 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deconfounded Visual Grounding
Dec 31, 2021
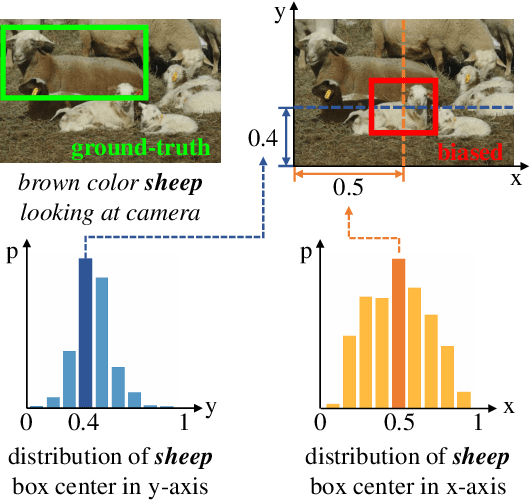
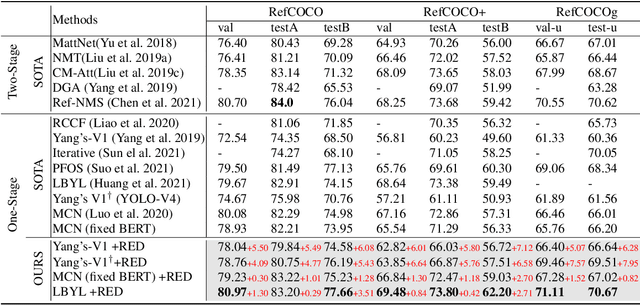
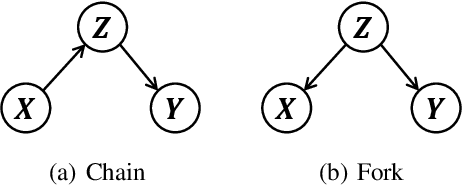
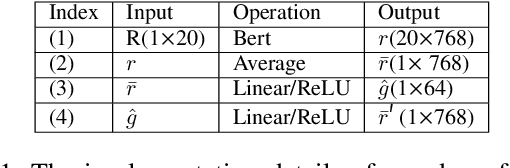
We focus on the confounding bias between language and location in the visual grounding pipeline, where we find that the bias is the major visual reasoning bottleneck. For example, the grounding process is usually a trivial language-location association without visual reasoning, e.g., grounding any language query containing sheep to the nearly central regions, due to that most queries about sheep have ground-truth locations at the image center. First, we frame the visual grounding pipeline into a causal graph, which shows the causalities among image, query, target location and underlying confounder. Through the causal graph, we know how to break the grounding bottleneck: deconfounded visual grounding. Second, to tackle the challenge that the confounder is unobserved in general, we propose a confounder-agnostic approach called: Referring Expression Deconfounder (RED), to remove the confounding bias. Third, we implement RED as a simple language attention, which can be applied in any grounding method. On popular benchmarks, RED improves various state-of-the-art grounding methods by a significant margin. Code will soon be available at: https://github.com/JianqiangH/Deconfounded_VG.
Robust Segmentation of Brain MRI in the Wild with Hierarchical CNNs and no Retraining
Mar 07, 2022


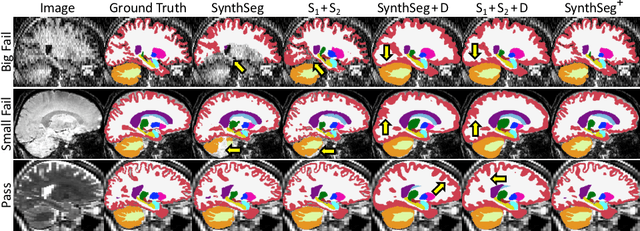
Retrospective analysis of brain MRI scans acquired in the clinic has the potential to enable neuroimaging studies with sample sizes much larger than those found in research datasets. However, analysing such clinical images "in the wild" is challenging, since subjects are scanned with highly variable protocols (MR contrast, resolution, orientation, etc.). Nevertheless, recent advances in convolutional neural networks (CNNs) and domain randomisation for image segmentation, best represented by the publicly available method SynthSeg, may enable morphometry of clinical MRI at scale. In this work, we first evaluate SynthSeg on an uncurated, heterogeneous dataset of more than 10,000 scans acquired at Massachusetts General Hospital. We show that SynthSeg is generally robust, but frequently falters on scans with low signal-to-noise ratio or poor tissue contrast. Next, we propose SynthSeg+, a novel method that greatly mitigates these problems using a hierarchy of conditional segmentation and denoising CNNs. We show that this method is considerably more robust than SynthSeg, while also outperforming cascaded networks and state-of-the-art segmentation denoising methods. Finally, we apply our approach to a proof-of-concept volumetric study of ageing, where it closely replicates atrophy patterns observed in research studies conducted on high-quality, 1mm, T1-weighted scans. The code and trained model are publicly available at https://github.com/BBillot/SynthSeg.
