 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fortuitous Forgetting in Connectionist Networks
Feb 01, 2022
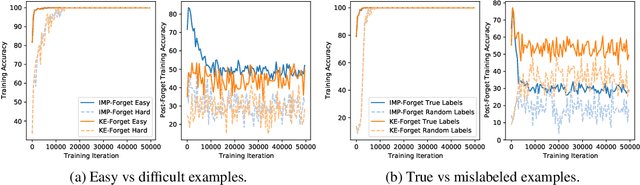
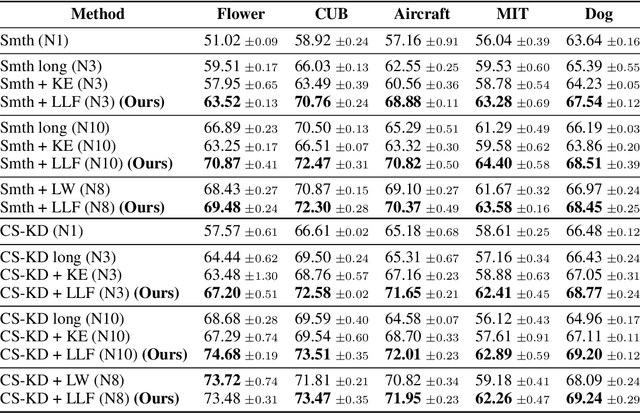
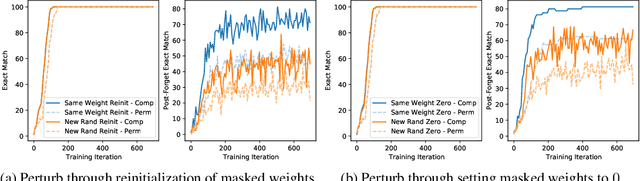
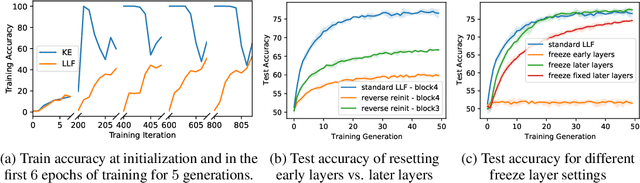
Forgetting is often seen as an unwanted characteristic in both human and machine learning. However, we propose that forgetting can in fact be favorable to learning. We introduce "forget-and-relearn" as a powerful paradigm for shaping the learning trajectories of artificial neural networks. In this process, the forgetting step selectively removes undesirable information from the model, and the relearning step reinforces features that are consistently useful under different conditions. The forget-and-relearn framework unifies many existing iterative training algorithms in the image classification and language emergence literature, and allows us to understand the success of these algorithms in terms of the disproportionate forgetting of undesirable information. We leverage this understanding to improve upon existing algorithms by designing more targeted forgetting operations. Insights from our analysis provide a coherent view on the dynamics of iterative training in neural networks and offer a clear path towards performance improvements.
* ICLR Camera Ready
Phrase-Based Affordance Detection via Cyclic Bilateral Interaction
Feb 25, 2022
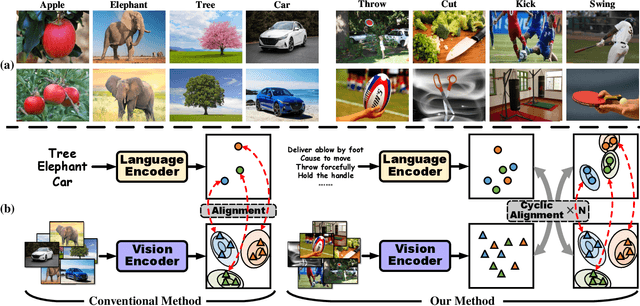
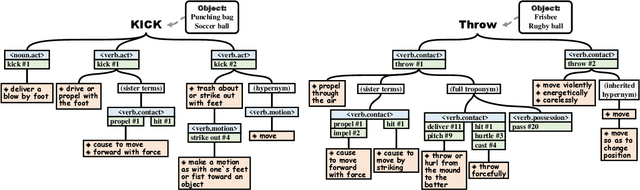
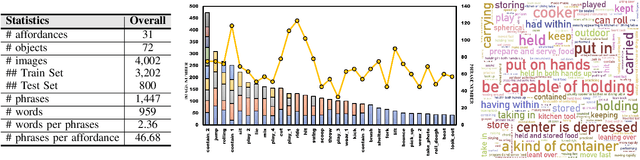
Affordance detection, which refers to perceiving objects with potential action possibilities in images, is a challenging task since the possible affordance depends on the person's purpose in real-world application scenarios. The existing works mainly extract the inherent human-object dependencies from image/video to accommodate affordance properties that change dynamically. In this paper, we explore to perceive affordance from a vision-language perspective and consider the challenging phrase-based affordance detection problem,i.e., given a set of phrases describing the action purposes, all the object regions in a scene with the same affordance should be detected. To this end, we propose a cyclic