 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Product1M: Towards Weakly Supervised Instance-Level Product Retrieval via Cross-modal Pretraining
Jul 30, 2021

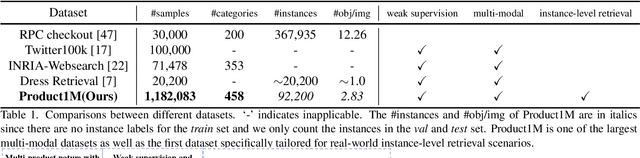
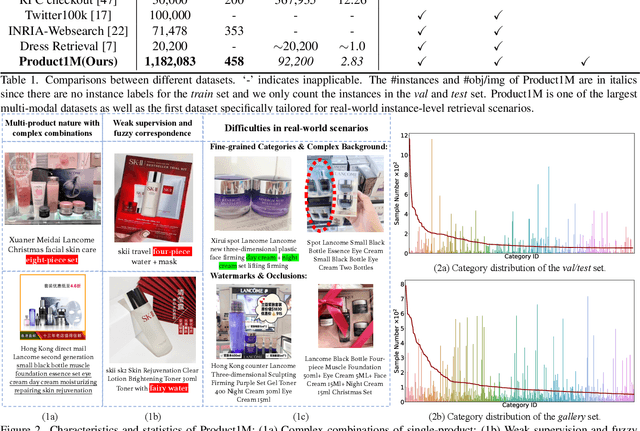
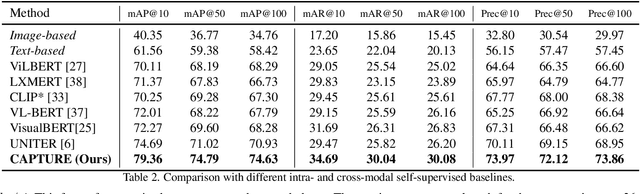
Nowadays, customer's demands for E-commerce are more diversified, which introduces more complications to the product retrieval industry. Previous methods are either subject to single-modal input or perform supervised image-level product retrieval, thus fail to accommodate real-life scenarios where enormous weakly annotated multi-modal data are present. In this paper, we investigate a more realistic setting that aims to perform weakly-supervised multi-modal instance-level product retrieval among fine-grained product categories. To promote the study of this challenging task, we contribute Product1M, one of the largest multi-modal cosmetic datasets for real-world instance-level retrieval. Notably, Product1M contains over 1 million image-caption pairs and consists of two sample types, i.e., single-product and multi-product samples, which encompass a wide variety of cosmetics brands. In addition to the great diversity, Product1M enjoys several appealing characteristics including fine-grained categories, complex combinations, and fuzzy correspondence that well mimic the real-world scenes. Moreover, we propose a novel model named Cross-modal contrAstive Product Transformer for instance-level prodUct REtrieval (CAPTURE), that excels in capturing the potential synergy between multi-modal inputs via a hybrid-stream transformer in a self-supervised manner.CAPTURE generates discriminative instance features via masked multi-modal learning as well as cross-modal contrastive pretraining and it outperforms several SOTA cross-modal baselines. Extensive ablation studies well demonstrate the effectiveness and the generalization capacity of our model.
