 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow well can VLMs rate audio descriptions: A multi-dimensional quantitative assessment framework
Feb 01, 2026Digital video is central to communication, education, and entertainment, but without audio description (AD), blind and low-vision audiences are excluded. While crowdsourced platforms and vision-language-models (VLMs) expand AD production, quality is rarely checked systematically. Existing evaluations rely on NLP metrics and short-clip guidelines, leaving questions about what constitutes quality for full-length content and how to assess it at scale. To address these questions, we first developed a multi-dimensional assessment framework for uninterrupted, full-length video, grounded in professional guidelines and refined by accessibility specialists. Second, we integrated this framework into a comprehensive methodological workflow, utilizing Item Response Theory, to assess the proficiency of VLM and human raters against expert-established ground truth. Findings suggest that while VLMs can approximate ground-truth ratings with high alignment, their reasoning was found to be less reliable and actionable than that of human respondents. These insights show the potential of hybrid evaluation systems that leverage VLMs alongside human oversight, offering a path towards scalable AD quality control.
Pushing the Envelope for Depth-Based Semi-Supervised 3D Hand Pose Estimation with Consistency Training
Mar 27, 2023



Despite the significant progress that depth-based 3D hand pose estimation methods have made in recent years, they still require a large amount of labeled training data to achieve high accuracy. However, collecting such data is both costly and time-consuming. To tackle this issue, we propose a semi-supervised method to significantly reduce the dependence on labeled training data. The proposed method consists of two identical networks trained jointly: a teacher network and a student network. The teacher network is trained using both the available labeled and unlabeled samples. It leverages the unlabeled samples via a loss formulation that encourages estimation equivariance under a set of affine transformations. The student network is trained using the unlabeled samples with their pseudo-labels provided by the teacher network. For inference at test time, only the student network is used. Extensive experiments demonstrate that the proposed method outperforms the state-of-the-art semi-supervised methods by large margins.
TriHorn-Net: A Model for Accurate Depth-Based 3D Hand Pose Estimation
Jun 14, 2022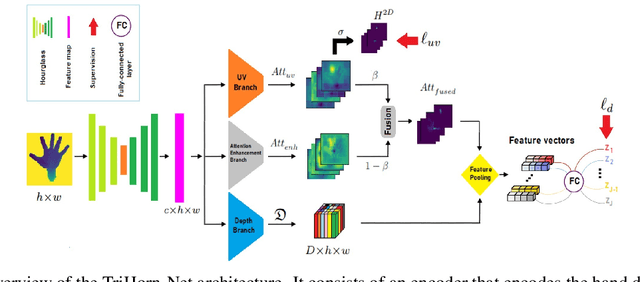

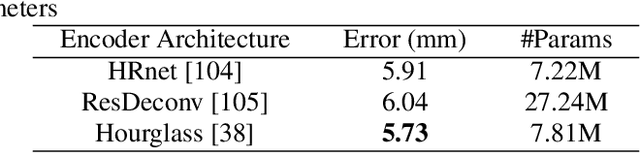
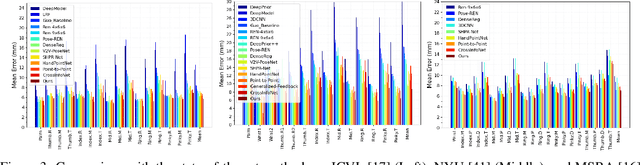
3D hand pose estimation methods have made significant progress recently. However, estimation accuracy is often far from sufficient for specific real-world applications, and thus there is significant room for improvement. This paper proposes TriHorn-Net, a novel model that uses specific innovations to improve hand pose estimation accuracy on depth images. The first innovation is the decomposition of the 3D hand pose estimation into the estimation of 2D joint locations in the depth image space (UV), and the estimation of their corresponding depths aided by two complementary attention maps. This decomposition prevents depth estimation, which is a more difficult task, from interfering with the UV estimations at both the prediction and feature levels. The second innovation is PixDropout, which is, to the best of our knowledge, the first appearance-based data augmentation method for hand depth images. Experimental results demonstrate that the proposed model outperforms the state-of-the-art methods on three public benchmark datasets.
