 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Retrieve in Style: Unsupervised Facial Feature Transfer and Retrieval
Jul 13, 2021

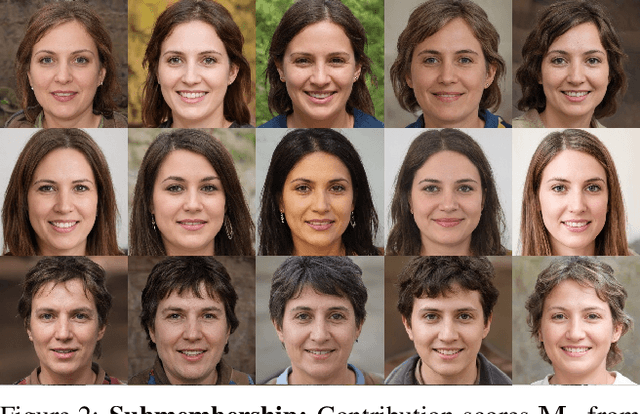
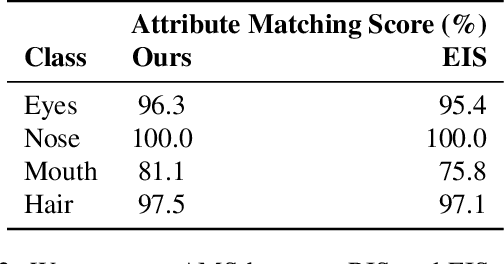

We present Retrieve in Style (RIS), an unsupervised framework for fine-grained facial feature transfer and retrieval on real images. Recent work shows that it is possible to learn a catalog that allows local semantic transfers of facial features on generated images by capitalizing on the disentanglement property of the StyleGAN latent space. RIS improves existing art on: 1) feature disentanglement and allows for challenging transfers (i.e., hair and pose) that were not shown possible in SoTA methods. 2) eliminating the need for per-image hyperparameter tuning, and for computing a catalog over a large batch of images. 3) enabling face retrieval using the proposed facial features (e.g., eyes), and to our best knowledge, is the first work to retrieve face images at the fine-grained level. 4) robustness and natural application to real images. Our qualitative and quantitative analyses show RIS achieves both high-fidelity feature transfers and accurate fine-grained retrievals on real images. We discuss the responsible application of RIS.
Geometry-Guided Street-View Panorama Synthesis from Satellite Imagery
Mar 05, 2021
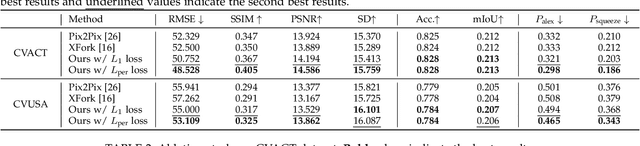
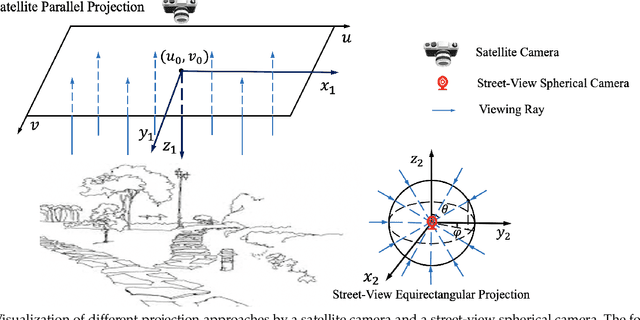
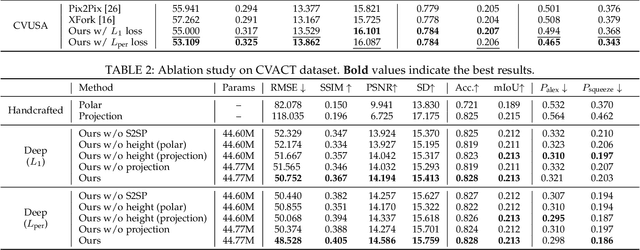
This paper presents a new approach for synthesizing a novel street-view panorama given an overhead satellite image. Taking a small satellite image patch as input, our method generates a Google's omnidirectional street-view type panorama, as if it is captured from the same geographical location as the center of the satellite patch. Existing works tackle this task as an image generation problem which adopts generative adversarial networks to implicitly learn the cross-view transformations, while ignoring the domain relevance. In this paper, we propose to explicitly establish the geometric correspondences between the two-view images so as to facilitate the cross-view transformation learning. Specifically, we observe that when a 3D point in the real world is visible in both views, there is a deterministic mapping between the projected points in the two-view images given the height information of this 3D point. Motivated by this, we develop a novel Satellite to Street-view image Projection (S2SP) module which explicitly establishes such geometric correspondences and projects the satellite images to the street viewpoint. With these projected satellite images as network input, we next employ a generator to synthesize realistic street-view panoramas that are geometrically consistent with the satellite images. Our S2SP module is differentiable and the whole framework is trained in an end-to-end manner. Extensive experimental results on two cross-view benchmark datasets demonstrate that our method generates images that better respect the scene geometry than existing approaches.
