 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalogical Image Translation for Fog Generation
Paper and Code
Jun 28, 2020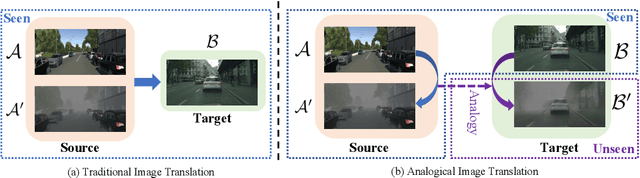
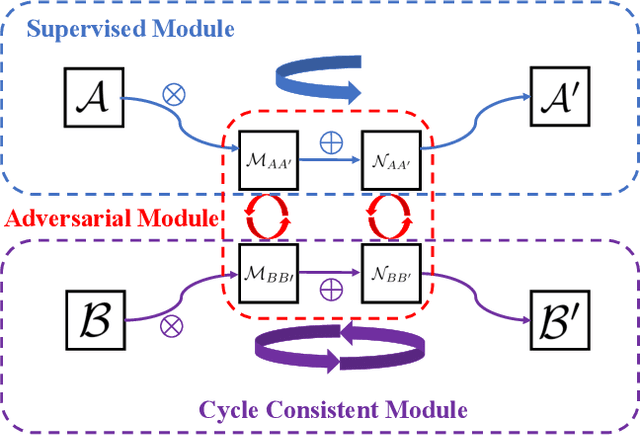
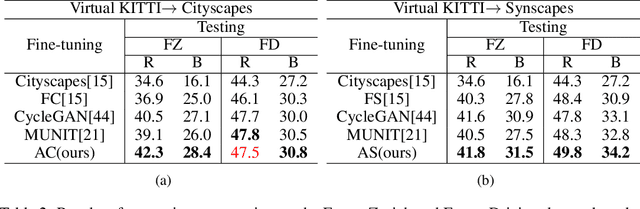

Image-to-image translation is to map images from a given \emph{style} to another given \emph{style}. While exceptionally successful, current methods assume the availability of training images in both source and target domains, which does not always hold in practice. Inspired by humans' reasoning capability of analogy, we propose analogical image translation (AIT). Given images of two styles in the source domain: $\mathcal{A}$ and $\mathcal{A}^\prime$, along with images $\mathcal{B}$ of the first style in the target domain, learn a model to translate $\mathcal{B}$ to $\mathcal{B}^\prime$ in the target domain, such that $\mathcal{A}:\mathcal{A}^\prime ::\mathcal{B}:\mathcal{B}^\prime$. AIT is especially useful for translation scenarios in which training data of one style is hard to obtain but training data of the same two styles in another domain is available. For instance, in the case from normal conditions to extreme, rare conditions, obtaining real training images for the latter case is challenging but obtaining synthetic data for both cases is relatively easy. In this work, we are interested in adding adverse weather effects, more specifically fog effects, to images taken in clear weather. To circumvent the challenge of collecting real foggy images, AIT learns with synthetic clear-weather images, synthetic foggy images and real clear-weather images to add fog effects onto real clear-weather images without seeing any real foggy images during training. AIT achieves this zero-shot image translation capability by coupling a supervised training scheme in the synthetic domain, a cycle consistency strategy in the real domain, an adversarial training scheme between the two domains, and a novel network design. Experiments show the effectiveness of our method for zero-short image translation and its benefit for downstream tasks such as semantic foggy scene understanding.