 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LF-VIO: A Visual-Inertial-Odometry Framework for Large Field-of-View Cameras with Negative Plane
Feb 25, 2022
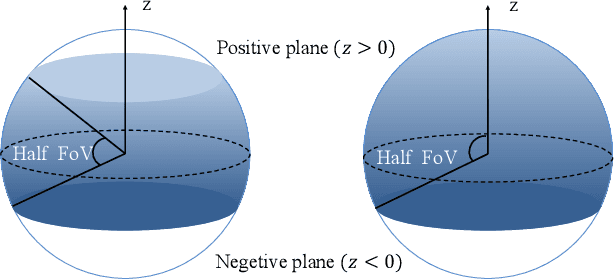
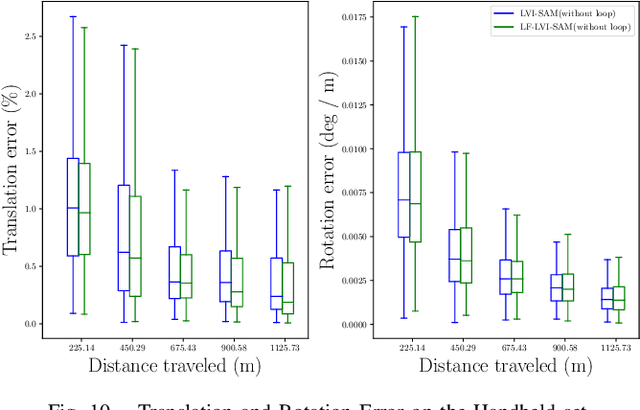
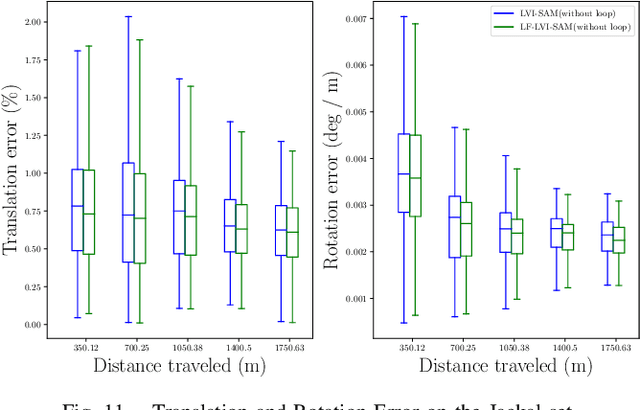

Visual-inertial-odometry has attracted extensive attention in the field of autonomous driving and robotics. The size of Field of View (FoV) plays an important role in Visual-Odometry (VO) and Visual-Inertial-Odometry (VIO), as a large FoV enables to perceive a wide range of surrounding scene elements and features. However, when the field of the camera reaches the negative half plane, one cannot simply use [u,v,1]^T to represent the image feature points anymore. To tackle this issue, we propose LF-VIO, a real-time VIO framework for cameras with extremely large FoV. We leverage a three-dimensional vector with unit length to represent feature points, and design a series of algorithms to overcome this challenge. To address the scarcity of panoramic visual odometry datasets with ground-truth location and pose, we present the PALVIO dataset, collected with a Panoramic Annular Lens (PAL) system with an entire FoV of 360x(40-120) degrees and an IMU sensor. With a comprehensive variety of experiments, the proposed LF-VIO is verified on both the established PALVIO benchmark and a public fisheye camera dataset with a FoV of 360x(0-93.5) degrees. LF-VIO outperforms state-of-the-art visual-inertial-odometry methods. Our dataset and code are made publicly available at https://github.com/flysoaryun/LF-VIO
