 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCO-EVOLVE: Bidirectional Co-Evolution of Graph Structure and Semantics for Heterophilous Learning
Mar 20, 2026The integration of Large Language Models (LLMs) and Graph Neural Networks (GNNs) promises to unify semantic understanding with structural reasoning, yet existing methods typically rely on static, unidirectional pipelines. These approaches suffer from fundamental limitations: (1) Bidirectional Error Propagation, where semantic hallucinations in LLMs or structural noise in GNNs permanently poison the downstream modality without opportunity for recourse; (2) Semantic-Structural Dissonance, particularly in heterophilous settings where textual similarity contradicts topological reality; (3) a Blind Leading the Blind phenomenon, where indiscriminate alignment forces models to mirror each other's mistakes regardless of uncertainty. To address these challenges, we propose CO-EVOLVE, a dual-view co-evolution framework that treats graph topology and semantic embeddings as dynamic, mutually reinforcing latent variables. By employing a Gauss-Seidel alternating optimization strategy, our framework establishes a cyclic feedback loop: the GNN injects structural context as Soft Prompts to guide the LLM, while the LLM constructs favorable Dynamic Semantic Graphs to rewire the GNN. We introduce three key innovations to stabilize this evolution: (1) a Hard-Structure Conflict-Aware Contrastive Loss that warps the semantic manifold to respect high-order topological boundaries; (2) an Adaptive Node Gating Mechanism that dynamically fuses static and learnable structures to recover missing links; (3) an Uncertainty-Gated Consistency strategy that enables meta-cognitive alignment, ensuring models only learn from the confident view. Finally, an Entropy-Aware Adaptive Fusion integrates predictions during inference. Extensive experiments on public benchmarks demonstrate that CO-EVOLVE significantly outperforms state-of-the-art baselines, achieving average improvements of 9.07% in Accuracy and 7.19% in F1-score.
GlobalGeoTree: A Multi-Granular Vision-Language Dataset for Global Tree Species Classification
May 18, 2025



Global tree species mapping using remote sensing data is vital for biodiversity monitoring, forest management, and ecological research. However, progress in this field has been constrained by the scarcity of large-scale, labeled datasets. To address this, we introduce GlobalGeoTree, a comprehensive global dataset for tree species classification. GlobalGeoTree comprises 6.3 million geolocated tree occurrences, spanning 275 families, 2,734 genera, and 21,001 species across the hierarchical taxonomic levels. Each sample is paired with Sentinel-2 image time series and 27 auxiliary environmental variables, encompassing bioclimatic, geographic, and soil data. The dataset is partitioned into GlobalGeoTree-6M for model pretraining and curated evaluation subsets, primarily GlobalGeoTree-10kEval for zero-shot and few-shot benchmarking. To demonstrate the utility of the dataset, we introduce a baseline model, GeoTreeCLIP, which leverages paired remote sensing data and taxonomic text labels within a vision-language framework pretrained on GlobalGeoTree-6M. Experimental results show that GeoTreeCLIP achieves substantial improvements in zero- and few-shot classification on GlobalGeoTree-10kEval over existing advanced models. By making the dataset, models, and code publicly available, we aim to establish a benchmark to advance tree species classification and foster innovation in biodiversity research and ecological applications.
NetSight: Graph Attention Based Traffic Forecasting in Computer Networks
May 11, 2025The traffic in today's networks is increasingly influenced by the interactions among network nodes as well as by the temporal fluctuations in the demands of the nodes. Traditional statistical prediction methods are becoming obsolete due to their inability to address the non-linear and dynamic spatio-temporal dependencies present in today's network traffic. The most promising direction of research today is graph neural networks (GNNs) based prediction approaches that are naturally suited to handle graph-structured data. Unfortunately, the state-of-the-art GNN approaches separate the modeling of spatial and temporal information, resulting in the loss of important information about joint dependencies. These GNN based approaches further do not model information at both local and global scales simultaneously, leaving significant room for improvement. To address these challenges, we propose NetSight. NetSight learns joint spatio-temporal dependencies simultaneously at both global and local scales from the time-series of measurements of any given network metric collected at various nodes in a network. Using the learned information, NetSight can then accurately predict the future values of the given network metric at those nodes in the network. We propose several new concepts and techniques in the design of NetSight, such as spatio-temporal adjacency matrix and node normalization. Through extensive evaluations and comparison with prior approaches using data from two large real-world networks, we show that NetSight significantly outperforms all prior state-of-the-art approaches. We will release the source code and data used in the evaluation of NetSight on the acceptance of this paper.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025
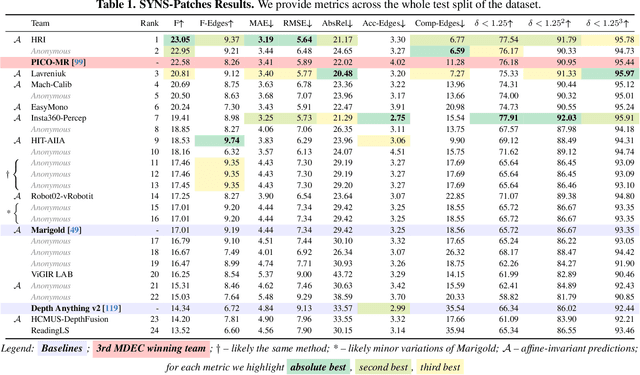
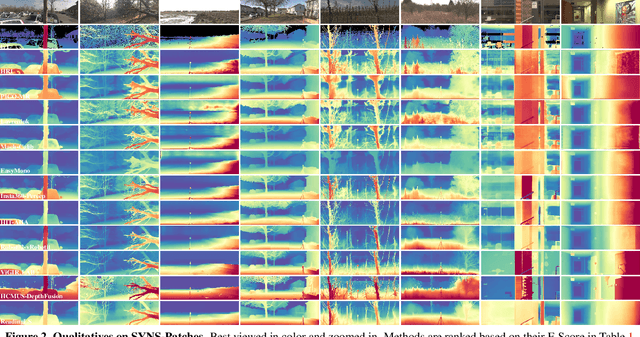
This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
MPTSNet: Integrating Multiscale Periodic Local Patterns and Global Dependencies for Multivariate Time Series Classification
Mar 07, 2025



