 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Ultrasound Image Enhancement via Self-Supervised Physics-Guided Degradation Modeling
Jan 29, 2026Ultrasound (US) interpretation is hampered by multiplicative speckle, acquisition blur from the point-spread function (PSF), and scanner- and operator-dependent artifacts. Supervised enhancement methods assume access to clean targets or known degradations; conditions rarely met in practice. We present a blind, self-supervised enhancement framework that jointly deconvolves and denoises B-mode images using a Swin Convolutional U-Net trained with a \emph{physics-guided} degradation model. From each training frame, we extract rotated/cropped patches and synthesize inputs by (i) convolving with a Gaussian PSF surrogate and (ii) injecting noise via either spatial additive Gaussian noise or complex Fourier-domain perturbations that emulate phase/magnitude distortions. For US scans, clean-like targets are obtained via non-local low-rank (NLLR) denoising, removing the need for ground truth; for natural images, the originals serve as targets. Trained and validated on UDIAT~B, JNU-IFM, and XPIE Set-P, and evaluated additionally on a 700-image PSFHS test set, the method achieves the highest PSNR/SSIM across Gaussian and speckle noise levels, with margins that widen under stronger corruption. Relative to MSANN, Restormer, and DnCNN, it typically preserves an extra $\sim$1--4\,dB PSNR and 0.05--0.15 SSIM in heavy Gaussian noise, and $\sim$2--5\,dB PSNR and 0.05--0.20 SSIM under severe speckle. Controlled PSF studies show reduced FWHM and higher peak gradients, evidence of resolution recovery without edge erosion. Used as a plug-and-play preprocessor, it consistently boosts Dice for fetal head and pubic symphysis segmentation. Overall, the approach offers a practical, assumption-light path to robust US enhancement that generalizes across datasets, scanners, and degradation types.
Guidance for Intra-cardiac Echocardiography Manipulation to Maintain Continuous Therapy Device Tip Visibility
May 08, 2025


Intra-cardiac Echocardiography (ICE) plays a critical role in Electrophysiology (EP) and Structural Heart Disease (SHD) interventions by providing real-time visualization of intracardiac structures. However, maintaining continuous visibility of the therapy device tip remains a challenge due to frequent adjustments required during manual ICE catheter manipulation. To address this, we propose an AI-driven tracking model that estimates the device tip incident angle and passing point within the ICE imaging plane, ensuring continuous visibility and facilitating robotic ICE catheter control. A key innovation of our approach is the hybrid dataset generation strategy, which combines clinical ICE sequences with synthetic data augmentation to enhance model robustness. We collected ICE images in a water chamber setup, equipping both the ICE catheter and device tip with electromagnetic (EM) sensors to establish precise ground-truth locations. Synthetic sequences were created by overlaying catheter tips onto real ICE images, preserving motion continuity while simulating diverse anatomical scenarios. The final dataset consists of 5,698 ICE-tip image pairs, ensuring comprehensive training coverage. Our model architecture integrates a pretrained ultrasound (US) foundation model, trained on 37.4M echocardiography images, for feature extraction. A transformer-based network processes sequential ICE frames, leveraging historical passing points and incident angles to improve prediction accuracy. Experimental results demonstrate that our method achieves 3.32 degree entry angle error, 12.76 degree rotation angle error. This AI-driven framework lays the foundation for real-time robotic ICE catheter adjustments, minimizing operator workload while ensuring consistent therapy device visibility. Future work will focus on expanding clinical datasets to further enhance model generalization.
Pose Estimation for Intra-cardiac Echocardiography Catheter via AI-Based Anatomical Understanding
May 07, 2025



Intra-cardiac Echocardiography (ICE) plays a crucial role in Electrophysiology (EP) and Structural Heart Disease (SHD) interventions by providing high-resolution, real-time imaging of cardiac structures. However, existing navigation methods rely on electromagnetic (EM) tracking, which is susceptible to interference and position drift, or require manual adjustments based on operator expertise. To overcome these limitations, we propose a novel anatomy-aware pose estimation system that determines the ICE catheter position and orientation solely from ICE images, eliminating the need for external tracking sensors. Our approach leverages a Vision Transformer (ViT)-based deep learning model, which captures spatial relationships between ICE images and anatomical structures. The model is trained on a clinically acquired dataset of 851 subjects, including ICE images paired with position and orientation labels normalized to the left atrium (LA) mesh. ICE images are patchified into 16x16 embeddings and processed through a transformer network, where a [CLS] token independently predicts position and orientation via separate linear layers. The model is optimized using a Mean Squared Error (MSE) loss function, balancing positional and orientational accuracy. Experimental results demonstrate an average positional error of 9.48 mm and orientation errors of (16.13 deg, 8.98 deg, 10.47 deg) across x, y, and z axes, confirming the model accuracy. Qualitative assessments further validate alignment between predicted and target views within 3D cardiac meshes. This AI-driven system enhances procedural efficiency, reduces operator workload, and enables real-time ICE catheter localization for tracking-free procedures. The proposed method can function independently or complement existing mapping systems like CARTO, offering a transformative approach to ICE-guided interventions.
