 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sparse-Attention Deep Learning Model Integrating Heterogeneous Multimodal Features for Parkinson's Disease Severity Profiling
Jan 02, 2026Characterising the heterogeneous presentation of Parkinson's disease (PD) requires integrating biological and clinical markers within a unified predictive framework. While multimodal data provide complementary information, many existing computational models struggle with interpretability, class imbalance, or effective fusion of high-dimensional imaging and tabular clinical features. To address these limitations, we propose the Class-Weighted Sparse-Attention Fusion Network (SAFN), an interpretable deep learning framework for robust multimodal profiling. SAFN integrates MRI cortical thickness, MRI volumetric measures, clinical assessments, and demographic variables using modality-specific encoders and a symmetric cross-attention mechanism that captures nonlinear interactions between imaging and clinical representations. A sparsity-constrained attention-gating fusion layer dynamically prioritises informative modalities, while a class-balanced focal loss (beta = 0.999, gamma = 1.5) mitigates dataset imbalance without synthetic oversampling. Evaluated on 703 participants (570 PD, 133 healthy controls) from the Parkinson's Progression Markers Initiative using subject-wise five-fold cross-validation, SAFN achieves an accuracy of 0.98 plus or minus 0.02 and a PR-AUC of 1.00 plus or minus 0.00, outperforming established machine learning and deep learning baselines. Interpretability analysis shows a clinically coherent decision process, with approximately 60 percent of predictive weight assigned to clinical assessments, consistent with Movement Disorder Society diagnostic principles. SAFN provides a reproducible and transparent multimodal modelling paradigm for computational profiling of neurodegenerative disease.
A Novel Image Similarity Metric for Scene Composition Structure
Aug 07, 2025The rapid advancement of generative AI models necessitates novel methods for evaluating image quality that extend beyond human perception. A critical concern for these models is the preservation of an image's underlying Scene Composition Structure (SCS), which defines the geometric relationships among objects and the background, their relative positions, sizes, orientations, etc. Maintaining SCS integrity is paramount for ensuring faithful and structurally accurate GenAI outputs. Traditional image similarity metrics often fall short in assessing SCS. Pixel-level approaches are overly sensitive to minor visual noise, while perception-based metrics prioritize human aesthetic appeal, neither adequately capturing structural fidelity. Furthermore, recent neural-network-based metrics introduce training overheads and potential generalization issues. We introduce the SCS Similarity Index Measure (SCSSIM), a novel, analytical, and training-free metric that quantifies SCS preservation by exploiting statistical measures derived from the Cuboidal hierarchical partitioning of images, robustly capturing non-object-based structural relationships. Our experiments demonstrate SCSSIM's high invariance to non-compositional distortions, accurately reflecting unchanged SCS. Conversely, it shows a strong monotonic decrease for compositional distortions, precisely indicating when SCS has been altered. Compared to existing metrics, SCSSIM exhibits superior properties for structural evaluation, making it an invaluable tool for developing and evaluating generative models, ensuring the integrity of scene composition.
ReflectGAN: Modeling Vegetation Effects for Soil Carbon Estimation from Satellite Imagery
May 24, 2025


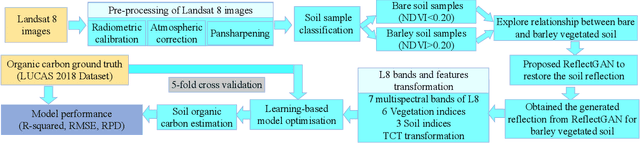
Soil organic carbon (SOC) is a critical indicator of soil health, but its accurate estimation from satellite imagery is hindered in vegetated regions due to spectral contamination from plant cover, which obscures soil reflectance and reduces model reliability. This study proposes the Reflectance Transformation Generative Adversarial Network (ReflectGAN), a novel paired GAN-based framework designed to reconstruct accurate bare soil reflectance from vegetated soil satellite observations. By learning the spectral transformation between vegetated and bare soil reflectance, ReflectGAN facilitates more precise SOC estimation under mixed land cover conditions. Using the LUCAS 2018 dataset and corresponding Landsat 8 imagery, we trained multiple learning-based models on both original and ReflectGAN-reconstructed reflectance inputs. Models trained on ReflectGAN outputs consistently outperformed those using existing vegetation correction methods. For example, the best-performing model (RF) achieved an $R^2$ of 0.54, RMSE of 3.95, and RPD of 2.07 when applied to the ReflectGAN-generated signals, representing a 35\% increase in $R^2$, a 43\% reduction in RMSE, and a 43\% improvement in RPD compared to the best existing method (PMM-SU). The performance of the models with ReflectGAN is also better compared to their counterparts when applied to another dataset, i.e., Sentinel-2 imagery. These findings demonstrate the potential of ReflectGAN to improve SOC estimation accuracy in vegetated landscapes, supporting more reliable soil monitoring.
Att2CPC: Attention-Guided Lossy Attribute Compression of Point Clouds
Oct 23, 2024



