 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Revisiting Deep Intrinsic Image Decompositions
Aug 31, 2018
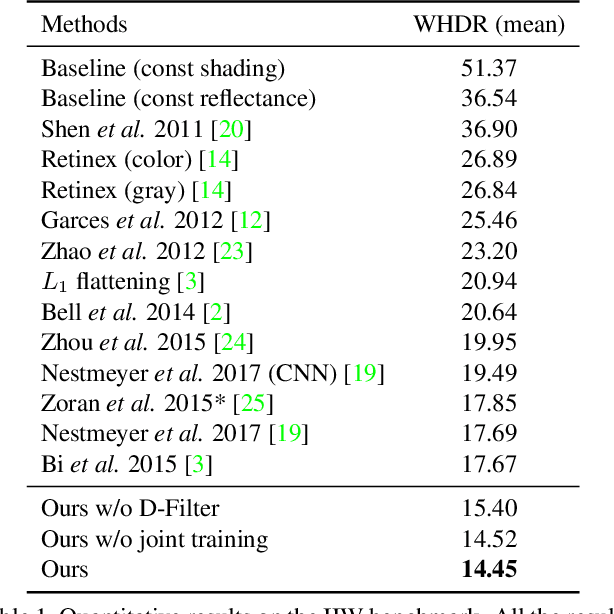

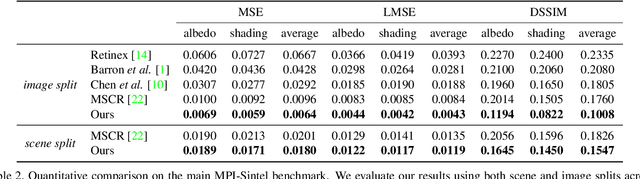

While invaluable for many computer vision applications, decomposing a natural image into intrinsic reflectance and shading layers represents a challenging, underdetermined inverse problem. As opposed to strict reliance on conventional optimization or filtering solutions with strong prior assumptions, deep learning based approaches have also been proposed to compute intrinsic image decompositions when granted access to sufficient labeled training data. The downside is that current data sources are quite limited, and broadly speaking fall into one of two categories: either dense fully-labeled images in synthetic/narrow settings, or weakly-labeled data from relatively diverse natural scenes. In contrast to many previous learning-based approaches, which are often tailored to the structure of a particular dataset (and may not work well on others), we adopt core network structures that universally reflect loose prior knowledge regarding the intrinsic image formation process and can be largely shared across datasets. We then apply flexibly supervised loss layers that are customized for each source of ground truth labels. The resulting deep architecture achieves state-of-the-art results on all of the major intrinsic image benchmarks, and runs considerably faster than most at test time.
Writing by Memorizing: Hierarchical Retrieval-based Medical Report Generation
May 25, 2021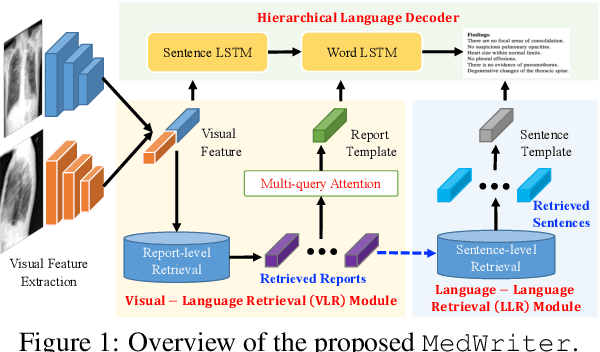
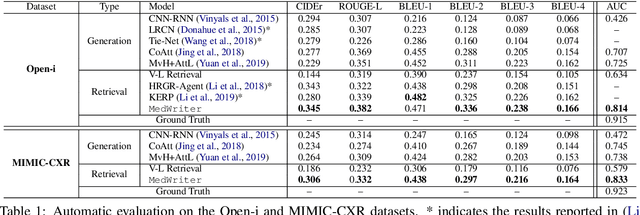
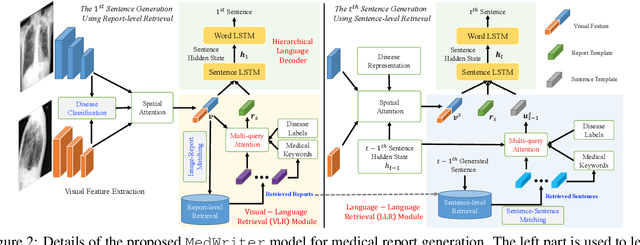
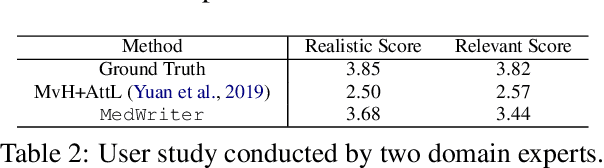
Medical report generation is one of the most challenging tasks in medical image analysis. Although existing approaches have achieved promising results, they either require a predefined template database in order to retrieve sentences or ignore the hierarchical nature of medical report generation. To address these issues, we propose MedWriter that incorporates a novel hierarchical retrieval mechanism to automatically extract both report and sentence-level templates for clinically accurate report generation. MedWriter