 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DTVNet: Dynamic Time-lapse Video Generation via Single Still Image
Aug 11, 2020


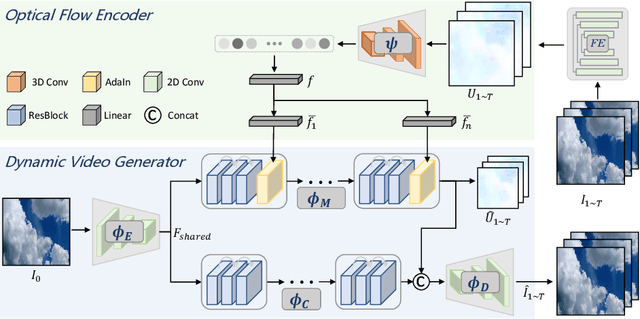
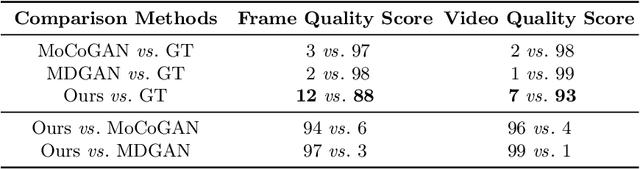
This paper presents a novel end-to-end dynamic time-lapse video generation framework, named DTVNet, to generate diversified time-lapse videos from a single landscape image, which are conditioned on normalized motion vectors. The proposed DTVNet consists of two submodules: \emph{Optical Flow Encoder} (OFE) and \emph{Dynamic Video Generator} (DVG). The OFE maps a sequence of optical flow maps to a \emph{normalized motion vector} that encodes the motion information inside the generated video. The DVG contains motion and content streams that learn from the motion vector and the single image respectively, as well as an encoder and a decoder to learn shared content features and construct video frames with corresponding motion respectively. Specifically, the \emph{motion stream} introduces multiple \emph{adaptive instance normalization} (AdaIN) layers to integrate multi-level motion information that are processed by linear layers. In the testing stage, videos with the same content but various motion information can be generated by different \emph{normalized motion vectors} based on only one input image. We further conduct experiments on Sky Time-lapse dataset, and the results demonstrate the superiority of our approach over the state-of-the-art methods for generating high-quality and dynamic videos, as well as the variety for generating videos with various motion information.
Characterization of Semantic Segmentation Models on Mobile Platforms for Self-Navigation in Disaster-Struck Zones
