 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction-Free Tuning of Large Vision Language Models for Medical Instruction Following
Mar 19, 2026Large vision language models (LVLMs) have demonstrated impressive performance across a wide range of tasks. These capabilities largely stem from visual instruction tuning, which fine-tunes models on datasets consisting of curated image-instruction-output triplets. However, in the medical domain, constructing large-scale, high-quality instruction datasets is particularly challenging due to the need for specialized expert knowledge. To address this issue, we propose an instruction-free tuning approach that reduces reliance on handcrafted instructions, leveraging only image-description pairs for fine-tuning. Specifically, we introduce a momentum proxy instruction as a replacement for curated text instructions, which preserves the instruction-following capability of the pre-trained LVLM while promoting updates to parameters that remain valid during inference. Consequently, the fine-tuned LVLM can flexibly respond to domain-specific instructions, even though explicit instructions are absent during fine-tuning. Additionally, we incorporate a response shuffling strategy to mitigate the model's over-reliance on previous words, facilitating more effective fine-tuning. Our approach achieves state-of-the-art accuracy on multiple-choice visual question answering tasks across SKINCON, WBCAtt, CBIS, and MIMIC-CXR datasets, significantly enhancing the fine-tuning efficiency of LVLMs in medical domains.
Model Agnostic Preference Optimization for Medical Image Segmentation
Dec 17, 2025Preference optimization offers a scalable supervision paradigm based on relative preference signals, yet prior attempts in medical image segmentation remain model-specific and rely on low-diversity prediction sampling. In this paper, we propose MAPO (Model-Agnostic Preference Optimization), a training framework that utilizes Dropout-driven stochastic segmentation hypotheses to construct preference-consistent gradients without direct ground-truth supervision. MAPO is fully architecture- and dimensionality-agnostic, supporting 2D/3D CNN and Transformer-based segmentation pipelines. Comprehensive evaluations across diverse medical datasets reveal that MAPO consistently enhances boundary adherence, reduces overfitting, and yields more stable optimization dynamics compared to conventional supervised training.
Illustrious: an Open Advanced Illustration Model
Sep 30, 2024



In this work, we share the insights for achieving state-of-the-art quality in our text-to-image anime image generative model, called Illustrious. To achieve high resolution, dynamic color range images, and high restoration ability, we focus on three critical approaches for model improvement. First, we delve into the significance of the batch size and dropout control, which enables faster learning of controllable token based concept activations. Second, we increase the training resolution of images, affecting the accurate depiction of character anatomy in much higher resolution, extending its generation capability over 20MP with proper methods. Finally, we propose the refined multi-level captions, covering all tags and various natural language captions as a critical factor for model development. Through extensive analysis and experiments, Illustrious demonstrates state-of-the-art performance in terms of animation style, outperforming widely-used models in illustration domains, propelling easier customization and personalization with nature of open source. We plan to publicly release updated Illustrious model series sequentially as well as sustainable plans for improvements.
Improving Text Generation on Images with Synthetic Captions
Jun 01, 2024



The recent emergence of latent diffusion models such as SDXL and SD 1.5 has shown significant capability in generating highly detailed and realistic images. Despite their remarkable ability to produce images, generating accurate text within images still remains a challenging task. In this paper, we examine the validity of fine-tuning approaches in generating legible text within the image. We propose a low-cost approach by leveraging SDXL without any time-consuming training on large-scale datasets. The proposed strategy employs a fine-tuning technique that examines the effects of data refinement levels and synthetic captions. Moreover, our results demonstrate how our small scale fine-tuning approach can improve the accuracy of text generation in different scenarios without the need of additional multimodal encoders. Our experiments show that with the addition of random letters to our raw dataset, our model's performance improves in producing well-formed visual text.
CAT: Contrastive Adapter Training for Personalized Image Generation
Apr 11, 2024



The emergence of various adapters, including Low-Rank Adaptation (LoRA) applied from the field of natural language processing, has allowed diffusion models to personalize image generation at a low cost. However, due to the various challenges including limited datasets and shortage of regularization and computation resources, adapter training often results in unsatisfactory outcomes, leading to the corruption of the backbone model's prior knowledge. One of the well known phenomena is the loss of diversity in object generation, especially within the same class which leads to generating almost identical objects with minor variations. This poses challenges in generation capabilities. To solve this issue, we present Contrastive Adapter Training (CAT), a simple yet effective strategy to enhance adapter training through the application of CAT loss. Our approach facilitates the preservation of the base model's original knowledge when the model initiates adapters. Furthermore, we introduce the Knowledge Preservation Score (KPS) to evaluate CAT's ability to keep the former information. We qualitatively and quantitatively compare CAT's improvement. Finally, we mention the possibility of CAT in the aspects of multi-concept adapter and optimization.