All You Need In Sign Language Production
Jan 06, 2022
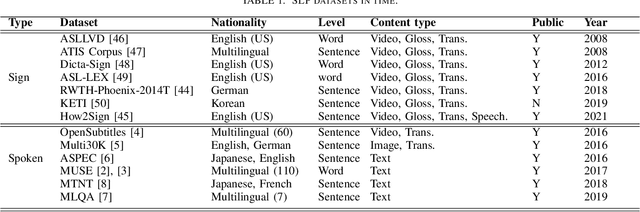
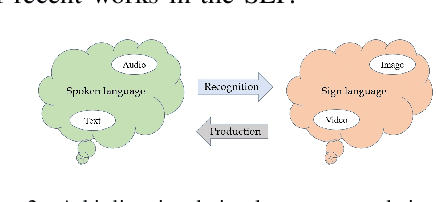

Sign Language is the dominant form of communication language used in the deaf and hearing-impaired community. To make an easy and mutual communication between the hearing-impaired and the hearing communities, building a robust system capable of translating the spoken language into sign language and vice versa is fundamental. To this end, sign language recognition and production are two necessary parts for making such a two-way system. Sign language recognition and production need to cope with some critical challenges. In this survey, we review recent advances in Sign Language Production (SLP) and related areas using deep learning. To have more realistic perspectives to sign language, we present an introduction to the Deaf culture, Deaf centers, psychological perspective of sign language, the main differences between spoken language and sign language. Furthermore, we present the fundamental components of a bi-directional sign language translation system, discussing the main challenges in this area. Also, the backbone architectures and methods in SLP are briefly introduced and the proposed taxonomy on SLP is presented. Finally, a general framework for SLP and performance evaluation, and also a discussion on the recent developments, advantages, and limitations in SLP, commenting on possible lines for future research are presented.
A Survey on Deep learning based Document Image Enhancement
Jan 03, 2022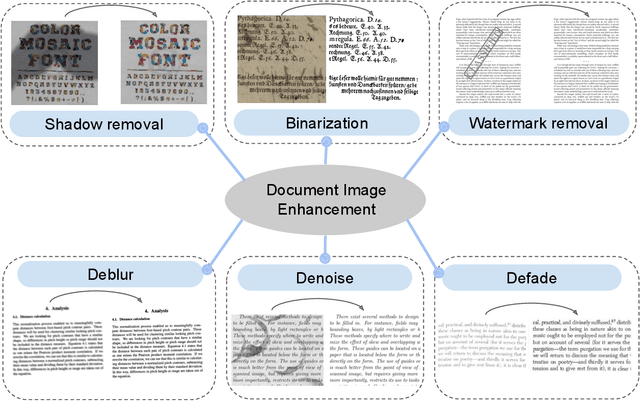
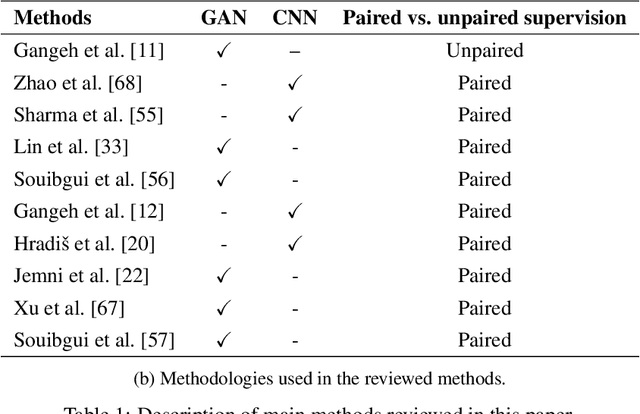


Digitized documents such as scientific articles, tax forms, invoices, contract papers, historic texts are widely used nowadays. These document images could be degraded or damaged due to various reasons including poor lighting conditions, shadow, distortions like noise and blur, aging, ink stain, bleed-through, watermark, stamp, etc. Document image enhancement plays a crucial role as a pre-processing step in many automated document analysis and recognition tasks such as character recognition. With recent advances in deep learning, many methods are proposed to enhance the quality of these document images. In this paper, we review deep learning-based methods, datasets, and metrics for six main document image enhancement tasks, including binarization, debluring, denoising, defading, watermark removal, and shadow removal. We summarize the recent works for each task and discuss their features, challenges, and limitations. We introduce multiple document image enhancement tasks that have received little to no attention, including over and under exposure correction, super resolution, and bleed-through removal. We identify several promising research directions and opportunities for future research.
