 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Color Filter Arrays for Quanta Image Sensors
Mar 26, 2019

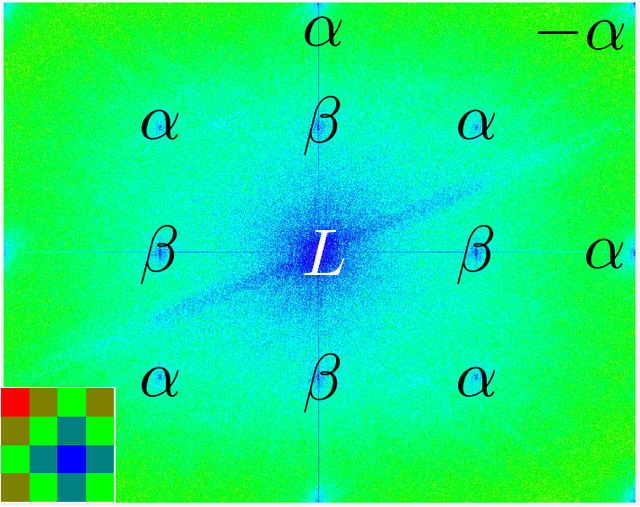

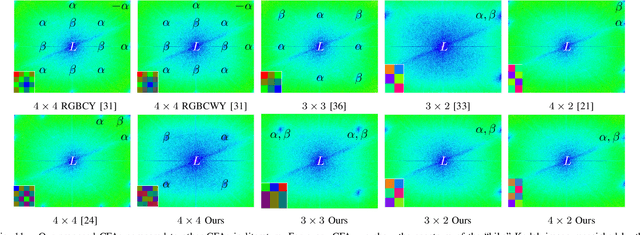
Quanta image sensor (QIS) is to be the next generation image sensor after CCD and CMOS. To enable such technology, significant progress was made over the past five years to advance both the device and image reconstruction algorithms. In this paper, we discuss color imaging using QIS, in particular how to design color filter arrays. Designing color filter arrays for QIS is challenging because at the pixel pitch of 1.1$\mu$m, maximizing the light efficiency while suppressing aliasing and crosstalk are conflicting tasks. We present an optimization-based framework to design color filter arrays for very small pixels. The new framework unifies several mainstream color filter array design frameworks by offering generality and flexibility. Compared to the existing frameworks which can only handle one or two design criteria, the new framework can simultaneously handle luminance gain, chrominance gain, cross-talk, anti-aliasing, manufacturability and orthogonality. Extensive experimental comparisons demonstrate the effectiveness and generality of the framework.
Selfie: Self-supervised Pretraining for Image Embedding
Jun 07, 2019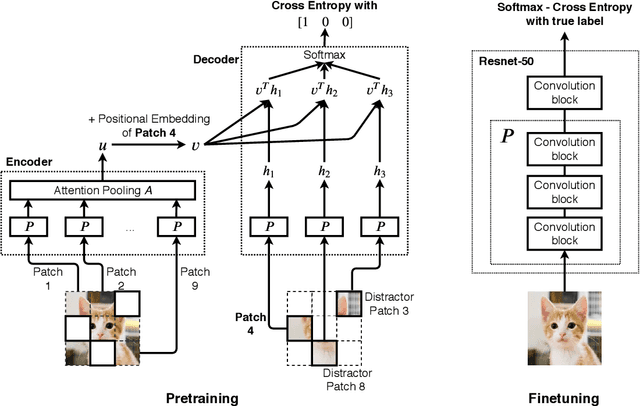
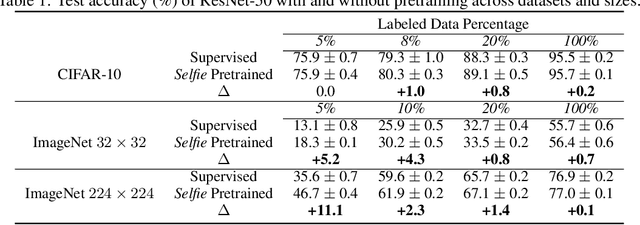

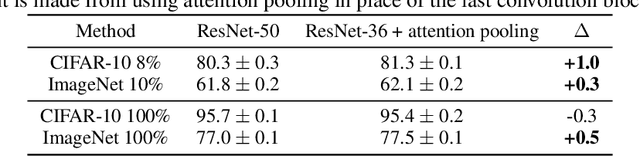
We introduce a pretraining technique called Selfie, which stands for SELF-supervised Image Embedding. Selfie generalizes the concept of masked language modeling to continuous data, such as images. Given masked-out patches in an input image, our method learns to select the correct patch, among other "distractor" patches sampled from the same image, to fill in the masked location. This classification objective sidesteps the need for predicting exact pixel values of the target patches. The pretraining architecture includes a network of convolutional blocks to process patches followed by an attention pooling network to summarize the content of unmasked patches before predicting masked ones. During finetuning, we reuse the convolutional weights found by pretraining. We evaluate our method on three benchmarks (CIFAR-10, ImageNet 32 x 32, and ImageNet 224 x 224) with varying amounts of labeled data, from 5% to 100% of the training sets. Our pretraining method provides consistent improvements to ResNet-50 across all settings compared to the standard supervised training of the same network. Notably, on ImageNet 224 x 224 with 60 examples per class (5%), our method improves the mean accuracy of ResNet-50 from 35.6% to 46.7%, an improvement of 11.1 points in absolute accuracy. Our pretraining method also improves ResNet-50 training stability, especially on low data regime, by significantly lowering the standard deviation of test accuracies across datasets.
