 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MIST GAN: Modality Imputation Using Style Transfer for MRI
Feb 21, 2022
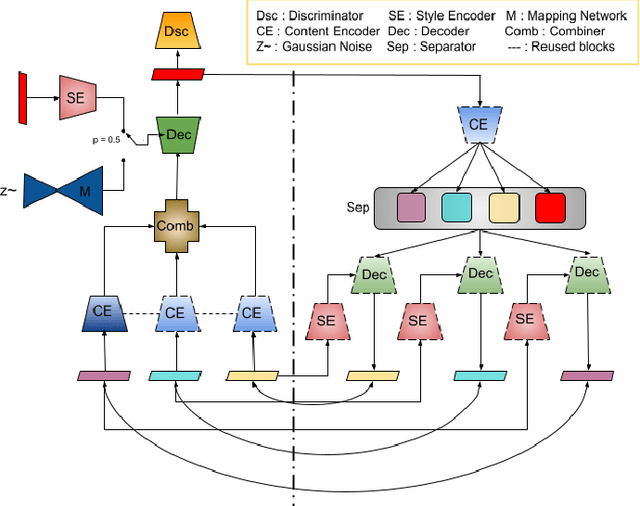
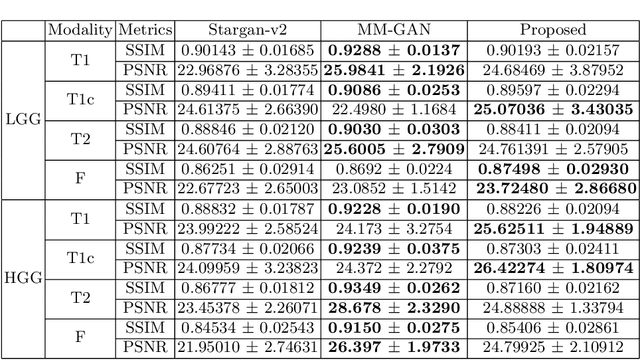
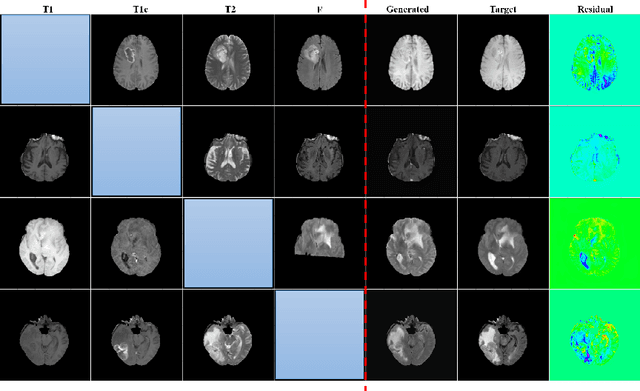
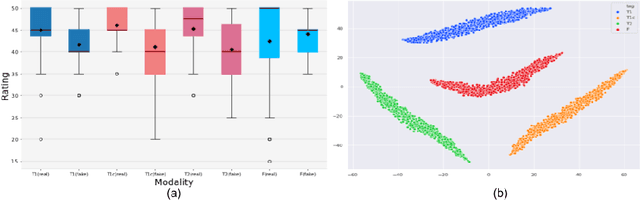
MRI entails a great amount of cost, time and effort for the generation of all the modalities that are recommended for efficient diagnosis and treatment planning. Recent advancements in deep learning research show that generative models have achieved substantial improvement in the aspects of style transfer and image synthesis. In this work, we formulate generating the missing MR modality from existing MR modalities as an imputation problem using style transfer. With a multiple-to-one mapping, we model a network that accommodates domain specific styles in generating the target image. We analyse the style diversity both within and across MR modalities. Our model is tested on the BraTS'18 dataset and the results obtained are observed to be on par with the state-of-the-art in terms of visual metrics, SSIM and PSNR. After being evaluated by two expert radiologists, we show that our model is efficient, extendable, and suitable for clinical applications.