AI-driven View Guidance System in Intra-cardiac Echocardiography Imaging
Sep 26, 2024



Intra-cardiac Echocardiography (ICE) is a crucial imaging modality used in electrophysiology (EP) and structural heart disease (SHD) interventions, providing real-time, high-resolution views from within the heart. Despite its advantages, effective manipulation of the ICE catheter requires significant expertise, which can lead to inconsistent outcomes, particularly among less experienced operators. To address this challenge, we propose an AI-driven closed-loop view guidance system with human-in-the-loop feedback, designed to assist users in navigating ICE imaging without requiring specialized knowledge. Our method models the relative position and orientation vectors between arbitrary views and clinically defined ICE views in a spatial coordinate system, guiding users on how to manipulate the ICE catheter to transition from the current view to the desired view over time. Operating in a closed-loop configuration, the system continuously predicts and updates the necessary catheter manipulations, ensuring seamless integration into existing clinical workflows. The effectiveness of the proposed system is demonstrated through a simulation-based evaluation, achieving an 89% success rate with the 6532 test dataset, highlighting its potential to improve the accuracy and efficiency of ICE imaging procedures.
Breast Ultrasound Report Generation using LangChain
Dec 05, 2023



Breast ultrasound (BUS) is a critical diagnostic tool in the field of breast imaging, aiding in the early detection and characterization of breast abnormalities. Interpreting breast ultrasound images commonly involves creating comprehensive medical reports, containing vital information to promptly assess the patient's condition. However, the ultrasound imaging system necessitates capturing multiple images of various parts to compile a single report, presenting a time-consuming challenge. To address this problem, we propose the integration of multiple image analysis tools through a LangChain using Large Language Models (LLM), into the breast reporting process. Through a combination of designated tools and text generation through LangChain, our method can accurately extract relevant features from ultrasound images, interpret them in a clinical context, and produce comprehensive and standardized reports. This approach not only reduces the burden on radiologists and healthcare professionals but also enhances the consistency and quality of reports. The extensive experiments shows that each tools involved in the proposed method can offer qualitatively and quantitatively significant results. Furthermore, clinical evaluation on the generated reports demonstrates that the proposed method can make report in clinically meaningful way.
Improving Medical Speech-to-Text Accuracy with Vision-Language Pre-training Model
Feb 27, 2023



Automatic Speech Recognition (ASR) is a technology that converts spoken words into text, facilitating interaction between humans and machines. One of the most common applications of ASR is Speech-To-Text (STT) technology, which simplifies user workflows by transcribing spoken words into text. In the medical field, STT has the potential to significantly reduce the workload of clinicians who rely on typists to transcribe their voice recordings. However, developing an STT model for the medical domain is challenging due to the lack of sufficient speech and text datasets. To address this issue, we propose a medical-domain text correction method that modifies the output text of a general STT system using the Vision Language Pre-training (VLP) method. VLP combines textual and visual information to correct text based on image knowledge. Our extensive experiments demonstrate that the proposed method offers quantitatively and clinically significant improvements in STT performance in the medical field. We further show that multi-modal understanding of image and text information outperforms single-modal understanding using only text information.