bilateral consistency enhancement network (CBCE-Net) to align language and vision features progressively. Specifically, the presented CBCE-Net consists of a mutual guided vision-language module that updates the common features of vision and language in a progressive manner, and a cyclic interaction module (CIM) that facilitates the perception of possible interaction with objects in a cyclic manner. In addition, we extend the public Purpose-driven Affordance Dataset (PAD) by annotating affordance categories with short phrases. The contrastive experimental results demonstrate the superiority of our method over nine typical methods from four relevant fields in terms of both objective metrics and visual quality. The related code and dataset will be released at \url{https://github.com/lulsheng/CBCE-Net}.
Closed-loop Feedback Registration for Consecutive Images of Moving Flexible Targets
Oct 20, 2021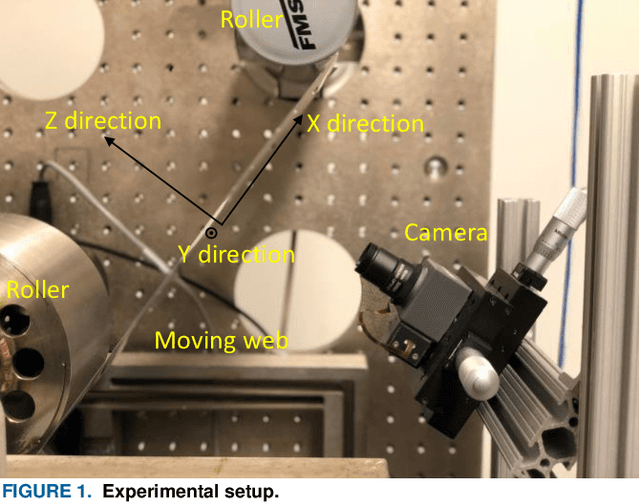

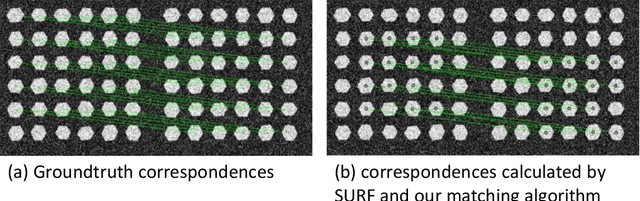
Advancement of imaging techniques enables consecutive image sequences to be acquired for quality monitoring of manufacturing production lines. Registration for these image sequences is essential for in-line pattern inspection and metrology, e.g., in the printing process of flexible electronics. However, conventional image registration algorithms cannot produce accurate results when the images contain many similar and deformable patterns in the manufacturing process. Such a failure originates from a fact that the conventional algorithms only use the spatial and pixel intensity information for registration. Considering the nature of temporal continuity and consecution of the product images, in this paper, we propose a closed-loop feedback registration algorithm for matching and stitching the deformable printed patterns on a moving flexible substrate. The algorithm leverages the temporal and spatial relationships of the consecutive images and the continuity of the image sequence for fast, accurate, and robust point matching. Our experimental results show that our algorithm can find more matching point pairs with a lower root mean squared error (RMSE) compared to other state-of-the-art algorithms while offering significant improvements to running time.