Phase Aberration Robust Beamformer for Planewave US Using Self-Supervised Learning
Feb 16, 2022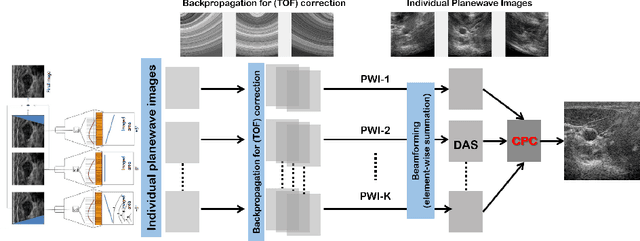
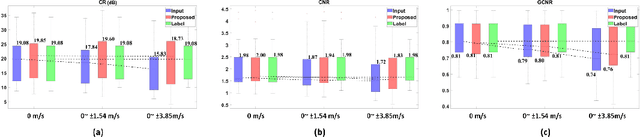
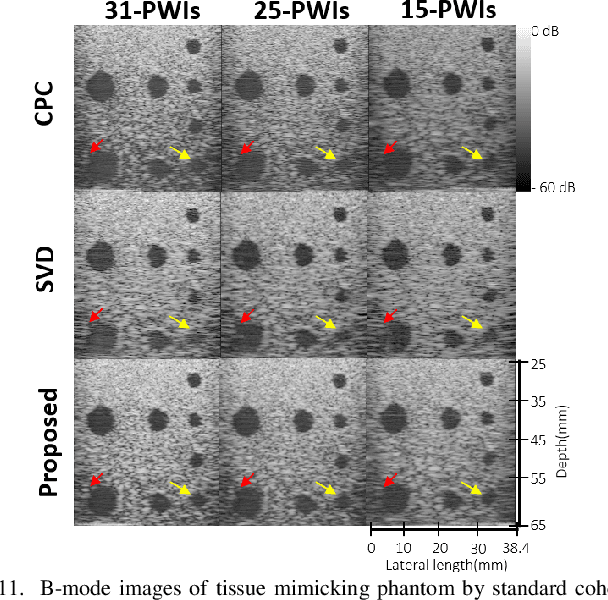
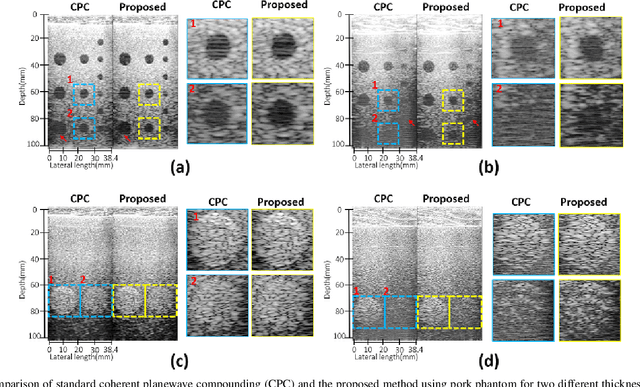
Ultrasound (US) is widely used for clinical imaging applications thanks to its real-time and non-invasive nature. However, its lesion detectability is often limited in many applications due to the phase aberration artefact caused by variations in the speed of sound (SoS) within body parts. To address this, here we propose a novel self-supervised 3D CNN that enables phase aberration robust plane-wave imaging. Instead of aiming at estimating the SoS distribution as in conventional methods, our approach is unique in that the network is trained in a self-supervised manner to robustly generate a high-quality image from various phase aberrated images by modeling the variation in the speed of sound as stochastic. Experimental results using real measurements from tissue-mimicking phantom and \textit{in vivo} scans confirmed that the proposed method can significantly reduce the phase aberration artifacts and improve the visual quality of deep scans.