Phase Aberration Robust Beamformer for Planewave US Using Self-Supervised Learning
Feb 16, 2022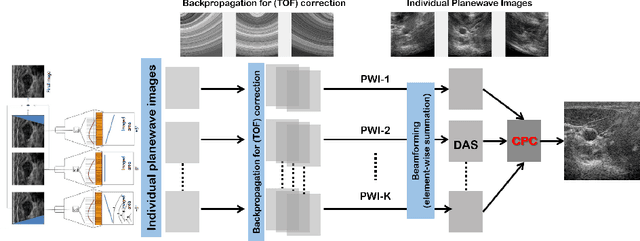
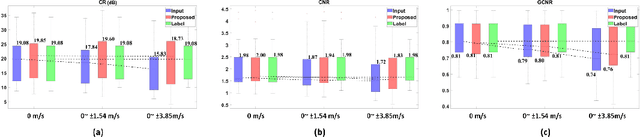
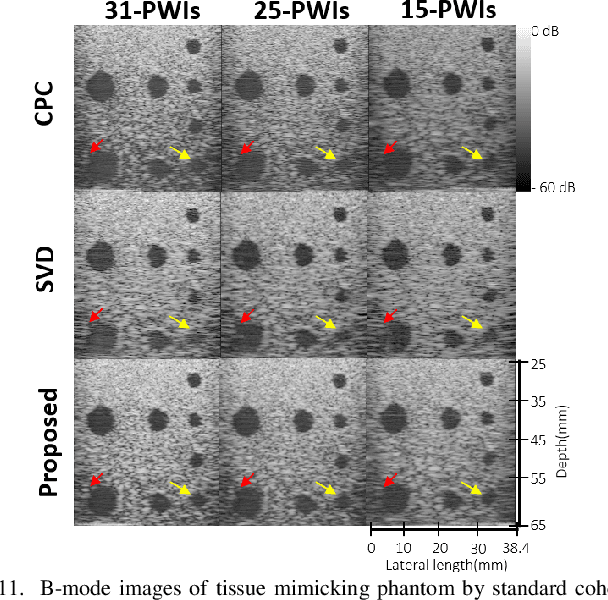
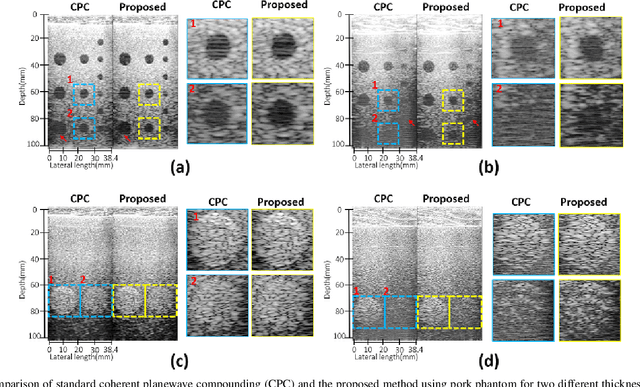
Ultrasound (US) is widely used for clinical imaging applications thanks to its real-time and non-invasive nature. However, its lesion detectability is often limited in many applications due to the phase aberration artefact caused by variations in the speed of sound (SoS) within body parts. To address this, here we propose a novel self-supervised 3D CNN that enables phase aberration robust plane-wave imaging. Instead of aiming at estimating the SoS distribution as in conventional methods, our approach is unique in that the network is trained in a self-supervised manner to robustly generate a high-quality image from various phase aberrated images by modeling the variation in the speed of sound as stochastic. Experimental results using real measurements from tissue-mimicking phantom and \textit{in vivo} scans confirmed that the proposed method can significantly reduce the phase aberration artifacts and improve the visual quality of deep scans.