Causal Contextual Prediction for Learned Image Compression
Dec 21, 2020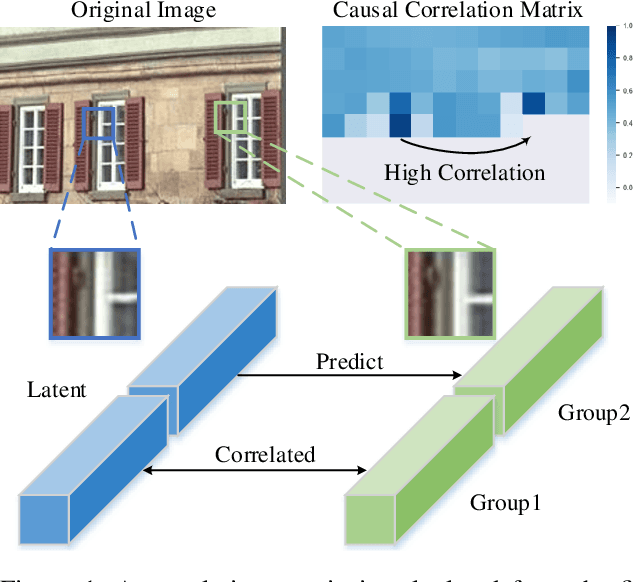
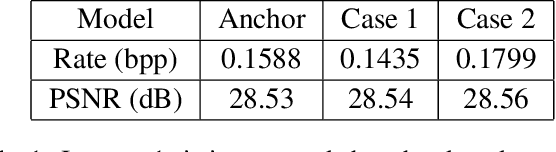
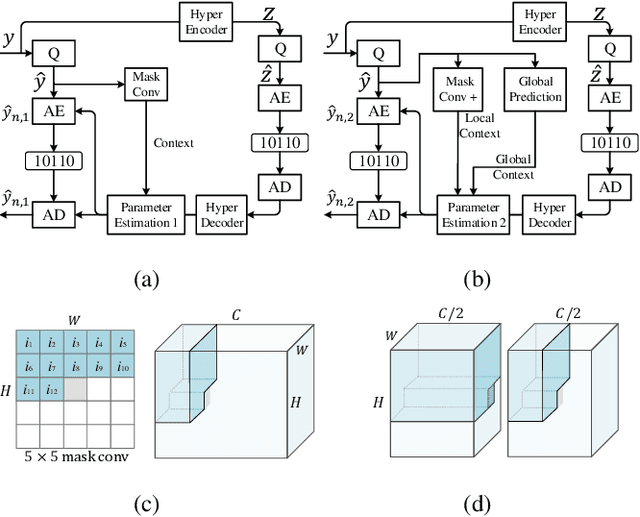

Over the past several years, we have witnessed impressive progress in the field of learned image compression. Recent learned image codecs are commonly based on autoencoders, that first encode an image into low-dimensional latent representations and then decode them for reconstruction purposes. To capture spatial dependencies in the latent space, prior works exploit hyperprior and spatial context model to build an entropy model, which estimates the bit-rate for end-to-end rate-distortion optimization. However, such an entropy model is suboptimal from two aspects: (1) It fails to capture spatially global correlations among the latents. (2) Cross-channel relationships of the latents are still underexplored. In this paper, we propose the concept of separate entropy coding to leverage a serial decoding process for causal contextual entropy prediction in the latent space. A causal context model is proposed that separates the latents across channels and makes use of cross-channel relationships to generate highly informative contexts. Furthermore, we propose a causal global prediction model, which is able to find global reference points for accurate predictions of unknown points. Both these two models facilitate entropy estimation without the transmission of overhead. In addition, we further adopt a new separate attention module to build more powerful transform networks. Experimental results demonstrate that our full image compression model outperforms standard VVC/H.266 codec on Kodak dataset in terms of both PSNR and MS-SSIM, yielding the state-of-the-art rate-distortion performance. Our test code is available at http://staff.ustc.edu.cn/~chenzhibo/resources/2020/ccp4lic.html.
A Practical Blockchain Framework using Image Hashing for Image Authentication
Apr 15, 2020
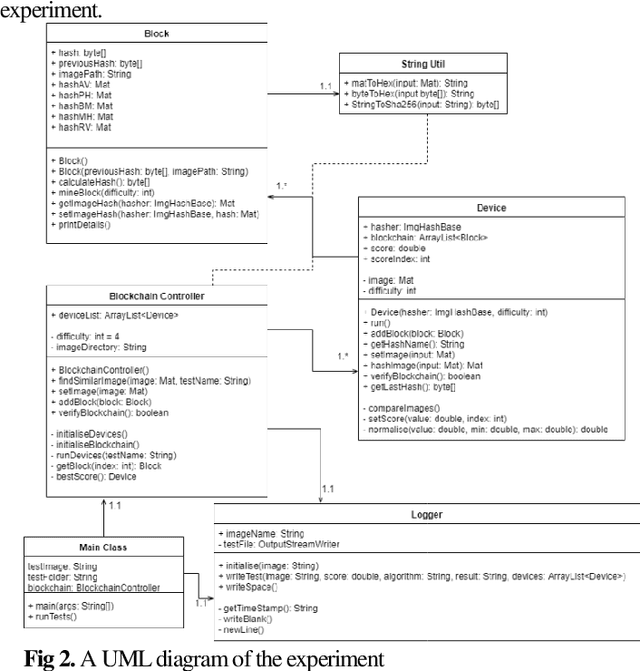