Multivariate Time Series Classification (MTSC) is crucial in extensive practical applications, such as environmental monitoring, medical EEG analysis, and action recognition. Real-world time series datasets typically exhibit complex dynamics. To capture this complexity, RNN-based, CNN-based, Transformer-based, and hybrid models have been proposed. Unfortunately, current deep learning-based methods often neglect the simultaneous construction of local features and global dependencies at different time scales, lacking sufficient feature extraction capabilities to achieve satisfactory classification accuracy. To address these challenges, we propose a novel Multiscale Periodic Time Series Network (MPTSNet), which integrates multiscale local patterns and global correlations to fully exploit the inherent information in time series. Recognizing the multi-periodicity and complex variable correlations in time series, we use the Fourier transform to extract primary periods, enabling us to decompose data into multiscale periodic segments. Leveraging the inherent strengths of CNN and attention mechanism, we introduce the PeriodicBlock, which adaptively captures local patterns and global dependencies while offering enhanced interpretability through attention integration across different periodic scales. The experiments on UEA benchmark datasets demonstrate that the proposed MPTSNet outperforms 21 existing advanced baselines in the MTSC tasks.
Video Is Worth a Thousand Images: Exploring the Latest Trends in Long Video Generation
Dec 24, 2024An image may convey a thousand words, but a video composed of hundreds or thousands of image frames tells a more intricate story. Despite significant progress in multimodal large language models (MLLMs), generating extended videos remains a formidable challenge. As of this writing, OpenAI's Sora, the current state-of-the-art system, is still limited to producing videos that are up to one minute in length. This limitation stems from the complexity of long video generation, which requires more than generative AI techniques for approximating density functions essential aspects such as planning, story development, and maintaining spatial and temporal consistency present additional hurdles. Integrating generative AI with a divide-and-conquer approach could improve scalability for longer videos while offering greater control. In this survey, we examine the current landscape of long video generation, covering foundational techniques like GANs and diffusion models, video generation strategies, large-scale training datasets, quality metrics for evaluating long videos, and future research areas to address the limitations of the existing video generation capabilities. We believe it would serve as a comprehensive foundation, offering extensive information to guide future advancements and research in the field of long video generation.
How Certain are Uncertainty Estimates? Three Novel Earth Observation Datasets for Benchmarking Uncertainty Quantification in Machine Learning
Dec 09, 2024