Image Processing and Quality Control for Abdominal Magnetic Resonance Imaging in the UK Biobank
Jul 16, 2020
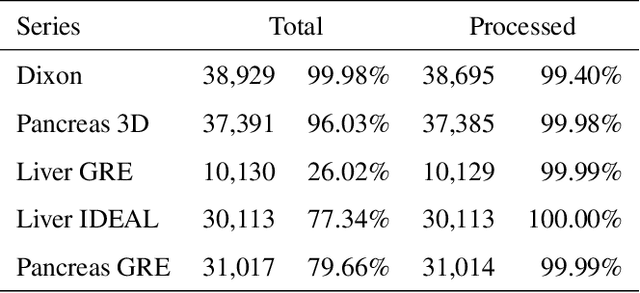

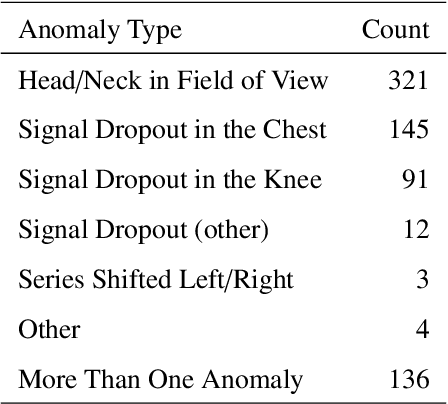
An end-to-end image analysis pipeline is presented for the abdominal MRI protocol used in the UK Biobank on the first 38,971 participants. Emphasis is on the processing steps necessary to ensure a high-level of data quality and consistency is produced in order to prepare the datasets for downstream quantitative analysis, such as segmentation and parameter estimation. Quality control procedures have been incorporated to detect and, where possible, correct issues in the raw data. Detection of fat-water swaps in the Dixon series is performed by a deep learning model and corrected automatically. Bone joints are predicted using a hybrid atlas-based registration and deep learning model for the shoulders, hips and knees. Simultaneous estimation of proton density fat fraction and transverse relaxivity (R2*) is performed using both the magnitude and phase information for the single-slice multiecho series. Approximately 98.1% of the two-point Dixon acquisitions were successfully processed and passed quality control, with 99.98% of the high-resolution T1-weighted 3D volumes succeeding. Approximately 99.98% of the single-slice multiecho acquisitions covering the liver were successfully processed and passed quality control, with 97.6% of the single-slice multiecho acquisitions covering the pancreas succeeding. At least one fat-water swap was detected in 1.8% of participants. With respect to the bone joints, approximately 3.3% of participants were missing at least one knee joint and 0.8% were missing at least one shoulder joint. For the participants who received both single-slice multiecho acquisition protocols for the liver a systematic difference between the two protocols was identified and modeled using multiple linear regression. The findings presented here will be invaluable for scientists who seek to use image-derived phenotypes from the abdominal MRI protocol.
Few-shot Learning Based on Multi-stage Transfer and Class-Balanced Loss for Diabetic Retinopathy Grading
Sep 24, 2021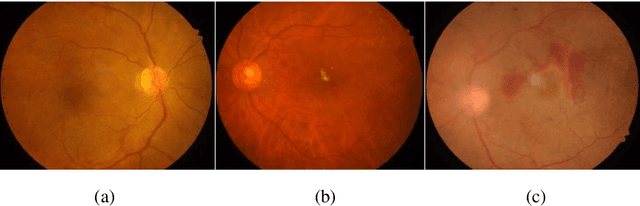

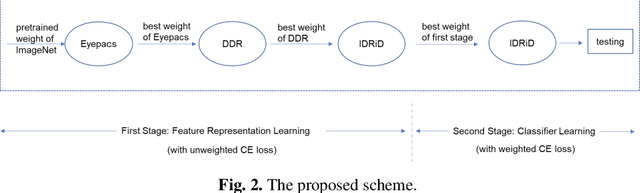
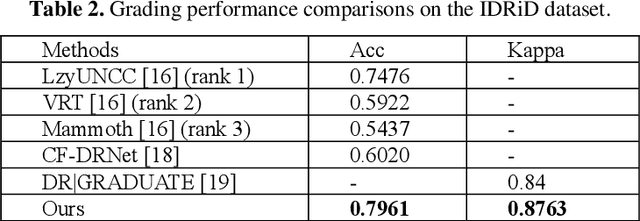
Diabetic retinopathy (DR) is one of the major blindness-causing diseases current-ly known. Automatic grading of DR using deep learning methods not only speeds up the diagnosis of the disease but also reduces the rate of misdiagnosis. However, problems such as insufficient samples and imbalanced class distribu-tion in DR datasets have constrained the improvement of grading performance. In this paper, we introduce the idea of multi-stage transfer into the grading task of DR. The new transfer learning technique leverages multiple datasets with differ-ent scales to enable the model to learn more feature representation information. Meanwhile, to cope with imbalanced DR datasets, we present a class-balanced loss function that performs well in natural image classification tasks, and adopt a simple and easy-to-implement training method for it. The experimental results show that the application of multi-stage transfer and class-balanced loss function can effectively improve the grading performance metrics such as accuracy and quadratic weighted kappa. In fact, our method has outperformed two state-of-the-art methods and achieved the best result on the DR grading task of IDRiD Sub-Challenge 2.