Feature Re-calibration based MIL for Whole Slide Image Classification
Jun 22, 2022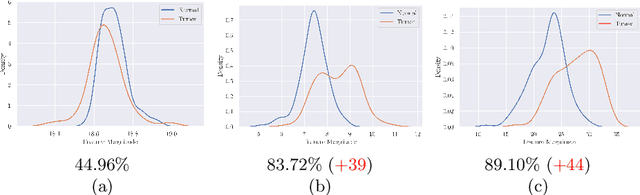
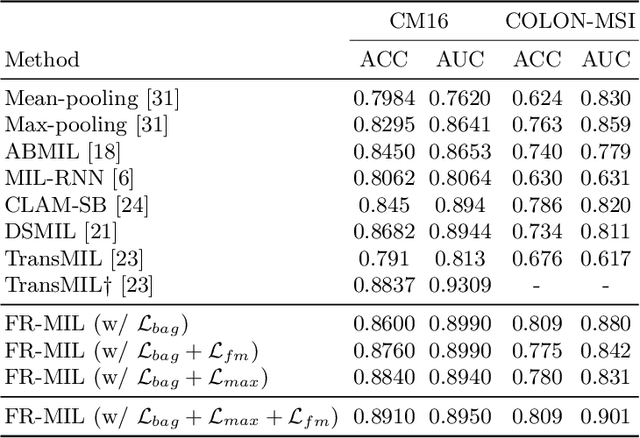
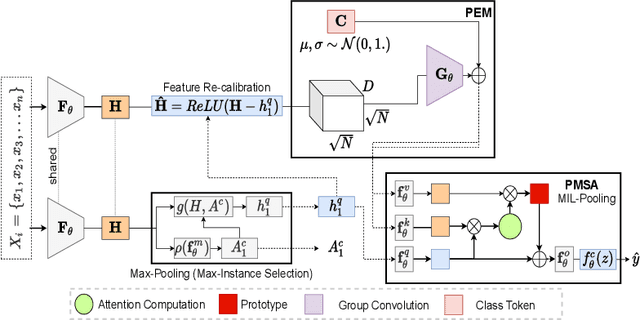
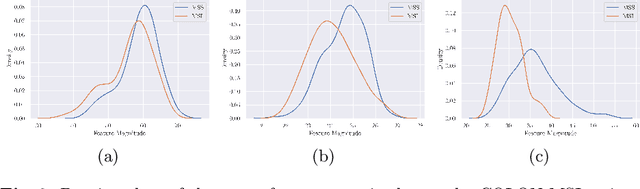
Whole slide image (WSI) classification is a fundamental task for the diagnosis and treatment of diseases; but, curation of accurate labels is time-consuming and limits the application of fully-supervised methods. To address this, multiple instance learning (MIL) is a popular method that poses classification as a weakly supervised learning task with slide-level labels only. While current MIL methods apply variants of the attention mechanism to re-weight instance features with stronger models, scant attention is paid to the properties of the data distribution. In this work, we propose to re-calibrate the distribution of a WSI bag (instances) by using the statistics of the max-instance (critical) feature. We assume that in binary MIL, positive bags have larger feature magnitudes than negatives, thus we can enforce the model to maximize the discrepancy between bags with a metric feature loss that models positive bags as out-of-distribution. To achieve this, unlike existing MIL methods that use single-batch training modes, we propose balanced-batch sampling to effectively use the feature loss i.e., (+/-) bags simultaneously. Further, we employ a position encoding module (PEM) to model spatial/morphological information, and perform pooling by multi-head self-attention (PSMA) with a Transformer encoder. Experimental results on existing benchmark datasets show our approach is effective and improves over state-of-the-art MIL methods.
