 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Progress Toward AGI: A Cognitive Framework
May 27, 2026Despite widespread discussion of AGI, there is no clear framework for measuring progress toward it. This ambiguity fuels subjective claims, makes it difficult to track progress, and risks hindering responsible governance. As a starting point to address this gap, we present a framework for understanding system capabilities in relation to human cognitive abilities. Drawing from decades of research in psychology, neuroscience, and cognitive science, we introduce a Cognitive Taxonomy that deconstructs general intelligence into 10 key cognitive faculties. We then propose a rigorous evaluation protocol in which a system's performance is measured across a suite of targeted, held-out cognitive tasks, generating a 'cognitive profile' that can be used to understand a system's strengths and weaknesses. We hope this framework will provide a practical roadmap and an initial step toward more rigorous, empirical evaluation of AGI.
CORE: Contrastive Reflection Enables Rapid Improvements in Reasoning
May 27, 2026Language models can use verifiable rewards to improve at a wide variety of reasoning tasks. However, both parametric (e.g. RLVR) and non-parametric (e.g. prompt optimization) approaches to doing so typically require hundreds of training samples and thousands of model rollouts, making them expensive in the best case and intractable in the worst. To address this challenge, we introduce Contrastive Reflection (CORE), a non-parametric learning algorithm that compares past reasoning traces to generate insights: short natural-language descriptions of reasoning strategies and constraints that capture differences between successful and unsuccessful problem attempts. Across four reasoning tasks, we demonstrate that CORE enables more rapid improvement than both parametric (GRPO) and non-parametric (GEPA, episodic RAG, and MemRL) methods, while using fewer rollouts. Under fixed rollout budgets with as few as five training samples, we then show that CORE also achieves comparable or greater performance gains than each baseline. Finally, we highlight how CORE is also substantially more context-efficient than non-parametric baselines, requiring fewer prompt tokens while storing learned knowledge as compact, interpretable natural-language insights. Our results therefore suggest that distilling contrasts between successful and unsuccessful reasoning traces into abstract and useful insights can provide a more efficient and interpretable route to model self-improvement than weight updates, prompt optimization, or direct reuse of stored reasoning traces.
Neural Garbage Collection: Learning to Forget while Learning to Reason
Apr 20, 2026Chain-of-thought reasoning has driven striking advances in language model capability, yet every reasoning step grows the KV cache, creating a bottleneck to scaling this paradigm further. Current approaches manage these constraints on the model's behalf using hand-designed criteria. A more scalable approach would let end-to-end learning subsume this design choice entirely, following a broader pattern in deep learning. After all, if a model can learn to reason, why can't it learn to forget? We introduce Neural Garbage Collection (NGC), in which a language model learns to forget while learning to reason, trained end-to-end from outcome-based task reward alone. As the model reasons, it periodically pauses, decides which KV cache entries to evict, and continues to reason conditioned on the remaining cache. By treating tokens in a chain-of-thought and cache-eviction decisions as discrete actions sampled from the language model, we can use reinforcement learning to jointly optimize how the model reasons and how it manages its own memory: what the model evicts shapes what it remembers, what it remembers shapes its reasoning, and the correctness of that reasoning determines its reward. Crucially, the model learns this behavior entirely from a single learning signal - the outcome-based task reward - without supervised fine-tuning or proxy objectives. On Countdown, AMC, and AIME tasks, NGC maintains strong accuracy relative to the full-cache upper bound at 2-3x peak KV cache size compression and substantially outperforms eviction baselines. Our results are a first step towards a broader vision where end-to-end optimization drives both capability and efficiency in language models.
GIANTS: Generative Insight Anticipation from Scientific Literature
Apr 10, 2026Scientific breakthroughs often emerge from synthesizing prior ideas into novel contributions. While language models (LMs) show promise in scientific discovery, their ability to perform this targeted, literature-grounded synthesis remains underexplored. We introduce insight anticipation, a generation task in which a model predicts a downstream paper's core insight from its foundational parent papers. To evaluate this capability, we develop GiantsBench, a benchmark of 17k examples across eight scientific domains, where each example consists of a set of parent papers paired with the core insight of a downstream paper. We evaluate models using an LM judge that scores similarity between generated and ground-truth insights, and show that these similarity scores correlate with expert human ratings. Finally, we present GIANTS-4B, an LM trained via reinforcement learning (RL) to optimize insight anticipation using these similarity scores as a proxy reward. Despite its smaller open-source architecture, GIANTS-4B outperforms proprietary baselines and generalizes to unseen domains, achieving a 34% relative improvement in similarity score over gemini-3-pro. Human evaluations further show that GIANTS-4B produces insights that are more conceptually clear than those of the base model. In addition, SciJudge-30B, a third-party model trained to compare research abstracts by likely citation impact, predicts that insights generated by GIANTS-4B are more likely to lead to higher citations, preferring them over the base model in 68% of pairwise comparisons. We release our code, benchmark, and model to support future research in automated scientific discovery.