Spherical Transformer
Feb 10, 2022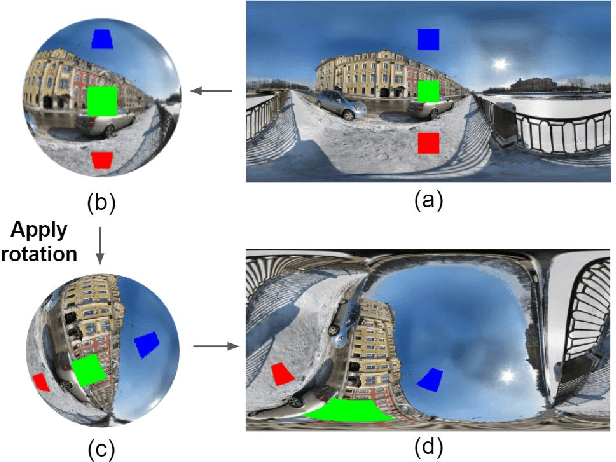
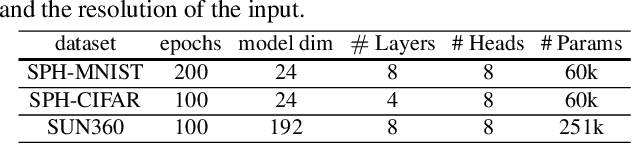
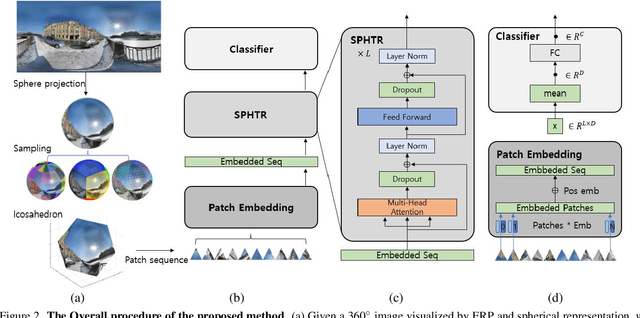
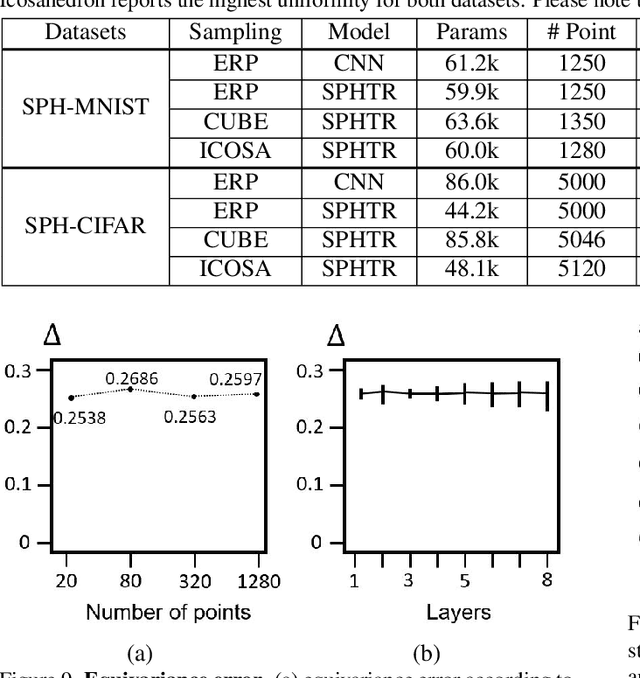
Using convolutional neural networks for 360images can induce sub-optimal performance due to distortions entailed by a planar projection. The distortion gets deteriorated when a rotation is applied to the 360image. Thus, many researches based on convolutions attempt to reduce the distortions to learn accurate representation. In contrast, we leverage the transformer architecture to solve image classification problems for 360images. Using the proposed transformer for 360images has two advantages. First, our method does not require the erroneous planar projection process by sampling pixels from the sphere surface. Second, our sampling method based on regular polyhedrons makes low rotation equivariance errors, because specific rotations can be reduced to permutations of faces. In experiments, we validate our network on two aspects, as follows. First, we show that using a transformer with highly uniform sampling methods can help reduce the distortion. Second, we demonstrate that the transformer architecture can achieve rotation equivariance on specific rotations. We compare our method to other state-of-the-art algorithms using the SPH-MNIST, SPH-CIFAR, and SUN360 datasets and show that our method is competitive with other methods.