Street-view Panoramic Video Synthesis from a Single Satellite Image
Dec 11, 2020
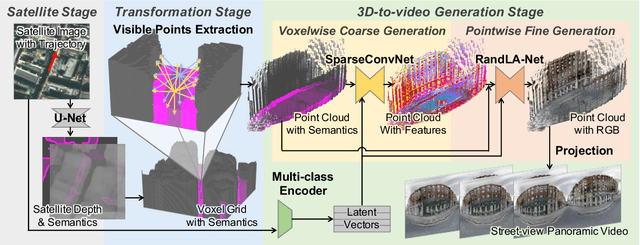


We present a novel method for synthesizing both temporally and geometrically consistent street-view panoramic video from a given single satellite image and camera trajectory. Existing cross-view synthesis approaches focus more on images, while video synthesis in such a case has not yet received enough attention. Single image synthesis approaches are not well suited for video synthesis since they lack temporal consistency which is a crucial property of videos. To this end, our approach explicitly creates a 3D point cloud representation of the scene and maintains dense 3D-2D correspondences across frames that reflect the geometric scene configuration inferred from the satellite view. We implement a cascaded network architecture with two hourglass modules for successive coarse and fine generation for colorizing the point cloud from the semantics and per-class latent vectors. By leveraging computed correspondences, the produced street-view video frames adhere to the 3D geometric scene structure and maintain temporal consistency. Qualitative and quantitative experiments demonstrate superior results compared to other state-of-the-art cross-view synthesis approaches that either lack temporal or geometric consistency. To the best of our knowledge, our work is the first work to synthesize cross-view images to video.
Fooling the Eyes of Autonomous Vehicles: Robust Physical Adversarial Examples Against Traffic Sign Recognition Systems
Jan 17, 2022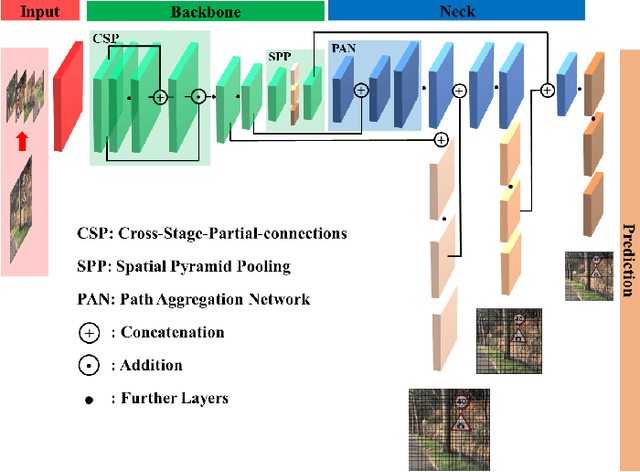
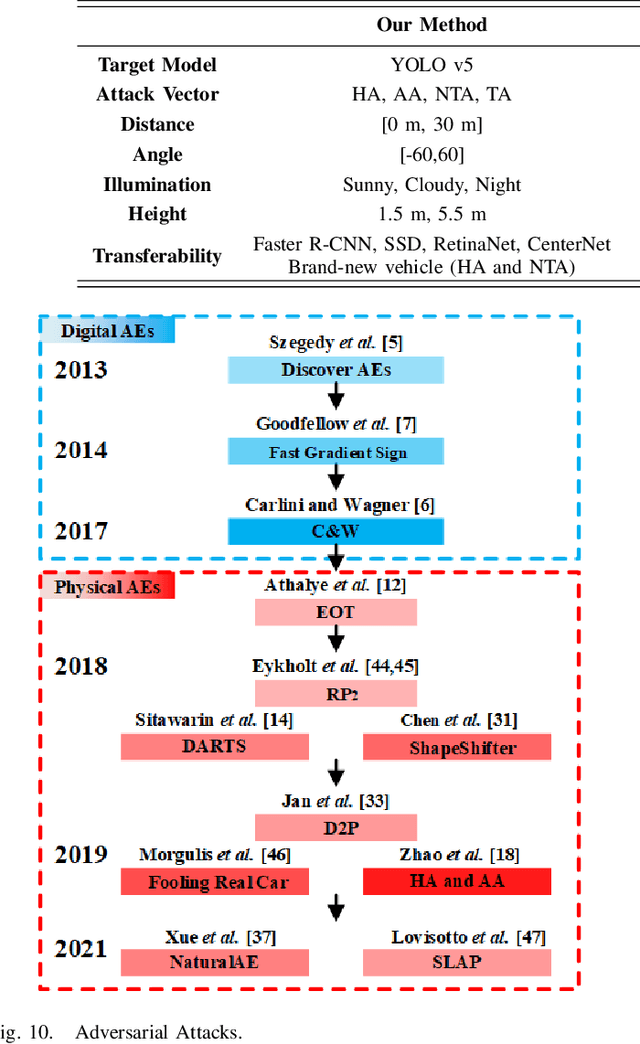
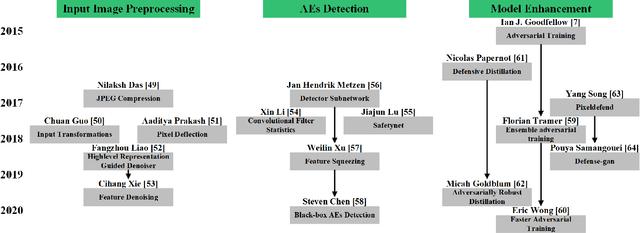

Adversarial Examples (AEs) can deceive Deep Neural Networks (DNNs) and have received a lot of attention recently. However, majority of the research on AEs is in the digital domain and the adversarial patches are static, which is very different from many real-world DNN applications such as Traffic Sign Recognition (TSR) systems in autonomous vehicles. In TSR systems, object detectors use DNNs to process streaming video in real time. From the view of object detectors, the traffic sign`s position and quality of the video are continuously changing, rendering the digital AEs ineffective in the physical world. In this paper, we propose a systematic pipeline to generate robust physical AEs against real-world object detectors. Robustness