first employs the Visual-Language Retrieval~(VLR) module to retrieve the most relevant reports for the given images. To guarantee the logical coherence between sentences, the Language-Language Retrieval~(LLR) module is introduced to retrieve relevant sentences based on the previous generated description. At last, a language decoder fuses image features and features from retrieved reports and sentences to generate meaningful medical reports. We verified the effectiveness of our model by automatic evaluation and human evaluation on two datasets, i.e., Open-I and MIMIC-CXR.
A Curated Image Parameter Dataset from Solar Dynamics Observatory Mission
Jun 03, 2019


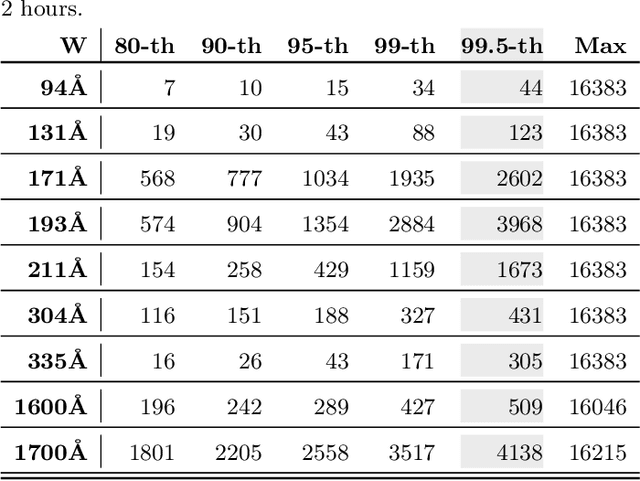
We provide a large image parameter dataset extracted from the Solar Dynamics Observatory (SDO) mission's AIA instrument, for the period of January 2011 through the current date, with the cadence of six minutes, for nine wavelength channels. The volume of the dataset for each year is just short of 1 TiB. Towards achieving better results in the region classification of active regions and coronal holes, we improve upon the performance of a set of ten image parameters, through an in depth evaluation of various assumptions that are necessary for calculation of these image parameters. Then, where possible, a method for finding an appropriate settings for the parameter calculations was devised, as well as a validation task to show our improved results. In addition, we include comparisons of JP2 and FITS image formats using supervised classification models, by tuning the parameters specific to the format of the images from which they are extracted, and specific to each wavelength. The results of these comparisons show that utilizing JP2 images, which are significantly smaller files, is not detrimental to the region classification task that these parameters were originally intended for. Finally, we compute the tuned parameters on the AIA images and provide a public API (http://dmlab.cs.gsu.edu/dmlabapi) to access the dataset. This dataset can be used in a range of studies on AIA images, such as content-based image retrieval or tracking of solar events, where dimensionality reduction on the images is necessary for feasibility of the tasks.