Explaining neural network predictions of material strength
Nov 05, 2021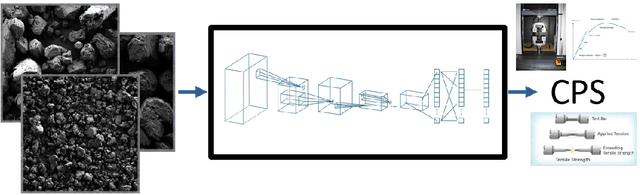
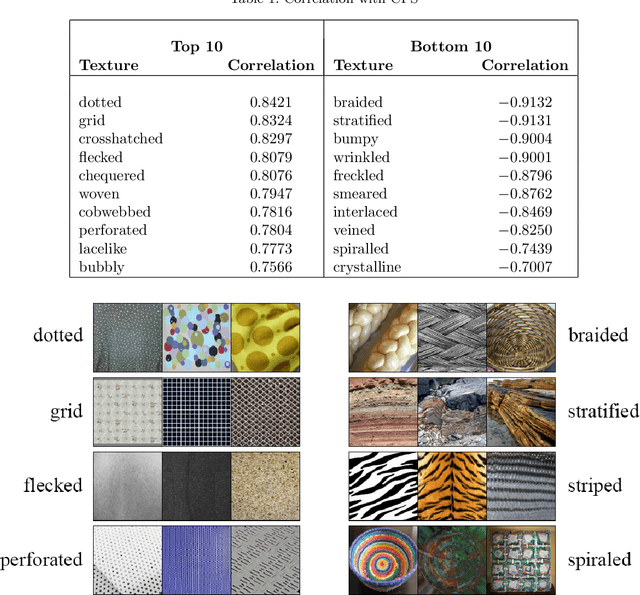


We recently developed a deep learning method that can determine the critical peak stress of a material by looking at scanning electron microscope (SEM) images of the material's crystals. However, it has been somewhat unclear what kind of image features the network is keying off of when it makes its prediction. It is common in computer vision to employ an explainable AI saliency map to tell one what parts of an image are important to the network's decision. One can usually deduce the important features by looking at these salient locations. However, SEM images of crystals are more abstract to the human observer than natural image photographs. As a result, it is not easy to tell what features are important at the locations which are most salient. To solve this, we developed a method that helps us map features from important locations in SEM images to non-abstract textures that are easier to interpret.
The Power of Proxy Data and Proxy Networks for Hyper-Parameter Optimization in Medical Image Segmentation
Jul 12, 2021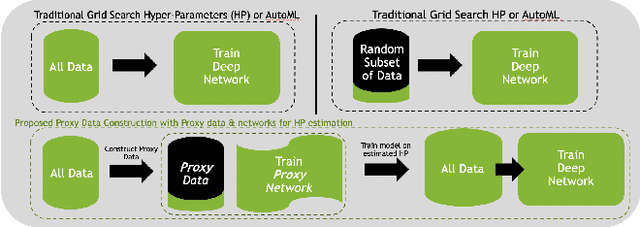
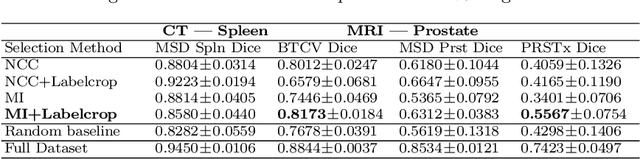
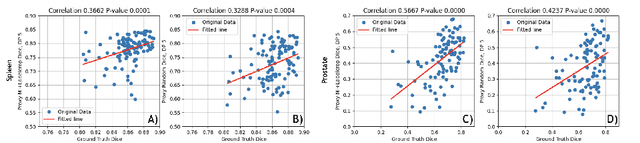
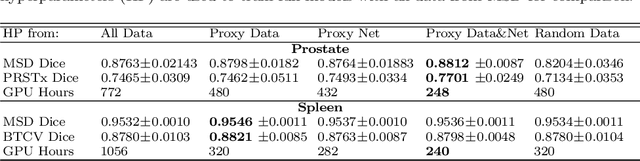
Deep learning models for medical image segmentation are primarily data-driven. Models trained with more data lead to improved performance and generalizability. However, training is a computationally expensive process because multiple hyper-parameters need to be tested to find the optimal setting for best performance. In this work, we focus on accelerating the estimation of hyper-parameters by proposing two novel methodologies: proxy data and proxy networks. Both can be useful for estimating hyper-parameters more efficiently. We test the proposed techniques on CT and MR imaging modalities using well-known public datasets. In both cases using one dataset for building proxy data and another data source for external evaluation. For CT, the approach is tested on spleen segmentation with two datasets. The first dataset is from the medical segmentation decathlon (MSD), where the proxy data is constructed, the secondary dataset is utilized as an external validation dataset. Similarly, for MR, the approach is evaluated on prostate segmentation where the first dataset is from MSD and the second dataset is PROSTATEx. First, we show higher correlation to using full data for training when testing on the external validation set using smaller proxy data than a random selection of the proxy data. Second, we show that a high correlation exists for proxy networks when compared with the full network on validation Dice score. Third, we show that the proposed approach of utilizing a proxy network can speed up an AutoML framework for hyper-parameter search by 3.3x, and by 4.4x if proxy data and proxy network are utilized together.