Feb 03, 2022
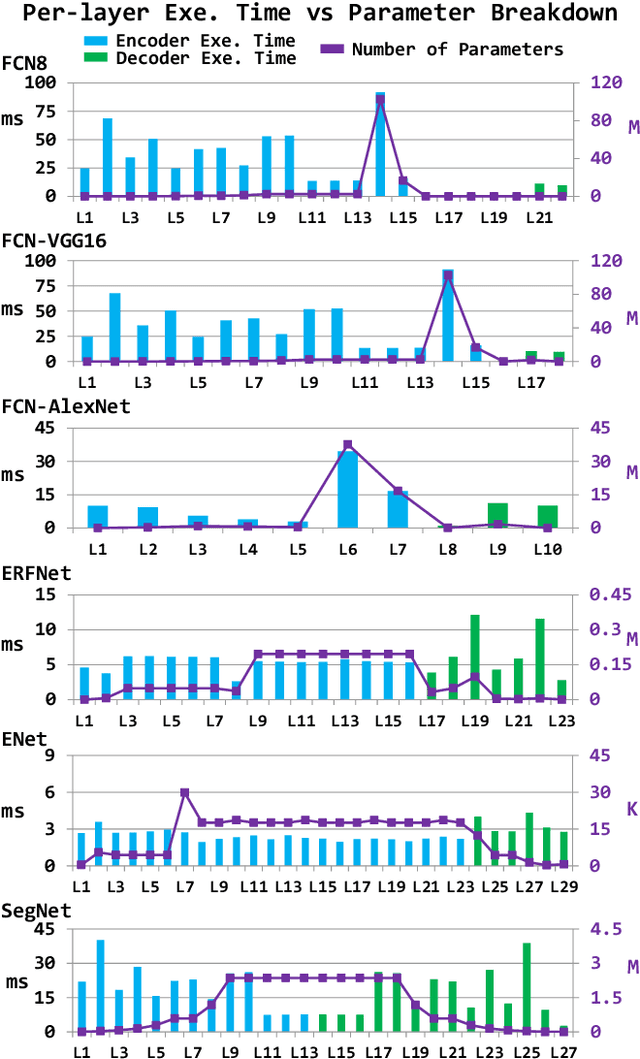
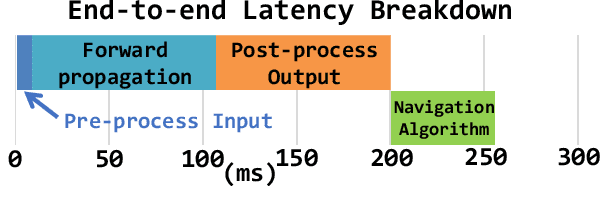
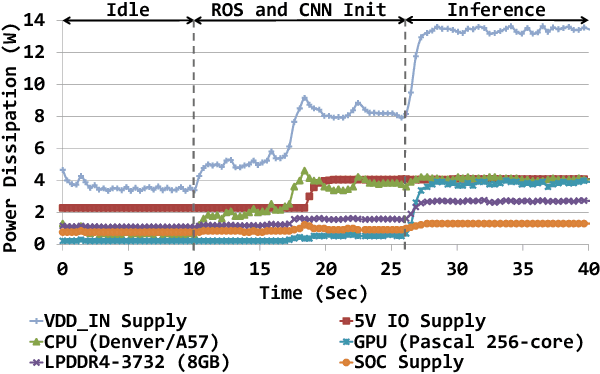
The role of unmanned vehicles for searching and localizing the victims in disaster impacted areas such as earthquake-struck zones is getting more important. Self-navigation on an earthquake zone has a unique challenge of detecting irregularly shaped obstacles such as road cracks, debris on the streets, and water puddles. In this paper, we characterize a number of state-of-the-art FCN models on mobile embedded platforms for self-navigation at these sites containing extremely irregular obstacles. We evaluate the models in terms of accuracy, performance, and energy efficiency. We present a few optimizations for our designed vision system. Lastly, we discuss the trade-offs of these models for a couple of mobile platforms that can each perform self-navigation. To enable vehicles to safely navigate earthquake-struck zones, we compiled a new annotated image database of various earthquake impacted regions that is different than traditional road damage databases. We train our database with a number of state-of-the-art semantic segmentation models in order to identify obstacles unique to earthquake-struck zones. Based on the statistics and tradeoffs, an optimal CNN model is selected for the mobile vehicular platforms, which we apply to both low-power and extremely low-power configurations of our design. To our best knowledge, this is the first study that identifies unique challenges and discusses the accuracy, performance, and energy impact of edge-based self-navigation mobile vehicles for earthquake-struck zones. Our proposed database and trained models are publicly available.