Visual resemblance and communicative context constrain the emergence of graphical conventions
Sep 17, 2021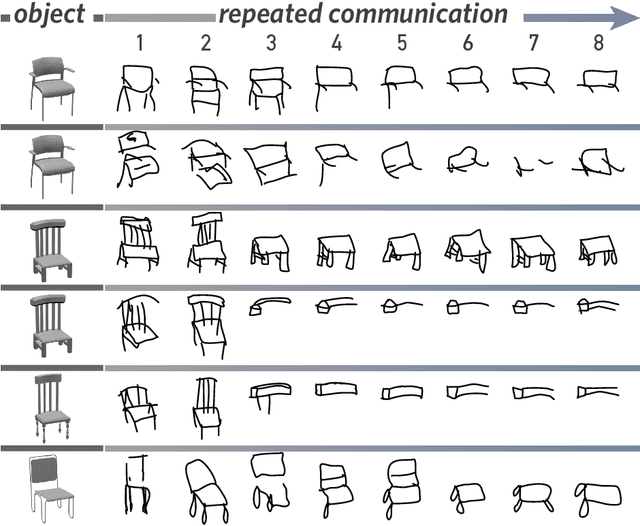
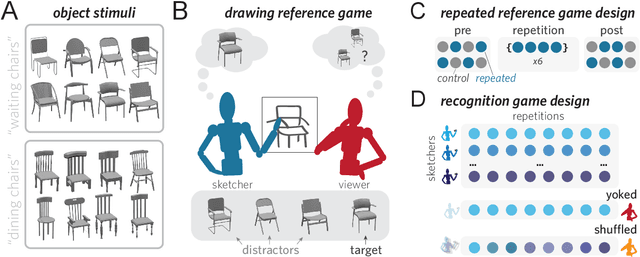
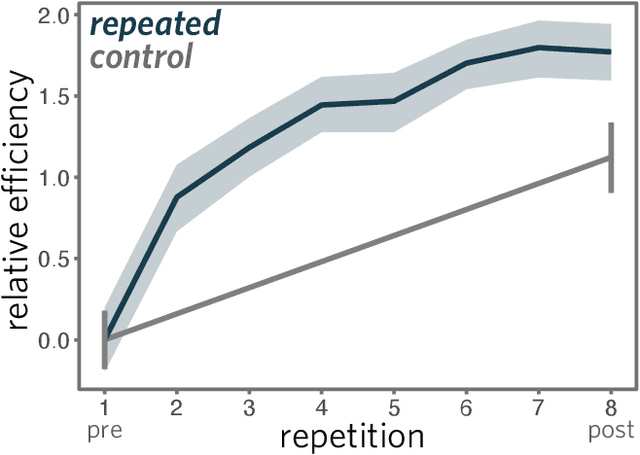
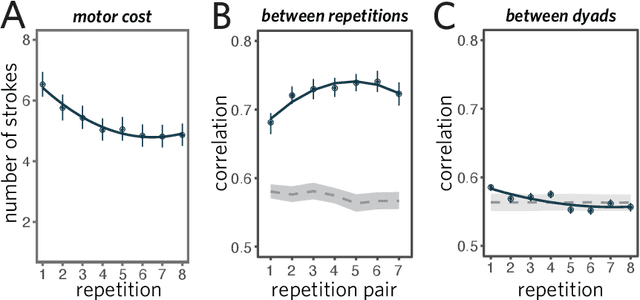
From photorealistic sketches to schematic diagrams, drawing provides a versatile medium for communicating about the visual world. How do images spanning such a broad range of appearances reliably convey meaning? Do viewers understand drawings based solely on their ability to resemble the entities they refer to (i.e., as images), or do they understand drawings based on shared but arbitrary associations with these entities (i.e., as symbols)? In this paper, we provide evidence for a cognitive account of pictorial meaning in which both visual and social information is integrated to support effective visual communication. To evaluate this account, we used a communication task where pairs of participants used drawings to repeatedly communicate the identity of a target object among multiple distractor objects. We manipulated social cues across three experiments and a full internal replication, finding pairs of participants develop referent-specific and interaction-specific strategies for communicating more efficiently over time, going beyond what could be explained by either task practice or a pure resemblance-based account alone. Using a combination of model-based image analyses and crowdsourced sketch annotations, we further determined that drawings did not drift toward arbitrariness, as predicted by a pure convention-based account, but systematically preserved those visual features that were most distinctive of the target object. Taken together, these findings advance theories of pictorial meaning and have implications for how successful graphical conventions emerge via complex interactions between visual perception, communicative experience, and social context.