CAD: Co-Adapting Discriminative Features for Improved Few-Shot Classification
Mar 25, 2022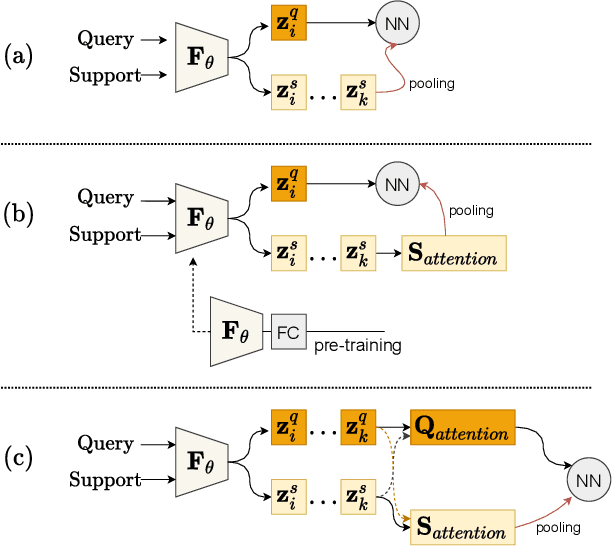
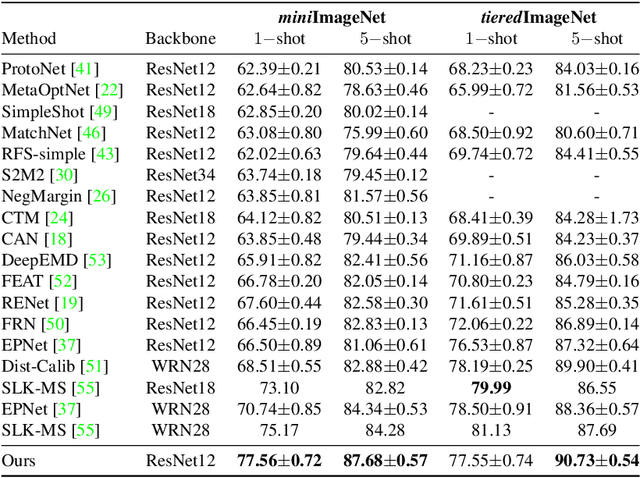
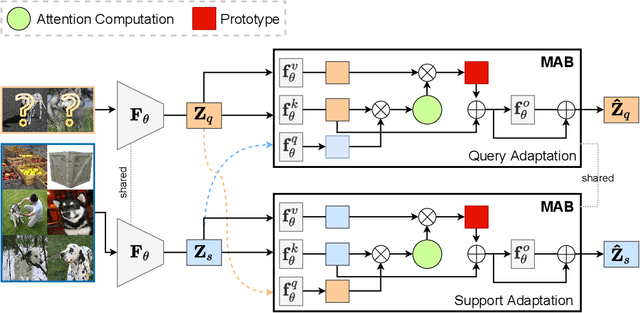
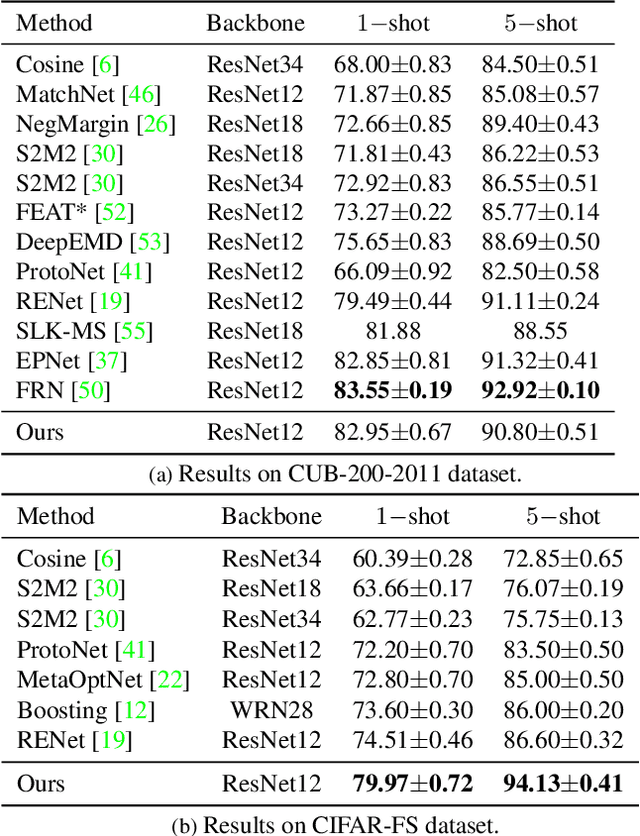
Few-shot classification is a challenging problem that aims to learn a model that can adapt to unseen classes given a few labeled samples. Recent approaches pre-train a feature extractor, and then fine-tune for episodic meta-learning. Other methods leverage spatial features to learn pixel-level correspondence while jointly training a classifier. However, results using such approaches show marginal improvements. In this paper, inspired by the transformer style self-attention mechanism, we propose a strategy to cross-attend and re-weight discriminative features for few-shot classification. Given a base representation of support and query images after global pooling, we introduce a single shared module that projects features and cross-attends in two aspects: (i) query to support, and (ii) support to query. The module computes attention scores between features to produce an attention pooled representation of features in the same class that is later added to the original representation followed by a projection head. This effectively re-weights features in both aspects (i & ii) to produce features that better facilitate improved metric-based meta-learning. Extensive experiments on public benchmarks show our approach outperforms state-of-the-art methods by 3%~5%.