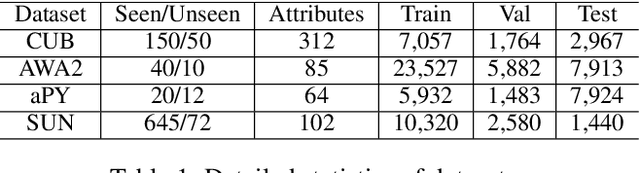
Task-Independent Knowledge Makes for Transferable Representations for Generalized Zero-Shot Learning
Apr 05, 2021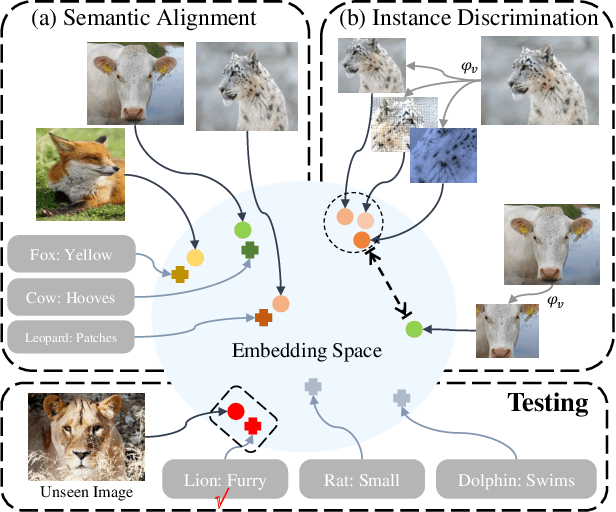
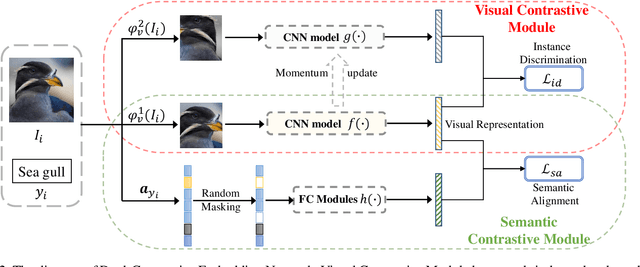
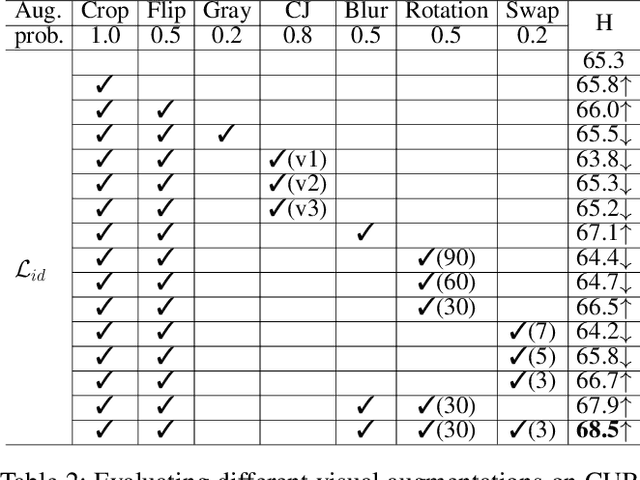
Generalized Zero-Shot Learning (GZSL) targets recognizing new categories by learning transferable image representations. Existing methods find that, by aligning image representations with corresponding semantic labels, the semantic-aligned representations can be transferred to unseen categories. However, supervised by only seen category labels, the learned semantic knowledge is highly task-specific, which makes image representations biased towards seen categories. In this paper, we propose a novel Dual-Contrastive Embedding Network (DCEN) that simultaneously learns task-specific and task-independent knowledge via semantic alignment and instance discrimination. First, DCEN leverages task labels to cluster representations of the same semantic category by cross-modal contrastive learning and exploring semantic-visual complementarity. Besides task-specific knowledge, DCEN then introduces task-independent knowledge by attracting representations of different views of the same image and repelling representations of different images. Compared to high-level seen category supervision, this instance discrimination supervision encourages DCEN to capture low-level visual knowledge, which is less biased toward seen categories and alleviates the representation bias. Consequently, the task-specific and task-independent knowledge jointly make for transferable representations of DCEN, which obtains averaged 4.1% improvement on four public benchmarks.