Learning a Discriminant Latent Space with Neural Discriminant Analysis
Jul 13, 2021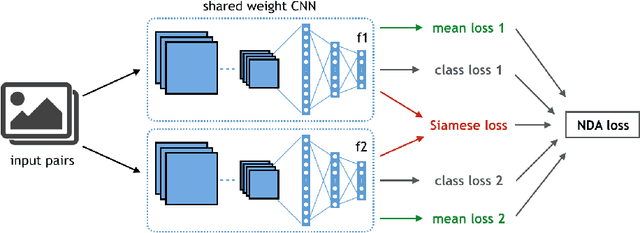

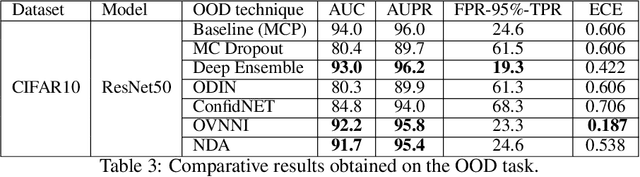
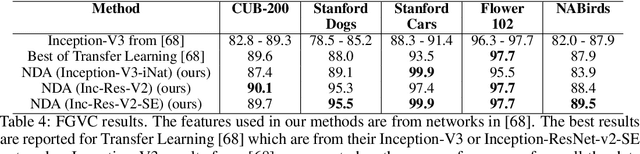
Discriminative features play an important role in image and object classification and also in other fields of research such as semi-supervised learning, fine-grained classification, out of distribution detection. Inspired by Linear Discriminant Analysis (LDA), we propose an optimization called Neural Discriminant Analysis (NDA) for Deep Convolutional Neural Networks (DCNNs). NDA transforms deep features to become more discriminative and, therefore, improves the performances in various tasks. Our proposed optimization has two primary goals for inter- and intra-class variances. The first one is to minimize variances within each individual class. The second goal is to maximize pairwise distances between features coming from different classes. We evaluate our NDA optimization in different research fields: general supervised classification, fine-grained classification, semi-supervised learning, and out of distribution detection. We achieve performance improvements in all the fields compared to baseline methods that do not use NDA. Besides, using NDA, we also surpass the state of the art on the four tasks on various testing datasets.