Spectral Compressive Imaging Reconstruction Using Convolution and Spectral Contextual Transformer
Jan 15, 2022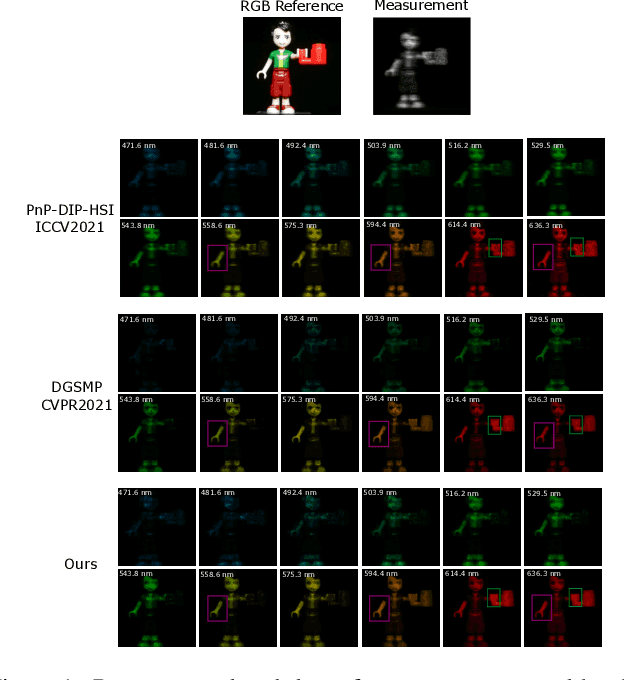
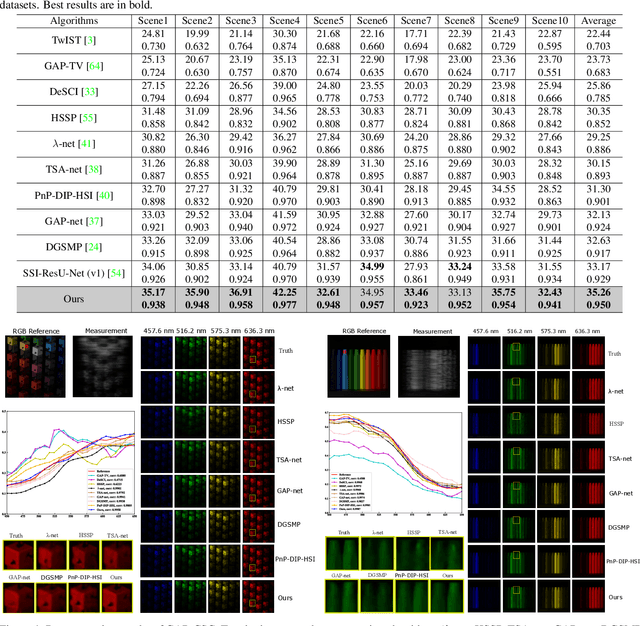
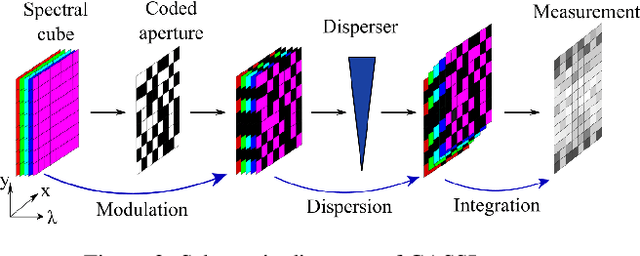

Spectral compressive imaging (SCI) is able to encode the high-dimensional hyperspectral image to a 2D measurement, and then uses algorithms to reconstruct the spatio-spectral data-cube. At present, the main bottleneck of SCI is the reconstruction algorithm, and the state-of-the-art (SOTA) reconstruction methods generally face the problem of long reconstruction time and/or poor detail recovery. In this paper, we propose a novel hybrid network module, namely CSCoT (Convolution and Spectral Contextual Transformer) block, which can acquire the local perception of convolution and the global perception of transformer simultaneously, and is conducive to improving the quality of reconstruction to restore fine details. We integrate the proposed CSCoT block into deep unfolding framework based on the generalized alternating projection algorithm, and further propose the GAP-CSCoT network. Finally, we apply the GAP-CSCoT algorithm to SCI reconstruction. Through the experiments of extensive synthetic and real data, our proposed model achieves higher reconstruction quality ($>$2dB in PSNR on simulated benchmark datasets) and shorter running time than existing SOTA algorithms by a large margin. The code and models will be released to the public.