Endless Terminals: Scaling RL Environments for Terminal Agents
Jan 27, 2026Environments are the bottleneck for self-improving agents. Current terminal benchmarks were built for evaluation, not training; reinforcement learning requires a scalable pipeline, not just a dataset. We introduce Endless Terminals, a fully autonomous pipeline that procedurally generates terminal-use tasks without human annotation. The pipeline has four stages: generating diverse task descriptions, building and validating containerized environments, producing completion tests, and filtering for solvability. From this pipeline we obtain 3255 tasks spanning file operations, log management, data processing, scripting, and database operations. We train agents using vanilla PPO with binary episode level rewards and a minimal interaction loop: no retrieval, multi-agent coordination, or specialized tools. Despite this simplicity, models trained on Endless Terminals show substantial gains: on our held-out dev set, Llama-3.2-3B improves from 4.0% to 18.2%, Qwen2.5-7B from 10.7% to 53.3%, and Qwen3-8B-openthinker-sft from 42.6% to 59.0%. These improvements transfer to human-curated benchmarks: models trained on Endless Terminals show substantial gains on held out human curated benchmarks: on TerminalBench 2.0, Llama-3.2-3B improves from 0.0% to 2.2%, Qwen2.5-7B from 2.2% to 3.4%, and Qwen3-8B-openthinker-sft from 1.1% to 6.7%, in each case outperforming alternative approaches including models with more complex agentic scaffolds. These results demonstrate that simple RL succeeds when environments scale.
Learning to Simulate Human Dialogue
Jan 07, 2026To predict what someone will say is to model how they think. We study this through next-turn dialogue prediction: given a conversation, predict the next utterance produced by a person. We compare learning approaches along two dimensions: (1) whether the model is allowed to think before responding, and (2) how learning is rewarded either through an LLM-as-a-judge that scores semantic similarity and information completeness relative to the ground-truth response, or by directly maximizing the log-probability of the true human dialogue. We find that optimizing for judge-based rewards indeed increases judge scores throughout training, however it decreases the likelihood assigned to ground truth human responses and decreases the win rate when human judges choose the most human-like response among a real and synthetic option. This failure is amplified when the model is allowed to think before answering. In contrast, by directly maximizing the log-probability of observed human responses, the model learns to better predict what people actually say, improving on both log-probability and win rate evaluations. Treating chain-of-thought as a latent variable, we derive a lower bound on the log-probability. Optimizing this objective yields the best results on all our evaluations. These results suggest that thinking helps primarily when trained with a distribution-matching objective grounded in real human dialogue, and that scaling this approach to broader conversational data may produce models with a more nuanced understanding of human behavior.
Scaling up the think-aloud method
May 29, 2025The think-aloud method, where participants voice their thoughts as they solve a task, is a valuable source of rich data about human reasoning processes. Yet, it has declined in popularity in contemporary cognitive science, largely because labor-intensive transcription and annotation preclude large sample sizes. Here, we develop methods to automate the transcription and annotation of verbal reports of reasoning using natural language processing tools, allowing for large-scale analysis of think-aloud data. In our study, 640 participants thought aloud while playing the Game of 24, a mathematical reasoning task. We automatically transcribed the recordings and coded the transcripts as search graphs, finding moderate inter-rater reliability with humans. We analyze these graphs and characterize consistency and variation in human reasoning traces. Our work demonstrates the value of think-aloud data at scale and serves as a proof of concept for the automated analysis of verbal reports.
Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs
Mar 03, 2025



Test-time inference has emerged as a powerful paradigm for enabling language models to ``think'' longer and more carefully about complex challenges, much like skilled human experts. While reinforcement learning (RL) can drive self-improvement in language models on verifiable tasks, some models exhibit substantial gains while others quickly plateau. For instance, we find that Qwen-2.5-3B far exceeds Llama-3.2-3B under identical RL training for the game of Countdown. This discrepancy raises a critical question: what intrinsic properties enable effective self-improvement? We introduce a framework to investigate this question by analyzing four key cognitive behaviors -- verification, backtracking, subgoal setting, and backward chaining -- that both expert human problem solvers and successful language models employ. Our study reveals that Qwen naturally exhibits these reasoning behaviors, whereas Llama initially lacks them. In systematic experimentation with controlled behavioral datasets, we find that priming Llama with examples containing these reasoning behaviors enables substantial improvements during RL, matching or exceeding Qwen's performance. Importantly, the presence of reasoning behaviors, rather than correctness of answers, proves to be the critical factor -- models primed with incorrect solutions containing proper reasoning patterns achieve comparable performance to those trained on correct solutions. Finally, leveraging continued pretraining with OpenWebMath data, filtered to amplify reasoning behaviors, enables the Llama model to match Qwen's self-improvement trajectory. Our findings establish a fundamental relationship between initial reasoning behaviors and the capacity for improvement, explaining why some language models effectively utilize additional computation while others plateau.
Non-literal Understanding of Number Words by Language Models
Feb 10, 2025
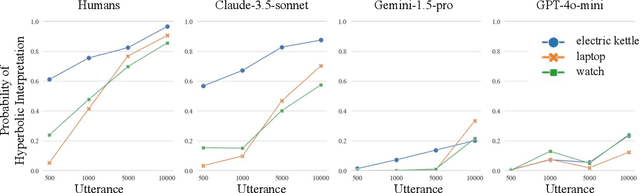

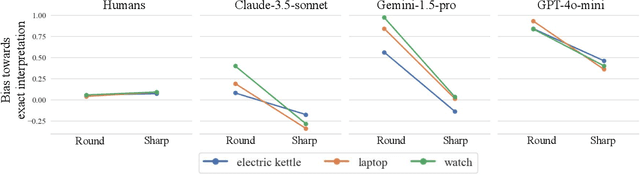
Humans naturally interpret numbers non-literally, effortlessly combining context, world knowledge, and speaker intent. We investigate whether large language models (LLMs) interpret numbers similarly, focusing on hyperbole and pragmatic halo effects. Through systematic comparison with human data and computational models of pragmatic reasoning, we find that LLMs diverge from human interpretation in striking ways. By decomposing pragmatic reasoning into testable components, grounded in the Rational Speech Act framework, we pinpoint where LLM processing diverges from human cognition -- not in prior knowledge, but in reasoning with it. This insight leads us to develop a targeted solution -- chain-of-thought prompting inspired by an RSA model makes LLMs' interpretations more human-like. Our work demonstrates how computational cognitive models can both diagnose AI-human differences and guide development of more human-like language understanding capabilities.
Emergent Symbol-like Number Variables in Artificial Neural Networks
Jan 10, 2025



What types of numeric representations emerge in Neural Networks (NNs)? To what degree do NNs induce abstract, mutable, slot-like numeric variables, and in what situations do these representations emerge? How do these representations change over learning, and how can we understand the neural implementations in ways that are unified across different NNs? In this work, we approach these questions by first training sequence based neural systems using Next Token Prediction (NTP) objectives on numeric tasks. We then seek to understand the neural solutions through the lens of causal abstractions or symbolic algorithms. We use a combination of causal interventions and visualization methods to find that artificial neural models do indeed develop analogs of interchangeable, mutable, latent number variables purely from the NTP objective. We then ask how variations on the tasks and model architectures affect the models' learned solutions to find that these symbol-like numeric representations do not form for every variant of the task, and transformers solve the problem in a notably different way than their recurrent counterparts. We then show how the symbol-like variables change over the course of training to find a strong correlation between the models' task performance and the alignment of their symbol-like representations. Lastly, we show that in all cases, some degree of gradience exists in these neural symbols, highlighting the difficulty of finding simple, interpretable symbolic stories of how neural networks perform numeric tasks. Taken together, our results are consistent with the view that neural networks can approximate interpretable symbolic programs of number cognition, but the particular program they approximate and the extent to which they approximate it can vary widely, depending on the network architecture, training data, extent of training, and network size.