Adaptive Dilated Convolution For Human Pose Estimation
Jul 22, 2021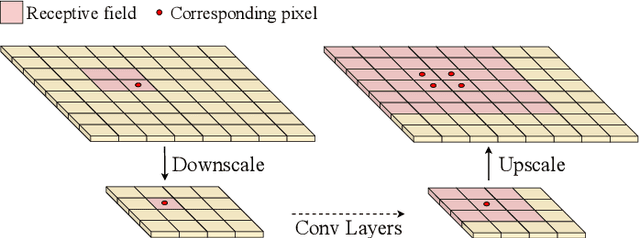
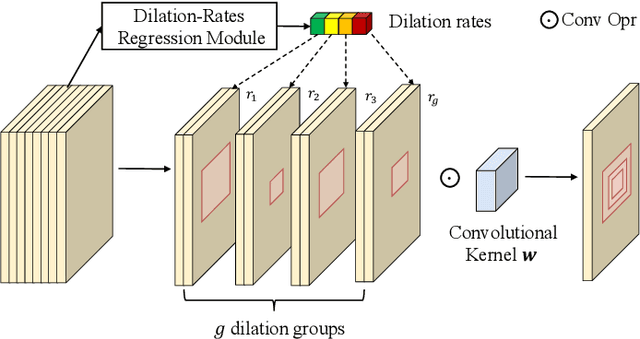

Most existing human pose estimation (HPE) methods exploit multi-scale information by fusing feature maps of four different spatial sizes, \ie $1/4$, $1/8$, $1/16$, and $1/32$ of the input image. There are two drawbacks of this strategy: 1) feature maps of different spatial sizes may be not well aligned spatially, which potentially hurts the accuracy of keypoint location; 2) these scales are fixed and inflexible, which may restrict the generalization ability over various human sizes. Towards these issues, we propose an adaptive dilated convolution (ADC). It can generate and fuse multi-scale features of the same spatial sizes by setting different dilation rates for different channels. More importantly, these dilation rates are generated by a regression module. It enables ADC to adaptively adjust the fused scales and thus ADC may generalize better to various human sizes. ADC can be end-to-end trained and easily plugged into existing methods. Extensive experiments show that ADC can bring consistent improvements to various HPE methods. The source codes will be released for further research.
Piecewise Flat Embedding for Image Segmentation
May 20, 2018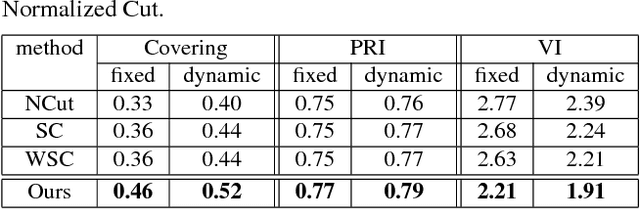

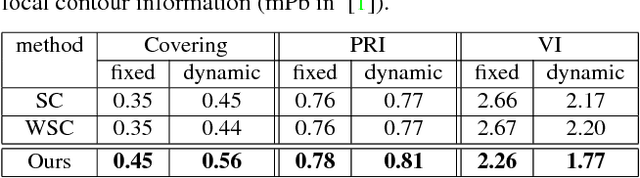
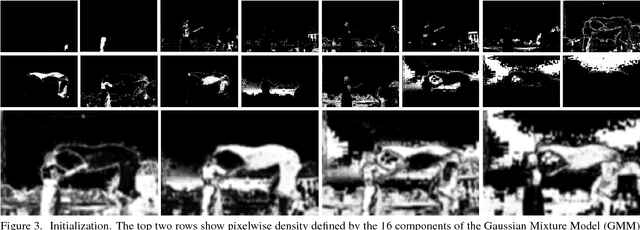
We introduce a new multi-dimensional nonlinear embedding -- Piecewise Flat Embedding (PFE) -- for image segmentation. Based on the theory of sparse signal recovery, piecewise flat embedding with diverse channels attempts to recover a piecewise constant image representation with sparse region boundaries and sparse cluster value scattering. The resultant piecewise flat embedding exhibits interesting properties such as suppressing slowly varying signals, and offers an image representation with higher region identifiability which is desirable for image segmentation or high-level semantic analysis tasks. We formulate our embedding as a variant of the Laplacian Eigenmap embedding with an $L_{1,p} (0<p\leq1)$ regularization term to promote sparse solutions. First, we devise a two-stage numerical algorithm based on Bregman iterations to compute $L_{1,1}$-regularized piecewise flat embeddings. We further generalize this algorithm through iterative reweighting to solve the general $L_{1,p}$-regularized problem. To demonstrate its efficacy, we integrate PFE into two existing image segmentation frameworks, segmentation based on clustering and hierarchical segmentation based on contour detection. Experiments on four major benchmark datasets, BSDS500, MSRC, Stanford Background Dataset, and PASCAL Context, show that segmentation algorithms incorporating our embedding achieve significantly improved results.