Greedy Gradient Ensemble for Robust Visual Question Answering
Aug 23, 2021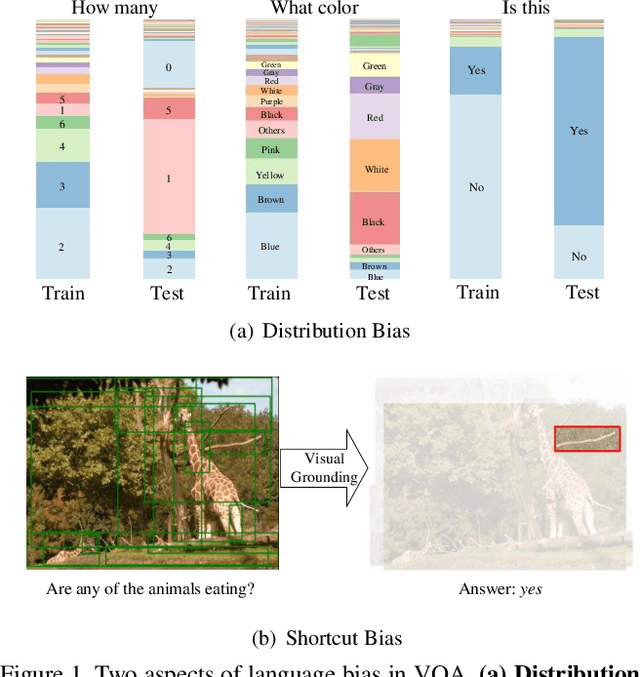
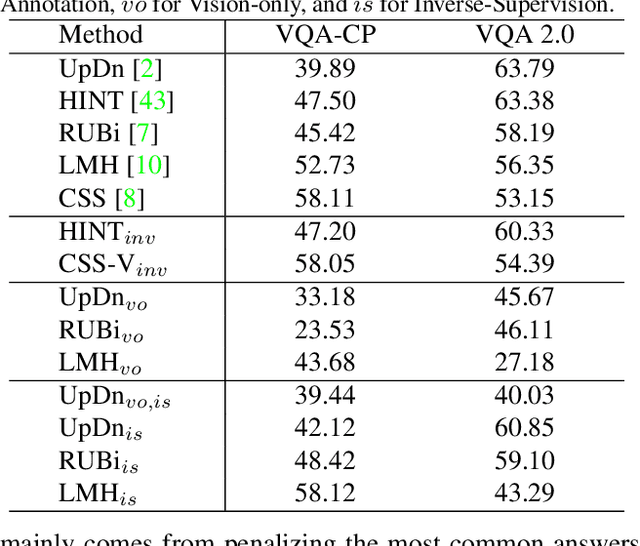
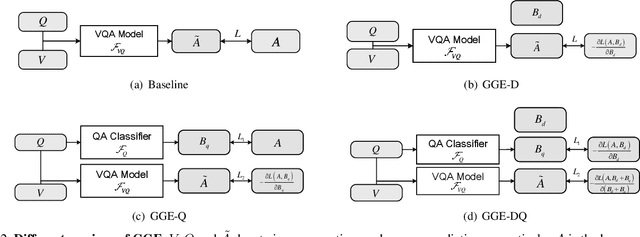
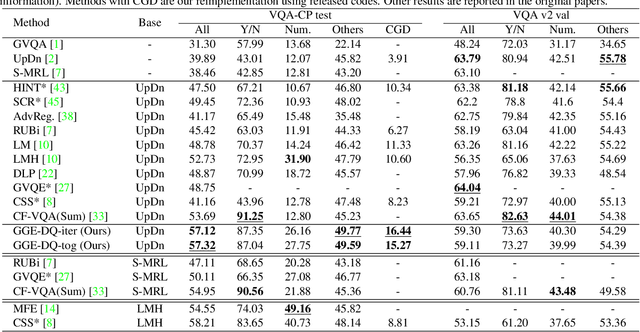
Language bias is a critical issue in Visual Question Answering (VQA), where models often exploit dataset biases for the final decision without considering the image information. As a result, they suffer from performance drop on out-of-distribution data and inadequate visual explanation. Based on experimental analysis for existing robust VQA methods, we stress the language bias in VQA that comes from two aspects, i.e., distribution bias and shortcut bias. We further propose a new de-bias framework, Greedy Gradient Ensemble (GGE), which combines multiple biased models for unbiased base model learning. With the greedy strategy, GGE forces the biased models to over-fit the biased data distribution in priority, thus makes the base model pay more attention to examples that are hard to solve by biased models. The experiments demonstrate that our method makes better use of visual information and achieves state-of-the-art performance on diagnosing dataset VQA-CP without using extra annotations.