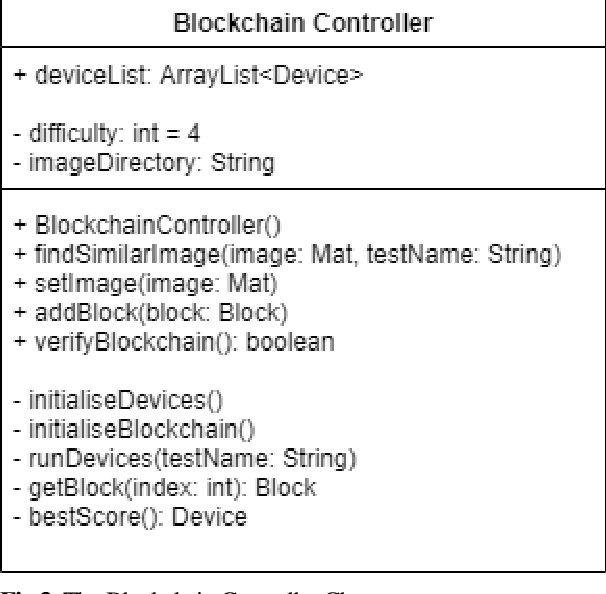
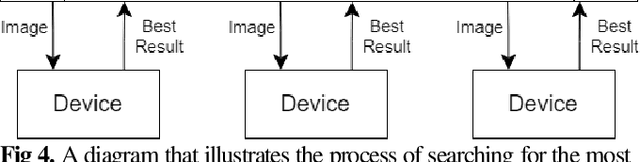
Blockchain is a relatively new technology that can be seen as a decentralised database. Blockchain systems heavily rely on cryptographic hash functions to store their data, which makes it difficult to tamper with any data stored in the system. A topic that was researched along with blockchain is image authentication. Image authentication focuses on investigating and maintaining the integrity of images. As a blockchain system can be useful for maintaining data integrity, image authentication has the potential to be enhanced by blockchain. There are many techniques that can be used to authenticate images; the technique investigated by this work is image hashing. Image hashing is a technique used to calculate how similar two different images are. This is done by converting the images into hashes and then comparing them using a distance formula. To investigate the topic, an experiment involving a simulated blockchain was created. The blockchain acted as a database for images. This blockchain was made up of devices which contained their own unique image hashing algorithms. The blockchain was tested by creating modified copies of the images contained in the database, and then submitting them to the blockchain to see if it will return the original image. Through this experiment it was discovered that it is plausible to create an image authentication system using blockchain and image hashing. However, the design proposed by this work requires refinement, as it appears to struggle in some situations. This work shows that blockchain can be a suitable approach for authenticating images, particularly via image hashing. Other observations include that using multiple image hash algorithms at the same time can increase performance in some cases, as well as that each type of test done to the blockchain has its own unique pattern to its data.
Revealing unforeseen diagnostic image features with deep learning by detecting cardiovascular diseases from apical four-chamber ultrasounds