Deep Bayesian inference for seismic imaging with tasks
Oct 10, 2021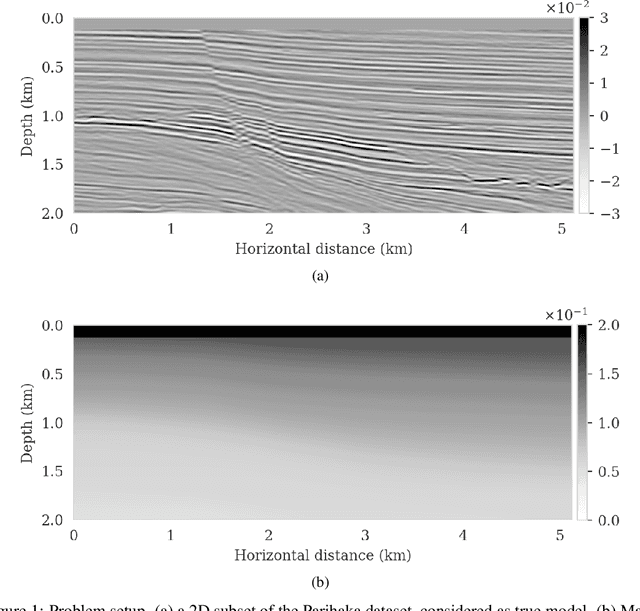
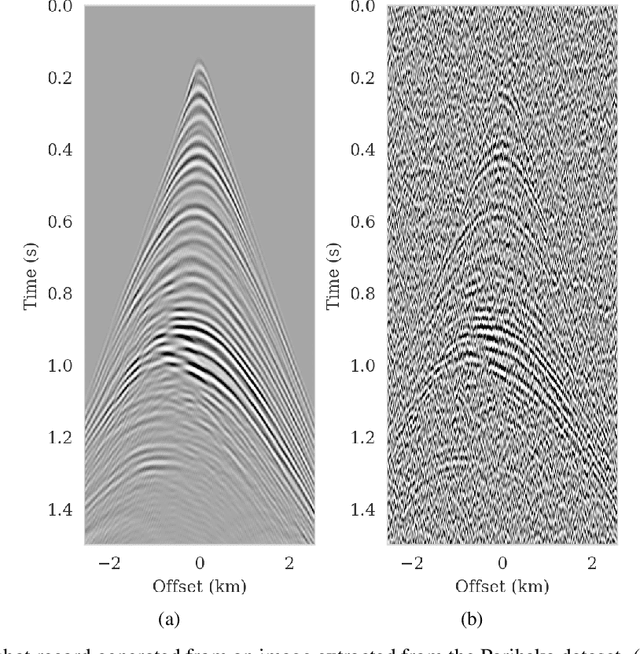
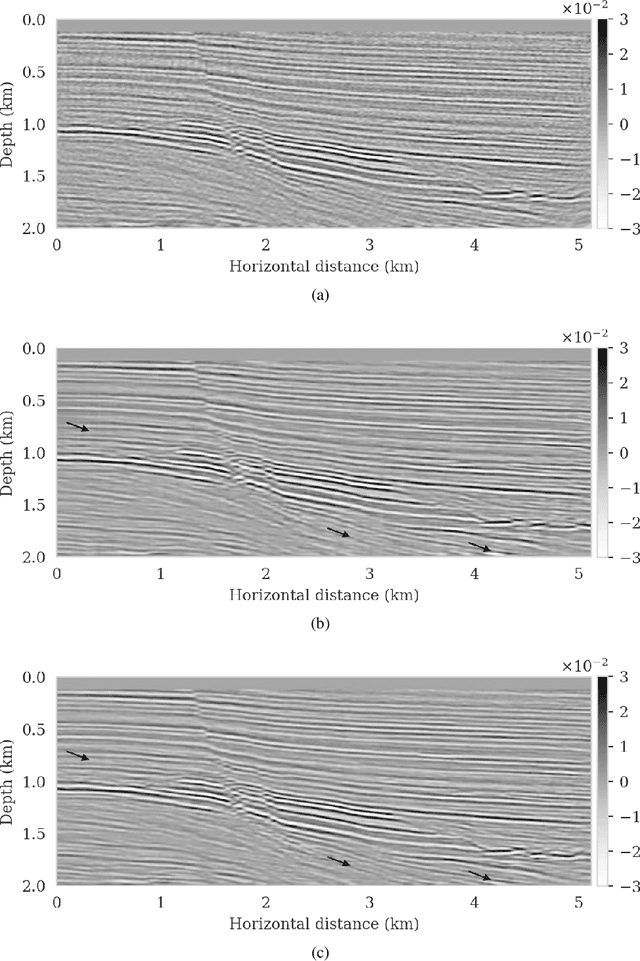
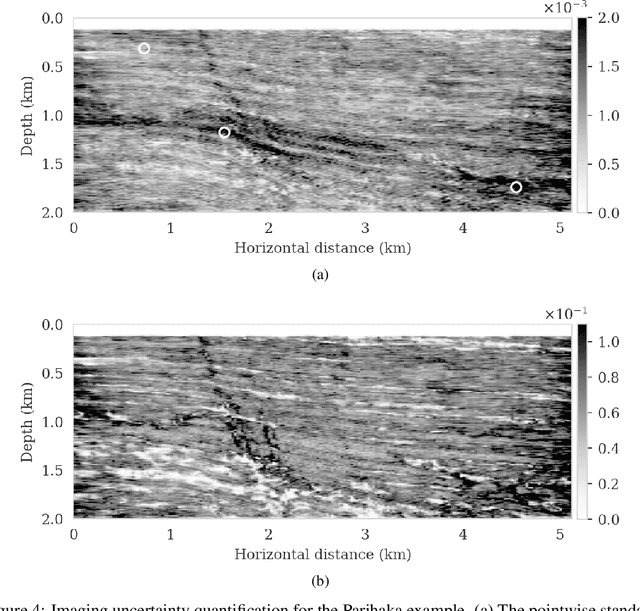
We propose to use techniques from Bayesian inference and deep neural networks to translate uncertainty in seismic imaging to uncertainty in tasks performed on the image, such as horizon tracking. Seismic imaging is an ill-posed inverse problem because of unavoidable bandwidth and aperture limitations, which that is hampered by the presence of noise and linearization errors. Many regularization methods, such as transform-domain sparsity promotion, have been designed to deal with the adverse effects of these errors, however, these methods run the risk of biasing the solution and do not provide information on uncertainty in the image space and how this uncertainty impacts certain tasks on the image. A systematic approach is proposed to translate uncertainty due to noise in the data to confidence intervals of automatically tracked horizons in the image. The uncertainty is characterized by a convolutional neural network (CNN) and to assess these uncertainties, samples are drawn from the posterior distribution of the CNN weights, used to parameterize the image. Compared to traditional priors, in the literature it is argued that these CNNs introduce a flexible inductive bias that is a surprisingly good fit for many diverse domains in imaging. The method of stochastic gradient Langevin dynamics is employed to sample from the posterior distribution. This method is designed to handle large scale Bayesian inference problems with computationally expensive forward operators as in seismic imaging. Aside from offering a robust alternative to maximum a posteriori estimate that is prone to overfitting, access to these samples allow us to translate uncertainty in the image, due to noise in the data, to uncertainty on the tracked horizons. For instance, it admits estimates for the pointwise standard deviation on the image and for confidence intervals on its automatically tracked horizons.