is achieved in three ways. First, we simulate the in-vehicle cameras by extending the distribution of image transformations with the blur transformation and the resolution transformation. Second, we design the single and multiple bounding boxes filters to improve the efficiency of the perturbation training. Third, we consider four representative attack vectors, namely Hiding Attack, Appearance Attack, Non-Target Attack and Target Attack. We perform a comprehensive set of experiments under a variety of environmental conditions, and considering illuminations in sunny and cloudy weather as well as at night. The experimental results show that the physical AEs generated from our pipeline are effective and robust when attacking the YOLO v5 based TSR system. The attacks have good transferability and can deceive other state-of-the-art object detectors. We launched HA and NTA on a brand-new 2021 model vehicle. Both attacks are successful in fooling the TSR system, which could be a life-threatening case for autonomous vehicles. Finally, we discuss three defense mechanisms based on image preprocessing, AEs detection, and model enhancing.
Towards a Unified Foundation Model: Jointly Pre-Training Transformers on Unpaired Images and Text
Dec 14, 2021



In this paper, we explore the possibility of building a unified foundation model that can be adapted to both vision-only and text-only tasks. Starting from BERT and ViT, we design a unified transformer consisting of modality-specific tokenizers, a shared transformer encoder, and task-specific output heads. To efficiently pre-train the proposed model jointly on unpaired images and text, we propose two novel techniques: (i) We employ the separately-trained BERT and ViT models as teachers and apply knowledge distillation to provide additional, accurate supervision signals for the joint training; (ii) We propose a novel gradient masking strategy to balance the parameter updates from the image and text pre-training losses. We evaluate the jointly pre-trained transformer by fine-tuning it on image classification tasks and natural language understanding tasks, respectively. The experiments show that the resultant unified foundation transformer works surprisingly well on both the vision-only and text-only tasks, and the proposed knowledge distillation and gradient masking strategy can effectively lift the performance to approach the level of separately-trained models.