Oct 25, 2021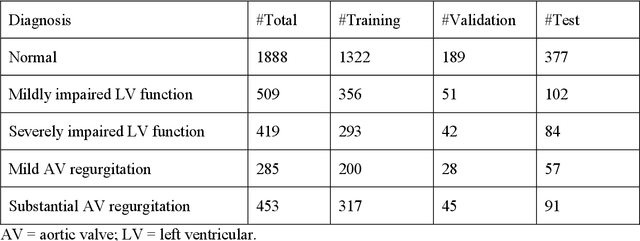
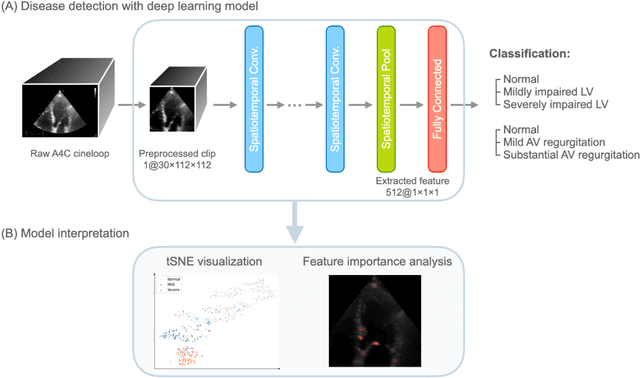
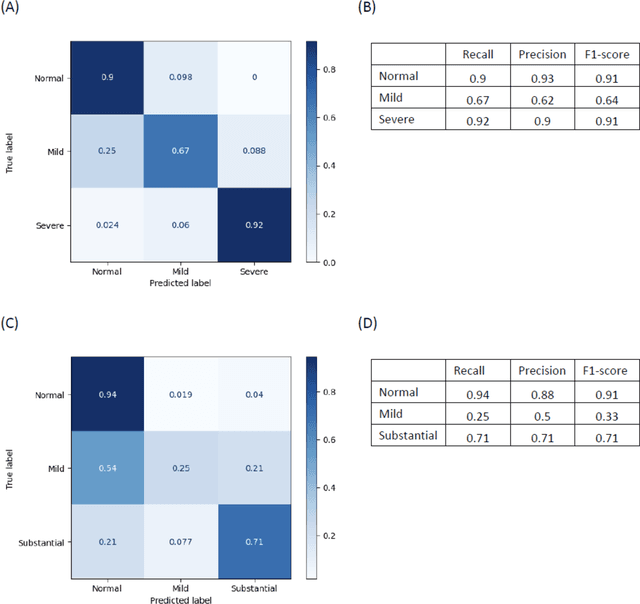
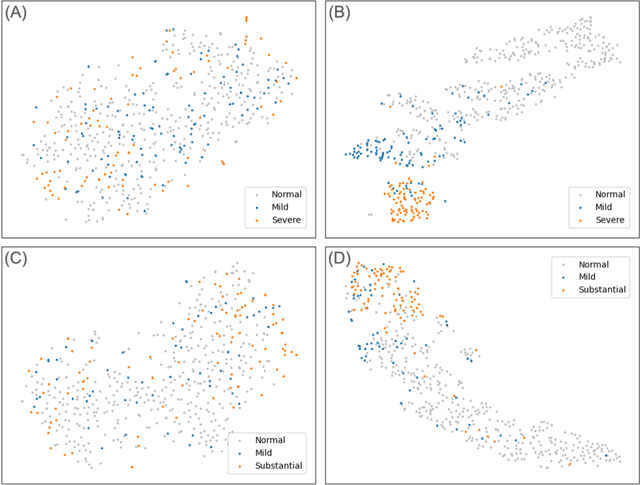
Background. With the rise of highly portable, wireless, and low-cost ultrasound devices and automatic ultrasound acquisition techniques, an automated interpretation method requiring only a limited set of views as input could make preliminary cardiovascular disease diagnoses more accessible. In this study, we developed a deep learning (DL) method for automated detection of impaired left ventricular (LV) function and aortic valve (AV) regurgitation from apical four-chamber (A4C) ultrasound cineloops and investigated which anatomical structures or temporal frames provided the most relevant information for the DL model to enable disease classification. Methods and Results. A4C ultrasounds were extracted from 3,554 echocardiograms of patients with either impaired LV function (n=928), AV regurgitation (n=738), or no significant abnormalities (n=1,888). Two convolutional neural networks (CNNs) were trained separately to classify the respective disease cases against normal cases. The overall classification accuracy of the impaired LV function detection model was 86%, and that of the AV regurgitation detection model was 83%. Feature importance analyses demonstrated that the LV myocardium and mitral valve were important for detecting impaired LV function, while the tip of the mitral valve anterior leaflet, during opening, was considered important for detecting AV regurgitation. Conclusion. The proposed method demonstrated the feasibility of a 3D CNN approach in detection of impaired LV function and AV regurgitation using A4C ultrasound cineloops. The current research shows that DL methods can exploit large training data to detect diseases in a different way than conventionally agreed upon methods, and potentially reveal unforeseen diagnostic image features.