Cross Your Body: A Cognitive Assessment System for Children
Nov 24, 2021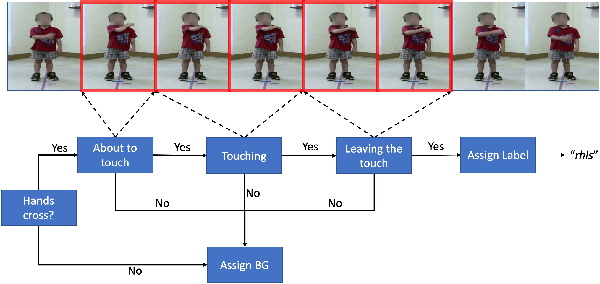
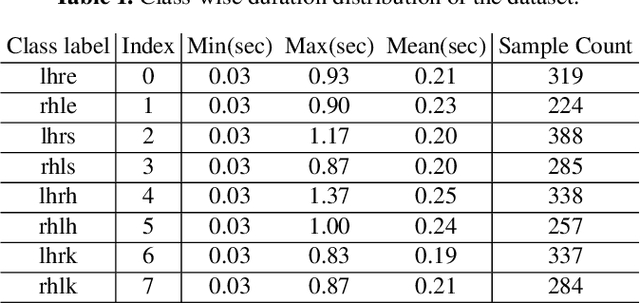

While many action recognition techniques have great success on public benchmarks, such performance is not necessarily replicated in real-world scenarios, where the data comes from specific application requirements. The specific real-world application that we are focusing on in this paper is cognitive assessment in children using cognitively demanding physical tasks. We created a system called Cross-Your-Body and recorded data, which is unique in several aspects, including the fact that the tasks have been designed by psychologists, the subjects are children, and the videos capture real-world usage, as they record children performing tasks during real-world assessment by psychologists. Other distinguishing features of our system is that it's scores can directly be translated to measure executive functioning which is one of the key factor to distinguish onset of ADHD in adolescent kids. Due to imprecise execution of actions performed by children, and the presence of fine-grained motion patterns, we systematically investigate and evaluate relevant methods on the recorded data. It is our goal that this system will be useful in advancing research in cognitive assessment of kids.
Hierarchical Modeling for Task Recognition and Action Segmentation in Weakly-Labeled Instructional Videos
Oct 12, 2021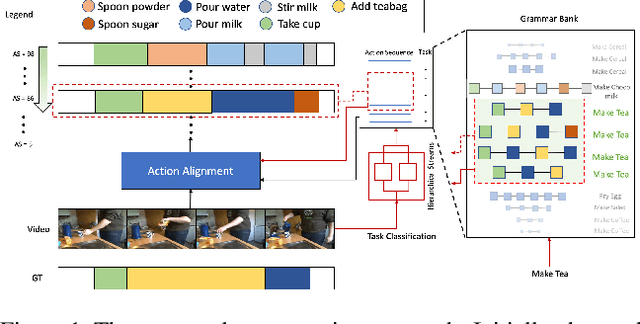
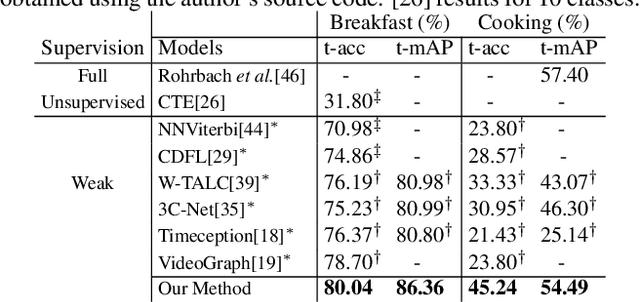
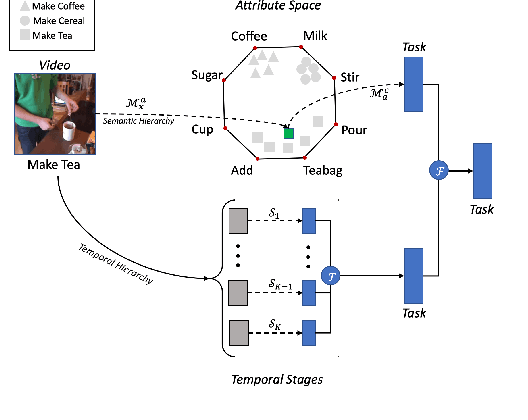
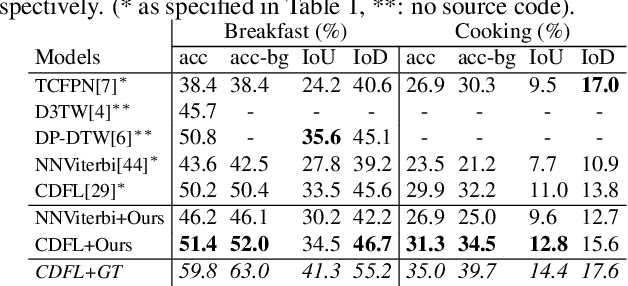
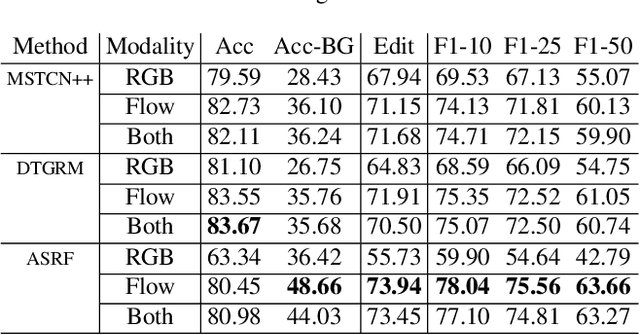
This paper focuses on task recognition and action segmentation in weakly-labeled instructional videos, where only the ordered sequence of video-level actions is available during training. We propose a two-stream framework, which exploits semantic and temporal hierarchies to recognize top-level tasks in instructional videos. Further, we present a novel top-down weakly-supervised action segmentation