ASDN: A Deep Convolutional Network for Arbitrary Scale Image Super-Resolution
Oct 06, 2020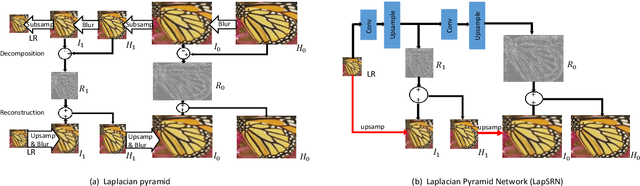
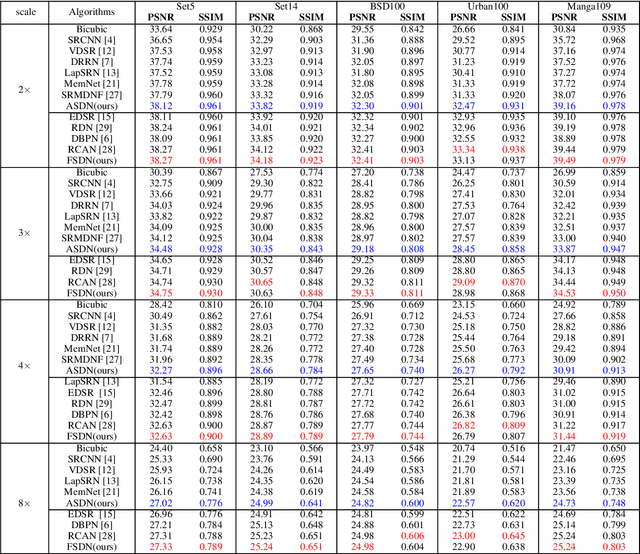
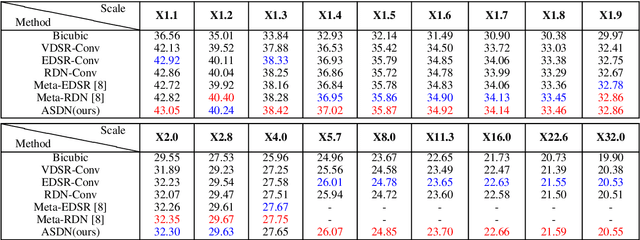
Deep convolutional neural networks have significantly improved the peak signal-to-noise ratio of SuperResolution (SR). However, image viewer applications commonly allow users to zoom the images to arbitrary magnification scales, thus far imposing a large number of required training scales at a tremendous computational cost. To obtain a more computationally efficient model for arbitrary scale SR, this paper employs a Laplacian pyramid method to reconstruct any-scale high-resolution (HR) images using the high-frequency image details in a Laplacian Frequency Representation. For SR of small-scales (between 1 and 2), images are constructed by interpolation from a sparse set of precalculated Laplacian pyramid levels. SR of larger scales is computed by recursion from small scales, which significantly reduces the computational cost. For a full comparison, fixed- and any-scale experiments are conducted using various benchmarks. At fixed scales, ASDN outperforms predefined upsampling methods (e.g., SRCNN, VDSR, DRRN) by about 1 dB in PSNR. At any-scale, ASDN generally exceeds Meta-SR on many scales.