RRL:Regional Rotation Layer in Convolutional Neural Networks
Feb 25, 2022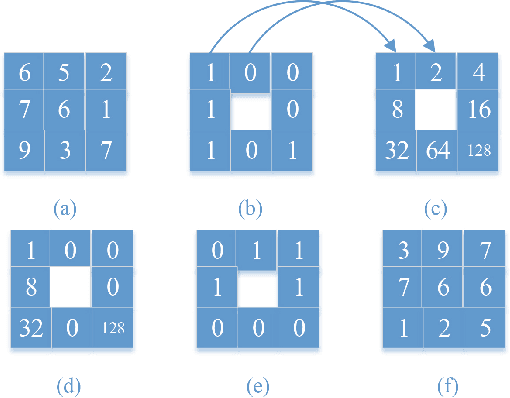
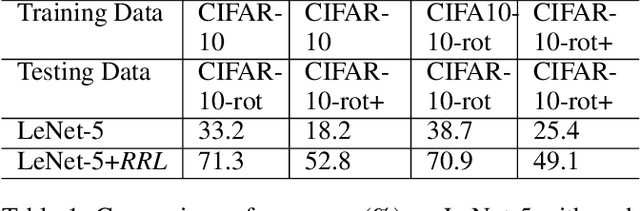
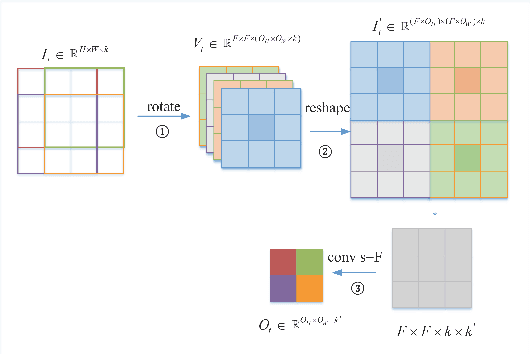
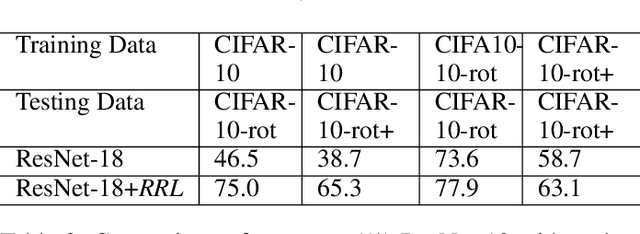
Convolutional Neural Networks (CNNs) perform very well in image classification and object detection in recent years, but even the most advanced models have limited rotation invariance. Known solutions include the enhancement of training data and the increase of rotation invariance by globally merging the rotation equivariant features. These methods either increase the workload of training or increase the number of model parameters. To address this problem, this paper proposes a module that can be inserted into the existing networks, and directly incorporates the rotation invariance into the feature extraction layers of the CNNs. This module does not have learnable parameters and will not increase the complexity of the model. At the same time, only by training the upright data, it can perform well on the rotated testing set. These advantages will be suitable for fields such as biomedicine and astronomy where it is difficult to obtain upright samples or the target has no directionality. Evaluate our module with LeNet-5, ResNet-18 and tiny-yolov3, we get impressive results.