Uncertainty-Aware Semi-Supervised Few Shot Segmentation
Oct 18, 2021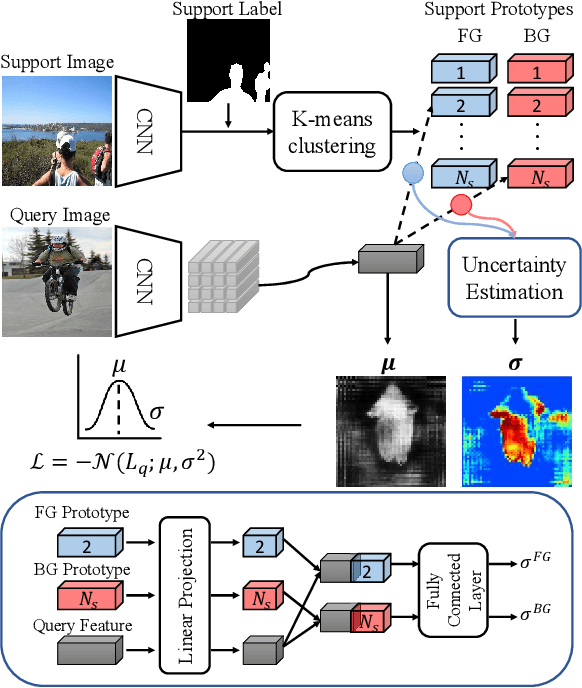
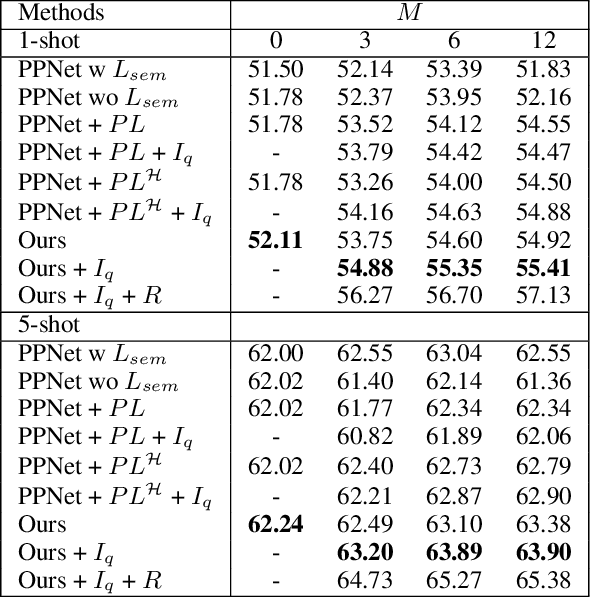
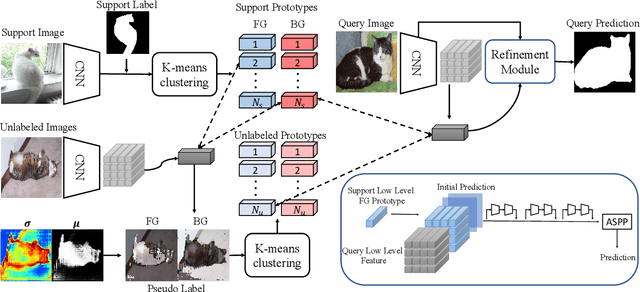
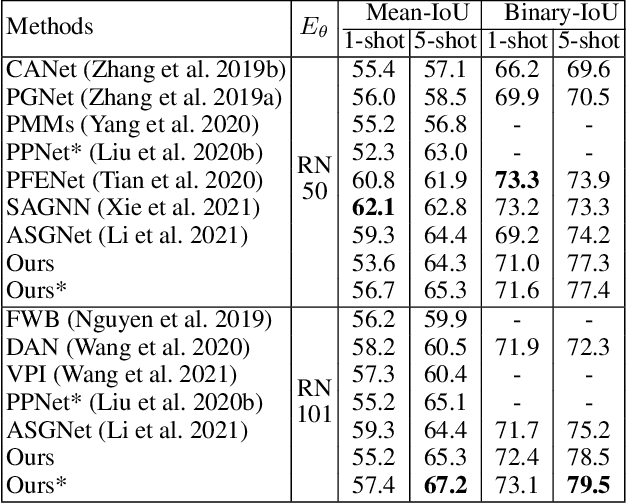
Few shot segmentation (FSS) aims to learn pixel-level classification of a target object in a query image using only a few annotated support samples. This is challenging as it requires modeling appearance variations of target objects and the diverse visual cues between query and support images with limited information. To address this problem, we propose a semi-supervised FSS strategy that leverages additional prototypes from unlabeled images with uncertainty guided pseudo label refinement. To obtain reliable prototypes from unlabeled images, we meta-train a neural network to jointly predict segmentation and estimate the uncertainty of predictions. We employ the uncertainty estimates to exclude predictions with high degrees of uncertainty for pseudo label construction to obtain additional prototypes based on the refined pseudo labels. During inference, query segmentation is predicted using prototypes from both support and unlabeled images including low-level features of the query images. Our approach is end-to-end and can easily supplement existing approaches without the requirement of additional training to employ unlabeled samples. Extensive experiments on PASCAL-$5^i$ and COCO-$20^i$ demonstrate that our model can effectively remove unreliable predictions to refine pseudo labels and significantly improve upon state-of-the-art performances.