Scaling Up Influence Functions
Dec 06, 2021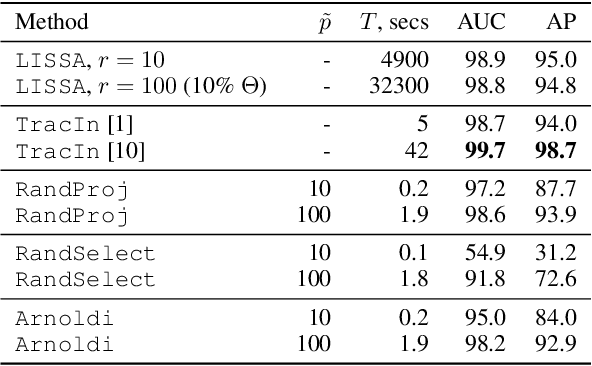
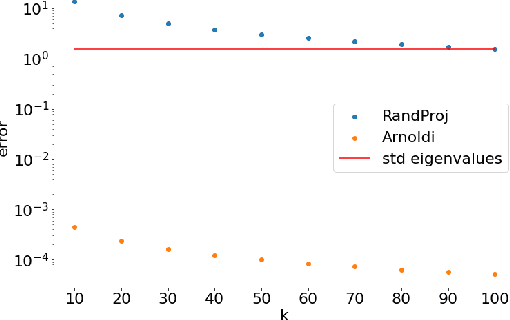
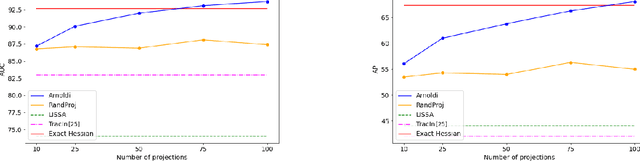
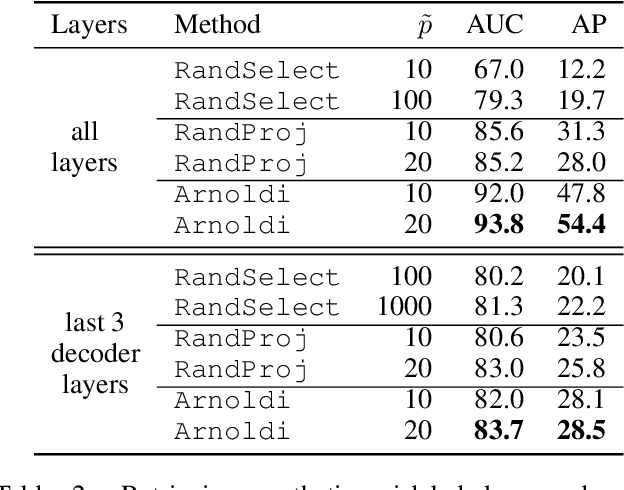
We address efficient calculation of influence functions for tracking predictions back to the training data. We propose and analyze a new approach to speeding up the inverse Hessian calculation based on Arnoldi iteration. With this improvement, we achieve, to the best of our knowledge, the first successful implementation of influence functions that scales to full-size (language and vision) Transformer models with several hundreds of millions of parameters. We evaluate our approach on image classification and sequence-to-sequence tasks with tens to a hundred of millions of training examples. Our code will be available at https://github.com/google-research/jax-influence.
TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models
Sep 25, 2021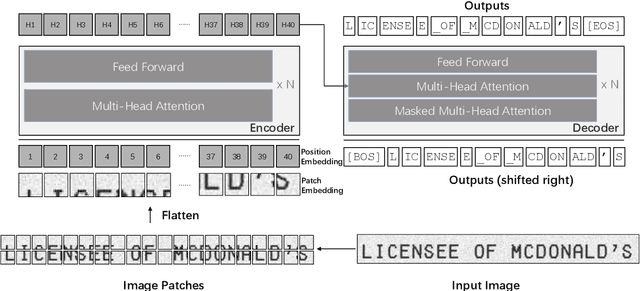

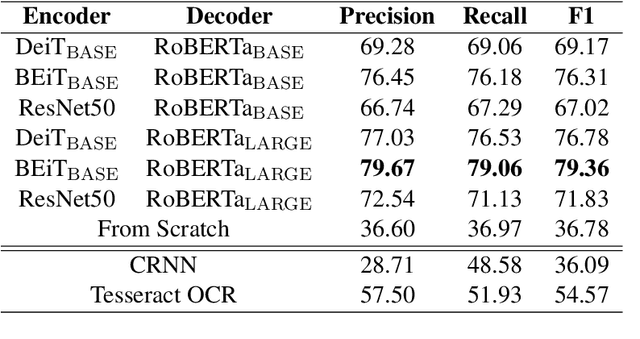
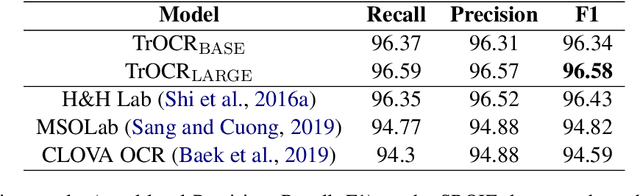
Text recognition is a long-standing research problem for document digitalization. Existing approaches for text recognition are usually built based on CNN for image understanding and RNN for char-level text generation. In addition, another language model is usually needed to improve the overall accuracy as a post-processing step. In this paper, we propose an end-to-end text recognition approach with pre-trained image Transformer and text Transformer models, namely TrOCR, which leverages the Transformer architecture for both image understanding and wordpiece-level text generation. The TrOCR model is simple but effective, and can be pre-trained with large-scale synthetic data and fine-tuned with human-labeled datasets. Experiments show that the TrOCR model outperforms the current state-of-the-art models on both printed and handwritten text recognition tasks. The code and models will be publicly available at https://aka.ms/TrOCR.