Structural Gaussian Priors for Bayesian CT reconstruction of Subsea Pipes
Mar 02, 2022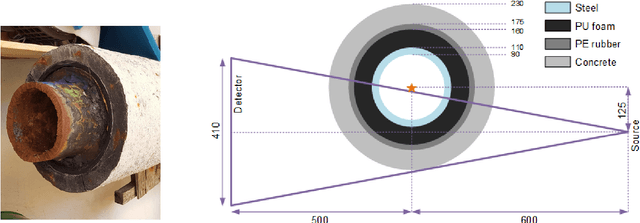
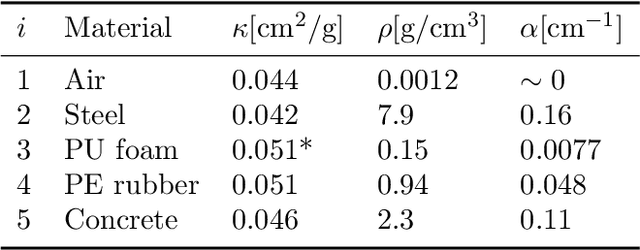
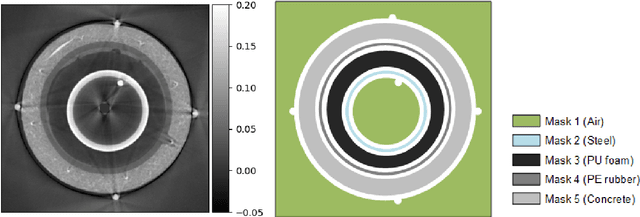
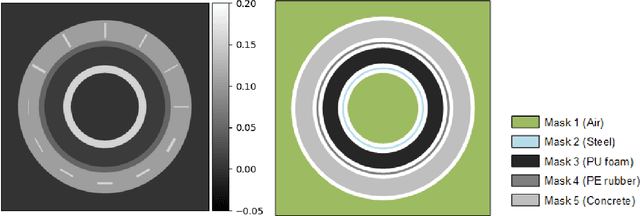
A non-destructive testing (NDT) application of X-ray computed tomography (CT) is inspection of subsea pipes in operation via 2D cross-sectional scans. Data acquisition is time-consuming and costly due to the challenging subsea environment. Reducing the number of projections in a scan can yield time and cost savings, but compromises the reconstruction quality, if conventional reconstruction methods are used. In this work we take a Bayesian approach to CT reconstruction and focus on designing an effective prior to make use of available structural information about the pipe geometry. We propose a new class of structural Gaussian priors to enforce expected material properties in different regions of the reconstructed image based on independent Gaussian priors in combination with global regularity through a Gaussian Markov Random Field (GMRF) prior. Numerical experiments with synthetic and real data show that the proposed structural Gaussian prior can reduce artifacts and enhance contrast in the reconstruction compared to using only a global GMRF prior or no prior at all. We show how the resulting posterior distribution can be efficiently sampled even for large-scale images, which is essential for practical NDT applications.
Right for the Right Reason: Making Image Classification Robust
Jul 23, 2020
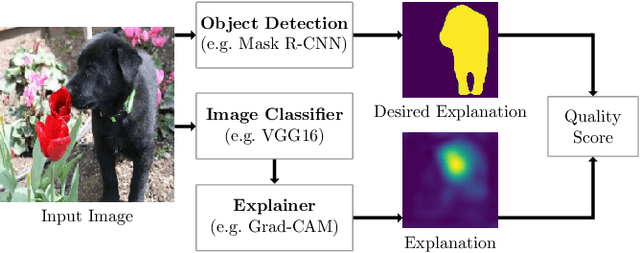
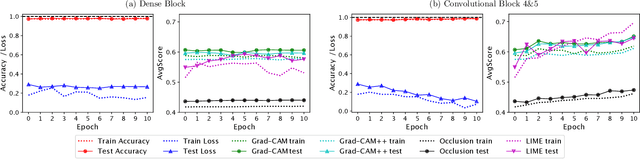

Convolutional neural networks (CNNs) have achieved astonishing performance on various image classification tasks. Although such models classify most images correctly, they do not provide any explanation for their decisions. Recently, there have been attempts to provide such an explanation by determining which parts of the input image the classifier focuses on most. It turns out that many models output the correct classification, but for the wrong reason (e.g., based on irrelevant parts of the image). In this paper, we propose a new score for automatically quantifying to which degree the model focuses on the right image parts. The score is calculated by considering the degree to which the most decisive image regions - given by applying an explainer to the CNN model - overlap with the silhouette of the object to be classified. In extensive experiments using VGG16, ResNet, and MobileNet as CNNs, Occlusion, LIME, and Grad-Cam/Grad-Cam++ as explanation methods, and Dogs vs. Cats and Caltech 101 as data sets, we can show that our metric can indeed be used for making CNN models for image classification more robust while keeping their accuracy.