Data Generation using Texture Co-occurrence and Spatial Self-Similarity for Debiasing
Oct 15, 2021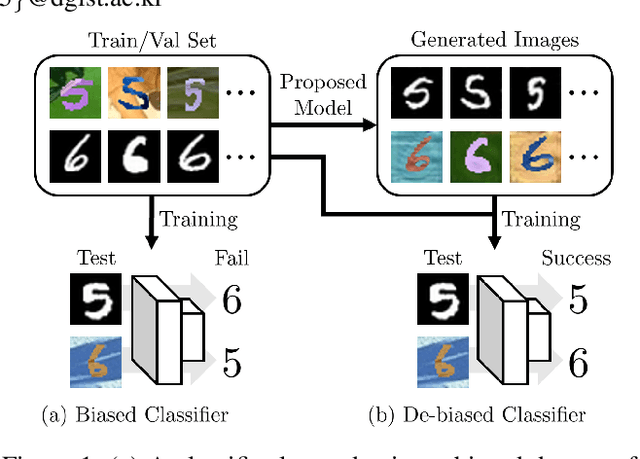
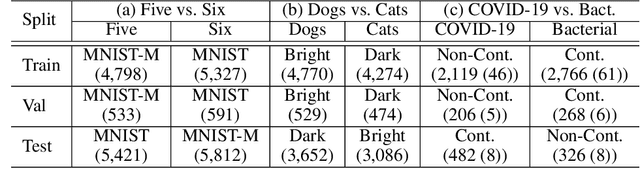
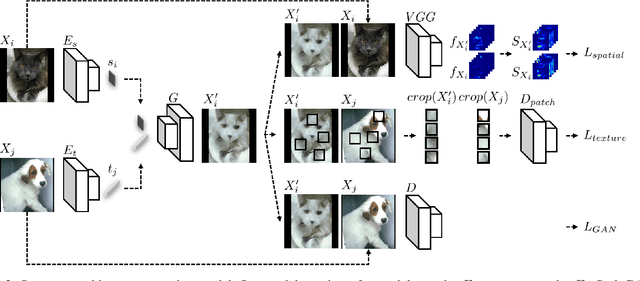
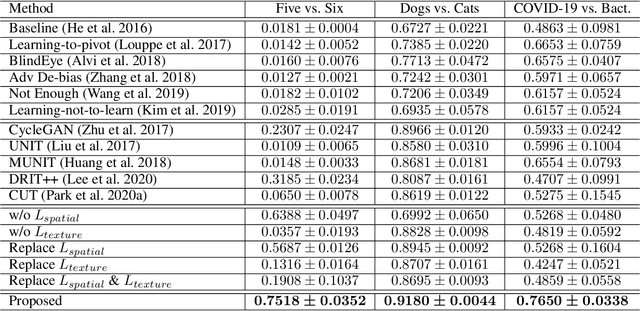
Classification models trained on biased datasets usually perform poorly on out-of-distribution samples since biased representations are embedded into the model. Recently, adversarial learning methods have been proposed to disentangle biased representations, but it is challenging to discard only the biased features without altering other relevant information. In this paper, we propose a novel de-biasing approach that explicitly generates additional images using texture representations of oppositely labeled images to enlarge the training dataset and mitigate the effect of biases when training a classifier. Every new generated image contains similar spatial information from a source image while transferring textures from a target image of opposite label. Our model integrates a texture co-occurrence loss that determines whether a generated image's texture is similar to that of the target, and a spatial self-similarity loss that determines whether the spatial details between the generated and source images are well preserved. Both generated and original training images are further used to train a classifier that is able to avoid learning unknown bias representations. We employ three distinct artificially designed datasets with known biases to demonstrate the ability of our method to mitigate bias information, and report competitive performance over existing state-of-the-art methods.