Residual-driven Fuzzy C-Means Clustering for Image Segmentation
Apr 15, 2020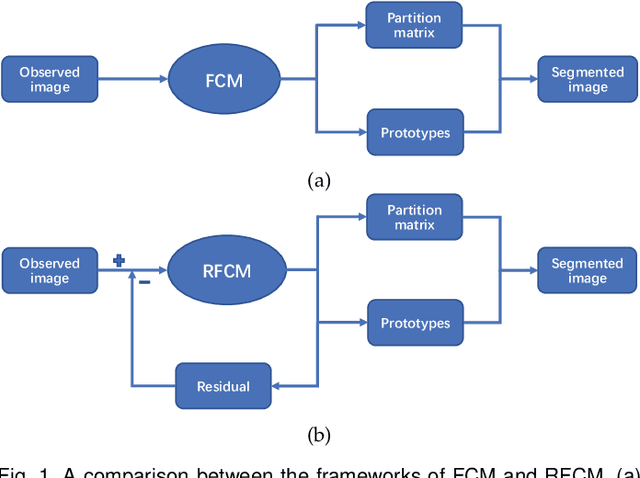
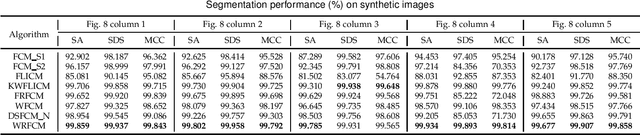
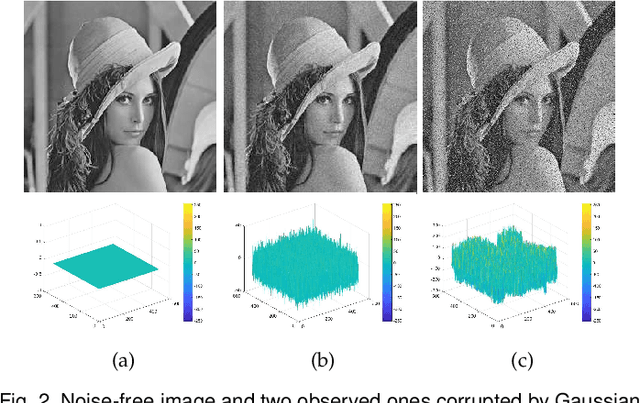
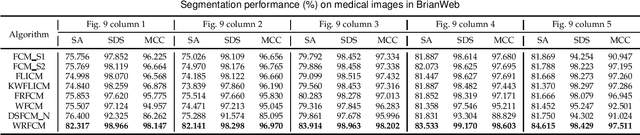
Due to its inferior characteristics, an observed (noisy) image's direct use gives rise to poor segmentation results. Intuitively, using its noise-free image can favorably impact image segmentation. Hence, the accurate estimation of the residual between observed and noise-free images is an important task. To do so, we elaborate on residual-driven Fuzzy \emph{C}-Means (FCM) for image segmentation, which is the first approach that realizes accurate residual estimation and leads noise-free image to participate in clustering. We propose a residual-driven FCM framework by integrating into FCM a residual-related fidelity term derived from the distribution of different types of noise. Built on this framework, we present a weighted $\ell_{2}$-norm fidelity term by weighting mixed noise distribution, thus resulting in a universal residual-driven FCM algorithm in presence of mixed or unknown noise. Besides, with the constraint of spatial information, the residual estimation becomes more reliable than that only considering an observed image itself. Supporting experiments on synthetic, medical, and real-world images are conducted. The results demonstrate the superior effectiveness and efficiency of the proposed algorithm over existing FCM-related algorithms.