Analogical Image Translation for Fog Generation
Jun 28, 2020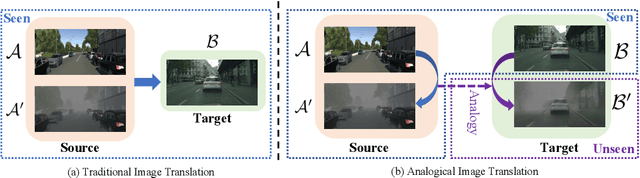
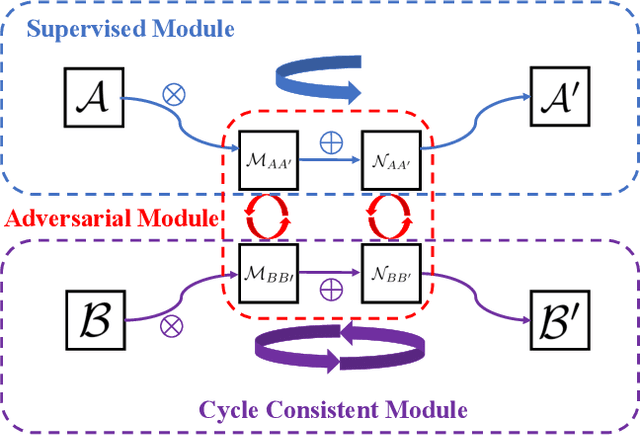
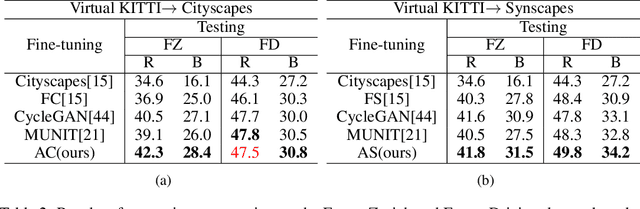

Image-to-image translation is to map images from a given \emph{style} to another given \emph{style}. While exceptionally successful, current methods assume the availability of training images in both source and target domains, which does not always hold in practice. Inspired by humans' reasoning capability of analogy, we propose analogical image translation (AIT). Given images of two styles in the source domain: $\mathcal{A}$ and $\mathcal{A}^\prime$, along with images $\mathcal{B}$ of the first style in the target domain, learn a model to translate $\mathcal{B}$ to $\mathcal{B}^\prime$ in the target domain, such that $\mathcal{A}:\mathcal{A}^\prime ::\mathcal{B}:\mathcal{B}^\prime$. AIT is especially useful for translation scenarios in which training data of one style is hard to obtain but training data of the same two styles in another domain is available. For instance, in the case from normal conditions to extreme, rare conditions, obtaining real training images for the latter case is challenging but obtaining synthetic data for both cases is relatively easy. In this work, we are interested in adding adverse weather effects, more specifically fog effects, to images taken in clear weather. To circumvent the challenge of collecting real foggy images, AIT learns with synthetic clear-weather images, synthetic foggy images and real clear-weather images to add fog effects onto real clear-weather images without seeing any real foggy images during training. AIT achieves this zero-shot image translation capability by coupling a supervised training scheme in the synthetic domain, a cycle consistency strategy in the real domain, an adversarial training scheme between the two domains, and a novel network design. Experiments show the effectiveness of our method for zero-short image translation and its benefit for downstream tasks such as semantic foggy scene understanding.