In-Domain GAN Inversion for Real Image Editing
Mar 31, 2020

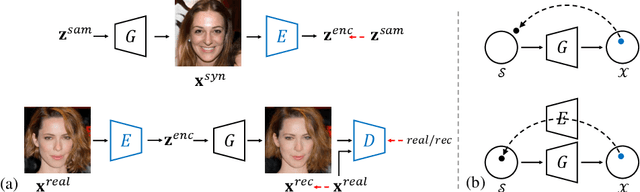

Recent work has shown that a variety of controllable semantics emerges in the latent space of the Generative Adversarial Networks (GANs) when being trained to synthesize images. However, it is difficult to use these learned semantics for real image editing. A common practice of feeding a real image to a trained GAN generator is to invert it back to a latent code. However, we find that existing inversion methods typically focus on reconstructing the target image by pixel values yet fail to land the inverted code in the semantic domain of the original latent space. As a result, the reconstructed image cannot well support semantic editing through varying the latent code. To solve this problem, we propose an in-domain GAN inversion approach, which not only faithfully reconstructs the input image but also ensures the inverted code to be semantically meaningful for editing. We first learn a novel domain-guided encoder to project any given image to the native latent space of GANs. We then propose a domain-regularized optimization by involving the encoder as a regularizer to fine-tune the code produced by the encoder, which better recovers the target image. Extensive experiments suggest that our inversion method achieves satisfying real image reconstruction and more importantly facilitates various image editing tasks, such as image interpolation and semantic manipulation, significantly outperforming start-of-the-arts.
Bridging the Gap Between Learning in Discrete and Continuous Environments for Vision-and-Language Navigation
Mar 05, 2022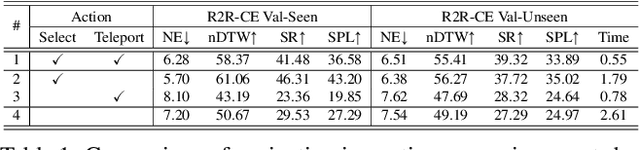
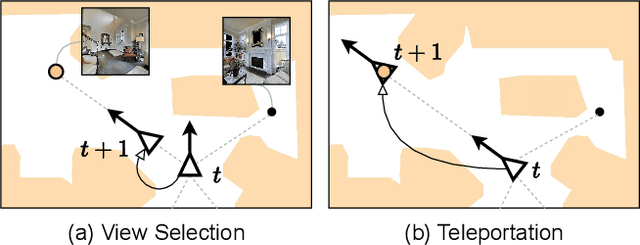
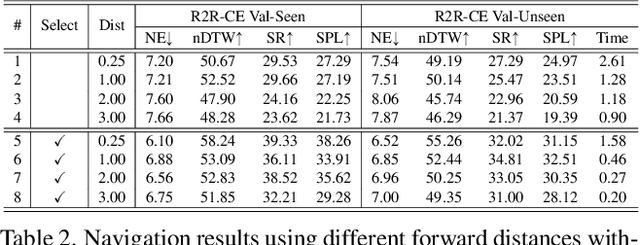
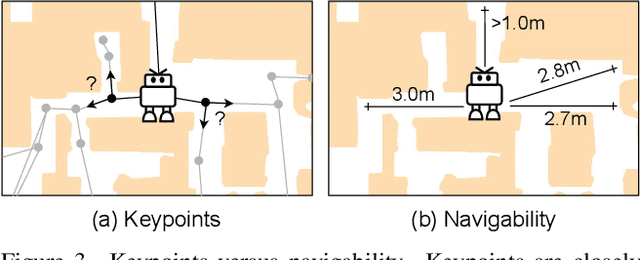
Most existing works in vision-and-language navigation (VLN) focus on either discrete or continuous environments, training agents that cannot generalize across the two. The fundamental difference between the two setups is that discrete navigation assumes prior knowledge of the connectivity graph of the environment, so that the agent can effectively transfer the problem of navigation with low-level controls to jumping from node to node with high-level actions by grounding to an image of a navigable direction. To bridge the discrete-to-continuous gap, we propose a predictor to generate a set of candidate waypoints during navigation, so that agents designed with high-level actions can be transferred to and trained in continuous environments. We