Reliable and Efficient Image Cropping: A Grid Anchor based Approach
Apr 09, 2019
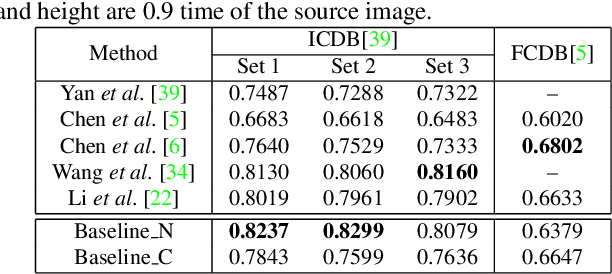

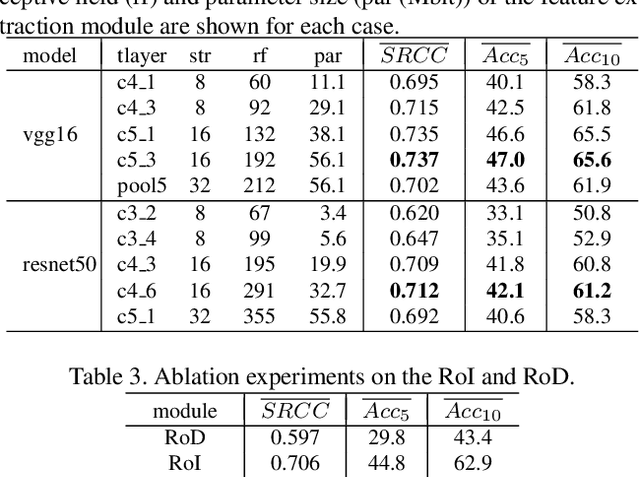
Image cropping aims to improve the composition as well as aesthetic quality of an image by removing extraneous content from it. Existing image cropping databases provide only one or several human-annotated bounding boxes as the groundtruth, which cannot reflect the non-uniqueness and flexibility of image cropping in practice. The employed evaluation metrics such as intersection-over-union cannot reliably reflect the real performance of cropping models, either. This work revisits the problem of image cropping, and presents a grid anchor based formulation by considering the special properties and requirements (e.g., local redundancy, content preservation, aspect ratio) of image cropping. Our formulation reduces the searching space of candidate crops from millions to less than one hundred. Consequently, a grid anchor based cropping benchmark is constructed, where all crops of each image are annotated and more reliable evaluation metrics are defined. We also design an effective and lightweight network module, which simultaneously considers the region of interest and region of discard for more accurate image cropping. Our model can stably output visually pleasing crops for images of different scenes and run at a speed of 125 FPS. Code and dataset are available at: https://github.com/HuiZeng/Grid-Anchor-based-Image-Cropping.