First Demonstration of the Korean eLoran Accuracy in a Narrow Waterway Using Improved ASF Maps
Sep 28, 2021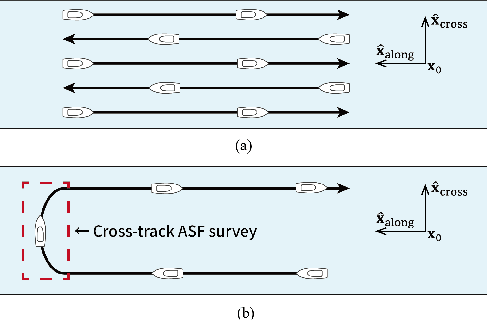
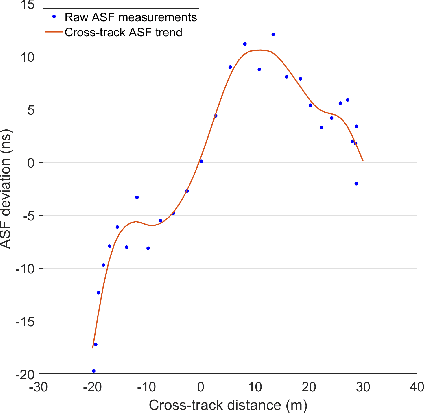
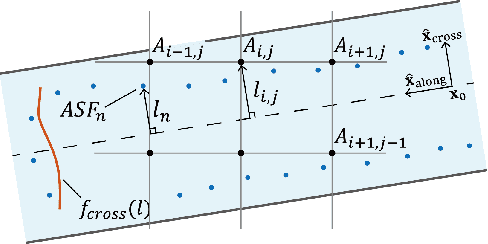
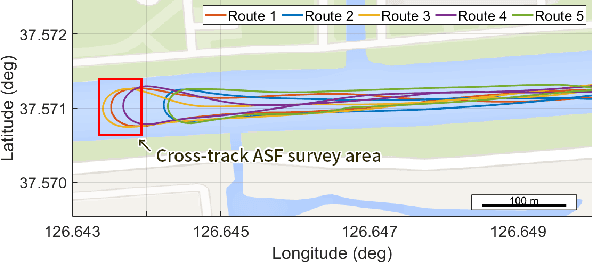
The vulnerabilities of global navigation satellite systems (GNSSs) to radio frequency jamming and spoofing have attracted significant research attention. In particular, the large-scale jamming incidents that occurred in South Korea substantiate the practical importance of implementing a complementary navigation system. This letter briefly summarizes the efforts of South Korea to deploy an enhanced long-range navigation (eLoran) system, which is a terrestrial low-frequency radio navigation system that can complement GNSSs. After four years of research and development, the Korean eLoran testbed system has been recently deployed and is operational since June 1, 2021. Although its initial performance at sea is satisfactory, navigation through a narrow waterway is still challenging because a complete survey of the additional secondary factor (ASF), which is the largest source of error for eLoran, is practically difficult in a narrow waterway. This letter proposes an alternative way to survey the ASF in a narrow waterway and improve the ASF map generation methods. Moreover, the performance of the proposed approach was validated experimentally.