Confidence Calibration for Object Detection and Segmentation
Mar 02, 2022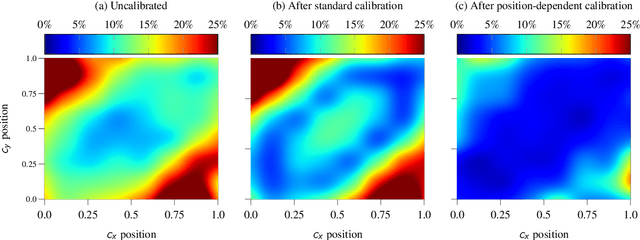
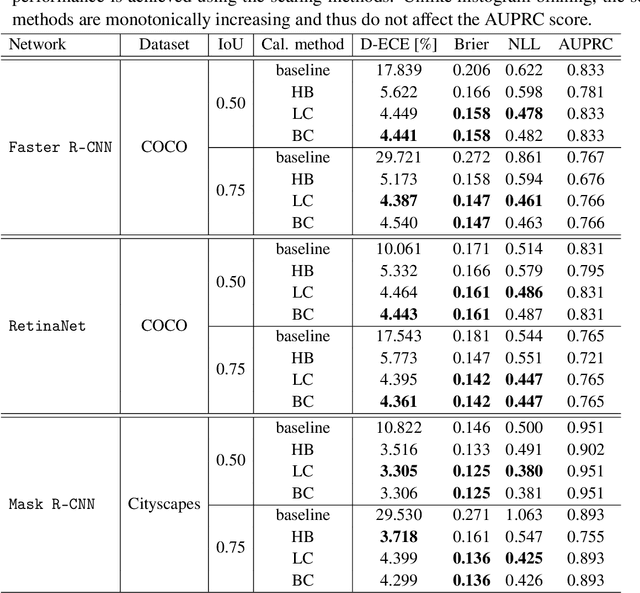
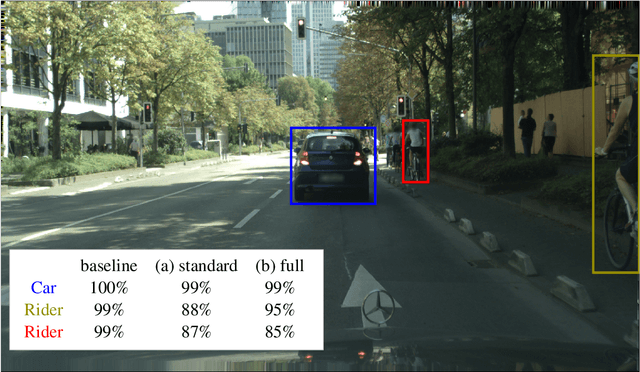
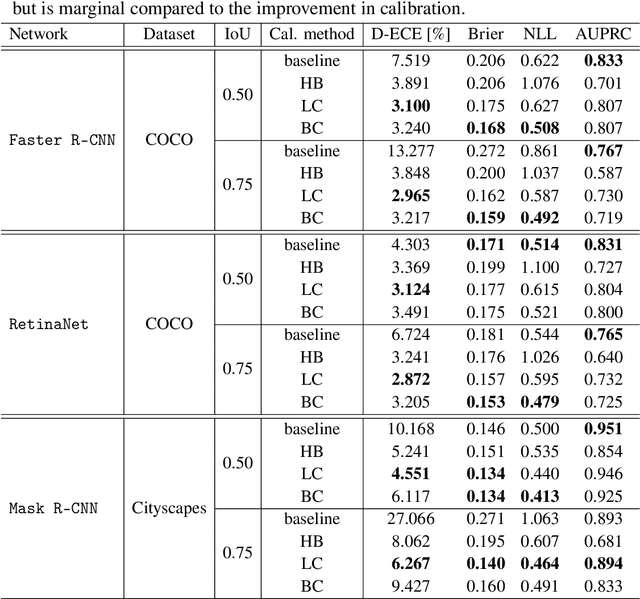
Calibrated confidence estimates obtained from neural networks are crucial, particularly for safety-critical applications such as autonomous driving or medical image diagnosis. However, although the task of confidence calibration has been investigated on classification problems, thorough investigations on object detection and segmentation problems are still missing. Therefore, we focus on the investigation of confidence calibration for object detection and segmentation models in this chapter. We introduce the concept of multivariate confidence calibration that is an extension of well-known calibration methods to the task of object detection and segmentation. This allows for an extended confidence calibration that is also aware of additional features such as bounding box/pixel position, shape information, etc. Furthermore, we extend the expected calibration error (ECE) to measure miscalibration of object detection and segmentation models. We examine several network architectures on MS COCO as well as on Cityscapes and show that especially object detection as well as instance segmentation models are intrinsically miscalibrated given the introduced definition of calibration. Using our proposed calibration methods, we have been able to improve calibration so that it also has a positive impact on the quality of segmentation masks as well.