Tunable Image Quality Control of 3-D Ultrasound using Switchable CycleGAN
Dec 06, 2021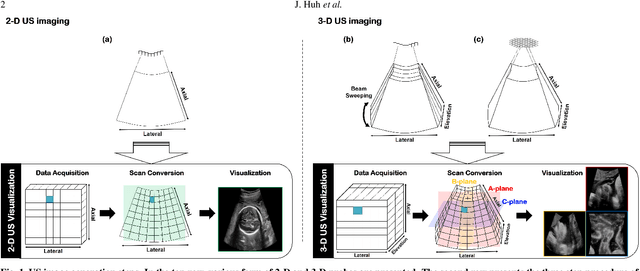
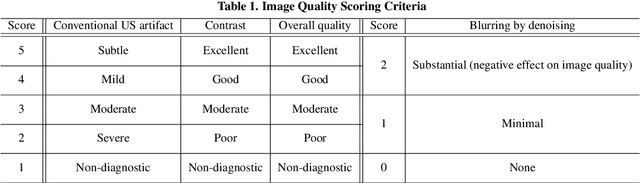
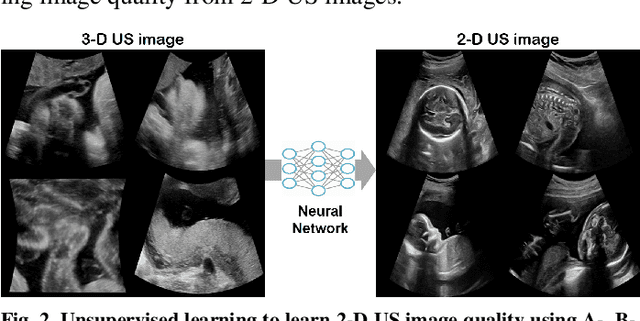
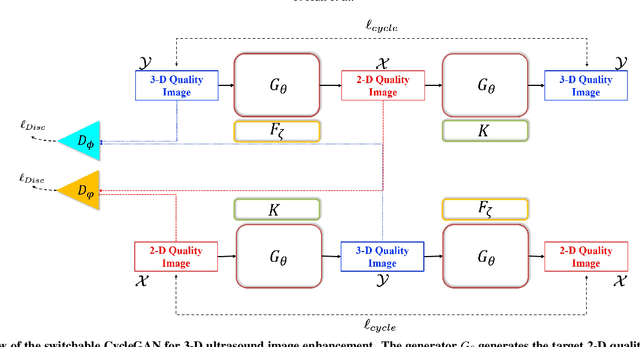
In contrast to 2-D ultrasound (US) for uniaxial plane imaging, a 3-D US imaging system can visualize a volume along three axial planes. This allows for a full view of the anatomy, which is useful for gynecological (GYN) and obstetrical (OB) applications. Unfortunately, the 3-D US has an inherent limitation in resolution compared to the 2-D US. In the case of 3-D US with a 3-D mechanical probe, for example, the image quality is comparable along the beam direction, but significant deterioration in image quality is often observed in the other two axial image planes. To address this, here we propose a novel unsupervised deep learning approach to improve 3-D US image quality. In particular, using {\em unmatched} high-quality 2-D US images as a reference, we trained a recently proposed switchable CycleGAN architecture so that every mapping plane in 3-D US can learn the image quality of 2-D US images. Thanks to the switchable architecture, our network can also provide real-time control of image enhancement level based on user preference, which is ideal for a user-centric scanner setup. Extensive experiments with clinical evaluation confirm that our method offers significantly improved image quality as well user-friendly flexibility.
Unsupervised Missing Cone Deep Learning in Optical Diffraction Tomography
Mar 16, 2021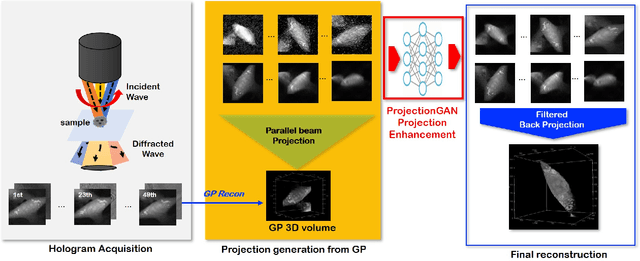
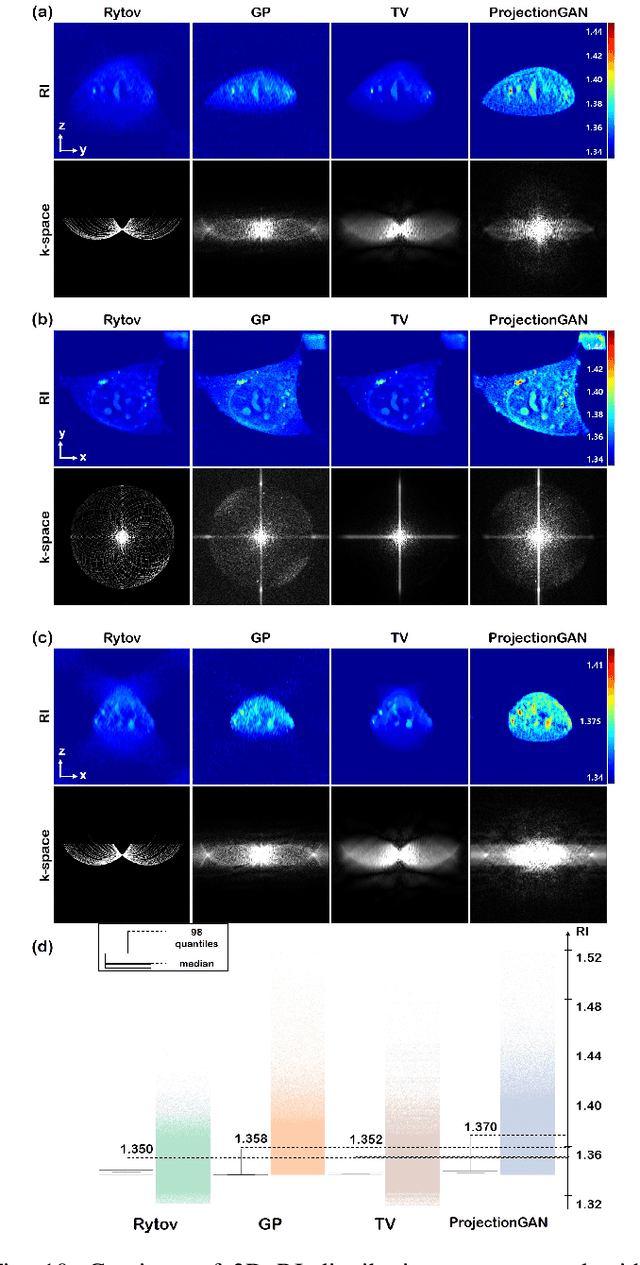
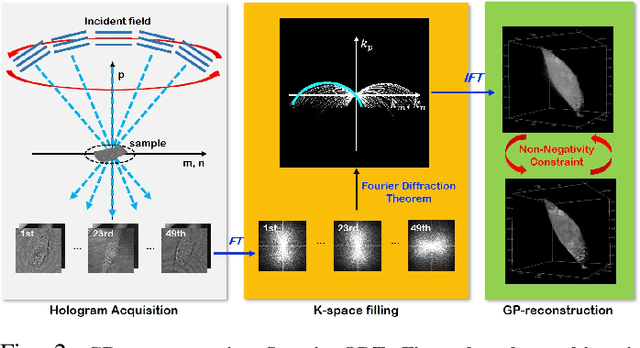