Tk-merge: Computationally Efficient Robust Clustering Under General Assumptions
Jan 17, 2022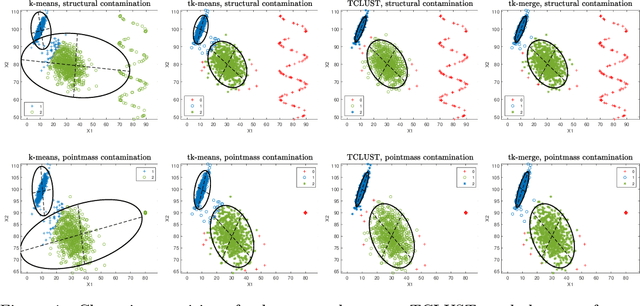
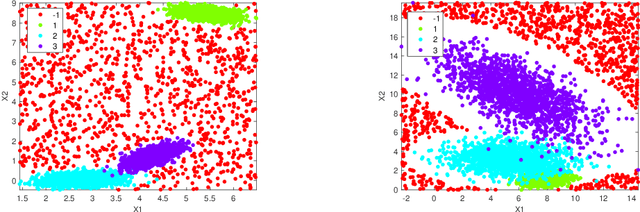
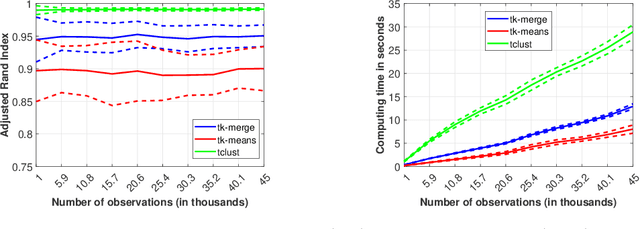
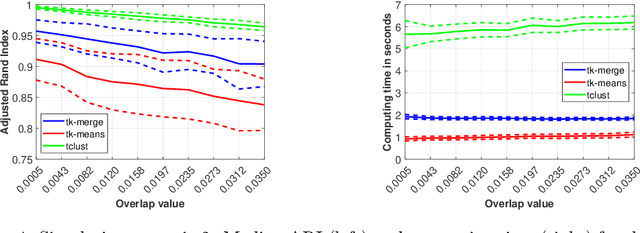
We address general-shaped clustering problems under very weak parametric assumptions with a two-step hybrid robust clustering algorithm based on trimmed k-means and hierarchical agglomeration. The algorithm has low computational complexity and effectively identifies the clusters also in presence of data contamination. We also present natural generalizations of the approach as well as an adaptive procedure to estimate the amount of contamination in a data-driven fashion. Our proposal outperforms state-of-the-art robust, model-based methods in our numerical simulations and real-world applications related to color quantization for image analysis, human mobility patterns based on GPS data, biomedical images of diabetic retinopathy, and functional data across weather stations.
Evaluating Single Image Dehazing Methods Under Realistic Sunlight Haze
Aug 31, 2020
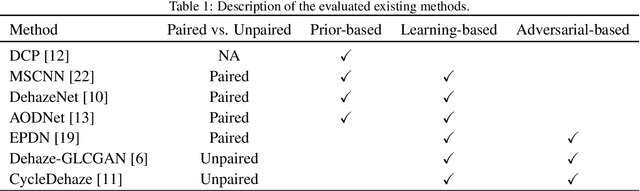

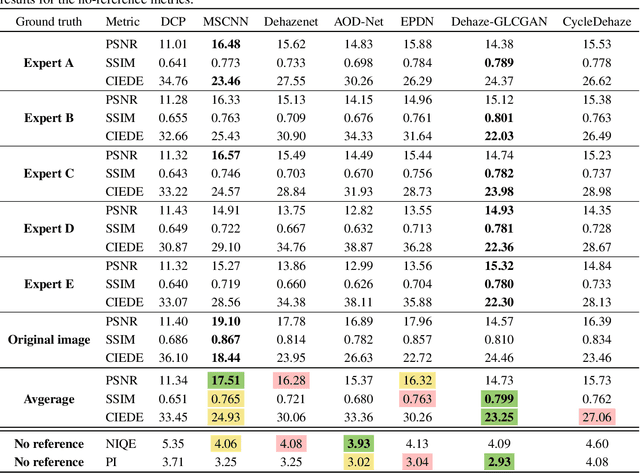
Haze can degrade the visibility and the image quality drastically, thus degrading the performance of computer vision tasks such as object detection. Single image dehazing is a challenging and ill-posed problem, despite being widely studied. Most existing methods assume that haze has a uniform/homogeneous distribution and haze can have a single color, i.e. grayish white color similar to smoke, while in reality haze can be distributed non-uniformly with different patterns and colors. In this paper, we focus on haze created by sunlight as it is one of the most prevalent type of haze in the wild. Sunlight can generate non-uniformly distributed haze with drastic density changes due to sun rays and also a spectrum of haze color due to sunlight color changes during the day. This presents a new challenge to image dehazing methods. For these methods to be practical, this problem needs to be addressed. To quantify the challenges and assess the performance of these methods, we present a sunlight haze benchmark dataset, Sun-Haze, containing 107 hazy images with different types of haze created by sunlight having a variety of intensity and color. We evaluate a representative set of state-of-the-art image dehazing methods on this benchmark dataset in terms of standard metrics such as PSNR, SSIM, CIEDE2000, PI and NIQE. This uncovers the limitation of the current methods, and questions their underlying assumptions as well as their practicality.