Data Generation using Texture Co-occurrence and Spatial Self-Similarity for Debiasing
Oct 15, 2021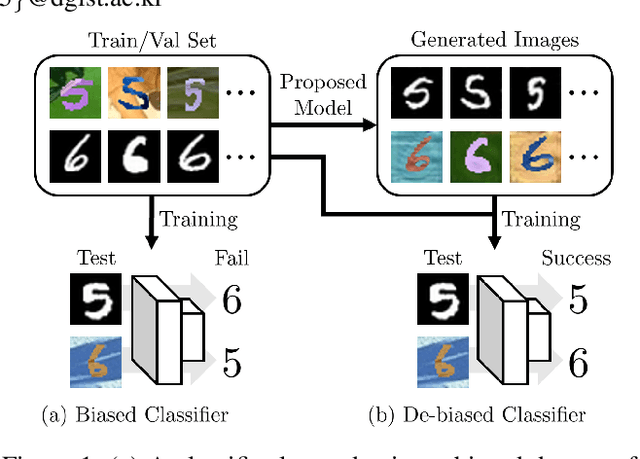
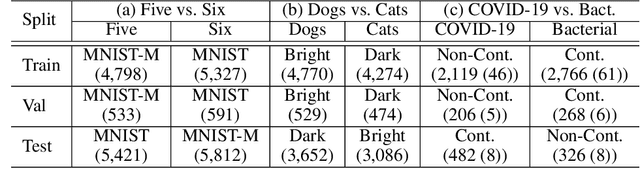
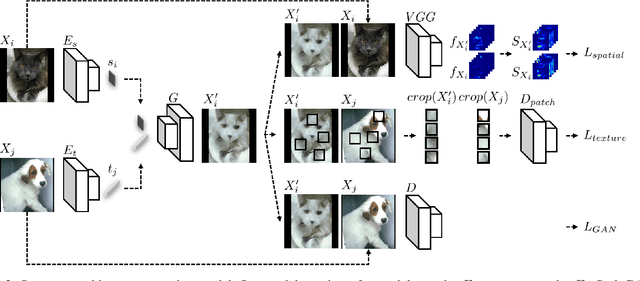
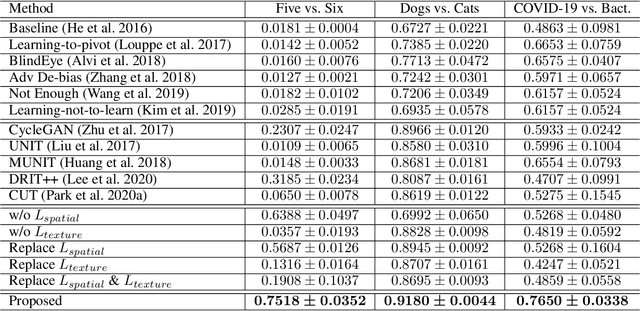
Classification models trained on biased datasets usually perform poorly on out-of-distribution samples since biased representations are embedded into the model. Recently, adversarial learning methods have been proposed to disentangle biased representations, but it is challenging to discard only the biased features without altering other relevant information. In this paper, we propose a novel de-biasing approach that explicitly generates additional images using texture representations of oppositely labeled images to enlarge the training dataset and mitigate the effect of biases when training a classifier. Every new generated image contains similar spatial information from a source image while transferring textures from a target image of opposite label. Our model integrates a texture co-occurrence loss that determines whether a generated image's texture is similar to that of the target, and a spatial self-similarity loss that determines whether the spatial details between the generated and source images are well preserved. Both generated and original training images are further used to train a classifier that is able to avoid learning unknown bias representations. We employ three distinct artificially designed datasets with known biases to demonstrate the ability of our method to mitigate bias information, and report competitive performance over existing state-of-the-art methods.