Semantic Segmentation Alternative Technique: Segmentation Domain Generation
Jul 06, 2021


Detecting objects of interest in images was always a compelling task to automate. In recent years this task was more and more explored using deep learning techniques, mostly using region-based convolutional networks. In this project we propose an alternative semantic segmentation technique making use of Generative Adversarial Networks. We consider semantic segmentation to be a domain transfer problem. Thus, we train a feed forward network (FFNN) to receive as input a seed real image and generate as output its segmentation mask.
VITAL: A Visual Interpretation on Text with Adversarial Learning for Image Labeling
Aug 01, 2019
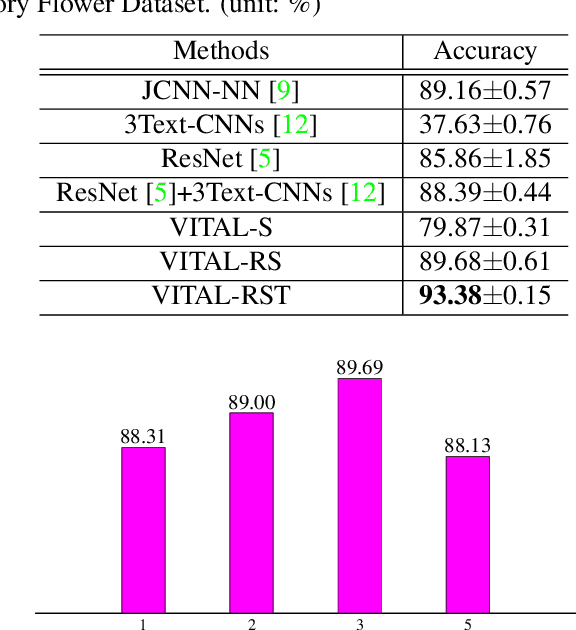
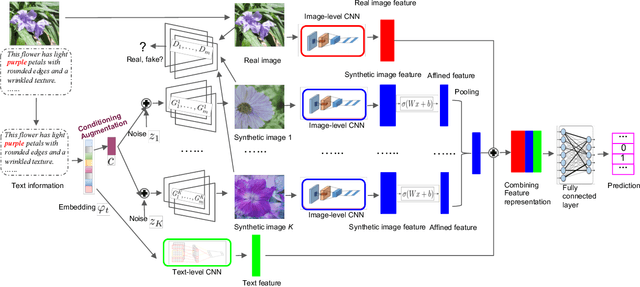
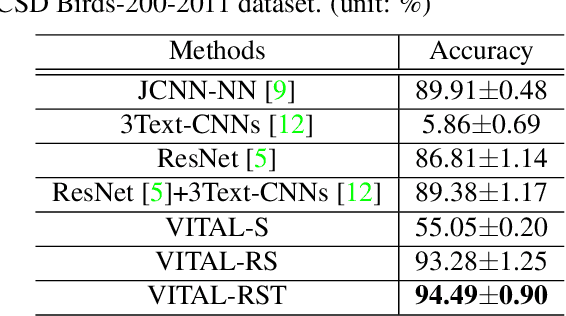
In this paper, we propose a novel way to interpret text information by extracting visual feature presentation from multiple high-resolution and photo-realistic synthetic images generated by Text-to-image Generative Adversarial Network (GAN) to improve the performance of image labeling. Firstly, we design a stacked Generative Multi-Adversarial Network (GMAN), StackGMAN++, a modified version of the current state-of-the-art Text-to-image GAN, StackGAN++, to generate multiple synthetic images with various prior noises conditioned on a text. And then we extract deep visual features from the generated synthetic images to explore the underlying visual concepts for text. Finally, we combine image-level visual feature, text-level feature and visual features based on synthetic images together to predict labels for images. We conduct experiments on two benchmark datasets and the experimental results clearly demonstrate the efficacy of our proposed approach.