MSDN: Mutually Semantic Distillation Network for Zero-Shot Learning
Mar 07, 2022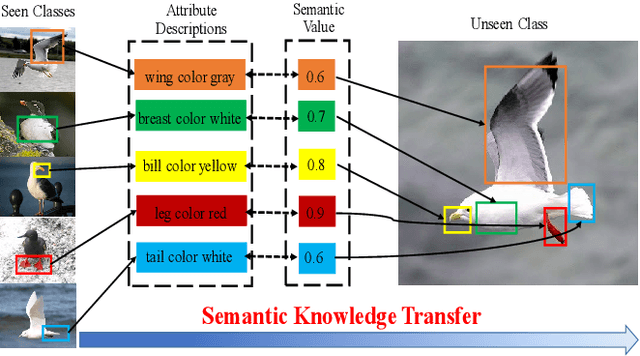
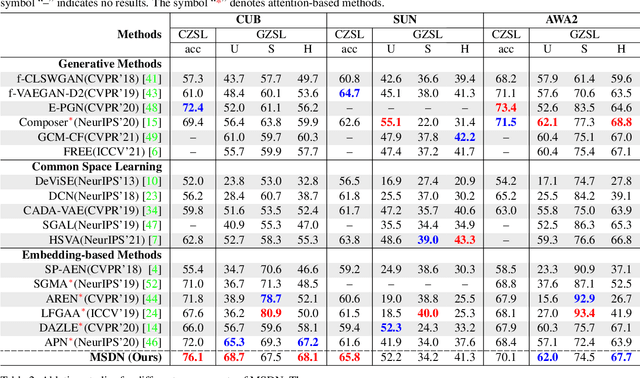

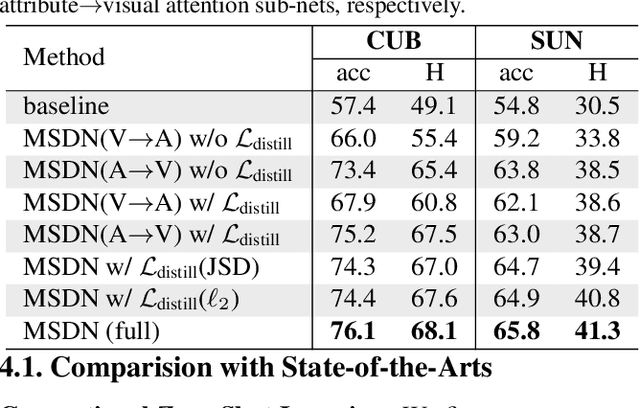
The key challenge of zero-shot learning (ZSL) is how to infer the latent semantic knowledge between visual and attribute features on seen classes, and thus achieving a desirable knowledge transfer to unseen classes. Prior works either simply align the global features of an image with its associated class semantic vector or utilize unidirectional attention to learn the limited latent semantic representations, which could not effectively discover the intrinsic semantic knowledge e.g., attribute semantics) between visual and attribute features. To solve the above dilemma, we propose a Mutually Semantic Distillation Network (MSDN), which progressively distills the intrinsic semantic representations between visual and attribute features for ZSL. MSDN incorporates an attribute$\rightarrow$visual attention sub-net that learns attribute-based visual features, and a visual$\rightarrow$attribute attention sub-net that learns visual-based attribute features. By further introducing a semantic distillation loss, the two mutual attention sub-nets are capable of learning collaboratively and teaching each other throughout the training process. The proposed MSDN yields significant improvements over the strong baselines, leading to new state-of-the-art performances on three popular challenging benchmarks, i.e., CUB, SUN, and AWA2. Our codes have been available at: \url{https://github.com/shiming-chen/MSDN}.