A Method to Generate Synthetically Warped Document Image
Oct 15, 2019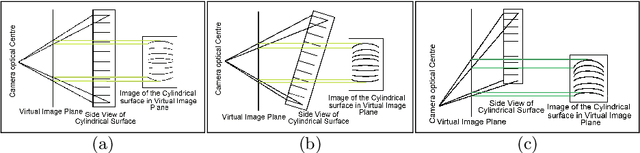

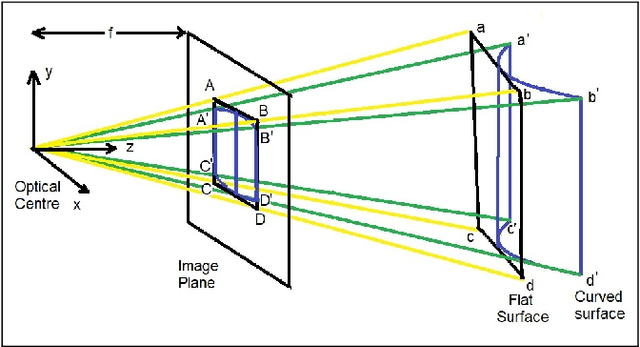

The digital camera captured document images may often be warped and distorted due to different camera angles or document surfaces. A robust technique is needed to solve this kind of distortion. The research on dewarping of the document suffers due to the limited availability of benchmark public dataset. In recent times, deep learning based approaches are used to solve the problems accurately. To train most of the deep neural networks a large number of document images is required and generating such a large volume of document images manually is difficult. In this paper, we propose a technique to generate a synthetic warped image from a flat-bedded scanned document image. It is done by calculating warping factors for each pixel position using two warping position parameters (WPP) and eight warping control parameters (WCP). These parameters can be specified as needed depending upon the desired warping. The results are compared with similar real captured images both qualitative and quantitative way.
Integrating Knowledge and Reasoning in Image Understanding
Jun 24, 2019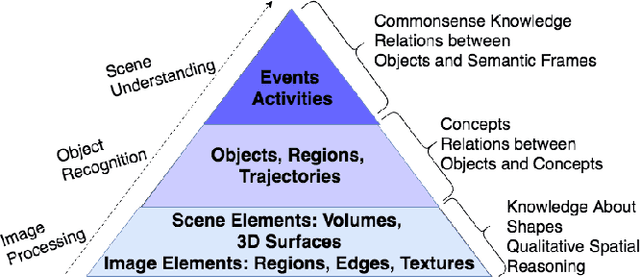

Deep learning based data-driven approaches have been successfully applied in various image understanding applications ranging from object recognition, semantic segmentation to visual question answering. However, the lack of knowledge integration as well as higher-level reasoning capabilities with the methods still pose a hindrance. In this work, we present a brief survey of a few representative reasoning mechanisms, knowledge integration methods and their corresponding image understanding applications developed by various groups of researchers, approaching the problem from a variety of angles. Furthermore, we discuss upon key efforts on integrating external knowledge with neural networks. Taking cues from these efforts, we conclude by discussing potential pathways to improve reasoning capabilities.
* 8 pages, 2 figures
SRR-Net: A Super-Resolution-Involved Reconstruction Method for High Resolution MR Imaging
Apr 13, 2021
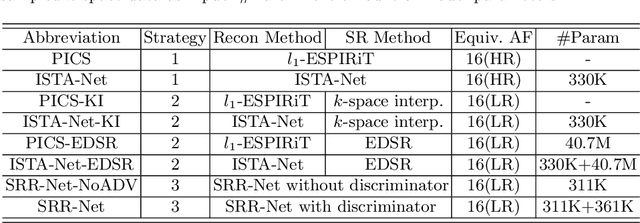
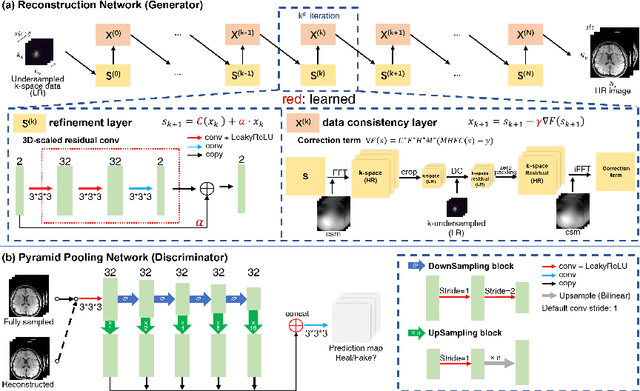
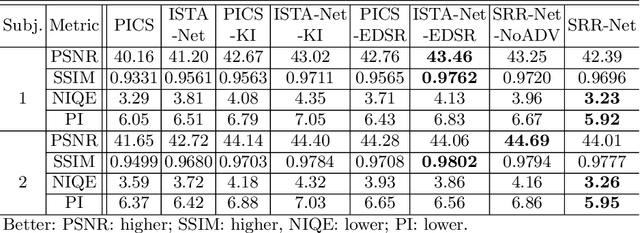