refine the connectivity graph of Matterport3D to fit the continuous Habitat-Matterport3D, and train the waypoints predictor with the refined graphs to produce accessible waypoints at each time step. Moreover, we demonstrate that the predicted waypoints can be augmented during training to diversify the views and paths, and therefore enhance agent's generalization ability. Through extensive experiments we show that agents navigating in continuous environments with predicted waypoints perform significantly better than agents using low-level actions, which reduces the absolute discrete-to-continuous gap by 11.76% Success Weighted by Path Length (SPL) for the Cross-Modal Matching Agent and 18.24% SPL for the Recurrent VLN-BERT. Our agents, trained with a simple imitation learning objective, outperform previous methods by a large margin, achieving new state-of-the-art results on the testing environments of the R2R-CE and the RxR-CE datasets.
SI-Score: An image dataset for fine-grained analysis of robustness to object location, rotation and size
Apr 09, 2021

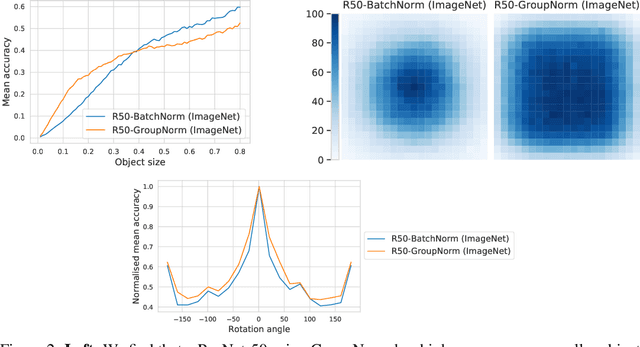

Before deploying machine learning models it is critical to assess their robustness. In the context of deep neural networks for image understanding, changing the object location, rotation and size may affect the predictions in non-trivial ways. In this work we perform a fine-grained analysis of robustness with respect to these factors of variation using SI-Score, a synthetic dataset. In particular, we investigate ResNets, Vision Transformers and CLIP, and identify interesting qualitative differences between these.
Unsupervised Multi-Domain Multimodal Image-to-Image Translation with Explicit Domain-Constrained Disentanglement
Nov 02, 2019
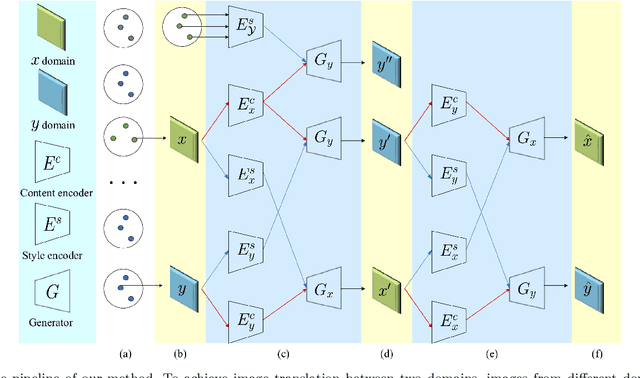
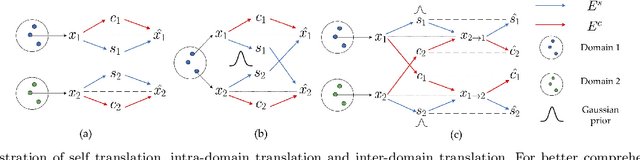
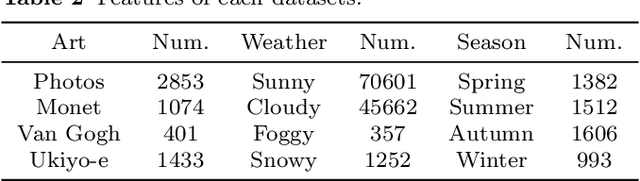
Image-to-image translation has drawn great attention during the past few years. It aims to translate an image in one domain to a given reference image in another domain. Due to its effectiveness and efficiency, many applications can be formulated as image-to-image translation problems. However, three main challenges remain in image-to-image translation: 1) the lack of large amounts of aligned training pairs for different tasks; 2) the ambiguity of multiple possible outputs from a single input image; and 3) the lack of simultaneous training of multiple datasets from different domains within a single network. We also found in experiments that the implicit disentanglement of content and