 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ColorVideoVDP: A visual difference predictor for image, video and display distortions
Jan 21, 2024
ColorVideoVDP is a video and image quality metric that models spatial and temporal aspects of vision, for both luminance and color. The metric is built on novel psychophysical models of chromatic spatiotemporal contrast sensitivity and cross-channel contrast masking. It accounts for the viewing conditions, geometric, and photometric characteristics of the display. It was trained to predict common video streaming distortions (e.g. video compression, rescaling, and transmission errors), and also 8 new distortion types related to AR/VR displays (e.g. light source and waveguide non-uniformities). To address the latter application, we collected our novel XR-Display-Artifact-Video quality dataset (XR-DAVID), comprised of 336 distorted videos. Extensive testing on XR-DAVID, as well as several datasets from the literature, indicate a significant gain in prediction performance compared to existing metrics. ColorVideoVDP opens the doors to many novel applications which require the joint automated spatiotemporal assessment of luminance and color distortions, including video streaming, display specification and design, visual comparison of results, and perceptually-guided quality optimization.
Exploring Compressed Image Representation as a Perceptual Proxy: A Study
Jan 14, 2024We propose an end-to-end learned image compression codec wherein the analysis transform is jointly trained with an object classification task. This study affirms that the compressed latent representation can predict human perceptual distance judgments with an accuracy comparable to a custom-tailored DNN-based quality metric. We further investigate various neural encoders and demonstrate the effectiveness of employing the analysis transform as a perceptual loss network for image tasks beyond quality judgments. Our experiments show that the off-the-shelf neural encoder proves proficient in perceptual modeling without needing an additional VGG network. We expect this research to serve as a valuable reference developing of a semantic-aware and coding-efficient neural encoder.
Using Perspective-n-Point Algorithms for a Local Positioning System Based on LEDs and a QADA Receiver
Feb 06, 2024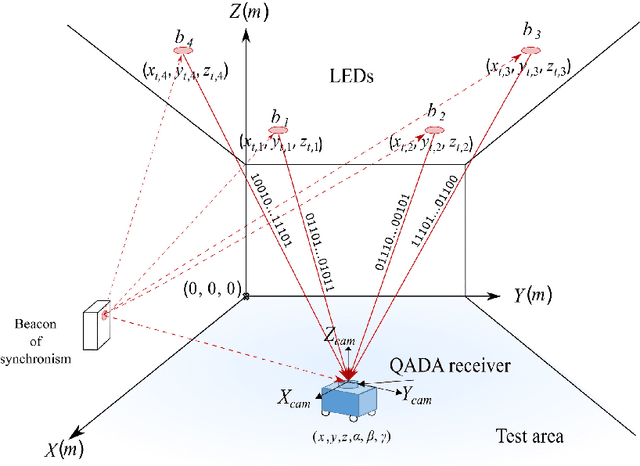

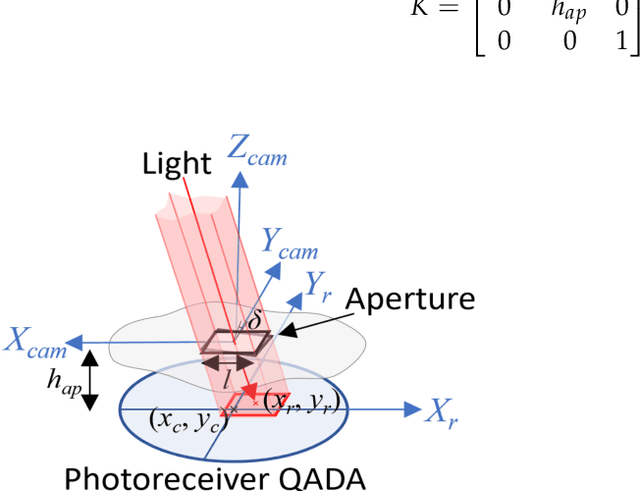
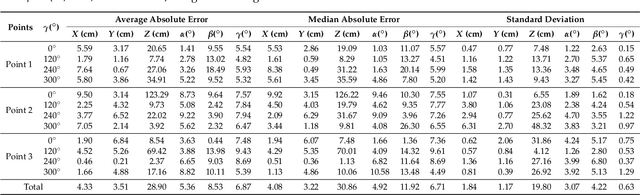
The research interest on location-based services has increased during the last years ever since 3D centimetre accuracy inside intelligent environments could be confronted with. This work proposes an indoor local positioning system based on LED lighting, transmitted from a set of beacons to a receiver.The receiver is based on a quadrant photodiode angular diversity aperture (QADA) plus an aperture placed over it.This configuration can be modelled as a perspective camera, where the image position of the transmitters can be used to recover the receiver's 3D pose. This process is known as the perspective-n-point (PnP) problem, which is well known in computer vision and photogrammetry. This work investigates the use of different state-of-the-art PnP algorithms to localize the receiver in a large space based on four co-planar transmitters and with a distance from transmitters to receiver of 3.4 m. Encoding techniques are used to permit the simultaneous emission of all the transmitted signals and their processing in the receiver. In addition, correlation techniques are used to determine the image points projected from each emitter on the QADA. This work uses Monte Carlo simulations to characterize the absolute errors for a grid of test points under noisy measurements, as well as the robustness of the system when varying the 3D location of one transmitter. The IPPE algorithm obtained the best performance in this configuration. The proposal has also been experimentally evaluated in a real setup. The estimation of the receiver's position at three points using the IPPE algorithm achieves average absolute errors of 4.33cm, 3.51cm and 28.90cm in the coordinates x, y and z, respectively. These positioning results are in line with those obtained in previous work using triangulation techniques but with the addition that the complete pose of the receiver is obtained in this proposal.