approach, where the predicted task is used to constrain the inference of fine-grained action sequences. Experimental results on the popular Breakfast and Cooking 2 datasets show that our two-stream hierarchical task modeling significantly outperforms existing methods in top-level task recognition for all datasets and metrics. Additionally, using our task recognition framework in the proposed top-down action segmentation approach consistently improves the state of the art, while also reducing segmentation inference time by 80-90 percent.
Gated Fusion Network for SAO Filter and Inter Frame Prediction in Versatile Video Coding
May 25, 2021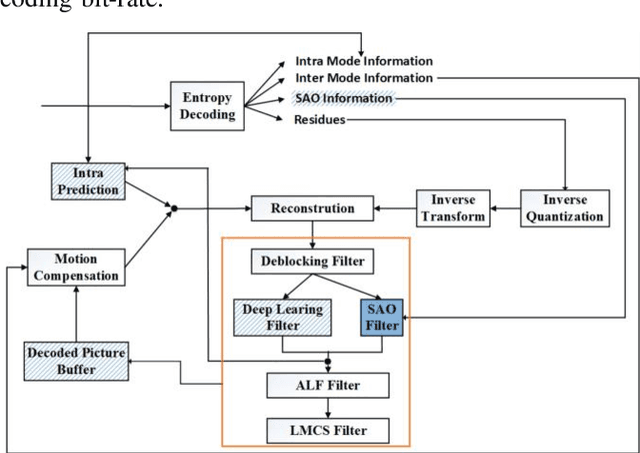
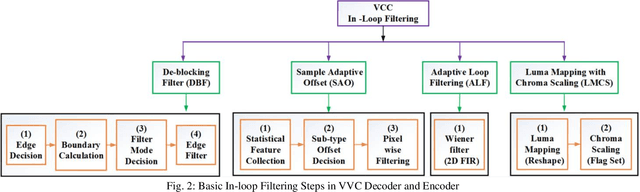
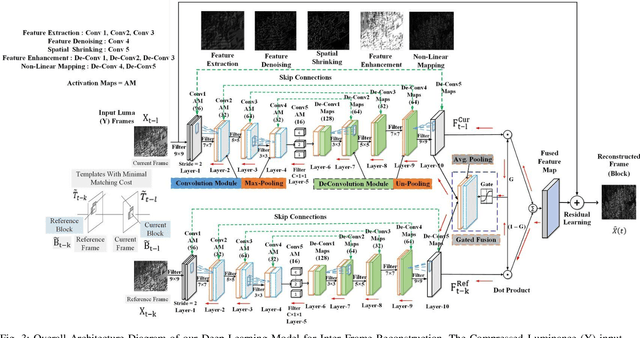
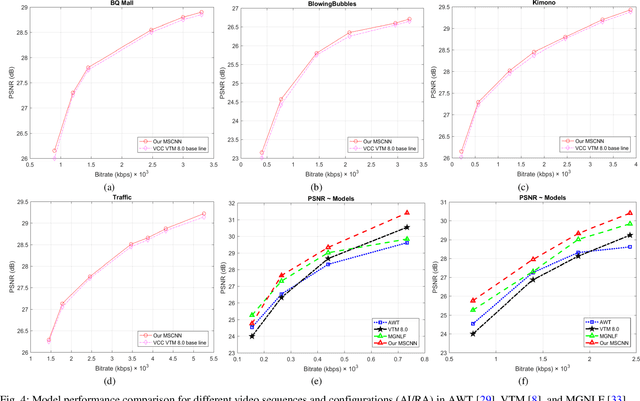
To achieve higher coding efficiency, Versatile Video Coding (VVC) includes several novel components, but at the expense of increasing decoder computational complexity. These technologies at a low bit rate often create contouring and ringing effects on the reconstructed frames and introduce various blocking artifacts at block boundaries. To suppress those visual artifacts, the VVC framework supports four post-processing filter operations. The interoperation of these filters introduces extra signaling bits and eventually becomes overhead at higher resolution video processing. In this paper, a novel deep learning-based model is proposed for sample adaptive offset (SAO) nonlinear filtering operation and substantiated the merits of intra-inter frame quality enhancement. We introduced a variable filter size multi-scale CNN (MSCNN) to improve the denoising operation and incorporated strided deconvolution for further computation improvement. We demonstrated that our deconvolution model can effectively be trained by leveraging the high-frequency edge features learned in a parallel fashion using feature fusion and residual learning. The simulation results demonstrate that the proposed method outperforms the baseline VVC method in BD-BR, BD-PSNR measurements and achieves an average of 3.762 % bit rate saving on the standard video test sequences.