Optical diffraction tomography (ODT) produces three dimensional distribution of refractive index (RI) by measuring scattering fields at various angles. Although the distribution of RI index is highly informative, due to the missing cone problem stemming from the limited-angle acquisition of holograms, reconstructions have very poor resolution along axial direction compared to the horizontal imaging plane. To solve this issue, here we present a novel unsupervised deep learning framework, which learns the probability distribution of missing projection views through optimal transport driven cycleGAN. Experimental results show that missing cone artifact in ODT can be significantly resolved by the proposed method.
Switchable Deep Beamformer
Sep 04, 2020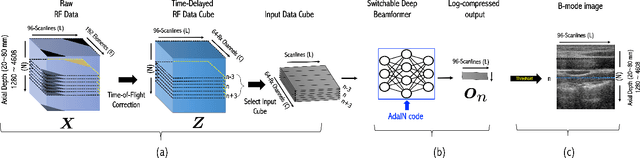
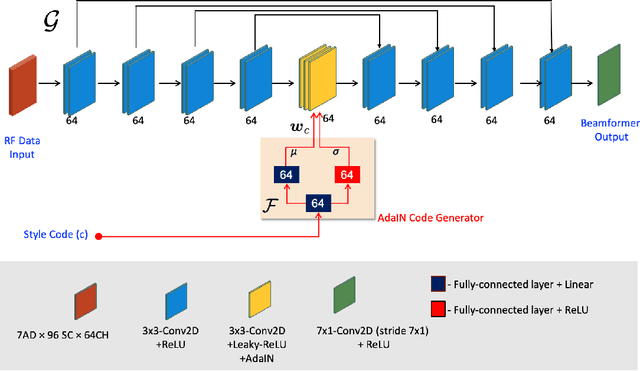

Recent proposals of deep beamformers using deep neural networks have attracted significant attention as computational efficient alternatives to adaptive and compressive beamformers. Moreover, deep beamformers are versatile in that image post-processing algorithms can be combined with the beamforming. Unfortunately, in the current technology, a separate beamformer should be trained and stored for each application, demanding significant scanner resources. To address this problem, here we propose a {\em switchable} deep beamformer that can produce various types of output such as DAS, speckle removal, deconvolution, etc., using a single network with a simple switch. In particular, the switch is implemented through Adaptive Instance Normalization (AdaIN) layers, so that various output can be generated by merely changing the AdaIN code. Experimental results using B-mode focused ultrasound confirm the flexibility and efficacy of the proposed methods for various applications.