Robust Method for Semantic Segmentation of Whole-Slide Blood Cell Microscopic Image
Jan 28, 2020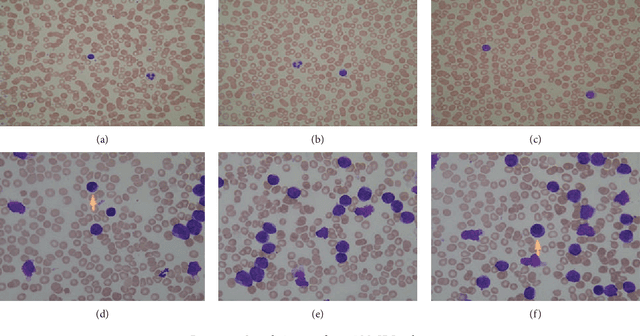
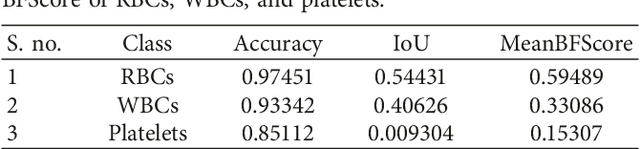

Previous works on segmentation of SEM (scanning electron microscope) blood cell image ignore the semantic segmentation approach of whole-slide blood cell segmentation. In the proposed work, we address the problem of whole-slide blood cell segmentation using the semantic segmentation approach. We design a novel convolutional encoder-decoder framework along with VGG-16 as the pixel-level feature extraction model. -e proposed framework comprises 3 main steps: First, all the original images along with manually generated ground truth masks of each blood cell type are passed through the preprocessing stage. In the preprocessing stage, pixel-level labeling, RGB to grayscale conversion of masked image and pixel fusing, and unity mask generation are performed. After that, VGG16 is loaded into the system, which acts as a pretrained pixel-level feature extraction model. In the third step, the training process is initiated on the proposed model. We have evaluated our network performance on three evaluation metrics. We obtained outstanding results with respect to classwise, as well as global and mean accuracies. Our system achieved classwise accuracies of 97.45%, 93.34%, and 85.11% for RBCs, WBCs, and platelets, respectively, while global and mean accuracies remain 97.18% and 91.96%, respectively.
* 13 pages, 13 figures
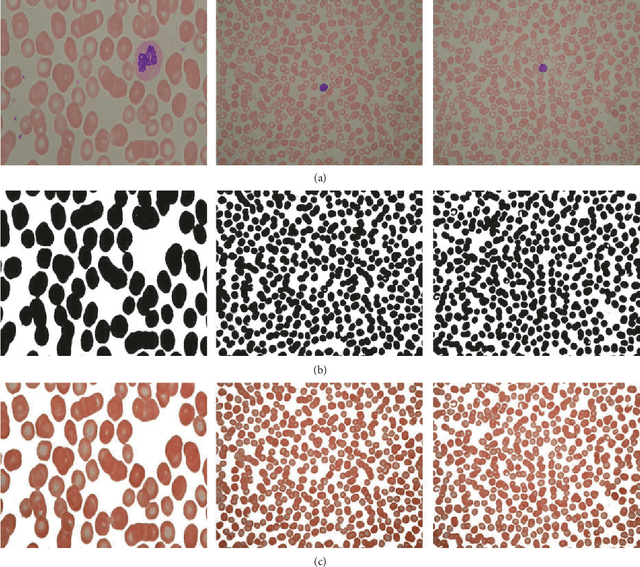
Fine-grained Attention and Feature-sharing Generative Adversarial Networks for Single Image Super-Resolution
Nov 25, 2019
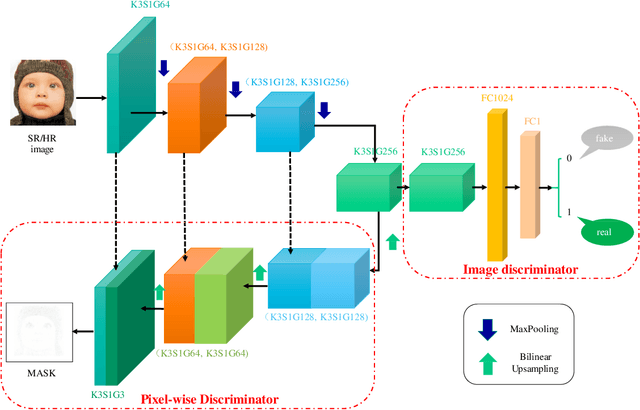
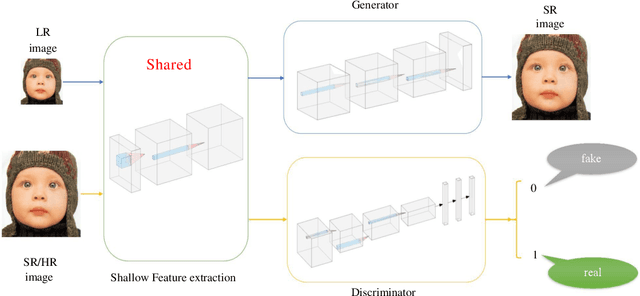
The traditional super-resolution methods that aim to minimize the mean square error usually produce the images with over-smoothed and blurry edges, due to the lose of high-frequency details. In this paper, we propose two novel techniques in the generative adversarial networks to produce photo-realistic images for image super-resolution. Firstly, instead of producing a single score to discriminate images between real and fake, we propose a variant, called Fine-grained Attention Generative Adversarial Network for image super-resolution (FASRGAN), to discriminate each pixel between real and fake. FASRGAN adopts a Unet-like network as the discriminator with two outputs: an image score and an image score map. The score map has the same spatial size as the HR/SR images, serving as the fine-grained attention to represent the degree of reconstruction difficulty for each pixel. Secondly, instead of using different networks for the generator and the discriminator in the SR problem, we use a feature-sharing network (Fs-SRGAN) for both the generator and the discriminator. By network sharing, certain information is shared between the generator and the discriminator, which in turn can improve the ability of producing high-quality images. Quantitative and visual comparisons with the state-of-the-art methods on the benchmark datasets demonstrate the superiority of our methods. The application of super-resolution images to object recognition further proves that the proposed methods endow the power to reconstruction capabilities and the excellent super-resolution effects.
Spatial Transformer Networks for Curriculum Learning
Aug 22, 2021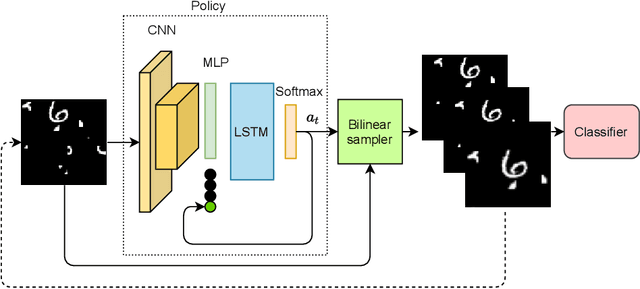



Curriculum learning is a bio-inspired training technique that is widely adopted to machine learning for improved optimization and better training of neural networks regarding the convergence rate or obtained accuracy. The main concept in curriculum learning is to start the training with simpler tasks and gradually increase the level of difficulty. Therefore, a natural question is how to determine or generate these simpler tasks. In this work, we take inspiration from Spatial Transformer Networks (STNs) in order to form an easy-to-hard curriculum. As STNs have been proven to be capable of removing the clutter from the input images and obtaining higher accuracy in image classification tasks, we hypothesize that images processed by STNs can be seen as easier tasks and utilized in the interest of curriculum learning. To this end, we study multiple strategies developed for shaping the training curriculum, using the data generated by STNs. We perform various experiments on cluttered MNIST and Fashion-MNIST datasets, where on the former, we obtain an improvement of $3.8$pp in classification accuracy compared to the baseline.