Fourier-Domain Optimization for Image Processing
Sep 11, 2018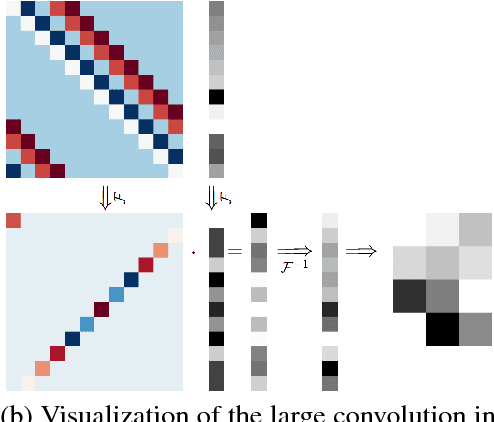
Image optimization problems encompass many applications such as spectral fusion, deblurring, deconvolution, dehazing, matting, reflection removal and image interpolation, among others. With current image sizes in the order of megabytes, it is extremely expensive to run conventional algorithms such as gradient descent, making them unfavorable especially when closed-form solutions can be derived and computed efficiently. This paper explains in detail the framework for solving convex image optimization and deconvolution in the Fourier domain. We begin by explaining the mathematical background and motivating why the presented setups can be transformed and solved very efficiently in the Fourier domain. We also show how to practically use these solutions, by providing the corresponding implementations. The explanations are aimed at a broad audience with minimal knowledge of convolution and image optimization. The eager reader can jump to Section 3 for a footprint of how to solve and implement a sample optimization function, and Section 5 for the more complex cases.
Occlusion-aware Visual Tracker using Spatial Structural Information and Dominant Features
Apr 16, 2021
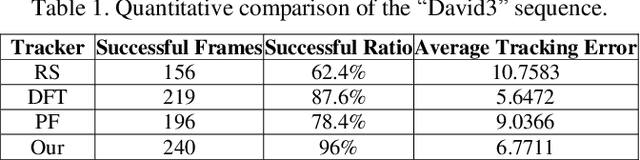

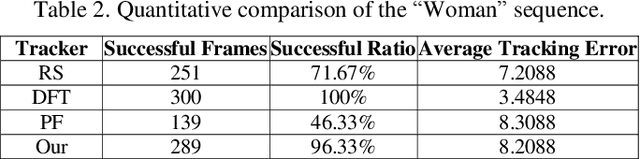
To overcome the problem of occlusion in visual tracking, this paper proposes an occlusion-aware tracking algorithm. The proposed algorithm divides the object into discrete image patches according to the pixel distribution of the object by means of clustering. To avoid the drifting of the tracker to false targets, the proposed algorithm extracts the dominant features, such as color histogram or histogram of oriented gradient orientation, from these image patches, and uses them as cues for tracking. To enhance the robustness of the tracker, the proposed algorithm employs an implicit spatial structure between these patches as another cue for tracking; Afterwards, the proposed algorithm incorporates these components into the particle filter framework, which results in a robust and precise tracker. Experimental results on color image sequences with different resolutions show that the proposed tracker outperforms the comparison algorithms on handling occlusion in visual tracking.