Improving the image resolution and acquisition speed of magnetic resonance imaging (MRI) is a challenging problem. There are mainly two strategies dealing with the speed-resolution trade-off: (1) $k$-space undersampling with high-resolution acquisition, and (2) a pipeline of lower resolution image reconstruction and image super-resolution. However, these approaches either have limited performance at certain high acceleration factor or suffer from the error accumulation of two-step structure. In this paper, we combine the idea of MR reconstruction and image super-resolution, and work on recovering HR images from low-resolution under-sampled $k$-space data directly. Particularly, the SR-involved reconstruction can be formulated as a variational problem, and a learnable network unrolled from its solution algorithm is proposed. A discriminator was introduced to enhance the detail refining performance. Experiment results using in-vivo HR multi-coil brain data indicate that the proposed SRR-Net is capable of recovering high-resolution brain images with both good visual quality and perceptual quality.
LAMP: Large Deep Nets with Automated Model Parallelism for Image Segmentation
Jun 26, 2020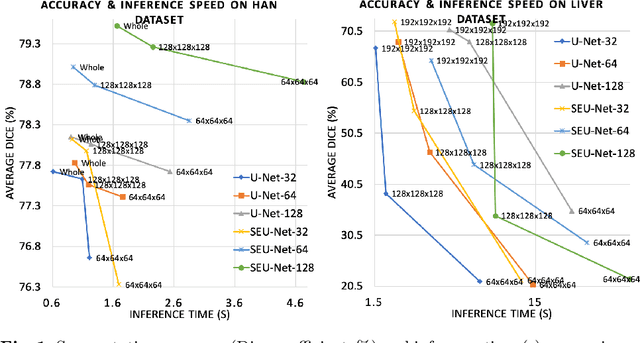
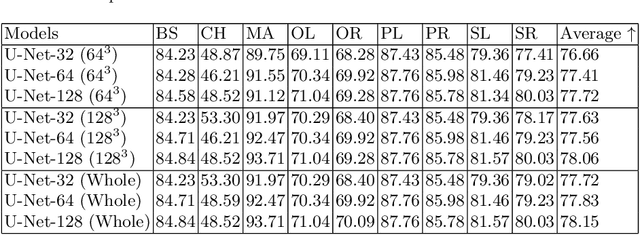
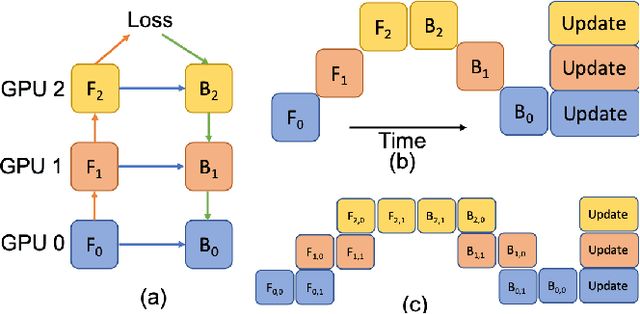
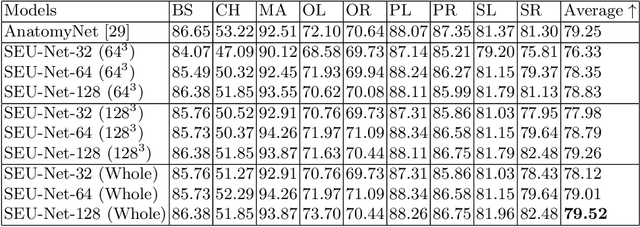
Deep Learning (DL) models are becoming larger, because the increase in model size might offer significant accuracy gain. To enable the training of large deep networks, data parallelism and model parallelism are two well-known approaches for parallel training. However, data parallelism does not help reduce memory footprint per device. In this work, we introduce Large deep 3D ConvNets with Automated Model Parallelism (LAMP) and investigate the impact of both input's and deep 3D ConvNets' size on segmentation accuracy. Through automated model parallelism, it is feasible to train large deep 3D ConvNets with a large input patch, even the whole image. Extensive experiments demonstrate that, facilitated by the automated model parallelism, the segmentation accuracy can be improved through increasing model size and input context size, and large input yields significant inference speedup compared with sliding window of small patches in the inference. Code is available\footnote{https://monai.io/research/lamp-automated-model-parallelism}.