Intensive Vision-guided Network for Radiology Report Generation
Feb 06, 2024Automatic radiology report generation is booming due to its huge application potential for the healthcare industry. However, existing computer vision and natural language processing approaches to tackle this problem are limited in two aspects. First, when extracting image features, most of them neglect multi-view reasoning in vision and model single-view structure of medical images, such as space-view or channel-view. However, clinicians rely on multi-view imaging information for comprehensive judgment in daily clinical diagnosis. Second, when generating reports, they overlook context reasoning with multi-modal information and focus on pure textual optimization utilizing retrieval-based methods. We aim to address these two issues by proposing a model that better simulates clinicians' perspectives and generates more accurate reports. Given the above limitation in feature extraction, we propose a Globally-intensive Attention (GIA) module in the medical image encoder to simulate and integrate multi-view vision perception. GIA aims to learn three types of vision perception: depth view, space view, and pixel view. On the other hand, to address the above problem in report generation, we explore how to involve multi-modal signals to generate precisely matched reports, i.e., how to integrate previously predicted words with region-aware visual content in next word prediction. Specifically, we design a Visual Knowledge-guided Decoder (VKGD), which can adaptively consider how much the model needs to rely on visual information and previously predicted text to assist next word prediction. Hence, our final Intensive Vision-guided Network (IVGN) framework includes a GIA-guided Visual Encoder and the VKGD. Experiments on two commonly-used datasets IU X-Ray and MIMIC-CXR demonstrate the superior ability of our method compared with other state-of-the-art approaches.
ChatScratch: An AI-Augmented System Toward Autonomous Visual Programming Learning for Children Aged 6-12
Feb 07, 2024As Computational Thinking (CT) continues to permeate younger age groups in K-12 education, established CT platforms such as Scratch face challenges in catering to these younger learners, particularly those in the elementary school (ages 6-12). Through formative investigation with Scratch experts, we uncover three key obstacles to children's autonomous Scratch learning: artist's block in project planning, bounded creativity in asset creation, and inadequate coding guidance during implementation. To address these barriers, we introduce ChatScratch, an AI-augmented system to facilitate autonomous programming learning for young children. ChatScratch employs structured interactive storyboards and visual cues to overcome artist's block, integrates digital drawing and advanced image generation technologies to elevate creativity, and leverages Scratch-specialized Large Language Models (LLMs) for professional coding guidance. Our study shows that, compared to Scratch, ChatScratch efficiently fosters autonomous programming learning, and contributes to the creation of high-quality, personally meaningful Scratch projects for children.
Color Recognition in Challenging Lighting Environments: CNN Approach
Feb 07, 2024Light plays a vital role in vision either human or machine vision, the perceived color is always based on the lighting conditions of the surroundings. Researchers are working to enhance the color detection techniques for the application of computer vision. They have implemented proposed several methods using different color detection approaches but still, there is a gap that can be filled. To address this issue, a color detection method, which is based on a Convolutional Neural Network (CNN), is proposed. Firstly, image segmentation is performed using the edge detection segmentation technique to specify the object and then the segmented object is fed to the Convolutional Neural Network trained to detect the color of an object in different lighting conditions. It is experimentally verified that our method can substantially enhance the robustness of color detection in different lighting conditions, and our method performed better results than existing methods.