Cloth-Changing Person Re-identification from A Single Image with Gait Prediction and Regularization
Mar 29, 2021
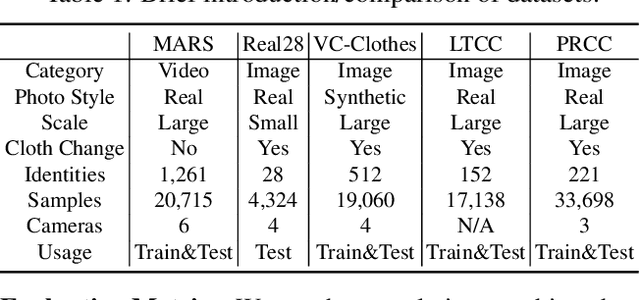
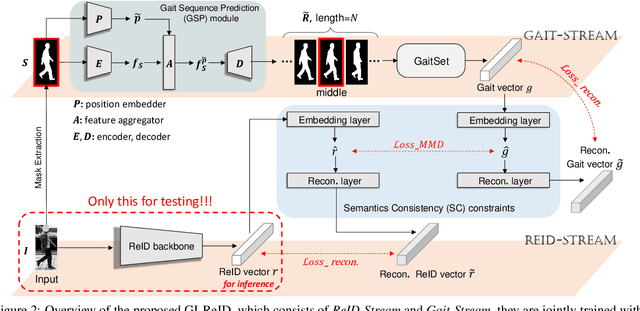
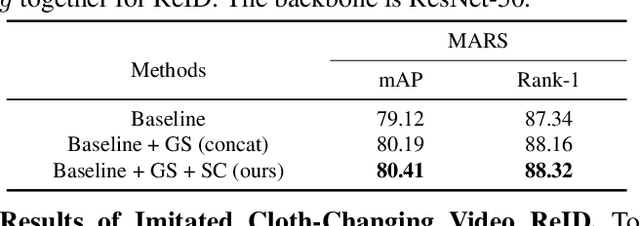
Cloth-Changing person re-identification (CC-ReID) aims at matching the same person across different locations over a long-duration, e.g., over days, and therefore inevitably meets challenge of changing clothing. In this paper, we focus on handling well the CC-ReID problem under a more challenging setting, i.e., just from a single image, which enables high-efficiency and latency-free pedestrian identify for real-time surveillance applications. Specifically, we introduce Gait recognition as an auxiliary task to drive the Image ReID model to learn cloth-agnostic representations by leveraging personal unique and cloth-independent gait information, we name this framework as GI-ReID. GI-ReID adopts a two-stream architecture that consists of a image ReID-Stream and an auxiliary gait recognition stream (Gait-Stream). The Gait-Stream, that is discarded in the inference for high computational efficiency, acts as a regulator to encourage the ReID-Stream to capture cloth-invariant biometric motion features during the training. To get temporal continuous motion cues from a single image, we design a Gait Sequence Prediction (GSP) module for Gait-Stream to enrich gait information. Finally, a high-level semantics consistency over two streams is enforced for effective knowledge regularization. Experiments on multiple image-based Cloth-Changing ReID benchmarks, e.g., LTCC, PRCC, Real28, and VC-Clothes, demonstrate that GI-ReID performs favorably against the state-of-the-arts. Codes are available at https://github.com/jinx-USTC/GI-ReID.
Self-Supervised Nonlinear Transform-Based Tensor Nuclear Norm for Multi-Dimensional Image Recovery
May 29, 2021
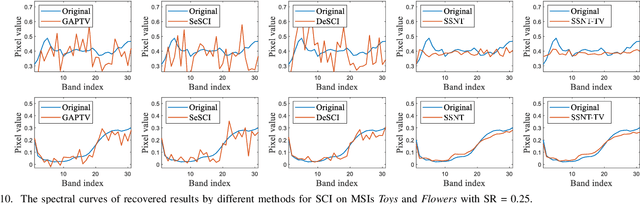

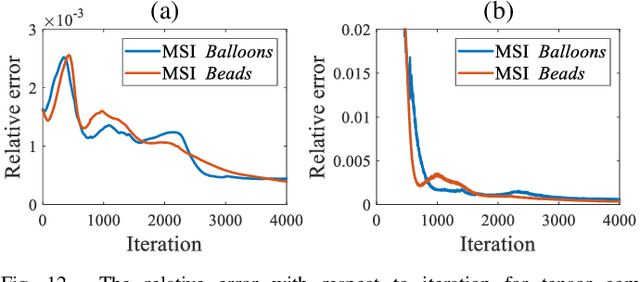
In this paper, we study multi-dimensional image recovery. Recently, transform-based tensor nuclear norm minimization methods are considered to capture low-rank tensor structures to recover third-order tensors in multi-dimensional image processing applications. The main characteristic of such methods is to perform the linear transform along the third mode of third-order tensors, and then compute tensor nuclear norm minimization on the transformed tensor so that the underlying low-rank tensors can be recovered. The main aim of this paper is to propose a nonlinear multilayer neural network to learn a nonlinear transform via the observed tensor data under self-supervision. The proposed network makes use of low-rank representation of transformed tensors and data-fitting between the observed tensor and the reconstructed tensor to construct the nonlinear transformation. Extensive experimental results on tensor completion, background subtraction, robust tensor completion, and snapshot compressive imaging are presented to demonstrate that the performance of the proposed method is better than that of state-of-the-art methods.