SPARK: SPAcecraft Recognition leveraging Knowledge of Space Environment
Apr 14, 2021
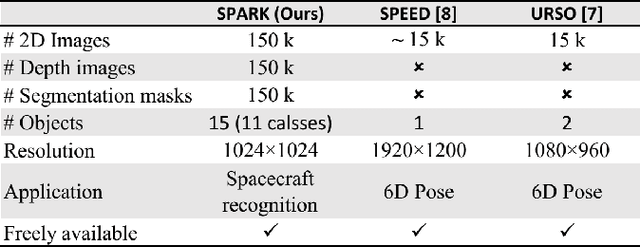
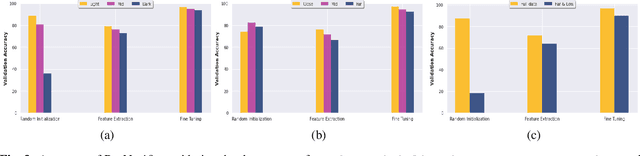
This paper proposes the SPARK dataset as a new unique space object multi-modal image dataset. Image-based object recognition is an important component of Space Situational Awareness, especially for applications such as on-orbit servicing, active debris removal, and satellite formation. However, the lack of sufficient annotated space data has limited research efforts in developing data-driven spacecraft recognition approaches. The SPARK dataset has been generated under a realistic space simulation environment, with a large diversity in sensing conditions for different orbital scenarios. It provides about 150k images per modality, RGB and depth, and 11 classes for spacecrafts and debris. This dataset offers an opportunity to benchmark and further develop object recognition, classification and detection algorithms, as well as multi-modal RGB-Depth approaches under space sensing conditions. Preliminary experimental evaluation validates the relevance of the data, and highlights interesting challenging scenarios specific to the space environment.
Protecting Intellectual Property of Generative Adversarial Networks from Ambiguity Attack
Mar 01, 2021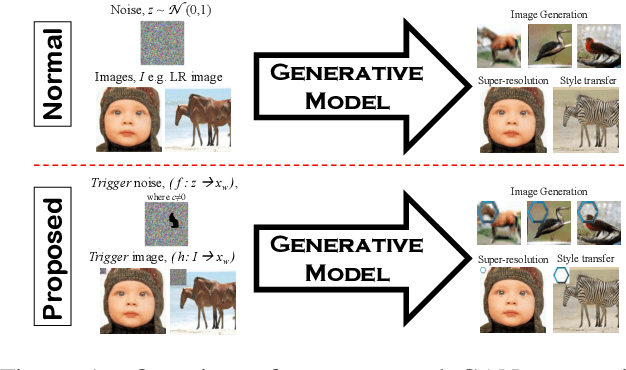



Ever since Machine Learning as a Service (MLaaS) emerges as a viable business that utilizes deep learning models to generate lucrative revenue, Intellectual Property Right (IPR) has become a major concern because these deep learning models can easily be replicated, shared, and re-distributed by any unauthorized third parties. To the best of our knowledge, one of the prominent deep learning models - Generative Adversarial Networks (GANs) which has been widely used to create photorealistic image are totally unprotected despite the existence of pioneering IPR protection methodology for Convolutional Neural Networks (CNNs). This paper therefore presents a complete protection framework in both black-box and white-box settings to enforce IPR protection on GANs. Empirically, we show that the proposed method does not compromise the original GANs performance (i.e. image generation, image super-resolution, style transfer), and at the same time, it is able to withstand both removal and ambiguity attacks against embedded watermarks.