SpectralNET: Exploring Spatial-Spectral WaveletCNN for Hyperspectral Image Classification
Apr 01, 2021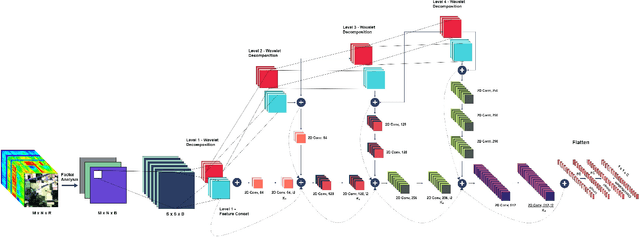
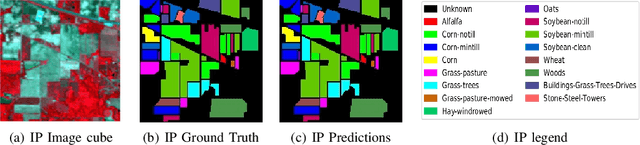
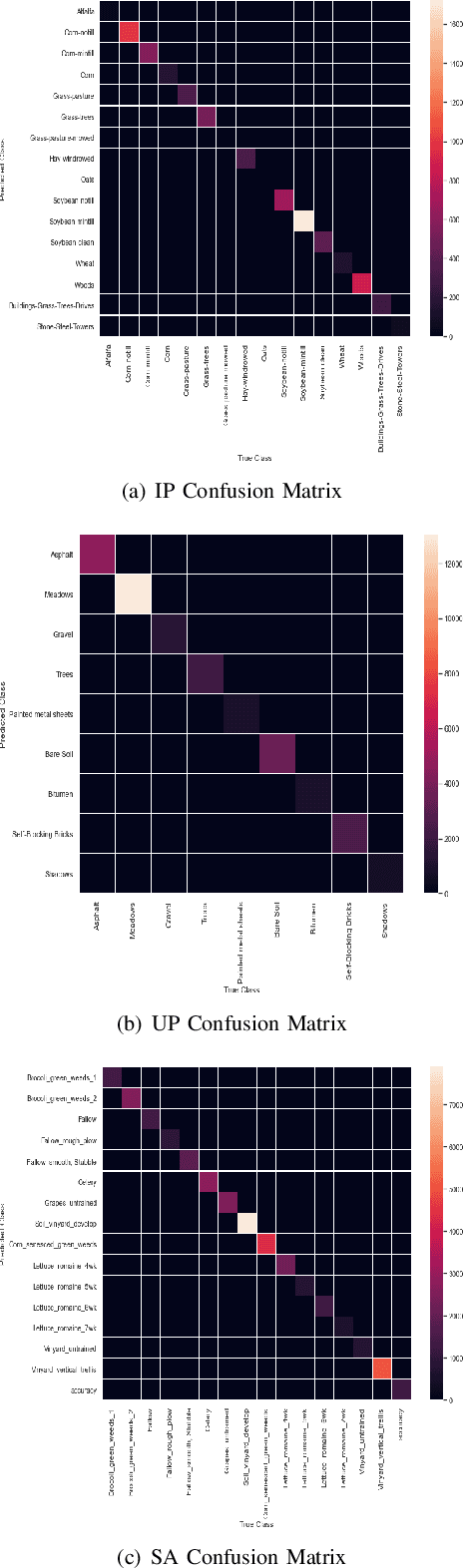

Hyperspectral Image (HSI) classification using Convolutional Neural Networks (CNN) is widely found in the current literature. Approaches vary from using SVMs to 2D CNNs, 3D CNNs, 3D-2D CNNs. Besides 3D-2D CNNs and FuSENet, the other approaches do not consider both the spectral and spatial features together for HSI classification task, thereby resulting in poor performances. 3D CNNs are computationally heavy and are not widely used, while 2D CNNs do not consider multi-resolution processing of images, and only limits itself to the spatial features. Even though 3D-2D CNNs try to model the spectral and spatial features their performance seems limited when applied over multiple dataset. In this article, we propose SpectralNET, a wavelet CNN, which is a variation of 2D CNN for multi-resolution HSI classification. A wavelet CNN uses layers of wavelet transform to bring out spectral features. Computing a wavelet transform is lighter than computing 3D CNN. The spectral features extracted are then connected to the 2D CNN which bring out the spatial features, thereby creating a spatial-spectral feature vector for classification. Overall a better model is achieved that can classify multi-resolution HSI data with high accuracy. Experiments performed with SpectralNET on benchmark dataset, i.e. Indian Pines, University of Pavia, and Salinas Scenes confirm the superiority of proposed SpectralNET with respect to the state-of-the-art methods. The code is publicly available in https://github.com/tanmay-ty/SpectralNET.