CMF: Cascaded Multi-model Fusion for Referring Image Segmentation
Jun 16, 2021
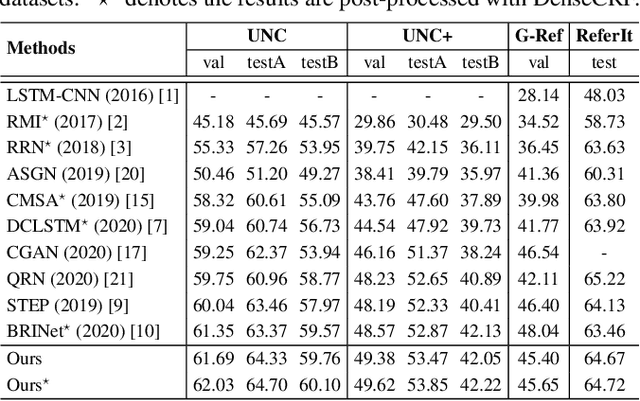
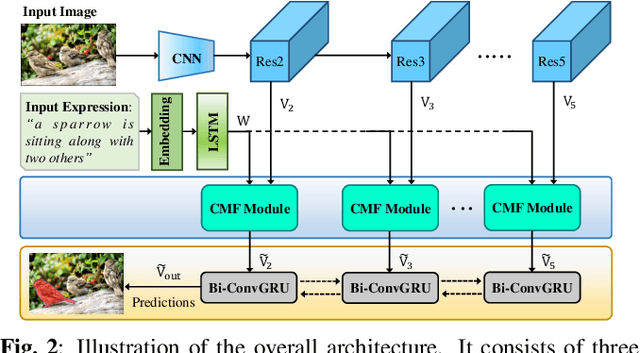
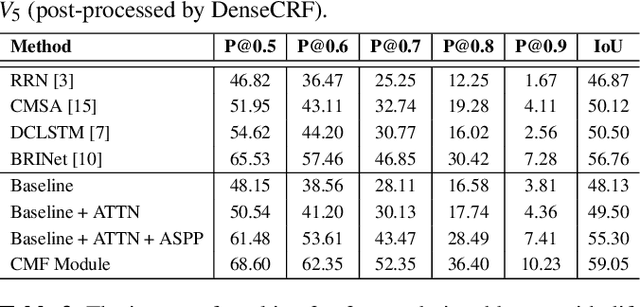
In this work, we address the task of referring image segmentation (RIS), which aims at predicting a segmentation mask for the object described by a natural language expression. Most existing methods focus on establishing unidirectional or directional relationships between visual and linguistic features to associate two modalities together, while the multi-scale context is ignored or insufficiently modeled. Multi-scale context is crucial to localize and segment those objects that have large scale variations during the multi-modal fusion process. To solve this problem, we propose a simple yet effective Cascaded Multi-modal Fusion (CMF) module, which stacks multiple atrous convolutional layers in parallel and further introduces a cascaded branch to fuse visual and linguistic features. The cascaded branch can progressively integrate multi-scale contextual information and facilitate the alignment of two modalities during the multi-modal fusion process. Experimental results on four benchmark datasets demonstrate that our method outperforms most state-of-the-art methods. Code is available at https://github.com/jianhua2022/CMF-Refseg.
WideCaps: A Wide Attention based Capsule Network for Image Classification
Aug 08, 2021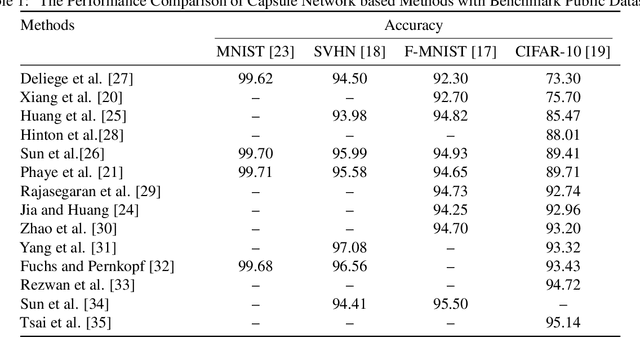
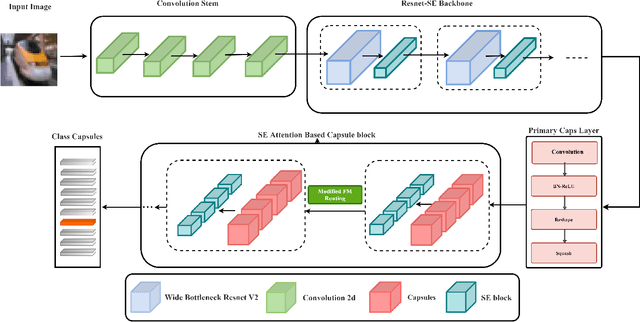
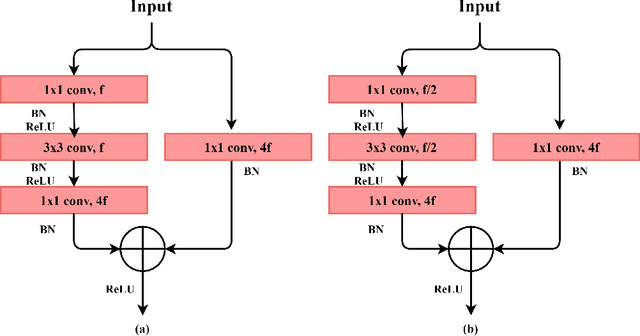

The capsule network is a distinct and promising segment of the neural network family that drew attention due to its unique ability to maintain the equivariance property by preserving the spatial relationship amongst the features. The capsule network has attained unprecedented success over image classification tasks with datasets such as MNIST and affNIST by encoding the characteristic features into the capsules and building the parse-tree structure. However, on the datasets involving complex foreground and background regions such as CIFAR-10, the performance of the capsule network is sub-optimal due to its naive data routing policy and incompetence towards extracting complex features. This paper proposes a new design strategy for capsule network architecture for efficiently dealing with complex images. The proposed method incorporates wide bottleneck residual modules and the Squeeze and Excitation attention blocks upheld by the modified FM routing algorithm to address the defined problem. A wide bottleneck residual module facilitates extracting complex features followed by the squeeze and excitation attention block to enable channel-wise attention by suppressing the trivial features. This setup allows channel inter-dependencies at almost no computational cost, thereby enhancing the representation ability of capsules on complex images. We extensively evaluate the performance of the proposed model on three publicly available datasets, namely CIFAR-10, Fashion MNIST, and SVHN, to outperform the top-5 performance on CIFAR-10 and Fashion MNIST with highly competitive performance on the SVHN dataset.