Soft Expectation and Deep Maximization for Image Feature Detection
Apr 21, 2021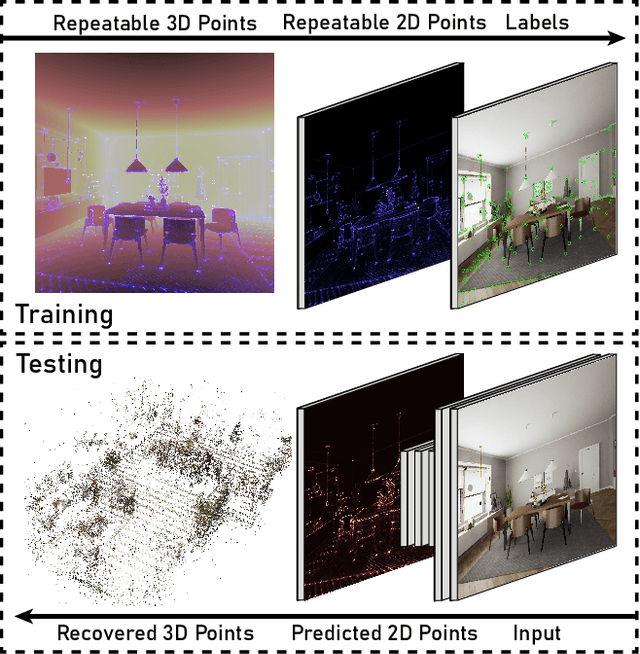
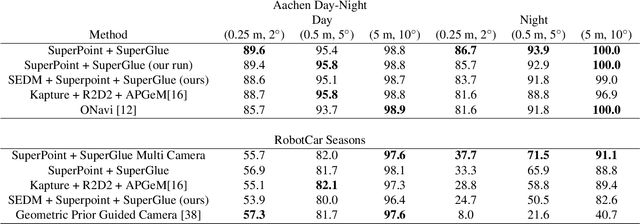
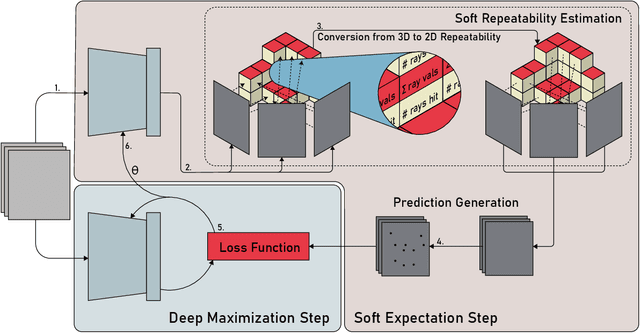
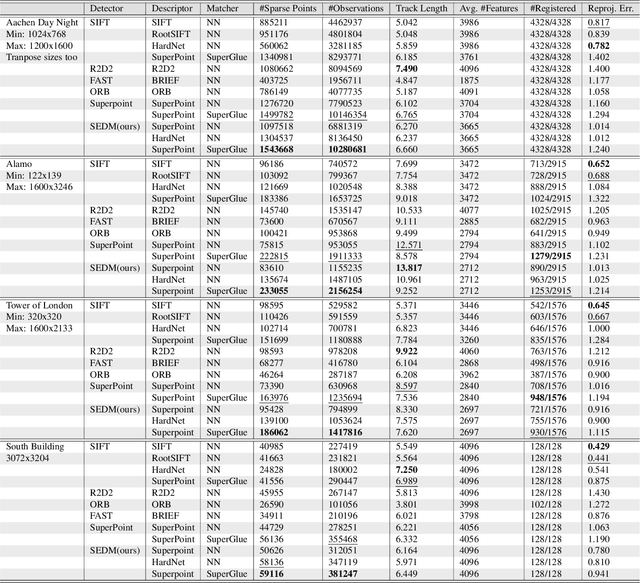
Central to the application of many multi-view geometry algorithms is the extraction of matching points between multiple viewpoints, enabling classical tasks such as camera pose estimation and 3D reconstruction. Over the decades, many approaches that characterize these points have been proposed based on hand-tuned appearance models and more recently data-driven learning methods. We propose SEDM, an iterative semi-supervised learning process that flips the question and first looks for repeatable 3D points, then trains a detector to localize them in image space. Our technique poses the problem as one of expectation maximization (EM), where the likelihood of the detector locating the 3D points is the objective function to be maximized. We utilize the geometry of the scene to refine the estimates of the location of these 3D points and produce a new pseudo ground truth during the expectation step, then train a detector to predict this pseudo ground truth in the maximization step. We apply our detector to standard benchmarks in visual localization, sparse 3D reconstruction, and mean matching accuracy. Our results show that this new model trained using SEDM is able to better localize the underlying 3D points in a scene, improving mean SfM quality by $-0.15\pm0.11$ mean reprojection error when compared to SuperPoint or $-0.38\pm0.23$ when compared to R2D2.