PreDisM: Pre-Disaster Modelling With CNN Ensembles for At-Risk Communities
Dec 26, 2021



The machine learning community has recently had increased interest in the climate and disaster damage domain due to a marked increased occurrences of natural hazards (e.g., hurricanes, forest fires, floods, earthquakes). However, not enough attention has been devoted to mitigating probable destruction from impending natural hazards. We explore this crucial space by predicting building-level damages on a before-the-fact basis that would allow state actors and non-governmental organizations to be best equipped with resource distribution to minimize or preempt losses. We introduce PreDisM that employs an ensemble of ResNets and fully connected layers over decision trees to capture image-level and meta-level information to accurately estimate weakness of man-made structures to disaster-occurrences. Our model performs well and is responsive to tuning across types of disasters and highlights the space of preemptive hazard damage modelling.
Implicit Pairs for Boosting Unpaired Image-to-Image Translation
Apr 15, 2019
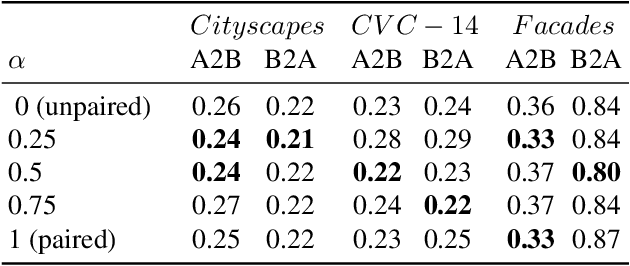
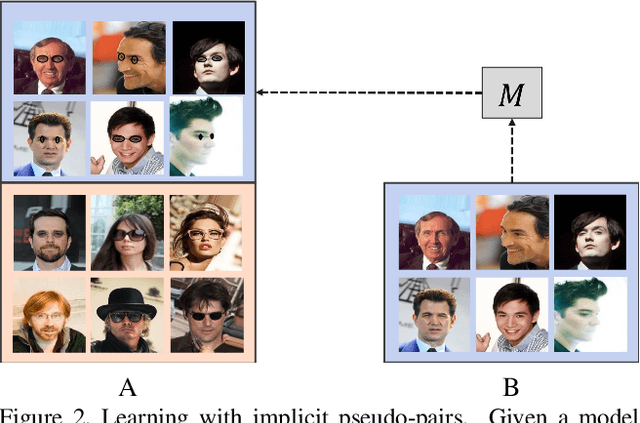
In image-to-image translation the goal is to learn a mapping from one image domain to another. Supervised approaches learn the mapping from paired samples. However, collecting large sets of image pairs is often prohibitively expensive or infeasible. In our work, we show that even training on the pairs implicitly, boosts the performance of unsupervised techniques by over 14% across several measurements. We illustrate that the injection of implicit pairs into unpaired sets strengthens the mapping between the two domains and improves the compatibility of their distributions. Furthermore, we show that for this purpose the implicit pairs can be pseudo-pairs, i.e., paired samples which only approximate a real pair. We demonstrate the effect of the approximated implicit samples on image-to-image translation problems, where such pseudo-pairs can be synthesized in one direction, but not in the other. We further show that pseudo-pairs are significantly more effective as implicit pairs in an unpaired setting, than directly using them explicitly in a paired setting.