Multi-scale Deep Learning Architecture for Nucleus Detection in Renal Cell Carcinoma Microscopy Image
Apr 28, 2021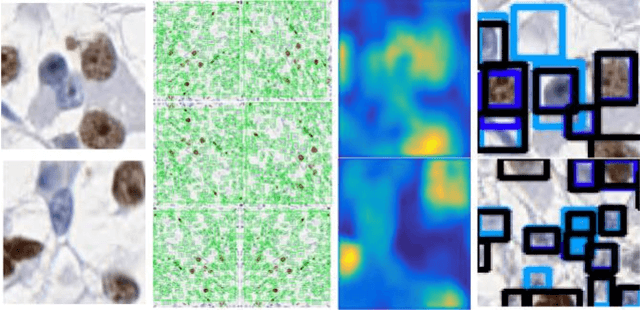
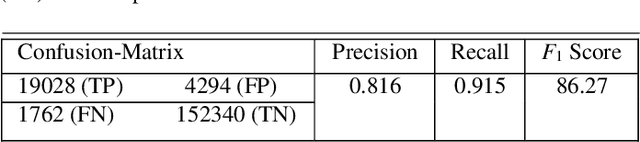
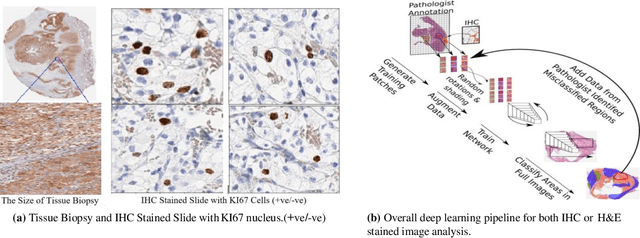
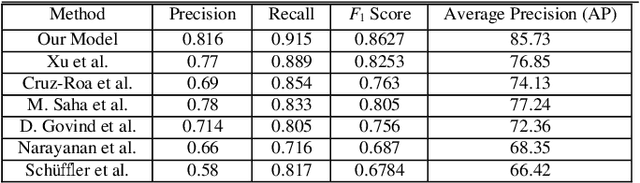
Clear cell renal cell carcinoma (ccRCC) is one of the most common forms of intratumoral heterogeneity in the study of renal cancer. ccRCC originates from the epithelial lining of proximal convoluted renal tubules. These cells undergo abnormal mutations in the presence of Ki67 protein and create a lump-like structure through cell proliferation. Manual counting of tumor cells in the tissue-affected sections is one of the strongest prognostic markers for renal cancer. However, this procedure is time-consuming and also prone to subjectivity. These assessments are based on the physical cell appearance and suffer wide intra-observer variations. Therefore, better cell nucleus detection and counting techniques can be an important biomarker for the assessment of tumor cell proliferation in routine pathological investigations. In this paper, we introduce a deep learning-based detection model for cell classification on IHC stained histology images. These images are classified into binary classes to find the presence of Ki67 protein in cancer-affected nucleus regions. Our model maps the multi-scale pyramid features and saliency information from local bounded regions and predicts the bounding box coordinates through regression. Our method validates the impact of Ki67 expression across a cohort of four hundred histology images treated with localized ccRCC and compares our results with the existing state-of-the-art nucleus detection methods. The precision and recall scores of the proposed method are computed and compared on the clinical data sets. The experimental results demonstrate that our model improves the F1 score up to 86.3% and an average area under the Precision-Recall curve as 85.73%.
