 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Contextual Prediction for Learned Image Compression
Paper and Code
Dec 21, 2020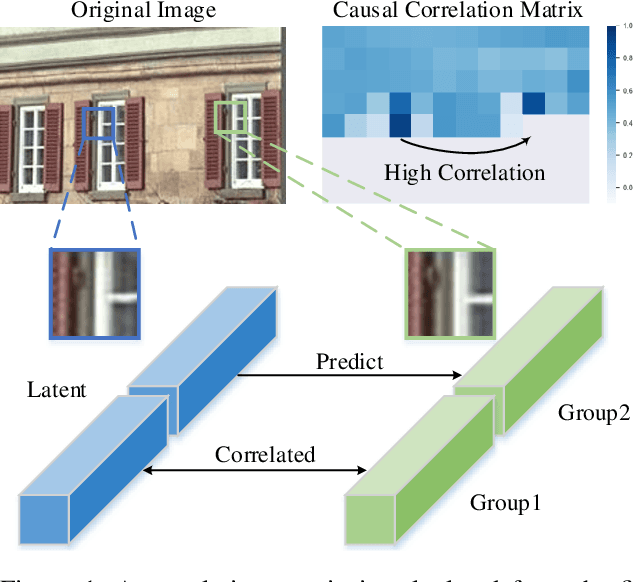
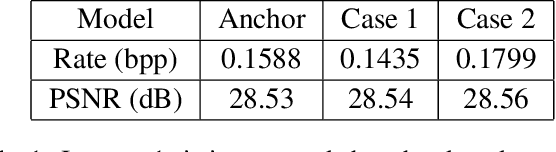
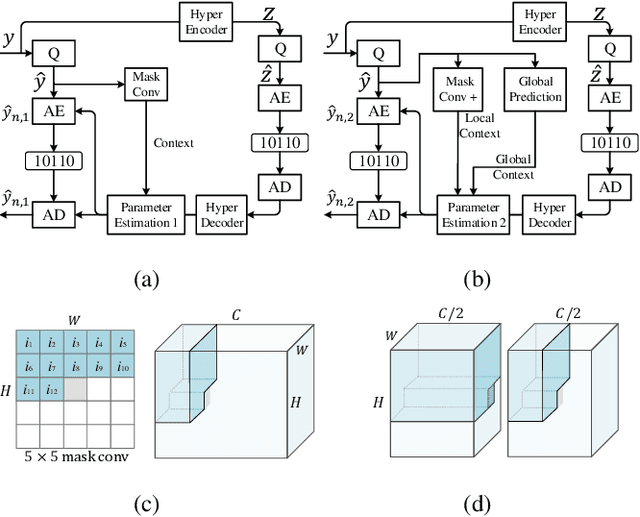

Over the past several years, we have witnessed impressive progress in the field of learned image compression. Recent learned image codecs are commonly based on autoencoders, that first encode an image into low-dimensional latent representations and then decode them for reconstruction purposes. To capture spatial dependencies in the latent space, prior works exploit hyperprior and spatial context model to build an entropy model, which estimates the bit-rate for end-to-end rate-distortion optimization. However, such an entropy model is suboptimal from two aspects: (1) It fails to capture spatially global correlations among the latents. (2) Cross-channel relationships of the latents are still underexplored. In this paper, we propose the concept of separate entropy coding to leverage a serial decoding process for causal contextual entropy prediction in the latent space. A causal context model is proposed that separates the latents across channels and makes use of cross-channel relationships to generate highly informative contexts. Furthermore, we propose a causal global prediction model, which is able to find global reference points for accurate predictions of unknown points. Both these two models facilitate entropy estimation without the transmission of overhead. In addition, we further adopt a new separate attention module to build more powerful transform networks. Experimental results demonstrate that our full image compression model outperforms standard VVC/H.266 codec on Kodak dataset in terms of both PSNR and MS-SSIM, yielding the state-of-the-art rate-distortion performance. Our test code is available at http://staff.ustc.edu.cn/~chenzhibo/resources/2020/ccp4lic.html.