With the great progress of 3D sensing and acquisition technology, the volume of point cloud data has grown dramatically, which urges the development of efficient point cloud compression methods. In this paper, we focus on the task of learned lossy point cloud attribute compression (PCAC). We propose an efficient attention-based method for lossy compression of point cloud attributes leveraging on an autoencoder architecture. Specifically, at the encoding side, we conduct multiple downsampling to best exploit the local attribute patterns, in which effective External Cross Attention (ECA) is devised to hierarchically aggregate features by intergrating attributes and geometry contexts. At the decoding side, the attributes of the point cloud are progressively reconstructed based on the multi-scale representation and the zero-padding upsampling tactic. To the best of our knowledge, this is the first approach to introduce attention mechanism to point-based lossy PCAC task. We verify the compression efficiency of our model on various sequences, including human body frames, sparse objects, and large-scale point cloud scenes. Experiments show that our method achieves an average improvement of 1.15 dB and 2.13 dB in BD-PSNR of Y channel and YUV channel, respectively, when comparing with the state-of-the-art point-based method Deep-PCAC. Codes of this paper are available at https://github.com/I2-Multimedia-Lab/Att2CPC.
Global Attention-Guided Dual-Domain Point Cloud Feature Learning for Classification and Segmentation
Jul 12, 2024



Previous studies have demonstrated the effectiveness of point-based neural models on the point cloud analysis task. However, there remains a crucial issue on producing the efficient input embedding for raw point coordinates. Moreover, another issue lies in the limited efficiency of neighboring aggregations, which is a critical component in the network stem. In this paper, we propose a Global Attention-guided Dual-domain Feature Learning network (GAD) to address the above-mentioned issues. We first devise the Contextual Position-enhanced Transformer (CPT) module, which is armed with an improved global attention mechanism, to produce a global-aware input embedding that serves as the guidance to subsequent aggregations. Then, the Dual-domain K-nearest neighbor Feature Fusion (DKFF) is cascaded to conduct effective feature aggregation through novel dual-domain feature learning which appreciates both local geometric relations and long-distance semantic connections. Extensive experiments on multiple point cloud analysis tasks (e.g., classification, part segmentation, and scene semantic segmentation) demonstrate the superior performance of the proposed method and the efficacy of the devised modules.
Predicting Heart Failure with Attention Learning Techniques Utilizing Cardiovascular Data
Jul 11, 2024



Cardiovascular diseases (CVDs) encompass a group of disorders affecting the heart and blood vessels, including conditions such as coronary artery disease, heart failure, stroke, and hypertension. In cardiovascular diseases, heart failure is one of the main causes of death and also long-term suffering in patients worldwide. Prediction is one of the risk factors that is highly valuable for treatment and intervention to minimize heart failure. In this work, an attention learning-based heart failure prediction approach is proposed on EHR(electronic health record) cardiovascular data such as ejection fraction and serum creatinine. Moreover, different optimizers with various learning rate approaches are applied to fine-tune the proposed approach. Serum creatinine and ejection fraction are the two most important features to predict the patient's heart failure. The computational result shows that the RMSProp optimizer with 0.001 learning rate has a better prediction based on serum creatinine. On the other hand, the combination of SGD optimizer with 0.01 learning rate exhibits optimum performance based on ejection fraction features. Overall, the proposed attention learning-based approach performs very efficiently in predicting heart failure compared to the existing state-of-the-art such as LSTM approach.
FSDR: A Novel Deep Learning-based Feature Selection Algorithm for Pseudo Time-Series Data using Discrete Relaxation
Mar 13, 2024



