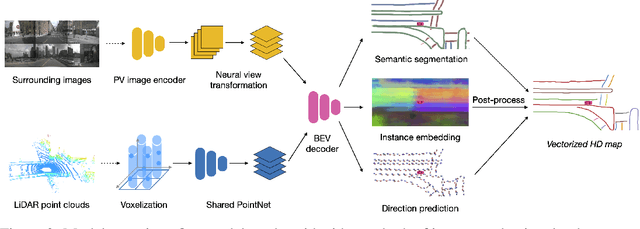

High-definition map (HD map) construction is a crucial problem for autonomous driving. This problem typically involves collecting high-quality point clouds, fusing multiple point clouds of the same scene, annotating map elements, and updating maps constantly. This pipeline, however, requires a vast amount of human efforts and resources which limits its scalability. Additionally, traditional HD maps are coupled with centimeter-level accurate localization which is unreliable in many scenarios. In this paper, we argue that online map learning, which dynamically constructs the HD maps based on local sensor observations, is a more scalable way to provide semantic and geometry priors to self-driving vehicles than traditional pre-annotated HD maps. Meanwhile, we introduce an online map learning method, titled HDMapNet. It encodes image features from surrounding cameras and/or point clouds from LiDAR, and predicts vectorized map elements in the bird's-eye view. We benchmark HDMapNet on the nuScenes dataset and show that in all settings, it performs better than baseline methods. Of note, our fusion-based HDMapNet outperforms existing methods by more than 50% in all metrics. To accelerate future research, we develop customized metrics to evaluate map learning performance, including both semantic-level and instance-level ones. By introducing this method and metrics, we invite the community to study this novel map learning problem. We will release our code and evaluation kit to facilitate future development.
Glaucoma detection beyond the optic disc: The importance of the peripapillary region using explainable deep learning
Mar 22, 2021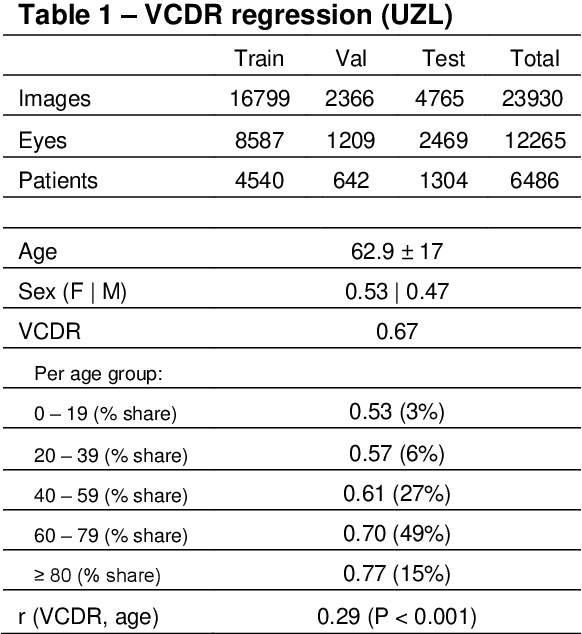
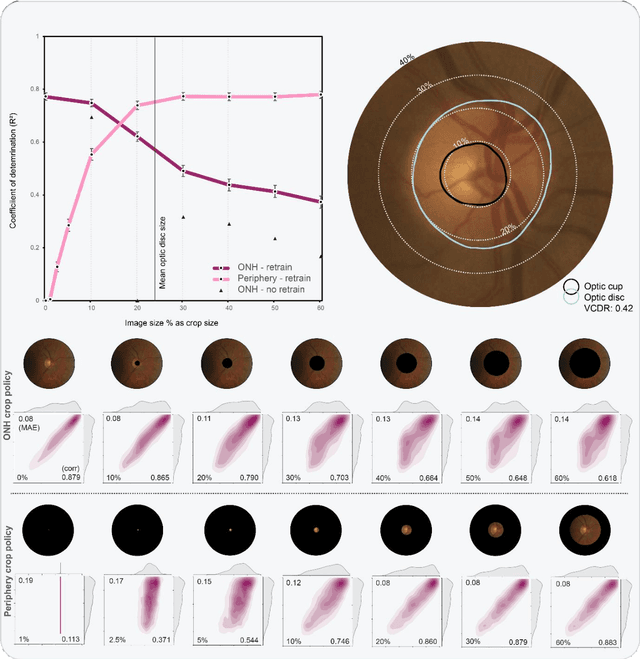
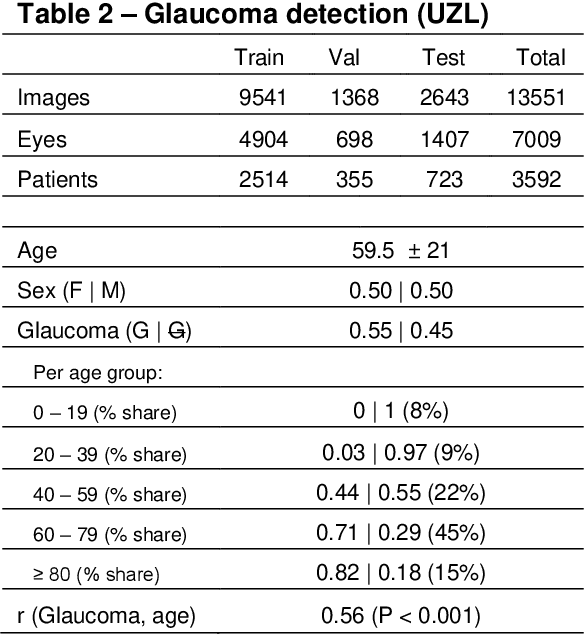
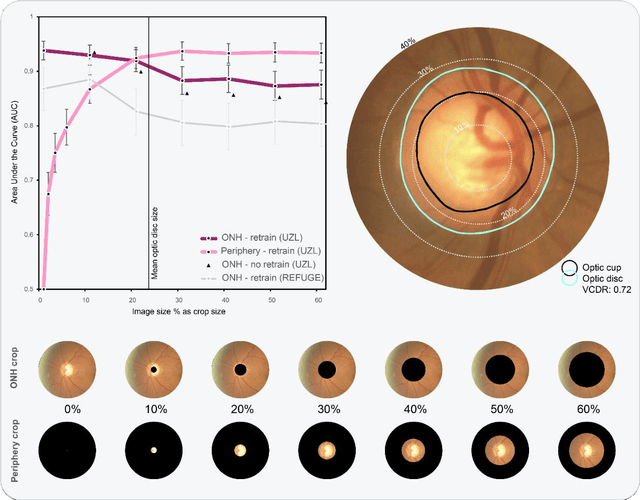