Residual Attention: A Simple but Effective Method for Multi-Label Recognition
Aug 05, 2021
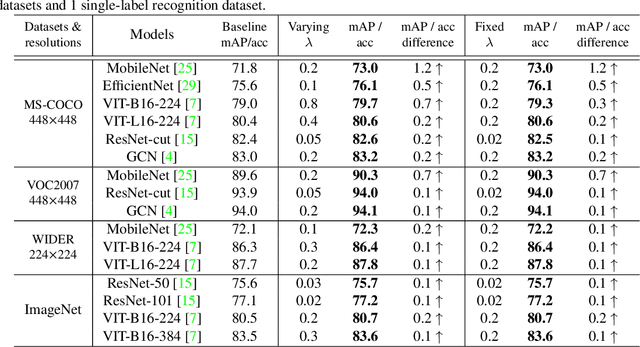
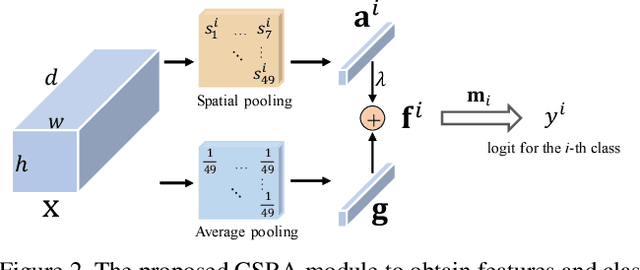
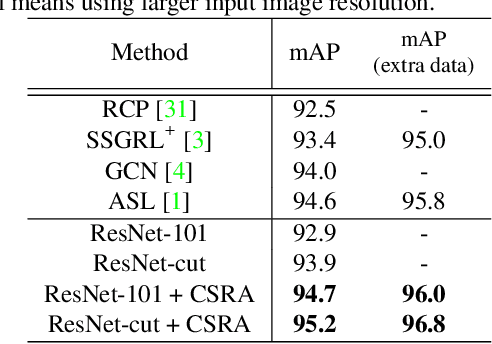
Multi-label image recognition is a challenging computer vision task of practical use. Progresses in this area, however, are often characterized by complicated methods, heavy computations, and lack of intuitive explanations. To effectively capture different spatial regions occupied by objects from different categories, we propose an embarrassingly simple module, named class-specific residual attention (CSRA). CSRA generates class-specific features for every category by proposing a simple spatial attention score, and then combines it with the class-agnostic average pooling feature. CSRA achieves state-of-the-art results on multilabel recognition, and at the same time is much simpler than them. Furthermore, with only 4 lines of code, CSRA also leads to consistent improvement across many diverse pretrained models and datasets without any extra training. CSRA is both easy to implement and light in computations, which also enjoys intuitive explanations and visualizations.
Iteratively-Refined Interactive 3D Medical Image Segmentation with Multi-Agent Reinforcement Learning
Nov 23, 2019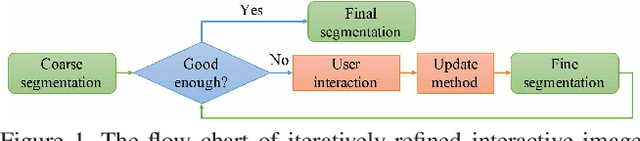
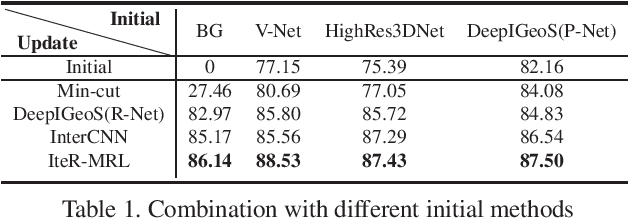
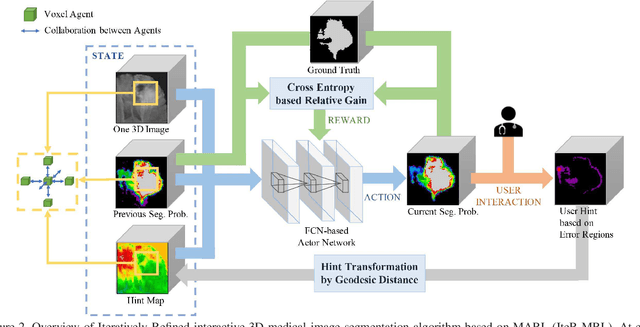
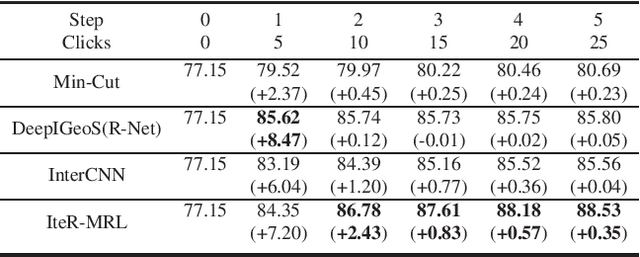
Existing automatic 3D image segmentation methods usually fail to meet the clinic use. Many studies have explored an interactive strategy to improve the image segmentation performance by iteratively incorporating user hints. However, the dynamic process for successive interactions is largely ignored. We here propose to model the dynamic process of iterative interactive image segmentation as a Markov decision process (MDP) and solve it with reinforcement learning (RL). Unfortunately, it is intractable to use single-agent RL for voxel-wise prediction due to the large exploration space. To reduce the exploration