Bilinear discriminant feature line analysis for image feature extraction
May 03, 2019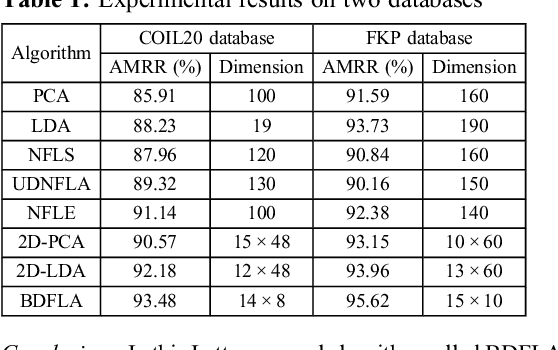
A novel bilinear discriminant feature line analysis (BDFLA) is proposed for image feature extraction. The nearest feature line (NFL) is a powerful classifier. Some NFL-based subspace algorithms were introduced recently. In most of the classical NFL-based subspace learning approaches, the input samples are vectors. For image classification tasks, the image samples should be transformed to vectors first. This process induces a high computational complexity and may also lead to loss of the geometric feature of samples. The proposed BDFLA is a matrix-based algorithm. It aims to minimise the within-class scatter and maximise the between-class scatter based on a two-dimensional (2D) NFL. Experimental results on two-image databases confirm the effectiveness.
Using latent space regression to analyze and leverage compositionality in GANs
Mar 18, 2021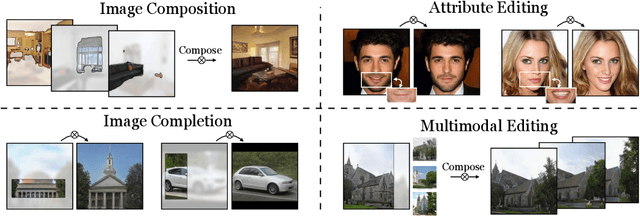



In recent years, Generative Adversarial Networks have become ubiquitous in both research and public perception, but how GANs convert an unstructured latent code to a high quality output is still an open question. In this work, we investigate regression into the latent space as a probe to understand the compositional properties of GANs. We find that combining the regressor and a pretrained generator provides a strong image prior, allowing us to create composite images from a collage of random image parts at inference time while maintaining global consistency. To compare compositional properties across different generators, we measure the trade-offs between reconstruction of the unrealistic input and image quality of the regenerated samples. We find that the regression approach enables more localized editing of individual image parts compared to direct editing in the latent space, and we conduct experiments to quantify this independence effect. Our method is agnostic to the semantics of edits, and does not require labels or predefined concepts during training. Beyond image composition, our method extends to a number of related applications, such as image inpainting or example-based image editing, which we demonstrate on several GANs and datasets, and because it uses only a single forward pass, it can operate in real-time. Code is available on our project page: https://chail.github.io/latent-composition/.