style could lead to unexpect results. In this paper, we propose a unified framework for learning to generate diverse outputs using unpaired training data and allow simultaneous training of multiple datasets from different domains via a single network. Furthermore, we also investigate how to better extract domain supervision information so as to learn better disentangled representations and achieve better image translation. Experiments show that the proposed method outperforms or is comparable with the state-of-the-art methods.
The CLEAR Benchmark: Continual LEArning on Real-World Imagery
Jan 17, 2022
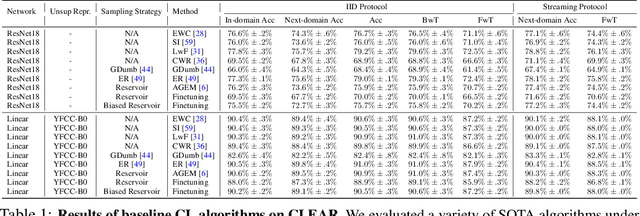
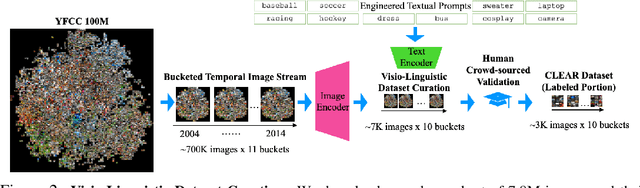
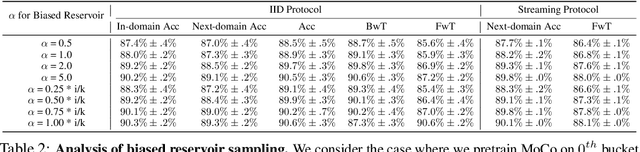
Continual learning (CL) is widely regarded as crucial challenge for lifelong AI. However, existing CL benchmarks, e.g. Permuted-MNIST and Split-CIFAR, make use of artificial temporal variation and do not align with or generalize to the real-world. In this paper, we introduce CLEAR, the first continual image classification benchmark dataset with a natural temporal evolution of visual concepts in the real world that spans a decade (2004-2014). We build CLEAR from existing large-scale image collections (YFCC100M) through a novel and scalable low-cost approach to visio-linguistic dataset curation. Our pipeline makes use of pretrained vision-language models (e.g. CLIP) to interactively build labeled datasets, which are further validated with crowd-sourcing to remove errors and even inappropriate images (hidden in original YFCC100M). The major strength of CLEAR over prior CL benchmarks is the smooth temporal evolution of visual concepts with real-world imagery, including both high-quality labeled data along with abundant unlabeled samples per time period for continual semi-supervised learning. We find that a simple unsupervised pre-training step can already boost state-of-the-art CL algorithms that only utilize fully-supervised data. Our analysis also reveals that mainstream CL evaluation protocols that train and test on iid data artificially inflate performance of CL system. To address this, we propose novel "streaming" protocols for CL that always test on the (near) future. Interestingly, streaming protocols (a) can simplify dataset curation since today's testset can be repurposed for tomorrow's trainset and (b) can produce more generalizable models with more accurate estimates of performance since all labeled data from each time-period is used for both training and testing (unlike classic iid train-test splits).