Today, a large number of glaucoma cases remain undetected, resulting in irreversible blindness. In a quest for cost-effective screening, deep learning-based methods are being evaluated to detect glaucoma from color fundus images. Although unprecedented sensitivity and specificity values are reported, recent glaucoma detection deep learning models lack in decision transparency. Here, we propose a methodology that advances explainable deep learning in the field of glaucoma detection and vertical cup-disc ratio (VCDR), an important risk factor. We trained and evaluated a total of 64 deep learning models using fundus images that undergo a certain cropping policy. We defined the circular crop radius as a percentage of image size, centered on the optic nerve head (ONH), with an equidistant spaced range from 10%-60% (ONH crop policy). The inverse of the cropping mask was also applied to quantify the performance of models trained on ONH information exclusively (periphery crop policy). The performance of the models evaluated on original images resulted in an area under the curve (AUC) of 0.94 [95% CI: 0.92-0.96] for glaucoma detection, and a coefficient of determination (R^2) equal to 77% [95% CI: 0.77-0.79] for VCDR estimation. Models that were trained on images with absence of the ONH are still able to obtain significant performance (0.88 [95% CI: 0.85-0.90] AUC for glaucoma detection and 37% [95% CI: 0.35-0.40] R^2 score for VCDR estimation in the most extreme setup of 60% ONH crop). We validated our glaucoma detection models on a recent public data set (REFUGE) that contains images captured with a different camera, still achieving an AUC of 0.80 [95% CI: 0.76-0.84] when ONH crop policy of 60% image size was applied. Our findings provide the first irrefutable evidence that deep learning can detect glaucoma from fundus image regions outside the ONH.