A Novel Triplet Sampling Method for Multi-Label Remote Sensing Image Search and Retrieval
May 08, 2021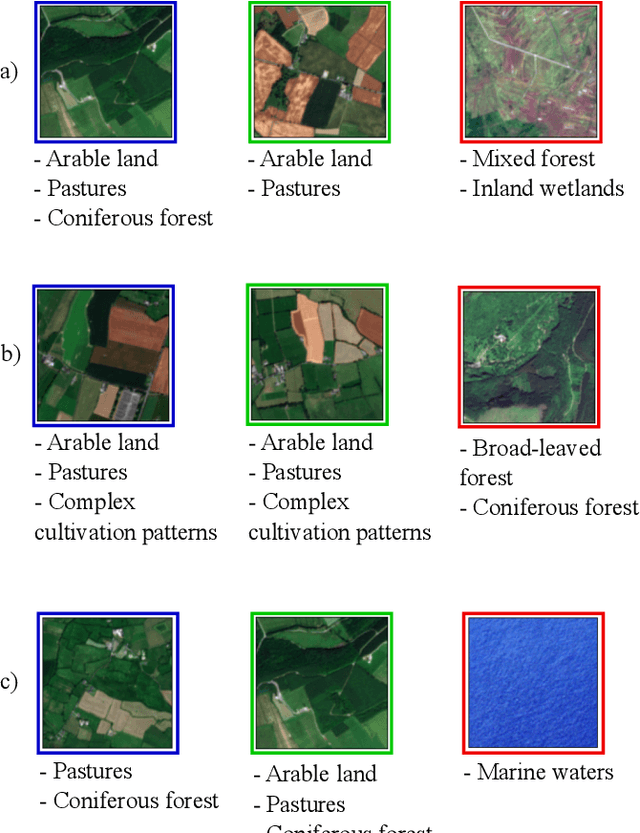
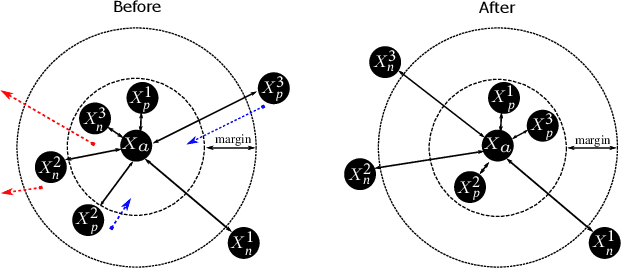
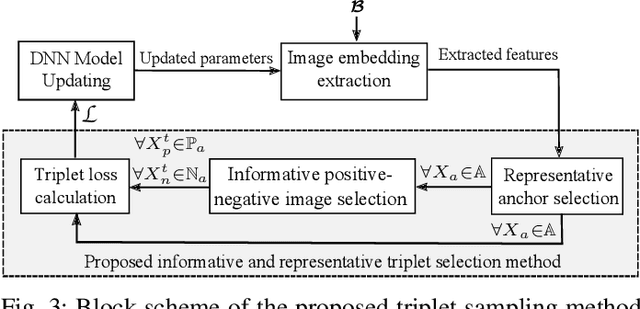

Learning the similarity between remote sensing (RS) images forms the foundation for content based RS image retrieval (CBIR). Recently, deep metric learning approaches that map the semantic similarity of images into an embedding space have been found very popular in RS. A common approach for learning the metric space relies on the selection of triplets of similar (positive) and dissimilar (negative) images to a reference image called as an anchor. Choosing triplets is a difficult task particularly for multi-label RS CBIR, where each training image is annotated by multiple class labels. To address this problem, in this paper we propose a novel triplet sampling method in the framework of deep neural networks (DNNs) defined for multi-label RS CBIR problems. The proposed method selects a small set of the most representative and informative triplets based on two main steps. In the first step, a set of anchors that are diverse to each other in the embedding space is selected from the current mini-batch using an iterative algorithm. In the second step, different sets of positive and negative images are chosen for each anchor by evaluating relevancy, hardness, and diversity of the images among each other based on a novel ranking strategy. Experimental results obtained on two multi-label benchmark achieves show that the selection of the most informative and representative triplets in the context of DNNs results in: i) reducing the computational complexity of the training phase of the DNNs without any significant loss on the performance; and ii) an increase in learning speed since informative triplets allow fast convergence. The code of the proposed method is publicly available at https://git.tu-berlin.de/rsim/image-retrieval-from-triplets.