Action Duration Prediction for Segment-Level Alignment of Weakly-Labeled Videos
Nov 20, 2020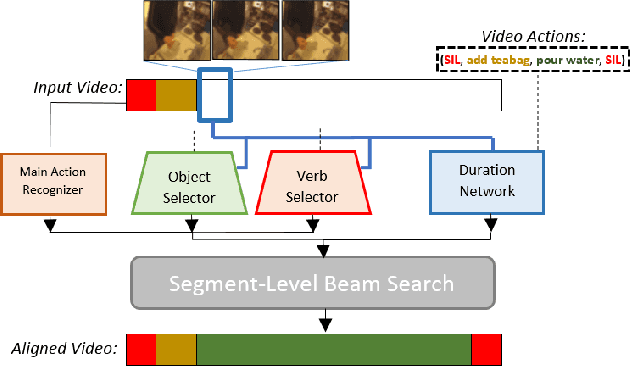
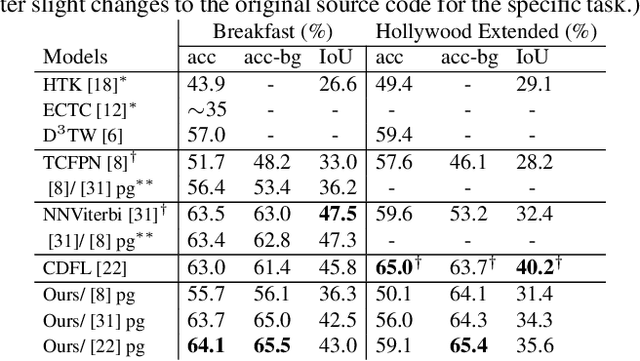
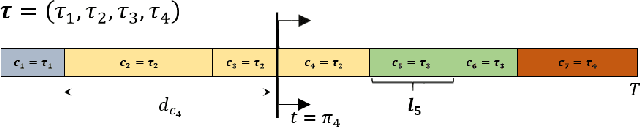
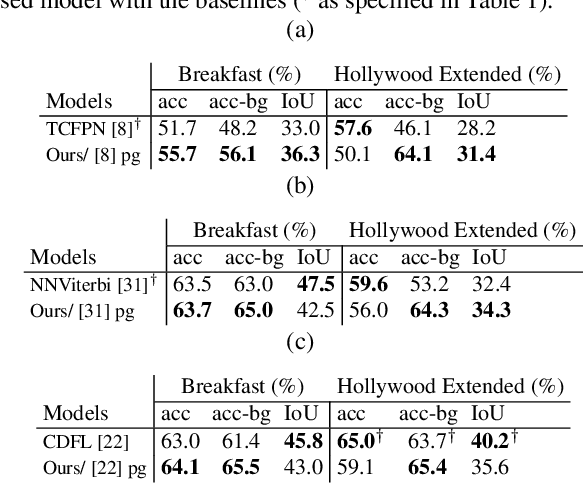
This paper focuses on weakly-supervised action alignment, where only the ordered sequence of video-level actions is available for training. We propose a novel Duration Network, which captures a short temporal window of the video and learns to predict the remaining duration of a given action at any point in time with a level of granularity based on the type of that action. Further, we introduce a Segment-Level Beam Search to obtain the best alignment, that maximizes our posterior probability. Segment-Level Beam Search efficiently aligns actions by considering only a selected set of frames that have more confident predictions. The experimental results show that our alignments for long videos are more robust than existing models. Moreover, the proposed method achieves state of the art results in certain cases on the popular Breakfast and Hollywood Extended datasets.