Bringing A Robot Simulator to the SCAMP Vision System
May 21, 2021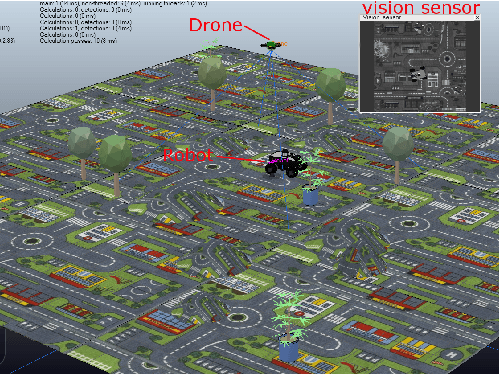
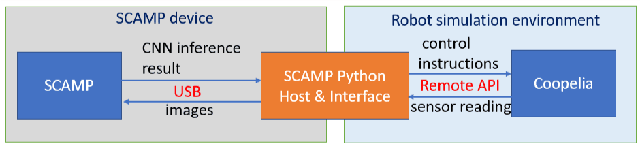
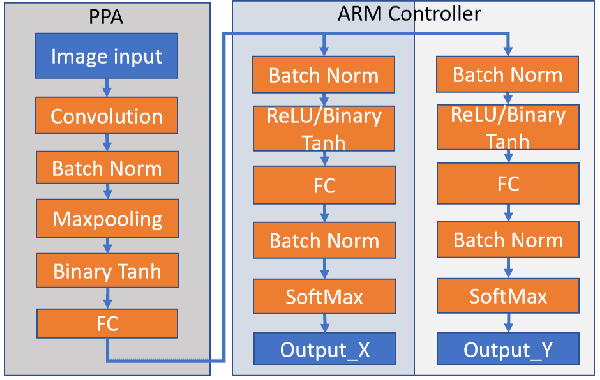

This work develops and demonstrates the integration of the SCAMP-5d vision system into the CoppeliaSim robot simulator, creating a semi-simulated environment. By configuring a camera in the simulator and setting up communication with the SCAMP python host through remote API, sensor images from the simulator can be transferred to the SCAMP vision sensor, where on-sensor image processing such as CNN inference can be performed. SCAMP output is then fed back into CoppeliaSim. This proposed platform integration enables rapid prototyping validations of SCAMP algorithms for robotic systems. We demonstrate a car localisation and tracking task using this proposed semi-simulated platform, with a CNN inference on SCAMP to command the motion of a robot. We made this platform available online.