Image-to-image Mapping with Many Domains by Sparse Attribute Transfer
Jun 23, 2020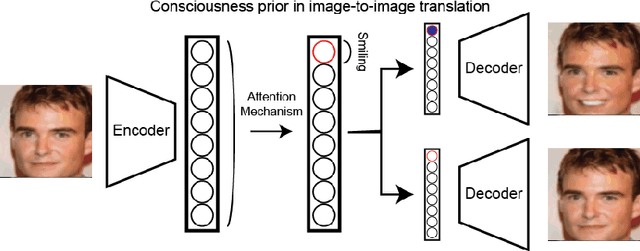
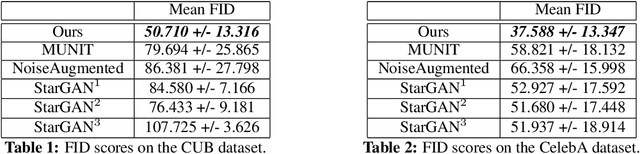
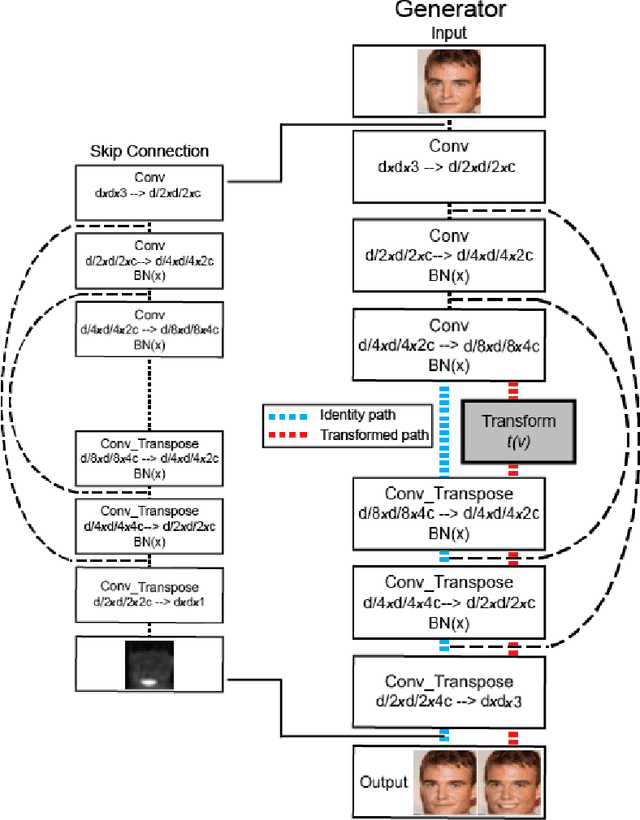

Unsupervised image-to-image translation consists of learning a pair of mappings between two domains without known pairwise correspondences between points. The current convention is to approach this task with cycle-consistent GANs: using a discriminator to encourage the generator to change the image to match the target domain, while training the generator to be inverted with another mapping. While ending up with paired inverse functions may be a good end result, enforcing this restriction at all times during training can be a hindrance to effective modeling. We propose an alternate approach that directly restricts the generator to performing a simple sparse transformation in a latent layer, motivated by recent work from cognitive neuroscience suggesting an architectural prior on representations corresponding to consciousness. Our biologically motivated approach leads to representations more amenable to transformation by disentangling high-level abstract concepts in the latent space. We demonstrate that image-to-image domain translation with many different domains can be learned more effectively with our architecturally constrained, simple transformation than with previous unconstrained architectures that rely on a cycle-consistency loss.