space to a tractable size, we treat each voxel as an agent with a shared voxel-level behavior strategy so that it can be solved with multi-agent reinforcement learning. An additional advantage of this multi-agent model is to capture the dependency among voxels for segmentation task. Meanwhile, to enrich the information of previous segmentations, we reserve the prediction uncertainty in the state space of MDP and derive an adjustment action space leading to a more precise and finer segmentation. In addition, to improve the efficiency of exploration, we design a relative cross-entropy gain-based reward to update the policy in a constrained direction. Experimental results on various medical datasets have shown that our method significantly outperforms existing state-of-the-art methods, with the advantage of fewer interactions and a faster convergence.
Synthetic Learning: Learn From Distributed Asynchronized Discriminator GAN Without Sharing Medical Image Data
Jun 14, 2020

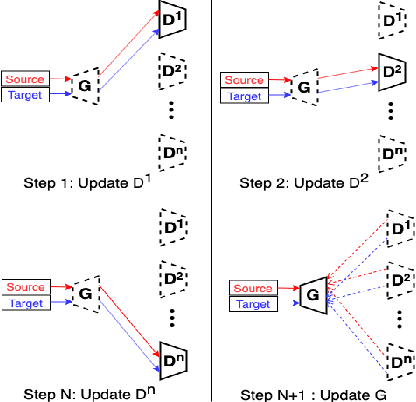
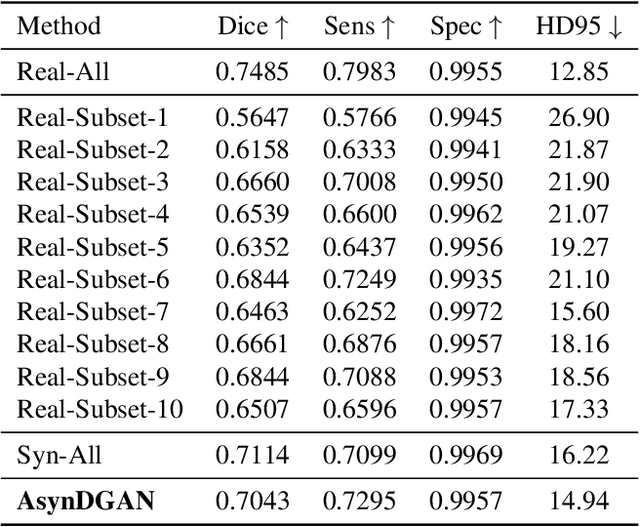
In this paper, we propose a data privacy-preserving and communication efficient distributed GAN learning framework named Distributed Asynchronized Discriminator GAN (AsynDGAN). Our proposed framework aims to train a central generator learns from distributed discriminator, and use the generated synthetic image solely to train the segmentation model.We validate the proposed framework on the application of health entities learning problem which is known to be privacy sensitive. Our experiments show that our approach: 1) could learn the real image's distribution from multiple datasets without sharing the patient's raw data. 2) is more efficient and requires lower bandwidth than other distributed deep learning methods. 3) achieves higher performance compared to the model trained by one real dataset, and almost the same performance compared to the model trained by all real datasets. 4) has provable guarantees that the generator could learn the distributed distribution in an all important fashion thus is unbiased.