Conventional feature selection algorithms applied to Pseudo Time-Series (PTS) data, which consists of observations arranged in sequential order without adhering to a conventional temporal dimension, often exhibit impractical computational complexities with high dimensional data. To address this challenge, we introduce a Deep Learning (DL)-based feature selection algorithm: Feature Selection through Discrete Relaxation (FSDR), tailored for PTS data. Unlike the existing feature selection algorithms, FSDR learns the important features as model parameters using discrete relaxation, which refers to the process of approximating a discrete optimisation problem with a continuous one. FSDR is capable of accommodating a high number of feature dimensions, a capability beyond the reach of existing DL-based or traditional methods. Through testing on a hyperspectral dataset (i.e., a type of PTS data), our experimental results demonstrate that FSDR outperforms three commonly used feature selection algorithms, taking into account a balance among execution time, $R^2$, and $RMSE$.
Full-resolution Lung Nodule Segmentation from Chest X-ray Images using Residual Encoder-Decoder Networks
Jul 13, 2023



Lung cancer is the leading cause of cancer death and early diagnosis is associated with a positive prognosis. Chest X-ray (CXR) provides an inexpensive imaging mode for lung cancer diagnosis. Suspicious nodules are difficult to distinguish from vascular and bone structures using CXR. Computer vision has previously been proposed to assist human radiologists in this task, however, leading studies use down-sampled images and computationally expensive methods with unproven generalization. Instead, this study localizes lung nodules using efficient encoder-decoder neural networks that process full resolution images to avoid any signal loss resulting from down-sampling. Encoder-decoder networks are trained and tested using the JSRT lung nodule dataset. The networks are used to localize lung nodules from an independent external CXR dataset. Sensitivity and false positive rates are measured using an automated framework to eliminate any observer subjectivity. These experiments allow for the determination of the optimal network depth, image resolution and pre-processing pipeline for generalized lung nodule localization. We find that nodule localization is influenced by subtlety, with more subtle nodules being detected in earlier training epochs. Therefore, we propose a novel self-ensemble model from three consecutive epochs centered on the validation optimum. This ensemble achieved a sensitivity of 85% in 10-fold internal testing with false positives of 8 per image. A sensitivity of 81% is achieved at a false positive rate of 6 following morphological false positive reduction. This result is comparable to more computationally complex systems based on linear and spatial filtering, but with a sub-second inference time that is faster than other methods. The proposed algorithm achieved excellent generalization results against an external dataset with sensitivity of 77% at a false positive rate of 7.6.
Efficient quantum image representation and compression circuit using zero-discarded state preparation approach
Jun 22, 2023



Quantum image computing draws a lot of attention due to storing and processing image data faster than classical. With increasing the image size, the number of connections also increases, leading to the circuit complex. Therefore, efficient quantum image representation and compression issues are still challenging. The encoding of images for representation and compression in quantum systems is different from classical ones. In quantum, encoding of position is more concerned which is the major difference from the classical. In this paper, a novel zero-discarded state connection novel enhance quantum representation (ZSCNEQR) approach is introduced to reduce complexity further by discarding '0' in the location representation information. In the control operational gate, only input '1' contribute to its output thus, discarding zero makes the proposed ZSCNEQR circuit more efficient. The proposed ZSCNEQR approach significantly reduced the required bit for both representation and compression. The proposed method requires 11.76\% less qubits compared to the recent existing method. The results show that the proposed approach is highly effective for representing and compressing images compared to the two relevant existing methods in terms of rate-distortion performance.
Exploiting Inductive Bias in Transformer for Point Cloud Classification and Segmentation
Apr 27, 2023



Discovering inter-point connection for efficient high-dimensional feature extraction from point coordinate is a key challenge in processing point cloud. Most existing methods focus on designing efficient local feature extractors while ignoring global connection, or vice versa. In this paper, we design a new Inductive Bias-aided Transformer (IBT) method to learn 3D inter-point relations, which considers both local and global attentions. Specifically, considering local spatial coherence, local feature learning is performed through Relative Position Encoding and Attentive Feature Pooling. We incorporate the learned locality into the Transformer module. The local feature affects value component in Transformer to modulate the relationship between channels of each point, which can enhance self-attention mechanism with locality based channel interaction. We demonstrate its superiority experimentally on classification and segmentation tasks. The code is available at: https://github.com/jiamang/IBT