Guided Interpretable Facial Expression Recognition via Spatial Action Unit Cues
Feb 02, 2024While state-of-the-art facial expression recognition (FER) classifiers achieve a high level of accuracy, they lack interpretability, an important aspect for end-users. To recognize basic facial expressions, experts resort to a codebook associating a set of spatial action units to a facial expression. In this paper, we follow the same expert footsteps, and propose a learning strategy that allows us to explicitly incorporate spatial action units (aus) cues into the classifier's training to build a deep interpretable model. In particular, using this aus codebook, input image expression label, and facial landmarks, a single action units heatmap is built to indicate the most discriminative regions of interest in the image w.r.t the facial expression. We leverage this valuable spatial cue to train a deep interpretable classifier for FER. This is achieved by constraining the spatial layer features of a classifier to be correlated with \aus map. Using a composite loss, the classifier is trained to correctly classify an image while yielding interpretable visual layer-wise attention correlated with aus maps, simulating the experts' decision process. This is achieved using only the image class expression as supervision and without any extra manual annotations. Moreover, our method is generic. It can be applied to any CNN- or transformer-based deep classifier without the need for architectural change or adding significant training time. Our extensive evaluation on two public benchmarks RAFDB, and AFFECTNET datasets shows that our proposed strategy can improve layer-wise interpretability without degrading classification performance. In addition, we explore a common type of interpretable classifiers that rely on Class-Activation Mapping methods (CAMs), and we show that our training technique improves the CAM interpretability.
SAMF: Small-Area-Aware Multi-focus Image Fusion for Object Detection
Jan 16, 2024Existing multi-focus image fusion (MFIF) methods often fail to preserve the uncertain transition region and detect small focus areas within large defocused regions accurately. To address this issue, this study proposes a new small-area-aware MFIF algorithm for enhancing object detection capability. First, we enhance the pixel attributes within the small focus and boundary regions, which are subsequently combined with visual saliency detection to obtain the pre-fusion results used to discriminate the distribution of focused pixels. To accurately ensure pixel focus, we consider the source image as a combination of focused, defocused, and uncertain regions and propose a three-region segmentation strategy. Finally, we design an effective pixel selection rule to generate segmentation decision maps and obtain the final fusion results. Experiments demonstrated that the proposed method can accurately detect small and smooth focus areas while improving object detection performance, outperforming existing methods in both subjective and objective evaluations. The source code is available at https://github.com/ixilai/SAMF.
Knowledge Graphs Meet Multi-Modal Learning: A Comprehensive Survey
Feb 08, 2024Knowledge Graphs (KGs) play a pivotal role in advancing various AI applications, with the semantic web community's exploration into multi-modal dimensions unlocking new avenues for innovation. In this survey, we carefully review over 300 articles, focusing on KG-aware research in two principal aspects: KG-driven Multi-Modal (KG4MM) learning, where KGs support multi-modal tasks, and Multi-Modal Knowledge Graph (MM4KG), which extends KG studies into the MMKG realm. We begin by defining KGs and MMKGs, then explore their construction progress. Our review includes two primary task categories: KG-aware multi-modal learning tasks, such as Image Classification and Visual Question Answering, and intrinsic MMKG tasks like Multi-modal Knowledge Graph Completion and Entity Alignment, highlighting specific research trajectories. For most of these tasks, we provide definitions, evaluation benchmarks, and additionally outline essential insights for conducting relevant research. Finally, we discuss current challenges and identify emerging trends, such as progress in Large Language Modeling and Multi-modal Pre-training strategies. This survey aims to serve as a comprehensive reference for researchers already involved in or considering delving into KG and multi-modal learning research, offering insights into the evolving landscape of MMKG research and supporting future work.
Text Role Classification in Scientific Charts Using Multimodal Transformers
Feb 08, 2024Text role classification involves classifying the semantic role of textual elements within scientific charts. For this task, we propose to finetune two pretrained multimodal document layout analysis models, LayoutLMv3 and UDOP, on chart datasets. The transformers utilize the three modalities of text, image, and layout as input. We further investigate whether data augmentation and balancing methods help the performance of the models. The models are evaluated on various chart datasets, and results show that LayoutLMv3 outperforms UDOP in all experiments. LayoutLMv3 achieves the highest F1-macro score of 82.87 on the ICPR22 test dataset, beating the best-performing model from the ICPR22 CHART-Infographics challenge. Moreover, the robustness of the models is tested on a synthetic noisy dataset ICPR22-N. Finally, the generalizability of the models is evaluated on three chart datasets, CHIME-R, DeGruyter, and EconBiz, for which we added labels for the text roles. Findings indicate that even in cases where there is limited training data, transformers can be used with the help of data augmentation and balancing methods. The source code and datasets are available on GitHub under https://github.com/hjkimk/text-role-classification