Lossless Multi-Scale Constitutive Elastic Relations with Artificial Intelligence
Aug 05, 2021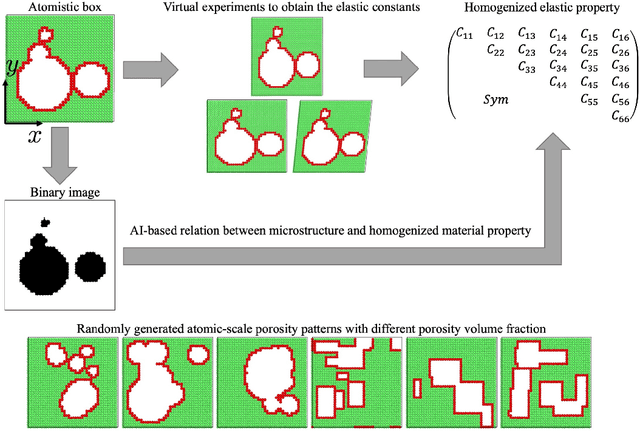
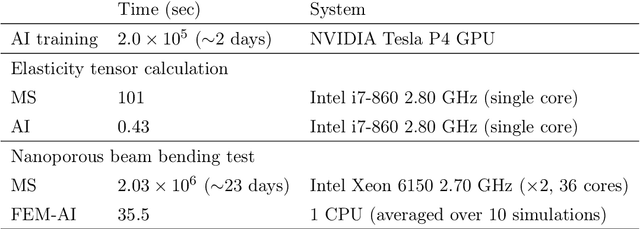
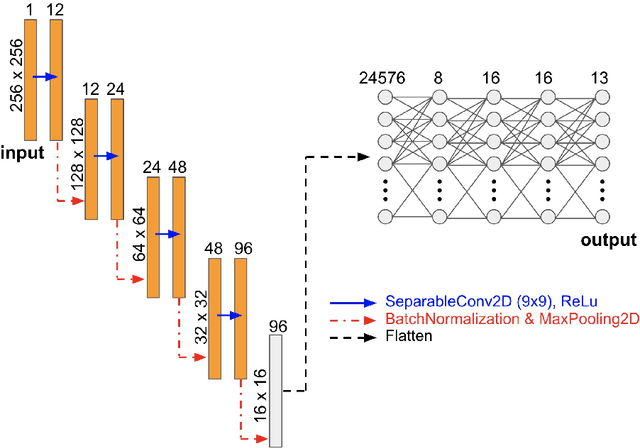
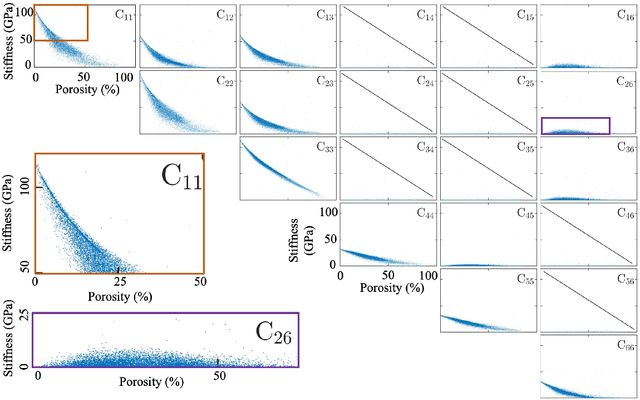
The elastic properties of materials derive from their electronic and atomic nature. However, simulating bulk materials fully at these scales is not feasible, so that typically homogenized continuum descriptions are used instead. A seamless and lossless transition of the constitutive description of the elastic response of materials between these two scales has been so far elusive. Here we show how this problem can be overcome by using Artificial Intelligence (AI). A Convolutional Neural Network (CNN) model is trained, by taking the structure image of a nanoporous material as input and the corresponding elasticity tensor, calculated from Molecular Statics (MS), as output. Trained with the atomistic data, the CNN model captures the size- and pore-dependency of the material's elastic properties which, on the physics side, can stem from surfaces and non-local effects. Such effects are often ignored in upscaling from atomistic to classical continuum theory. To demonstrate the accuracy and the efficiency of the trained CNN model, a Finite Element Method (FEM) based result of an elastically deformed nanoporous beam equipped with the CNN as constitutive law is compared with that by a full atomistic simulation. The good agreement between the atomistic simulations and the FEM-AI combination for a system with size and surface effects establishes a new lossless scale bridging approach to such problems. The trained CNN model deviates from the atomistic result by 9.6\% for porosity scenarios of up to 90\% but it is about 230 times faster than the MS calculation and does not require to change simulation methods between different scales. The efficiency of the CNN evaluation together with the preservation of important atomistic effects makes the trained model an effective atomistically-informed constitutive model for macroscopic simulations of nanoporous materials and solving of inverse problems.