Spatial Dependency Networks: Neural Layers for Improved Generative Image Modeling
Mar 16, 2021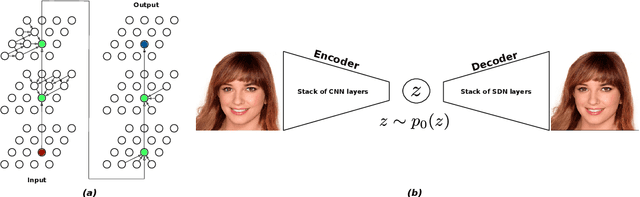
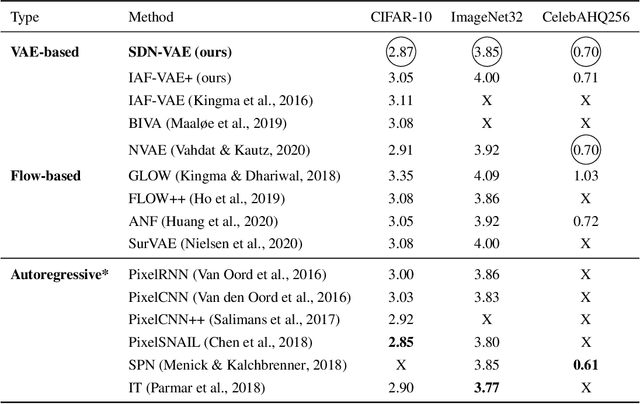
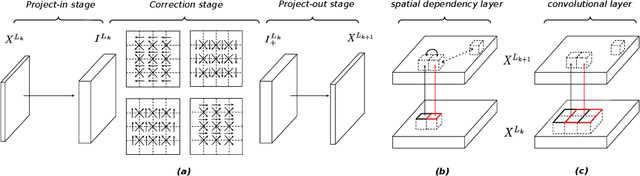
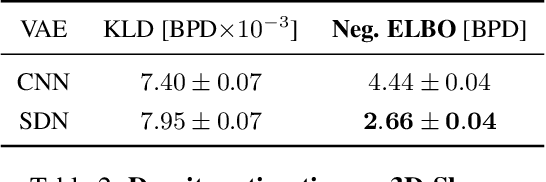
How to improve generative modeling by better exploiting spatial regularities and coherence in images? We introduce a novel neural network for building image generators (decoders) and apply it to variational autoencoders (VAEs). In our spatial dependency networks (SDNs), feature maps at each level of a deep neural net are computed in a spatially coherent way, using a sequential gating-based mechanism that distributes contextual information across 2-D space. We show that augmenting the decoder of a hierarchical VAE by spatial dependency layers considerably improves density estimation over baseline convolutional architectures and the state-of-the-art among the models within the same class. Furthermore, we demonstrate that SDN can be applied to large images by synthesizing samples of high quality and coherence. In a vanilla VAE setting, we find that a powerful SDN decoder also improves learning disentangled representations, indicating that neural architectures play an important role in this task. Our results suggest favoring spatial dependency over convolutional layers in various VAE settings. The accompanying source code is given at https://github.com/djordjemila/sdn.