Uncertainty quantification (UQ) is essential for assessing the reliability of Earth observation (EO) products. However, the extensive use of machine learning models in EO introduces an additional layer of complexity, as those models themselves are inherently uncertain. While various UQ methods do exist for machine learning models, their performance on EO datasets remains largely unevaluated. A key challenge in the community is the absence of the ground truth for uncertainty, i.e. how certain the uncertainty estimates are, apart from the labels for the image/signal. This article fills this gap by introducing three benchmark datasets specifically designed for UQ in EO machine learning models. These datasets address three common problem types in EO: regression, image segmentation, and scene classification. They enable a transparent comparison of different UQ methods for EO machine learning models. We describe the creation and characteristics of each dataset, including data sources, preprocessing steps, and label generation, with a particular focus on calculating the reference uncertainty. We also showcase baseline performance of several machine learning models on each dataset, highlighting the utility of these benchmarks for model development and comparison. Overall, this article offers a valuable resource for researchers and practitioners working in artificial intelligence for EO, promoting a more accurate and reliable quality measure of the outputs of machine learning models. The dataset and code are accessible via https://gitlab.lrz.de/ai4eo/WG_Uncertainty.
NimbleD: Enhancing Self-supervised Monocular Depth Estimation with Pseudo-labels and Large-scale Video Pre-training
Aug 26, 2024



We introduce NimbleD, an efficient self-supervised monocular depth estimation learning framework that incorporates supervision from pseudo-labels generated by a large vision model. This framework does not require camera intrinsics, enabling large-scale pre-training on publicly available videos. Our straightforward yet effective learning strategy significantly enhances the performance of fast and lightweight models without introducing any overhead, allowing them to achieve performance comparable to state-of-the-art self-supervised monocular depth estimation models. This advancement is particularly beneficial for virtual and augmented reality applications requiring low latency inference. The source code, model weights, and acknowledgments are available at https://github.com/xapaxca/nimbled .
The Third Monocular Depth Estimation Challenge
Apr 27, 2024



This paper discusses the results of the third edition of the Monocular Depth Estimation Challenge (MDEC). The challenge focuses on zero-shot generalization to the challenging SYNS-Patches dataset, featuring complex scenes in natural and indoor settings. As with the previous edition, methods can use any form of supervision, i.e. supervised or self-supervised. The challenge received a total of 19 submissions outperforming the baseline on the test set: 10 among them submitted a report describing their approach, highlighting a diffused use of foundational models such as Depth Anything at the core of their method. The challenge winners drastically improved 3D F-Score performance, from 17.51% to 23.72%.
Structured Radial Basis Function Network: Modelling Diversity for Multiple Hypotheses Prediction
Sep 02, 2023



Multi-modal regression is important in forecasting nonstationary processes or with a complex mixture of distributions. It can be tackled with multiple hypotheses frameworks but with the difficulty of combining them efficiently in a learning model. A Structured Radial Basis Function Network is presented as an ensemble of multiple hypotheses predictors for regression problems. The predictors are regression models of any type that can form centroidal Voronoi tessellations which are a function of their losses during training. It is proved that this structured model can efficiently interpolate this tessellation and approximate the multiple hypotheses target distribution and is equivalent to interpolating the meta-loss of the predictors, the loss being a zero set of the interpolation error. This model has a fixed-point iteration algorithm between the predictors and the centers of the basis functions. Diversity in learning can be controlled parametrically by truncating the tessellation formation with the losses of individual predictors. A closed-form solution with least-squares is presented, which to the authors knowledge, is the fastest solution in the literature for multiple hypotheses and structured predictions. Superior generalization performance and computational efficiency is achieved using only two-layer neural networks as predictors controlling diversity as a key component of success. A gradient-descent approach is introduced which is loss-agnostic regarding the predictors. The expected value for the loss of the structured model with Gaussian basis functions is computed, finding that correlation between predictors is not an appropriate tool for diversification. The experiments show outperformance with respect to the top competitors in the literature.