* 8 pages, 5 figures, Journal
BCNet: Learning Body and Cloth Shape from A Single Image
Apr 01, 2020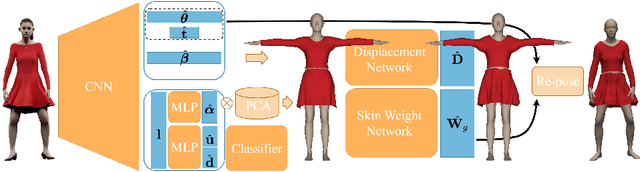
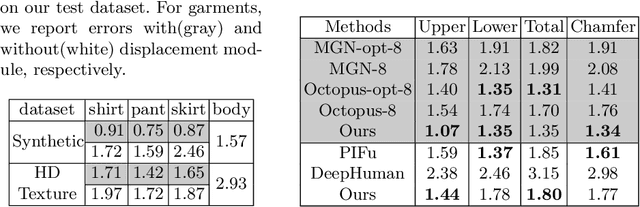
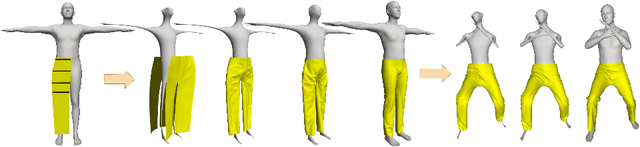

In this paper, we consider the problem to automatically reconstruct both garment and body shapes from a single near front view RGB image. To this end, we propose a layered garment representation on top of SMPL and novelly make the skinning weight of garment to be independent with the body mesh, which significantly improves the expression ability of our garment model. Compared with existing methods, our method can support more garment categories like skirts and recover more accurate garment geometry. To train our model, we construct two large scale datasets with ground truth body and garment geometries as well as paired color images. Compared with single mesh or non-parametric representation, our method can achieve more flexible control with separate meshes, makes applications like re-pose, garment transfer, and garment texture mapping possible.
Adversarial Attack Vulnerability of Medical Image Analysis Systems: Unexplored Factors
Jun 11, 2020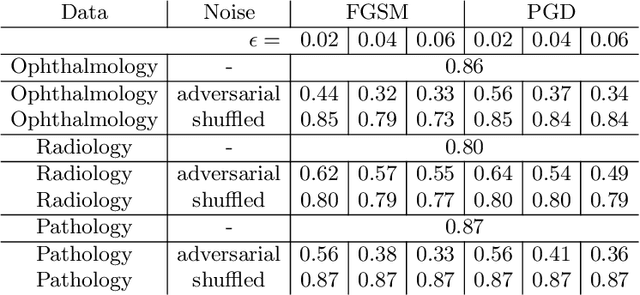
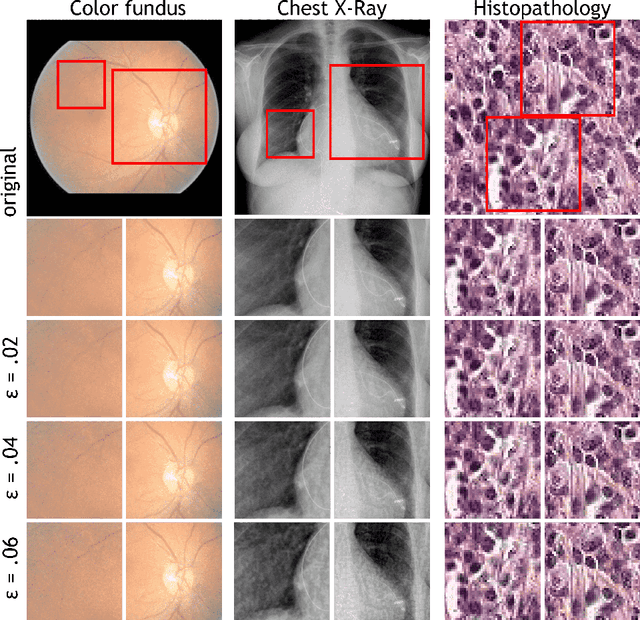
Adversarial attacks are considered a potentially serious security threat for machine learning systems. Medical image analysis (MedIA) systems have recently been argued to be particularly vulnerable to adversarial attacks due to strong financial incentives. In this paper, we study several previously unexplored factors affecting adversarial attack vulnerability of deep learning MedIA systems in three medical domains: ophthalmology, radiology and pathology. Firstly, we study the effect of varying the degree of adversarial perturbation on the attack performance and its visual perceptibility. Secondly, we study how pre-training on a public dataset (ImageNet) affects the models' vulnerability to attacks. Thirdly, we study the influence of data and model architecture disparity between target and attacker models. Our experiments show that the degree of perturbation significantly affects both performance and human perceptibility of attacks. Pre-training may dramatically increase the transfer of adversarial examples; the larger the performance gain achieved by pre-training, the larger the transfer. Finally, disparity in data and/or model architecture between target and attacker models substantially decreases the success of attacks. We believe that these factors should be considered when designing cybersecurity-critical MedIA systems, as well as kept in mind when evaluating their vulnerability to adversarial attacks. * indicates equal contribution