StrucTexT: Structured Text Understanding with Multi-Modal Transformers
Aug 06, 2021
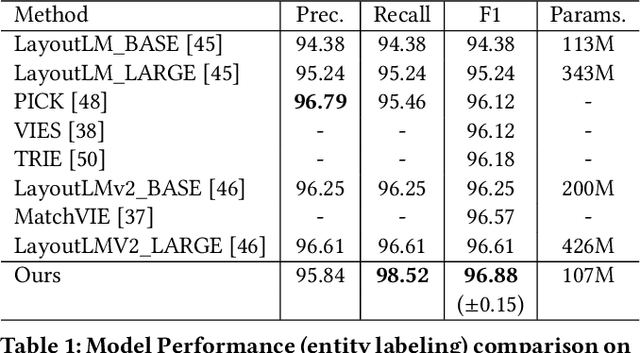
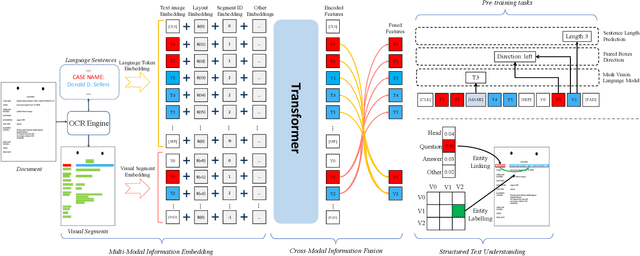
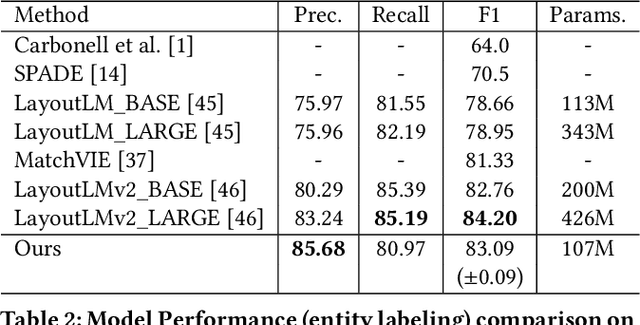
Structured text understanding on Visually Rich Documents (VRDs) is a crucial part of Document Intelligence. Due to the complexity of content and layout in VRDs, structured text understanding has been a challenging task. Most existing studies decoupled this problem into two sub-tasks: entity labeling and entity linking, which require an entire understanding of the context of documents at both token and segment levels. However, little work has been concerned with the solutions that efficiently extract the structured data from different levels. This paper proposes a unified framework named StrucTexT, which is flexible and effective for handling both sub-tasks. Specifically, based on the transformer, we introduce a segment-token aligned encoder to deal with the entity labeling and entity linking tasks at different levels of granularity. Moreover, we design a novel pre-training strategy with three self-supervised tasks to learn a richer representation. StrucTexT uses the existing Masked Visual Language Modeling task and the new Sentence Length Prediction and Paired Boxes Direction tasks to incorporate the multi-modal information across text, image, and layout. We evaluate our method for structured text understanding at segment-level and token-level and show it outperforms the state-of-the-art counterparts with significantly superior performance on the FUNSD, SROIE, and EPHOIE datasets.
M2IOSR: Maximal Mutual Information Open Set Recognition
Aug 06, 2021
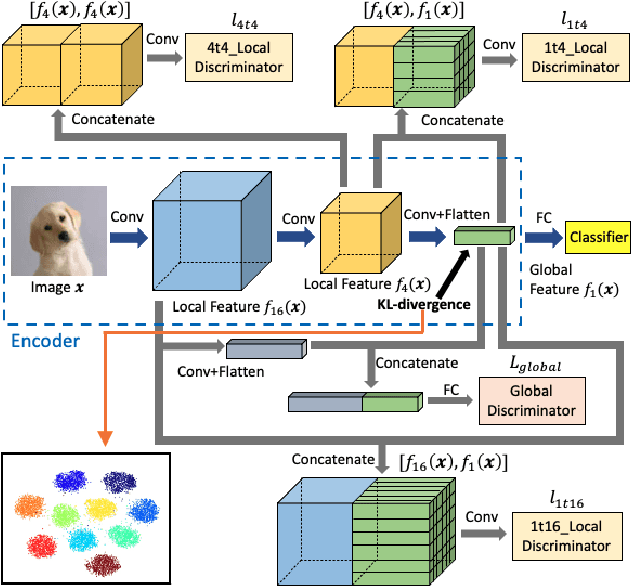
In this work, we aim to address the challenging task of open set recognition (OSR). Many recent OSR methods rely on auto-encoders to extract class-specific features by a reconstruction strategy, requiring the network to restore the input image on pixel-level. This strategy is commonly over-demanding for OSR since class-specific features are generally contained in target objects, not in all pixels. To address this shortcoming, here we discard the pixel-level reconstruction strategy and pay more attention to improving the effectiveness of class-specific feature extraction. We propose a mutual information-based method with a streamlined architecture, Maximal Mutual Information Open Set Recognition (M2IOSR). The proposed M2IOSR only uses an encoder to extract class-specific features by maximizing the mutual information between the given input and its latent features across multiple scales. Meanwhile, to further reduce the open space risk, latent features are constrained to class conditional Gaussian distributions by a KL-divergence loss function. In this way, a strong function is learned to prevent the network from mapping different observations to similar latent features and help the network extract class-specific features with desired statistical characteristics. The proposed method significantly improves the performance of baselines and achieves new state-of-the-art results on several benchmarks consistently.
Fine-Grained AutoAugmentation for Multi-Label Classification
Jul 13, 2021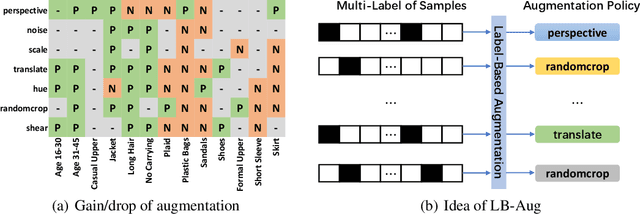
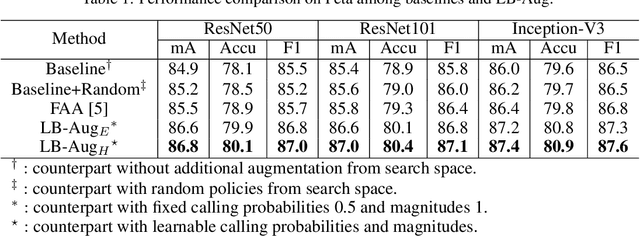
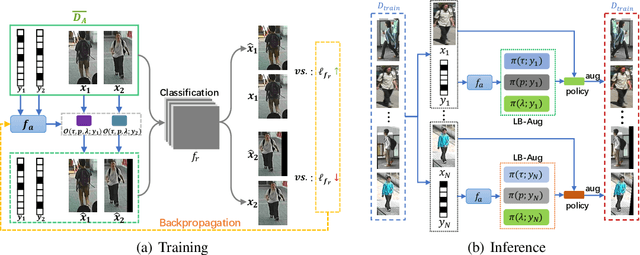
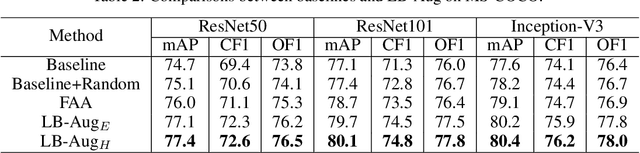
Data augmentation is a commonly used approach to improving the generalization of deep learning models. Recent works show that learned data augmentation policies can achieve better generalization than hand-crafted ones. However, most of these works use unified augmentation policies for all samples in a dataset, which is observed not necessarily beneficial for all labels in multi-label classification tasks, i.e., some policies may have negative impacts on some labels while benefitting the others. To tackle this problem, we propose a novel Label-Based AutoAugmentation (LB-Aug) method for multi-label scenarios, where augmentation policies are generated with respect to labels by an augmentation-policy network. The policies are learned via reinforcement learning using policy gradient methods, providing a mapping from instance labels to their optimal augmentation policies. Numerical experiments show that our LB-Aug outperforms previous state-of-the-art augmentation methods by large margins in multiple benchmarks on image and video classification.